Recognition: 1 theorem link
· Lean TheoremSolving Convolution-type Integral Equations using Preconditioned Neural Operators
Pith reviewed 2026-05-11 02:20 UTC · model grok-4.3
The pith
Preconditioned neural operators combined with weighted Jacobi iteration solve large convolution integral equations faster than multigrid or conjugate gradient methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By training a neural operator exclusively on the high-frequency residual after a simple diagonal preconditioner is applied, and then using that operator as an accelerator inside a weighted Jacobi iteration, the resulting hybrid solver converges rapidly on large-scale convolution-type integral equations that defeat conventional multigrid and PCG approaches.
What carries the argument
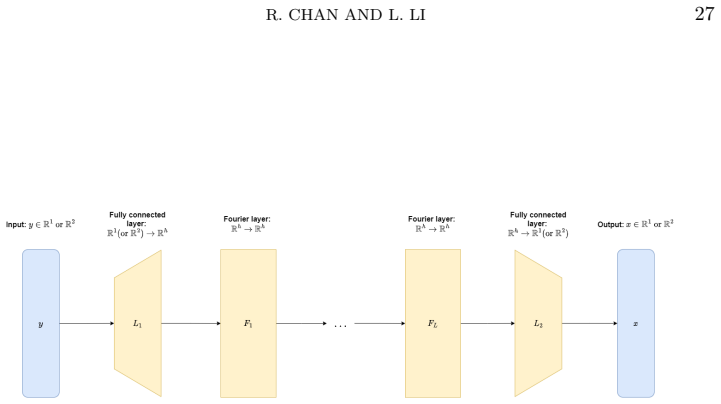
Preconditioned neural operator that approximates the action of the high-frequency inverse of the convolution kernel, inserted as a correction step inside a classical weighted Jacobi iteration.
If this is right
- The same training strategy yields a provably convergent method for any convolution kernel whose symbol admits a stable high-frequency splitting.
- Iteration count becomes essentially independent of mesh size once the neural operator is fixed.
- The approach extends directly to periodic boundary conditions and to kernels that arise in FIR filtering or image deblurring.
- Computational cost per iteration scales linearly with the number of grid points, matching the cost of a single matrix-vector product with the convolution kernel.
Where Pith is reading between the lines
- The same high-frequency neural correction could be inserted into other Krylov methods or into domain-decomposition schemes for non-convolution integral operators.
- If the training set is generated from random smooth right-hand sides, the resulting operator may also accelerate related deconvolution problems in statistics or geophysics.
- Because the neural component is trained once and reused, the method offers a practical route to real-time solvers for time-dependent convolution models.
Load-bearing premise
The neural operator, once trained on small preconditioned high-frequency residuals, continues to produce accurate corrections for arbitrarily large and ill-conditioned convolution systems without retraining.
What would settle it
Run the hybrid algorithm on a 1024-by-1024 discretization of a 2-D convolution equation whose condition number exceeds 10^6 and measure whether iteration count or runtime still beats multigrid by at least a factor of two.
Figures





read the original abstract
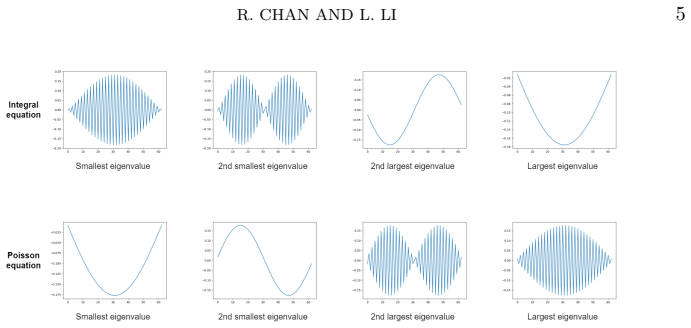
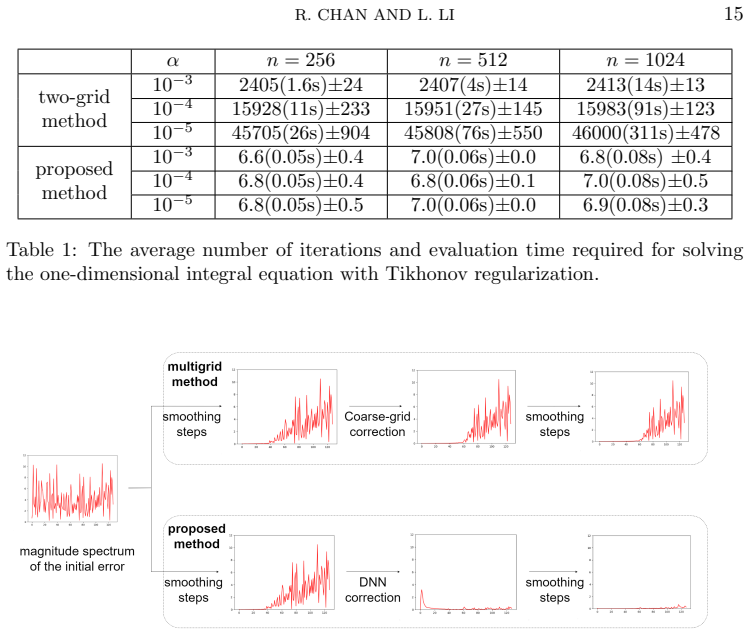
Convolution-type integral equations arise from various fields, \textit{e.g.}, finite impulse response filters in signal processing and deblurring problems in image processing. When solving these equations, conventional numerical methods, like the multigrid method, can only efficiently solve the low-frequency components in the error, but not the high-frequency components. In this paper, we apply neural operators to address this issue. By adopting a preconditioning approach, we propose a novel training strategy that trains neural operators to solve the high-frequency components efficiently. Then, we combine the neural operators with some classical iterative solvers, like the weighted Jacobi method, to obtain an efficient hybrid iterative algorithm for the integral equations. We analyze the generalization error of our training strategy and the convergence of the hybrid iterative algorithm. We test our algorithms on large-scale and ill-conditioned linear systems discretized from one- and two-dimensional convolution-type integral equations. Our proposed algorithm significantly outperforms the multigrid method and the preconditioned conjugate gradient method in both iteration numbers and computational time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a hybrid iterative solver for convolution-type integral equations that trains a neural operator on high-frequency residuals after a classical smoother (weighted Jacobi) and embeds it inside an outer iteration. It claims to analyze the generalization error of this training strategy and the convergence of the resulting algorithm, then reports numerical tests on large-scale, ill-conditioned 1-D and 2-D discretizations where the hybrid method outperforms multigrid and preconditioned conjugate gradient in both iteration count and wall-clock time.
Significance. If the claimed generalization bounds hold uniformly over kernel symbols and grid sizes, the approach would supply a practical way to accelerate high-frequency error reduction in Toeplitz systems that arise in signal processing and image deblurring, while retaining the low-frequency handling of classical smoothers. The explicit analysis of generalization error and convergence is a positive feature that distinguishes the work from purely empirical neural-operator papers.
major comments (2)
- [Generalization error analysis] Generalization-error analysis (the section following the training strategy): the stated uniform bounds over the operator family are not shown to be independent of the condition number of the discretized convolution operator or of the particular symbol of the kernel. Because the numerical tests emphasize precisely the ill-conditioned regime, this independence is load-bearing for the outperformance claim; without it the hybrid iteration may stall on unseen large-scale instances.
- [Numerical experiments] Numerical experiments section, Tables/Figures reporting iteration counts and timings: the training set is generated from specific residuals after the weighted Jacobi smoother, yet no ablation or cross-validation is reported for kernels or grid sizes outside the training distribution. The central claim that the preconditioned neural operator generalizes accurately to arbitrary large-scale ill-conditioned systems therefore rests on unverified extrapolation.
minor comments (2)
- [Algorithm description] Notation for the neural operator input (preconditioned residual) and output (correction) should be introduced with a single consistent symbol rather than varying between the training description and the algorithm pseudocode.
- [Introduction] The abstract states that 'generalization error and convergence are analyzed,' but the manuscript would benefit from a short remark in the introduction clarifying which classical results (e.g., on neural-operator approximation) are invoked versus which new bounds are derived.
Simulated Author's Rebuttal
We thank the referee for the careful reading, positive assessment of the work's significance, and constructive comments on the generalization analysis and numerical validation. We address each major comment below and outline revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Generalization error analysis] Generalization-error analysis (the section following the training strategy): the stated uniform bounds over the operator family are not shown to be independent of the condition number of the discretized convolution operator or of the particular symbol of the kernel. Because the numerical tests emphasize precisely the ill-conditioned regime, this independence is load-bearing for the outperformance claim; without it the hybrid iteration may stall on unseen large-scale instances.
Authors: We appreciate this observation. The generalization bounds are established for a family of kernels whose symbols satisfy bounded-variation and regularity assumptions that implicitly control the high-frequency behavior targeted by the neural operator; uniformity holds within that class. The analysis does not claim full independence from the condition number for arbitrary symbols, as the low-frequency component is handled by the outer weighted Jacobi iteration. We will revise the relevant section to state the assumptions more explicitly, add a remark clarifying the separation of high- and low-frequency handling, and include a brief discussion of how the preconditioner mitigates dependence on the symbol for the error components it is trained to correct. These clarifications will be accompanied by a note that the outperformance claims in the ill-conditioned regime rest on both the theory under the stated assumptions and the reported numerical evidence. revision: partial
-
Referee: [Numerical experiments] Numerical experiments section, Tables/Figures reporting iteration counts and timings: the training set is generated from specific residuals after the weighted Jacobi smoother, yet no ablation or cross-validation is reported for kernels or grid sizes outside the training distribution. The central claim that the preconditioned neural operator generalizes accurately to arbitrary large-scale ill-conditioned systems therefore rests on unverified extrapolation.
Authors: We agree that explicit ablation and cross-validation on out-of-distribution kernels and grids would provide stronger empirical support for generalization. The existing tests already include 1-D and 2-D problems with varying grid sizes and condition numbers, but we did not report separate hold-out experiments on entirely unseen kernel symbols. We will add an appendix containing additional numerical results: (i) tests on kernels whose symbols differ from those used in training (e.g., different decay rates), and (ii) runs on grid sizes larger than the training distribution. These will be presented with iteration counts and timings to document the observed extrapolation behavior. revision: yes
Circularity Check
No significant circularity; derivation relies on external approximation theory and classical convergence results.
full rationale
The paper's core claims rest on training a neural operator for high-frequency residuals (standard neural-operator approximation theory) combined with classical smoothers like weighted Jacobi, followed by separate analysis of generalization error and hybrid iteration convergence. No load-bearing step reduces by definition or self-citation to a fitted quantity inside the paper; the outperformance is presented as an empirical and theoretical consequence of the hybrid scheme rather than a tautology. Self-citations, if present, are not required to justify the central premises.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Neural operators can be trained to accurately represent the high-frequency component of the residual operator for convolution-type kernels.
- standard math The weighted Jacobi iteration combined with the learned correction satisfies a contraction mapping or spectral-radius bound less than one.
Reference graph
Works this paper leans on
-
[1]
20 [1]G. S. Ammar and W. B. Gragg,Superfast solution of real positive definite Toeplitz systems, SIAM Journal on Matrix Analysis and Applications, 9 (1988), pp. 61–76. [2]A. Beck and M. Teboulle,A fast iterative shrinkage-thresholding algorithm for linear inverse problems, SIAM Journal on Imaging Sciences, 2 (2009), pp. 183–202. [3]J.-M. Bergheau and R. F...
work page 1988
-
[2]
[4]R. R. Bitmead and B. D. Anderson,Asymptotically fast solution of Toeplitz and related systems of linear equations, Linear Algebra and its Applications, 34 (1980), pp. 103–116. [5]W. L. Briggs, V. E. Henson, and S. F. McCormick,A multigrid tutorial, SIAM,
work page 1980
-
[3]
[6]Y. Cao, Z. F ang, Y. Wu, D.-X. Zhou, and Q. Gu,Towards understanding the spectral bias of deep learning, in 30th International Joint Conference on Artificial Intelligence (IJCAI 2021), International Joint Conferences on Artificial Intelligence, 2021, pp. 2205–2211. [7]R. Chan, T. F. Chan, and W. W an,Multigrid for differential-convolution problems aris...
work page 2021
-
[4]
[10]R. H. Chan and X.-Q. Jin,A family of block preconditioners for block systems, SIAM Journal on Scientific and Statistical Computing, 13 (1992), pp. 1218–1235. [11]R. H. Chan and M. K. Ng,Conjugate gradient methods for Toeplitz systems, SIAM Review, 38 (1996), pp. 427–482. [12]R. H. Chan and M.-C. Yeung,Circulant preconditioners constructed from kernels...
work page 1992
-
[5]
[18]S. Goswami, M. Yin, Y. Yu, and G. E. Karniadakis,A physics-informed variational deep- onet for predicting crack path in quasi-brittle materials, Computer Methods in Applied Mechanics and Engineering, 391 (2022), p. 114587. [19]U. Grenander,Toeplitz forms and their applications, California Monographs in Mathematical Sciences/University of California Pr...
work page 2022
-
[6]
[23]J. Hu and P. Jin,A hybrid iterative method based on MIONet for pdes: Theory and numerical examples, arXiv preprint arXiv:2402.07156, (2024). [24]R. Huang, R. Li, and Y. Xi,Learning optimal multigrid smoothers via neural networks, SIAM Journal on Scientific Computing, 45 (2022), pp. S199–S225. [25]R. King, M. Ahmadi, R. Gorgui-Naguib, A. Kwabwe, and M....
-
[7]
[26]S. M. Kwerel,Bounds on the probability of the union and intersection of m events, Advances in Applied Probability, 7 (1975), pp. 431–448. [27]M. Ledoux and M. Talagrand,Probability in Banach Spaces: Isoperimetry and processes, Springer Science & Business Media,
work page 1975
- [8]
-
[9]
[29]Z. Li, N. B. Kovachki, K. Azizzadenesheli, B. liu, K. Bhattacharya, A. Stuart, and A. Anandkumar,Fourier neural operator for parametric partial differential equations, in International Conference on Learning Representations, 2021, https://openreview.net/ R. CHAN AND L. LI21 forum?id=c8P9NQVtmnO. [30]Z. Li, H. Zheng, N. Kovachki, D. Jin, H. Chen, B. Li...
-
[10]
[32]S. Liu, C. Su, J. Yao, Z. Hao, H. Su, Y. Wu, and J. Zhu,Preconditioning for physics- informed neural networks, arXiv preprint arXiv:2402.00531, (2024). [33]L. Lu, P. Jin, G. Pang, Z. Zhang, and G. E. Karniadakis,Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators, Nature Machine Intelligence, 3 (2021), p...
-
[11]
[37]N. Rahaman, A. Baratin, D. Arpit, F. Draxler, M. Lin, F. Hamprecht, Y. Bengio, and A. Courville,On the spectral bias of neural networks, in International conference on machine learning, PMLR, 2019, pp. 5301–5310. [38]O. Ronneberger, P. Fischer, and T. Brox,U-Net: Convolutional networks for biomedical image segmentation, in Procedings of Medical Image ...
work page 2019
-
[12]
[39]J. W. Ruge and K. St ¨uben,Algebraic multigrid, in Multigrid Methods, SIAM, 1987, pp. 73–
work page 1987
-
[13]
[41]S. Song, T. Mukerji, and D. Zhang,Physics-informed multi-grid neural operator: theory and an application to porous flow simulation, Journal of Computational Physics, 520 (2025), p. 113438. [42]H.-W. Sun, R. H. Chan, and Q.-S. Chang,A note on the convergence of the two-grid method for Toeplitz systems, Computers & Mathematics with Applications, 34 (199...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.