Recognition: 2 theorem links
· Lean TheoremUniISP: A Unified ISP Framework for Both Human and Machine Vision
Pith reviewed 2026-05-11 02:34 UTC · model grok-4.3
The pith
UniISP creates a single ISP pipeline that produces images appealing to humans while preserving details for machine vision tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
UniISP is a unified ISP framework that incorporates a Hybrid Attention Module with supervised learning to generate visually pleasing RGB images from raw sensor data and a Feature Adapter module to propagate informative features to subsequent computer vision networks, achieving state-of-the-art performance across various scenarios and multiple datasets.
What carries the argument
The Hybrid Attention Module (HAM) that emphasizes relevant features for human visual quality combined with the Feature Adapter that transfers preserved information to machine vision models.
If this is right
- Generated images satisfy human aesthetic standards while supporting high accuracy in computer vision tasks.
- The framework performs well in low-light and other challenging capture conditions.
- Performance holds across multiple public datasets without task-specific retraining.
- A single pipeline removes the need for separate human and machine processing branches in camera systems.
Where Pith is reading between the lines
- Device makers could embed this processing to deliver better photos alongside stronger AI features without extra hardware modes.
- End-to-end training of the ISP with specific vision tasks becomes feasible as a next step.
- Real-time video versions could be tested for applications like mobile photography or vehicle cameras.
Load-bearing premise
That the attention module and feature adapter can jointly optimize for human visual appeal and machine information integrity without meaningful trade-offs in either.
What would settle it
Compare UniISP outputs against traditional ISP and minimal-ISP baselines on a held-out low-light dataset using both human visual quality ratings and accuracy of a fixed downstream object detector; if either score is worse than the stronger baseline, the unified benefit fails.
Figures



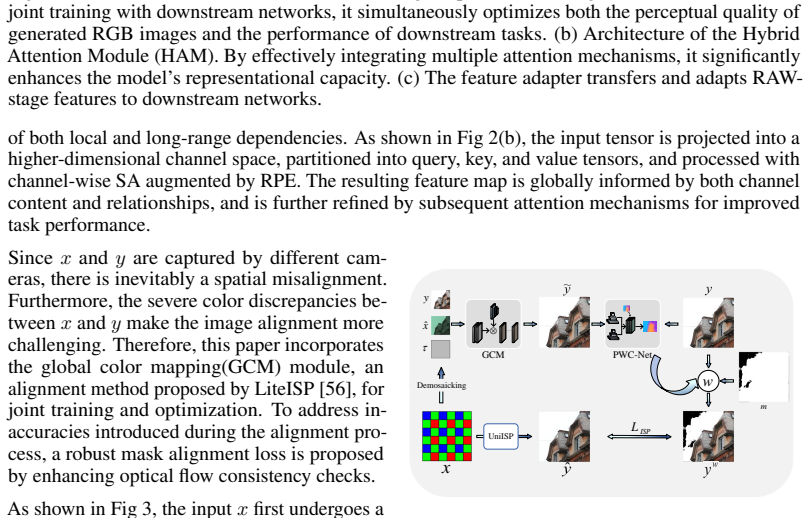

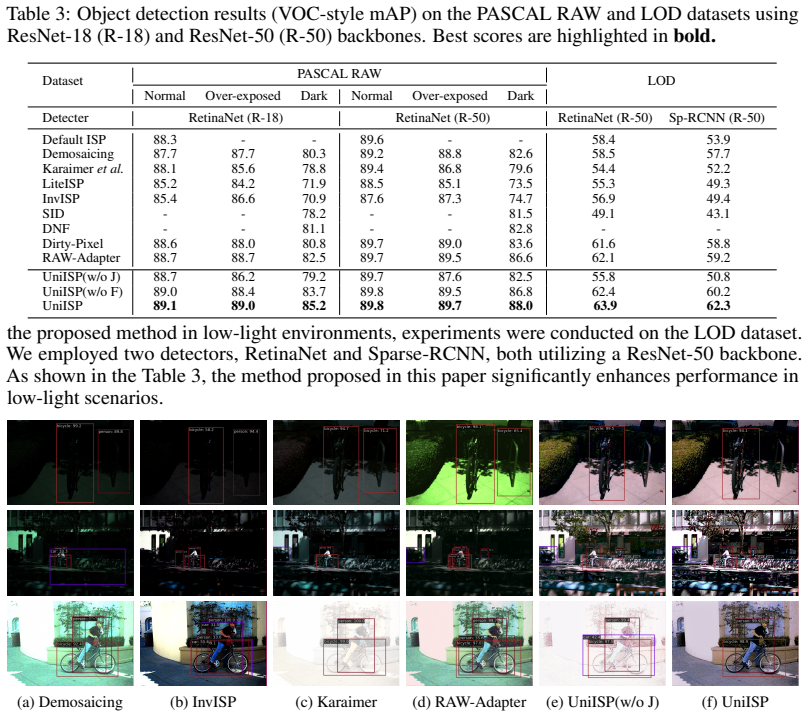






read the original abstract
Compared to RGB images, raw sensor data provides a richer representation of information, which is crucial for accurate recognition, particularly under challenging conditions such as low-light environments. The traditional Image Signal Processing (ISP) pipeline generates visually pleasing RGB images for human perception through a series of steps, but some of these operations may adversely impact the information integrity by introducing compression and loss. Furthermore, in computer vision tasks that directly utilize raw camera data, most existing methods integrate minimal ISP processing with downstream networks, yet the resulting images are often difficult to visualize or do not align with human aesthetic preferences. This paper proposes UniISP, a novel ISP framework designed to simultaneously meet the requirements of both human visual perception and computer vision applications. By incorporating a carefully designed Hybrid Attention Module (HAM) and employing supervised learning, the proposed method ensures that the generated images are visually appealing. Additionally, a Feature Adapter module is introduced to effectively propagate informative features from the ISP stage to subsequent downstream networks. Extensive experiments demonstrate that our approach achieves state-of-the-art performance across various scenarios and multiple datasets, proving its generalizability and effectiveness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes UniISP, a unified ISP framework that processes raw sensor data into RGB images suitable for both human visual perception and downstream machine vision tasks. It introduces a Hybrid Attention Module (HAM) trained with supervised learning to ensure visual appeal, along with a Feature Adapter module to propagate informative features to subsequent networks. The central claim is that this approach achieves state-of-the-art performance across various scenarios and multiple datasets while avoiding the information loss typical of traditional ISP pipelines.
Significance. If the empirical results hold, the work could be significant for computer vision applications that rely on raw or minimally processed data, such as low-light recognition. By jointly optimizing for human aesthetics and machine-usable features via the HAM and Feature Adapter, it offers a practical alternative to either fully traditional ISP or minimal-ISP approaches that produce unappealing outputs. The multi-dataset evaluation, if substantiated, would support claims of generalizability.
major comments (2)
- Abstract: The claim that 'extensive experiments demonstrate that our approach achieves state-of-the-art performance across various scenarios and multiple datasets' is presented without any quantitative metrics, baseline comparisons, ablation results, or dataset specifications. This is load-bearing for the central empirical claim, as the soundness of the method and the absence of trade-offs between human visual quality and machine vision performance cannot be evaluated from the provided description alone.
- Method description (inferred from abstract): The assertion that the Feature Adapter 'effectively propagate[s] informative features' and that the overall framework avoids 'significant trade-offs' requires explicit experimental validation (e.g., downstream task accuracy with vs. without the adapter, or human vs. machine metrics on the same outputs). Without such controls, the weakest assumption—that simultaneous optimization is possible without degradation—remains untested in the visible text.
minor comments (1)
- Abstract: Consider adding one sentence specifying the downstream tasks (e.g., object detection, classification) and example datasets to make the SOTA claim more concrete for readers.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below, clarifying the content of the full manuscript while noting where revisions can strengthen the presentation.
read point-by-point responses
-
Referee: Abstract: The claim that 'extensive experiments demonstrate that our approach achieves state-of-the-art performance across various scenarios and multiple datasets' is presented without any quantitative metrics, baseline comparisons, ablation results, or dataset specifications. This is load-bearing for the central empirical claim, as the soundness of the method and the absence of trade-offs between human visual quality and machine vision performance cannot be evaluated from the provided description alone.
Authors: We agree that the abstract, as a concise summary, does not include specific numbers or dataset names. The full manuscript contains multiple tables and figures reporting quantitative SOTA comparisons, baseline results, ablation studies, and dataset details (including low-light and standard scenarios). To better support the central claim for readers who focus on the abstract, we will revise it to include one or two key quantitative highlights (e.g., accuracy gains and perceptual scores) while remaining within length limits. revision: yes
-
Referee: Method description (inferred from abstract): The assertion that the Feature Adapter 'effectively propagate[s] informative features' and that the overall framework avoids 'significant trade-offs' requires explicit experimental validation (e.g., downstream task accuracy with vs. without the adapter, or human vs. machine metrics on the same outputs). Without such controls, the weakest assumption—that simultaneous optimization is possible without degradation—remains untested in the visible text.
Authors: The full manuscript includes dedicated ablation experiments that directly compare downstream task performance (e.g., recognition accuracy) with and without the Feature Adapter, as well as joint reporting of human perceptual quality metrics and machine vision accuracy on identical outputs. These results demonstrate that the adapter improves feature propagation without introducing measurable degradation in either domain. The experiments section already contains the requested controls; we can add a dedicated paragraph or table footnote if the referee believes the connection needs to be made more explicit. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper introduces UniISP as an architectural proposal combining a Hybrid Attention Module with supervised learning and a Feature Adapter module. Its claims rest on empirical results from training and evaluation on multiple datasets rather than any closed-form derivation, parameter fitting that is then relabeled as prediction, or load-bearing self-citation chains. No equations or definitions are shown that reduce the output to the input by construction, and the framework is presented as a new supervised pipeline whose performance is assessed externally via experiments.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Supervised learning on paired data can balance human visual quality and machine-usable feature preservation in ISP pipelines
invented entities (2)
-
Hybrid Attention Module (HAM)
no independent evidence
-
Feature Adapter module
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearHybrid Attention Module (HAM) ... channel-wise SA ... FreqFusion module aggregates multi-scale encoder outputs ... Ltotal = λ·Lhuman + (1−λ)·Lmachine with EMA weighting
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearlightweight end-to-end neural ISP framework ... U-Net architecture with the HAM as its backbone
Reference graph
Works this paper leans on
-
[1]
Reconfiguring the imaging pipeline for computer vision
Mark Buckler, Suren Jayasuriya, and Adrian Sampson. Reconfiguring the imaging pipeline for computer vision. InProceedings of the IEEE International Conference on Computer Vision, pages 975–984, 2017
work page 2017
-
[2]
Chen Chen, Qifeng Chen, Jia Xu, and Vladlen Koltun. Learning to see in the dark. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3291– 3300, 2018
work page 2018
-
[3]
MMDetection: Open MMLab Detection Toolbox and Benchmark
Kai Chen, Jiaqi Wang, Jiangmiao Pang, Yuhang Cao, Yu Xiong, Xiaoxiao Li, Shuyang Sun, Wansen Feng, Ziwei Liu, Jiarui Xu, et al. Mmdetection: Open mmlab detection toolbox and benchmark.arXiv preprint arXiv:1906.07155, 2019
work page Pith review arXiv 1906
-
[4]
Linwei Chen, Ying Fu, Lin Gu, Chenggang Yan, Tatsuya Harada, and Gao Huang. Frequency- aware feature fusion for dense image prediction.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
work page 2024
-
[5]
Mmsegmentation: Openmmlab semantic segmentation toolbox and benchmark, 2020
MMSegmentation Contributors. Mmsegmentation: Openmmlab semantic segmentation toolbox and benchmark, 2020
work page 2020
-
[6]
Raw-adapter: Adapting pre-trained visual model to camera raw images
Ziteng Cui and Tatsuya Harada. Raw-adapter: Adapting pre-trained visual model to camera raw images. InEuropean Conference on Computer Vision, pages 37–56. Springer, 2025
work page 2025
-
[7]
Multitask aet with orthogonal tangent regularity for dark object detection
Ziteng Cui, Guo-Jun Qi, Lin Gu, Shaodi You, Zenghui Zhang, and Tatsuya Harada. Multitask aet with orthogonal tangent regularity for dark object detection. InProceedings of the IEEE/CVF international conference on computer vision, pages 2553–2562, 2021
work page 2021
-
[8]
Awnet: Attentive wavelet network for image isp
Linhui Dai, Xiaohong Liu, Chengqi Li, and Jun Chen. Awnet: Attentive wavelet network for image isp. InComputer Vision–ECCV 2020 Workshops: Glasgow, UK, August 23–28, 2020, Proceedings, Part III 16, pages 185–201. Springer, 2020
work page 2020
-
[9]
Imagenet: A large- scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large- scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
work page 2009
-
[10]
Steven Diamond, Vincent Sitzmann, Frank Julca-Aguilar, Stephen Boyd, Gordon Wetzstein, and Felix Heide. Dirty pixels: Towards end-to-end image processing and perception.ACM Transactions on Graphics (TOG), 40(3):1–15, 2021
work page 2021
-
[11]
Learning degradation-independent representations for camera isp pipelines
Yanhui Guo, Fangzhou Luo, and Xiaolin Wu. Learning degradation-independent representations for camera isp pipelines. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 25774–25783, 2024
work page 2024
-
[12]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
work page 2016
-
[13]
Enhancing raw-to-srgb with decoupled style structure in fourier domain
Xuanhua He, Tao Hu, Guoli Wang, Zejin Wang, Run Wang, Qian Zhang, Keyu Yan, Ziyi Chen, Rui Li, Chengjun Xie, et al. Enhancing raw-to-srgb with decoupled style structure in fourier domain. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 2130–2138, 2024
work page 2024
-
[14]
Crafting object detection in very low light
Yang Hong, Kaixuan Wei, Linwei Chen, and Ying Fu. Crafting object detection in very low light. InBMVC, volume 1, page 3, 2021
work page 2021
-
[15]
Squeeze-and-excitation networks
Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation networks. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 7132–7141, 2018
work page 2018
-
[16]
Aim 2019 challenge on raw to rgb mapping: Methods and results
Andrey Ignatov, Radu Timofte, Sung-Jea Ko, Seung-Wook Kim, Kwang-Hyun Uhm, Seo-Won Ji, Sung-Jin Cho, Jun-Pyo Hong, Kangfu Mei, Juncheng Li, et al. Aim 2019 challenge on raw to rgb mapping: Methods and results. In2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), pages 3584–3590. IEEE, 2019. 10
work page 2019
-
[17]
Aim 2020 challenge on learned image signal processing pipeline
Andrey Ignatov, Radu Timofte, Zhilu Zhang, Ming Liu, Haolin Wang, Wangmeng Zuo, Jiawei Zhang, Ruimao Zhang, Zhanglin Peng, Sijie Ren, et al. Aim 2020 challenge on learned image signal processing pipeline. InComputer Vision–ECCV 2020 Workshops: Glasgow, UK, August 23–28, 2020, Proceedings, Part III 16, pages 152–170. Springer, 2020
work page 2020
-
[18]
Replacing mobile camera isp with a single deep learning model
Andrey Ignatov, Luc Van Gool, and Radu Timofte. Replacing mobile camera isp with a single deep learning model. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pages 536–537, 2020
work page 2020
-
[19]
Fine-grained fashion represen- tation learning by online deep clustering
Yang Jiao, Ning Xie, Yan Gao, Chien-Chih Wang, and Yi Sun. Fine-grained fashion represen- tation learning by online deep clustering. InEuropean conference on computer vision, pages 19–35. Springer, 2022
work page 2022
-
[20]
Learning attribute and class- specific representation duet for fine-grained fashion analysis
Yang Jiao, Yan Gao, Jingjing Meng, Jin Shang, and Yi Sun. Learning attribute and class- specific representation duet for fine-grained fashion analysis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11050–11059, 2023
work page 2023
-
[21]
Dnf: Decouple and feedback network for seeing in the dark
Xin Jin, Ling-Hao Han, Zhen Li, Chun-Le Guo, Zhi Chai, and Chongyi Li. Dnf: Decouple and feedback network for seeing in the dark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18135–18144, 2023
work page 2023
-
[22]
A software platform for manipulating the camera imaging pipeline
Hakki Can Karaimer and Michael S Brown. A software platform for manipulating the camera imaging pipeline. InComputer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part I 14, pages 429–444. Springer, 2016
work page 2016
-
[23]
Woohyeok Kim, Geonu Kim, Junyong Lee, Seungyong Lee, Seung-Hwan Baek, and Sunghyun Cho. Paramisp: learned forward and inverse isps using camera parameters.arXiv preprint arXiv:2312.13313, 2023
-
[24]
Adam: A Method for Stochastic Optimization
Diederik P Kingma. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[25]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4015–4026, 2023
work page 2023
-
[26]
Polarized color image denoising
Zhuoxiao Li, Haiyang Jiang, Mingdeng Cao, and Yinqiang Zheng. Polarized color image denoising. In2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9873–9882. IEEE, 2023
work page 2023
-
[27]
https://doi.org/10.48550/arXiv.1708.02002
T Lin. Focal loss for dense object detection.arXiv preprint arXiv:1708.02002, 2017
-
[28]
Feature pyramid networks for object detection
Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2117–2125, 2017
work page 2017
-
[29]
Multi-level wavelet convolutional neural networks.IEEE Access, 7:74973–74985, 2019
Pengju Liu, Hongzhi Zhang, Wei Lian, and Wangmeng Zuo. Multi-level wavelet convolutional neural networks.IEEE Access, 7:74973–74985, 2019
work page 2019
-
[30]
Least squares generative adversarial networks
Xudong Mao, Qing Li, Haoran Xie, Raymond YK Lau, Zhen Wang, and Stephen Paul Smolley. Least squares generative adversarial networks. InProceedings of the IEEE international conference on computer vision, pages 2794–2802, 2017
work page 2017
-
[31]
Dancing under the stars: video denoising in starlight
Kristina Monakhova, Stephan R Richter, Laura Waller, and Vladlen Koltun. Dancing under the stars: video denoising in starlight. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16241–16251, 2022
work page 2022
-
[32]
Genisp: Neural isp for low-light machine cognition
Igor Morawski, Yu-An Chen, Yu-Sheng Lin, Shusil Dangi, Kai He, and Winston H Hsu. Genisp: Neural isp for low-light machine cognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 630–639, 2022. 11
work page 2022
-
[33]
Hardware-in-the-loop end-to-end optimization of camera image processing pipelines
Ali Mosleh, Avinash Sharma, Emmanuel Onzon, Fahim Mannan, Nicolas Robidoux, and Felix Heide. Hardware-in-the-loop end-to-end optimization of camera image processing pipelines. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7529–7538, 2020
work page 2020
-
[34]
Pascalraw: raw image database for object detection.Stanford Digital Repository, 2014
Alex Omid-Zohoor, David Ta, and Boris Murmann. Pascalraw: raw image database for object detection.Stanford Digital Repository, 2014
work page 2014
-
[35]
Attention-aware learning for hyperparameter prediction in image processing pipelines
Haina Qin, Longfei Han, Juan Wang, Congxuan Zhang, Yanwei Li, Bing Li, and Weiming Hu. Attention-aware learning for hyperparameter prediction in image processing pipelines. In European Conference on Computer Vision, pages 271–287. Springer, 2022
work page 2022
-
[36]
Haina Qin, Longfei Han, Weihua Xiong, Juan Wang, Wentao Ma, Bing Li, and Weiming Hu. Learning to exploit the sequence-specific prior knowledge for image processing pipelines optimization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22314–22323, 2023
work page 2023
-
[37]
Color image processing pipeline.IEEE Signal processing magazine, 22(1):34–43, 2005
Rajeev Ramanath, Wesley E Snyder, Youngjun Yoo, and Mark S Drew. Color image processing pipeline.IEEE Signal processing magazine, 22(1):34–43, 2005
work page 2005
-
[38]
YOLOv3: An Incremental Improvement
Joseph Redmon. Yolov3: An incremental improvement.arXiv preprint arXiv:1804.02767, 2018
work page internal anchor Pith review arXiv 2018
-
[39]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InMedical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18, pages 234–241. Springer, 2015
work page 2015
-
[40]
An overview of gradient descent optimization algorithms,
Sebastian Ruder. An overview of gradient descent optimization algorithms.arXiv preprint arXiv:1609.04747, 2016
-
[41]
Transform your smartphone into a dslr camera: Learning the isp in the wild
Ardhendu Shekhar Tripathi, Martin Danelljan, Samarth Shukla, Radu Timofte, and Luc Van Gool. Transform your smartphone into a dslr camera: Learning the isp in the wild. InEuropean Conference on Computer Vision, pages 625–641. Springer, 2022
work page 2022
-
[42]
Pwc-net: Cnns for optical flow using pyramid, warping, and cost volume
Deqing Sun, Xiaodong Yang, Ming-Yu Liu, and Jan Kautz. Pwc-net: Cnns for optical flow using pyramid, warping, and cost volume. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 8934–8943, 2018
work page 2018
-
[43]
Sparse r-cnn: End-to-end object detection with learnable proposals
Peize Sun, Rufeng Zhang, Yi Jiang, Tao Kong, Chenfeng Xu, Wei Zhan, Masayoshi Tomizuka, Lei Li, Zehuan Yuan, Changhu Wang, et al. Sparse r-cnn: End-to-end object detection with learnable proposals. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14454–14463, 2021
work page 2021
-
[44]
Yujin Wang, Tianyi Xu, Zhang Fan, Tianfan Xue, and Jinwei Gu. Adaptiveisp: Learning an adaptive image signal processor for object detection.Advances in Neural Information Processing Systems, 37:112598–112623, 2024
work page 2024
-
[45]
Multiscale structural similarity for im- age quality assessment
Zhou Wang, Eero P Simoncelli, and Alan C Bovik. Multiscale structural similarity for im- age quality assessment. InThe Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, 2003, volume 2, pages 1398–1402. Ieee, 2003
work page 2003
-
[46]
A physics-based noise formation model for extreme low-light raw denoising
Kaixuan Wei, Ying Fu, Jiaolong Yang, and Hua Huang. A physics-based noise formation model for extreme low-light raw denoising. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2758–2767, 2020
work page 2020
-
[47]
Kaixuan Wei, Ying Fu, Yinqiang Zheng, and Jiaolong Yang. Physics-based noise modeling for extreme low-light photography.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(11):8520–8537, 2021
work page 2021
-
[48]
Visionisp: Repurposing the image signal processor for computer vision applications
Chyuan-Tyng Wu, Leo F Isikdogan, Sushma Rao, Bhavin Nayak, Timo Gerasimow, Aleksandar Sutic, Liron Ain-Kedem, and Gilad Michael. Visionisp: Repurposing the image signal processor for computer vision applications. In2019 IEEE International Conference on Image Processing (ICIP), pages 4624–4628. IEEE, 2019. 12
work page 2019
-
[49]
Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M Alvarez, and Ping Luo. Segformer: Simple and efficient design for semantic segmentation with transformers.Advances in neural information processing systems, 34:12077–12090, 2021
work page 2021
-
[50]
Invertible image signal processing
Yazhou Xing, Zian Qian, and Qifeng Chen. Invertible image signal processing. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6287–6296, 2021
work page 2021
-
[51]
Dynamicisp: dynamically controlled image signal processor for image recognition
Masakazu Yoshimura, Junji Otsuka, Atsushi Irie, and Takeshi Ohashi. Dynamicisp: dynamically controlled image signal processor for image recognition. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12866–12876, 2023
work page 2023
-
[52]
Reconfigisp: Reconfigurable camera image processing pipeline
Ke Yu, Zexian Li, Yue Peng, Chen Change Loy, and Jinwei Gu. Reconfigisp: Reconfigurable camera image processing pipeline. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4248–4257, 2021
work page 2021
-
[53]
Cycleisp: Real image restoration via improved data synthesis
Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, Ming- Hsuan Yang, and Ling Shao. Cycleisp: Real image restoration via improved data synthesis. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2696–2705, 2020
work page 2020
-
[54]
Restormer: Efficient transformer for high-resolution image restoration
Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, and Ming-Hsuan Yang. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5728–5739, 2022
work page 2022
-
[55]
The unrea- sonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unrea- sonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
work page 2018
-
[56]
Learning raw-to-srgb mappings with inaccurately aligned supervision
Zhilu Zhang, Haolin Wang, Ming Liu, Ruohao Wang, Jiawei Zhang, and Wangmeng Zuo. Learning raw-to-srgb mappings with inaccurately aligned supervision. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4348–4358, 2021
work page 2021
-
[57]
Scene parsing through ade20k dataset
Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Scene parsing through ade20k dataset. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 633–641, 2017
work page 2017
-
[58]
Wei Zhou, Shengyu Gao, Ling Zhang, and Xin Lou. Histogram of oriented gradients feature extraction from raw bayer pattern images.IEEE Transactions on Circuits and Systems II: Express Briefs, 67(5):946–950, 2020. 13 A Raw-to-RGB Mapping A qualitative comparison of the proposed method and existing approaches on the ZRR test set is provided in Fig 7. As depi...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.