Recognition: 1 theorem link
· Lean TheoremVelocity-Space 3D Asset Editing
Pith reviewed 2026-05-11 02:03 UTC · model grok-4.3
The pith
VS3D performs local 3D asset editing inside the rectified-flow sampler by anchoring source identity, amplifying consistent edits, and deciding preservation token by token.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
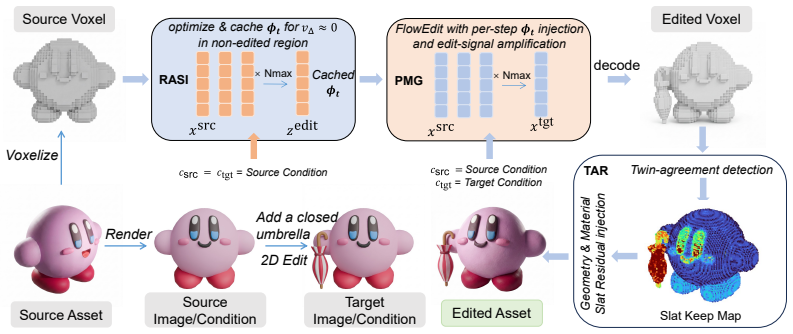
A single velocity field cannot simultaneously drive a strong edit on the target region and vanish on preserved content, so rectified-flow samplers produce identity leakage, lack dedicated amplification, and suffer identity drag. VS3D solves each problem with a velocity-space module: Reconstruction-Anchored Source Injection turns the unconditional embedding into a per-step asset-specific anchor, Partial-Mean Guidance contrasts high- and low-quality velocity differences to amplify only consistent edits, and Twin-Agreement Residual injection lets the sampler decide token by token what to preserve at the geometry and material stages.
What carries the argument
The combination of three velocity-space interventions—Reconstruction-Anchored Source Injection (RASI), Partial-Mean Guidance (PMG), and Twin-Agreement Residual (TAR)—applied directly inside the rectified-flow ODE sampler.
Load-bearing premise
The three interventions can be combined in the sampler without creating new artifacts or requiring per-asset tuning beyond the described procedure.
What would settle it
An edited asset in which the target region fails to change as intended or in which preserved regions show visible shifts in shape or material after applying the three modules would falsify the claim.
Figures





read the original abstract
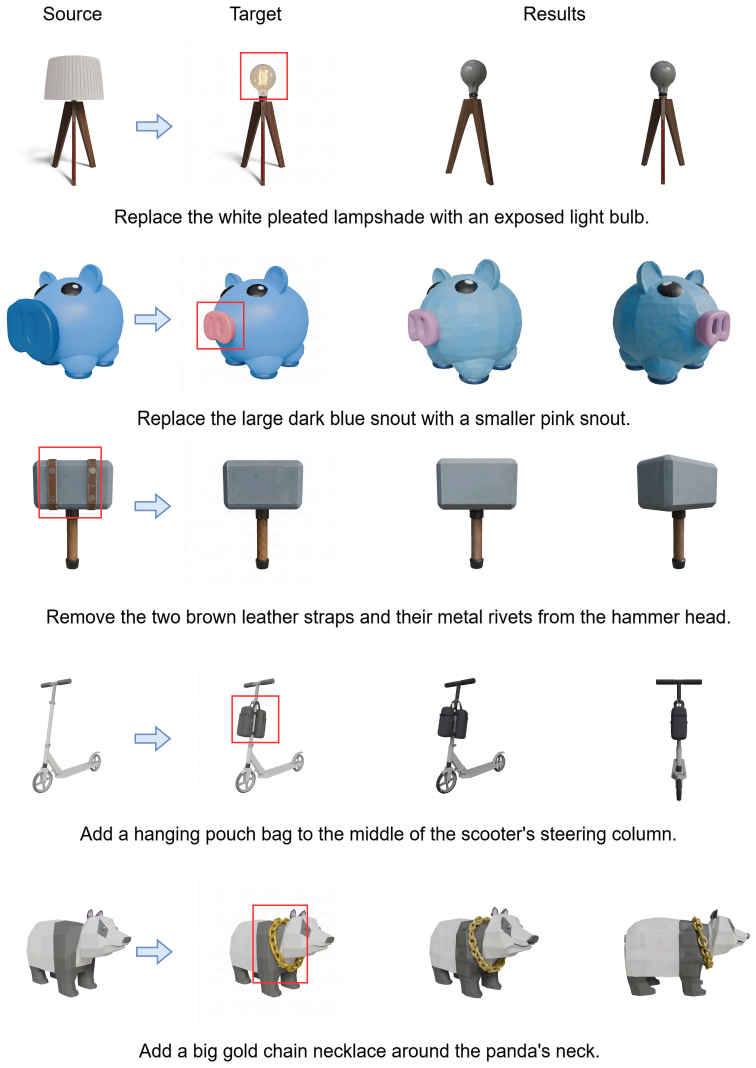
Editing a 3D asset locally, modifying a target region while preserving the rest, is a fundamental requirement of native 3D editing. Existing methods enforce locality through mechanisms external to the generator, such as manual 3D masks, post-hoc voxel merging, or 2D multi-view lifting. None of them intervene where the corruption actually originates: inside the ODE sampler. For a rectified-flow generator to achieve faithful local editing, its velocity field should be strong over the target editing region while vanishing on preserved content. Yet a single velocity field can hardly satisfy both requirements simultaneously, leading to three problems: (i) identity leakage that keeps the edit signal non-zero on preserved regions; (ii) no dedicated edit-amplification channel, so strengthening the edit inevitably perturbs identity; and (iii) an identity drag at the geometry and material stages, where a global condition pulls every token toward the target. We propose VS3D (Velocity-Space 3D Asset editing}), an inversion-free, training-free, and mask-free framework that addresses each problem with a targeted intervention inside the sampler. VS3D integrates three complementary modules, each corresponding to a specific stage of the editing pipeline. Reconstruction-Anchored Source Injection (RASI) absorbs identity leakage by turning the unconditional embedding into a per-step, asset-specific anchor calibrated through source reconstruction. Partial-Mean Guidance (PMG) amplifies the edit signal by contrasting high- and low-quality subsample estimates of the velocity difference, active only where a consistent edit exists. Twin-Agreement Residual injection (TAR) lets the sampler decide token by token what to preserve at the geometry and material stages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes VS3D, an inversion-free, training-free, and mask-free framework for local 3D asset editing that intervenes directly inside the rectified-flow ODE sampler. It identifies three problems (identity leakage, lack of edit amplification, and identity drag at geometry/material stages) and addresses them via three modules: Reconstruction-Anchored Source Injection (RASI) that calibrates the unconditional embedding from source reconstruction, Partial-Mean Guidance (PMG) that amplifies consistent velocity differences from high/low-quality subsamples, and Twin-Agreement Residual injection (TAR) that applies token-wise residuals only on agreeing tokens.
Significance. If the modules prove orthogonal and robust, the velocity-space approach could meaningfully advance 3D editing by eliminating reliance on external masks, post-hoc merging, or 2D lifting while remaining training-free. The explicit targeting of the velocity field v_t rather than latent or pixel space is a conceptual strength, and the absence of per-asset inversion or fine-tuning would be practically valuable if the interventions generalize without new artifacts.
major comments (2)
- The central claim that RASI, PMG, and TAR can be combined inside the sampler without mutual interference or per-asset tuning is load-bearing but unsupported by any derivation or normalization analysis of their additive effects on v_t. No equation shows how the RASI anchor, PMG velocity-difference contrast, and TAR residual are scheduled across denoising steps or scaled so that PMG amplification does not override TAR preservation on the same token (see the integration description following the problem statement).
- The paper asserts that PMG is 'active only where a consistent edit exists' and TAR decides 'token by token,' yet provides no formal definition or threshold for consistency/agreement, nor any ablation demonstrating that these decisions remain stable when all three modules operate simultaneously. This leaves the orthogonality assumption untested and risks re-introducing identity drag or high-frequency artifacts at geometry/material stages.
minor comments (2)
- The abstract and introduction use several invented acronyms (RASI, PMG, TAR) without immediate expansion on first use, which reduces readability.
- No quantitative metrics, datasets, or baseline comparisons are referenced in the provided description, making it difficult to assess the magnitude of improvement over existing mask-based or post-hoc methods.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the integration and orthogonality of the proposed modules in VS3D. We address each major comment below and plan to revise the manuscript accordingly to provide additional analysis and ablations.
read point-by-point responses
-
Referee: The central claim that RASI, PMG, and TAR can be combined inside the sampler without mutual interference or per-asset tuning is load-bearing but unsupported by any derivation or normalization analysis of their additive effects on v_t. No equation shows how the RASI anchor, PMG velocity-difference contrast, and TAR residual are scheduled across denoising steps or scaled so that PMG amplification does not override TAR preservation on the same token (see the integration description following the problem statement).
Authors: We appreciate the referee highlighting the need for explicit integration details. The manuscript describes the modules as complementary interventions on distinct aspects of the velocity field (RASI on unconditional embeddings, PMG on velocity differences, TAR on token residuals), but we acknowledge the absence of a formal derivation or normalization analysis for their combined effects and scheduling. In the revision we will add a dedicated subsection with equations specifying the per-step scaling and scheduling of the three terms, along with empirical validation of non-interference across denoising stages. revision: yes
-
Referee: The paper asserts that PMG is 'active only where a consistent edit exists' and TAR decides 'token by token,' yet provides no formal definition or threshold for consistency/agreement, nor any ablation demonstrating that these decisions remain stable when all three modules operate simultaneously. This leaves the orthogonality assumption untested and risks re-introducing identity drag or high-frequency artifacts at geometry/material stages.
Authors: We agree that the current description of activation criteria and joint behavior is qualitative. The manuscript states that PMG activates on consistent edits and TAR operates token-wise, yet omits explicit thresholds and a combined ablation. We will revise to include formal definitions (e.g., velocity-difference threshold for PMG consistency and token-agreement score for TAR) and a new ablation table evaluating all three modules together, confirming stability and absence of introduced artifacts at geometry and material stages. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The provided manuscript text and abstract present VS3D as a conceptual framework that integrates three named interventions (RASI, PMG, TAR) inside a rectified-flow sampler to mitigate identity leakage, lack of edit amplification, and identity drag. No equations, derivations, fitted parameters, or self-citations appear that would reduce any claimed result to its own inputs by construction. The description remains at the level of module definitions and qualitative problem statements without a load-bearing mathematical chain that collapses into self-definition or renamed fits. The central claim therefore stands as an independent proposal rather than a tautological restatement of inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A single velocity field in a rectified-flow generator cannot simultaneously be strong on the edit region and zero on preserved regions.
- domain assumption Rectified-flow ODE sampling allows per-step injection of auxiliary signals without breaking the overall generative process.
invented entities (3)
-
Reconstruction-Anchored Source Injection (RASI)
no independent evidence
-
Partial-Mean Guidance (PMG)
no independent evidence
-
Twin-Agreement Residual injection (TAR)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearVS3D integrates three complementary modules... Reconstruction-Anchored Source Injection (RASI) absorbs identity leakage by turning the unconditional embedding into a per-step, asset-specific anchor... Partial-Mean Guidance (PMG) amplifies the edit signal by contrasting high- and low-quality subsample estimates... Twin-Agreement Residual injection (TAR) lets the sampler decide token by token what to preserve
Reference graph
Works this paper leans on
- [1]
-
[2]
FlowEdit: Inversion-Free Text-Based Editing Using Pre-Trained Flow Models , journal =
V . Kulikov, M. Kleiner, I. Huberman-Spiegelglas, and T. Michaeli. FlowEdit: Inversion-free text-based editing using pre-trained flow models.arXiv preprint arXiv:2412.08629, 2024
- [3]
-
[4]
X. Liu, C. Gong, and Q. Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InThe Eleventh International Conference on Learning Representations (ICLR), 2023
work page 2023
-
[5]
O. Siméoni, H. V . V o, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V . Khalidov, M. Szafraniec, S. E. Yi, M. Ramamonjisoa, F. Massa, D. Haziza, L. Wehrstedt, J. Wang, T. Darcet, T. Moutakanni, L. Sentana, C. Roberts, A. Vedaldi, J. Tolan, J. Brandt, C. Couprie, J. Mairal, H. Jégou, P. Labatut, and P. Bojanowski. DINOv3.arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [6]
-
[7]
Native and Compact Structured Latents for 3D Generation.arXiv preprint arXiv:2512.14692, 2025a
J. Xiang, X. Chen, S. Xu, R. Wang, Z. Lv, Y . Deng, H. Zhu, Y . Dong, H. Zhao, N. J. Yuan, and J. Yang. Native and compact structured latents for 3D generation.arXiv preprint arXiv:2512.14692, 2025
- [8]
- [9]
-
[10]
VecSet-Edit: Unleashing Pre-trained LRM for Mesh Editing from Single Image
T.-F. Hsiao, B.-K. Ruan, Y .-L. Liu, and H.-H. Shuai. VecSet-Edit: Unleashing pre-trained LRM for mesh editing from single image.arXiv preprint arXiv:2602.04349, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [11]
- [12]
-
[13]
I. Gat, D. Cohen-Bar, G. Levy, E. Richardson, and D. Cohen-Or. ShapeUP: Scalable image-conditioned 3D editing.arXiv preprint arXiv:2602.05676, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [14]
- [15]
-
[16]
Z. Lai, Y . Zhao, H. Liu, Z. Zhao, Q. Lin, H. Shi, X. Yang, M. Yang, S. Yang, Y . Feng, S. Zhang, X. Huang, D. Luo, F. Yang, F. Yang, L. Wang, S. Liu, Y . Tang, Y . Cai, Z. He, T. Liu, Y . Liu, J. Jiang, Linus, J. Huang, and C. Guo. Hunyuan3D 2.5: Towards high-fidelity 3D assets generation with ultimate details.arXiv preprint arXiv:2506.16504, 2025
- [17]
- [18]
- [19]
- [20]
- [21]
-
[22]
M. Oquab, T. Darcet, T. Moutakanni, H. V . V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P. Huang, S. Li, I. Misra, M. Rabbat, V . Sharma, G. Synnaeve, H. Xu, H. Jégou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski. DINOv2: Learning robust visual features without supervis...
work page 2024
-
[23]
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning (ICML), pages 8748–8763, 2021. A Technical appendices and supplementary material A.1 Experimental s...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.