Recognition: no theorem link
Learning myopic mixed-integer nonlinear model predictive control from expert demonstrations
Pith reviewed 2026-05-11 02:11 UTC · model grok-4.3
The pith
A value function learned from expert demonstrations allows mixed-integer nonlinear MPC to use short prediction horizons while retaining high performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The learned value function from expert state-action pairs via inverse optimization induces an approximately policy-consistent policy that, when used in a myopic MINMPC, achieves high closed-loop performance with significantly reduced online computation.
What carries the argument
The value function approximation obtained by minimizing KKT optimality residuals under relaxed integer constraints during offline learning.
Load-bearing premise
The assumption that a value function trained under relaxed integer constraints during learning will still yield high-quality decisions when the online controller uses the exact integer constraints.
What would settle it
Running the learned myopic controller on the Lotka-Volterra or satellite example and observing that its closed-loop performance falls substantially below that of the full-horizon expert or optimal MINMPC.
Figures

read the original abstract
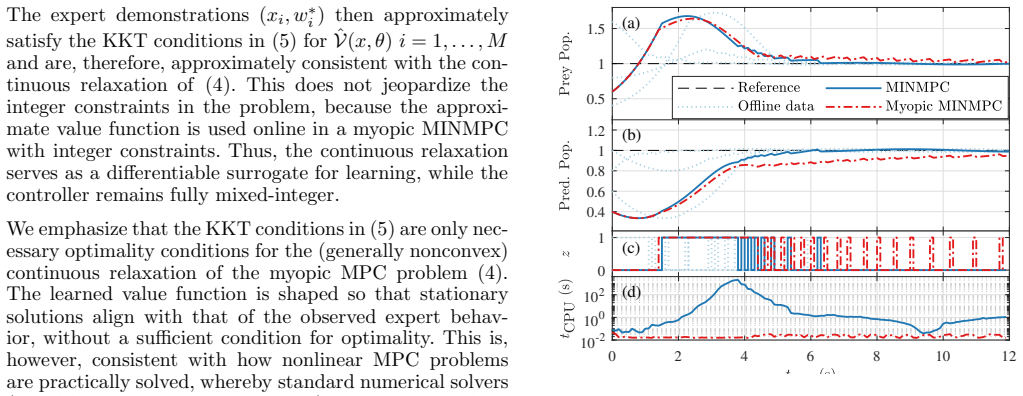
Applying nonlinear model predictive control (NMPC) to systems with hybrid dynamics or discrete actions typically yields mixed-integer nonlinear programs (MINLPs), whose real-time solution remains a major challenge and limits the applicability of mixed-integer NMPC (MINMPC). This paper proposes a myopic MINMPC framework that incorporates value-function approximation to substantially reduce the online computational burden. Using Bellman's principle of optimality, we shorten the prediction horizon and append a value function learned offline from expert state-action demonstrations via inverse optimization with optimality residual minimization. A central feature is the dual treatment of discrete decisions, whereby integer constraints are relaxed during offline learning to enable KKT-residual-based value function synthesis, while the online controller enforces the true integer constraints to ensure feasibility. The learned value function induces a policy that is approximately policy-consistent with the expert demonstrations. The resulting controller achieves high closed-loop performance with a significantly shorter horizon, enabling real-time MINMPC. The effectiveness of the approach is demonstrated on the Lotka-Volterra fishing problem and a satellite attitude control system with discrete actuators.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a myopic MINMPC framework that learns a terminal value function offline from expert state-action demonstrations via inverse optimization and KKT-residual minimization under relaxed (continuous) integer variables. The online controller then uses this value function to shorten the prediction horizon while re-imposing the original discrete constraints, claiming approximate policy consistency with the experts and high closed-loop performance, as shown on the Lotka-Volterra fishing problem and a satellite attitude control example.
Significance. If the learned value function remains a sufficiently accurate approximation when integer constraints are enforced online, the approach could meaningfully lower the computational cost of MINMPC for hybrid or discrete-actuator systems, enabling real-time deployment where full-horizon MINLPs are currently intractable. The two numerical demonstrations provide concrete evidence that shorter-horizon controllers can achieve competitive performance, which is a practically relevant strength.
major comments (2)
- [§3 (method description and optimality residual minimization)] The central claim that the learned value function induces an approximately policy-consistent myopic policy (abstract and §3) rests on the transfer from relaxed-integer offline learning to integer-enforced online optimization. No quantitative bound, sensitivity analysis, or gap measurement is provided on how the relaxation affects the value-function approximation or Bellman consistency when the online optimizer is restricted to integer vertices. This directly impacts the validity of the shorter-horizon claim for both examples.
- [§5 (numerical examples)] In the Lotka-Volterra and satellite demonstrations, closed-loop performance is stated to be high with the myopic controller, yet the manuscript supplies no comparison against the full-horizon expert MINMPC or any explicit evaluation of the integer-relaxation gap on the expert trajectories or closed-loop states visited. Without such data, it is impossible to confirm that the observed performance stems from policy consistency rather than post-hoc tuning or problem-specific tolerance to suboptimality.
minor comments (2)
- [§3.1] Notation for the relaxed versus integer variables is introduced but used inconsistently in the KKT residual expressions; a single table or explicit mapping would improve readability.
- [§5] The abstract claims 'significantly shorter horizon' but the manuscript does not report the exact horizon lengths used in the full versus myopic controllers or the resulting solve-time reduction factors.
Simulated Author's Rebuttal
Thank you for the constructive review of our manuscript arXiv:2605.07401. We address each major comment point by point below, acknowledging where the manuscript can be strengthened through additional analysis and data, and outline the corresponding revisions.
read point-by-point responses
-
Referee: [§3 (method description and optimality residual minimization)] The central claim that the learned value function induces an approximately policy-consistent myopic policy (abstract and §3) rests on the transfer from relaxed-integer offline learning to integer-enforced online optimization. No quantitative bound, sensitivity analysis, or gap measurement is provided on how the relaxation affects the value-function approximation or Bellman consistency when the online optimizer is restricted to integer vertices. This directly impacts the validity of the shorter-horizon claim for both examples.
Authors: We agree that quantifying the effect of the continuous relaxation during offline learning on the subsequent integer-enforced online optimization is important for validating the approximate policy consistency. Deriving a general a priori bound is challenging given the nonlinear dynamics and hybrid nature of the systems considered. However, we can and will strengthen the manuscript by adding a numerical sensitivity analysis and gap measurement. In the revision, we will include evaluations of the value-function approximation error, optimality residual differences, and Bellman consistency gaps computed on the expert trajectories and closed-loop states, comparing relaxed versus integer-feasible solutions. This will be presented in a new subsection of §3 or an appendix to directly address the transfer from offline learning to online execution. revision: yes
-
Referee: [§5 (numerical examples)] In the Lotka-Volterra and satellite demonstrations, closed-loop performance is stated to be high with the myopic controller, yet the manuscript supplies no comparison against the full-horizon expert MINMPC or any explicit evaluation of the integer-relaxation gap on the expert trajectories or closed-loop states visited. Without such data, it is impossible to confirm that the observed performance stems from policy consistency rather than post-hoc tuning or problem-specific tolerance to suboptimality.
Authors: We accept this observation and will revise the numerical examples section to include the requested comparisons and gap evaluations. For both the Lotka-Volterra and satellite cases, we will add direct closed-loop performance metrics comparing the myopic controller against the full-horizon expert MINMPC (computed offline for benchmarking where feasible). We will also report explicit integer-relaxation gap measures, such as differences in cost and constraint satisfaction between relaxed and integer solutions on the expert data and visited states. These additions will clarify that the reported performance arises from the learned value function's approximate consistency rather than other factors. revision: yes
Circularity Check
Value function learned via residual minimization on experts makes policy-consistency claim tautological by construction
specific steps
-
fitted input called prediction
[Abstract]
"The learned value function induces a policy that is approximately policy-consistent with the expert demonstrations."
The value function is synthesized by inverse optimization that minimizes optimality residuals on the same expert state-action pairs. Consequently, approximate policy consistency is enforced by the residual-minimization objective and is not an emergent or independently verified property of the myopic controller.
full rationale
The paper learns the terminal value function by minimizing KKT optimality residuals of an inverse optimization problem posed on the expert demonstrations (under continuous relaxation). It then asserts that this learned value function 'induces a policy that is approximately policy-consistent with the expert demonstrations.' Because the learning objective directly penalizes deviation from the experts' optimality conditions, the consistency statement reduces to a restatement of the fitting success rather than an independent derivation or prediction. The dual treatment of integer constraints (relaxed offline, enforced online) and the appeal to Bellman's principle do not break this reduction. No self-citations, uniqueness theorems, or ansatzes are load-bearing in the provided text, so the circularity is moderate and localized to the central claim.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Bellman's principle of optimality
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
B.C. Able and R.A. Tagg and M. Rush , title=. Advances in Enzymology , address=. 1954 , volume=
work page 1954
- [4]
- [5]
-
[6]
Dictionary of the American Language
The American Heritage. Dictionary of the American Language
- [7]
- [8]
- [9]
- [10]
-
[11]
Kalman, R. E. , title = ". Journal of Basic Engineering , volume =. 1964 , month =. doi:10.1115/1.3653115 , url =
-
[12]
Proceedings of the AAAI conference on artificial intelligence , volume=
Deep q-learning from demonstrations , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[13]
2011 IEEE international symposium on intelligent control , pages=
Imputing a convex objective function , author=. 2011 IEEE international symposium on intelligent control , pages=. 2011 , organization=
work page 2011
-
[14]
Andrew Bagnell, Pieter Abbeel, and Jan Peters
Foundations and Trends® in Robotics , title =. 2018 , volume =. doi:10.1561/2300000053 , issn =
-
[15]
Computers & Chemical Engineering , pages=
Approximate moving horizon estimation and robust nonlinear model predictive control via deep learning , author=. Computers & Chemical Engineering , pages=. 2021 , publisher=
work page 2021
-
[16]
Proceedings of the 2019 Foundations in Process Analytics and Machine Learning , year=
Real-time optimization strategies using Surrogate Optimizers , author=. Proceedings of the 2019 Foundations in Process Analytics and Machine Learning , year=
work page 2019
-
[17]
Learning for Dynamics and Control , pages=
Learning convex optimization control policies , author=. Learning for Dynamics and Control , pages=. 2020 , organization=
work page 2020
-
[18]
IEEE Transactions on Industrial Electronics , volume=
Supervised Imitation Learning of Finite-Set Model Predictive Control Systems for Power Electronics , author=. IEEE Transactions on Industrial Electronics , volume=. 2020 , publisher=
work page 2020
-
[19]
Advances in neural information processing systems , volume=
Practical bayesian optimization of machine learning algorithms , author=. Advances in neural information processing systems , volume=
-
[20]
A survey on image data augmentation for deep learning , author=. Journal of Big Data , volume=. 2019 , publisher=
work page 2019
- [21]
-
[22]
Learning for Dynamics and Control , pages=
Fitting a linear control policy to demonstrations with a Kalman constraint , author=. Learning for Dynamics and Control , pages=. 2020 , organization=
work page 2020
-
[23]
A reduction of imitation learning and structured prediction to no-regret online learning , author=. Proceedings of the fourteenth international conference on artificial intelligence and statistics , pages=. 2011 , organization=
work page 2011
-
[24]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Autoaugment: Learning augmentation strategies from data , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[25]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops , pages=
Randaugment: Practical automated data augmentation with a reduced search space , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops , pages=
-
[26]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Self-training with noisy student improves imagenet classification , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[27]
International conference on machine learning , pages=
A simple framework for contrastive learning of visual representations , author=. International conference on machine learning , pages=. 2020 , organization=
work page 2020
-
[28]
A robot controller using learning by imitation , author=. 1994 , publisher=
work page 1994
-
[29]
Alvinn: An autonomous land vehicle in a neural network , author=. 1989 , institution=
work page 1989
-
[30]
IEEE transactions on robotics and automation , volume=
Learning by watching: Extracting reusable task knowledge from visual observation of human performance , author=. IEEE transactions on robotics and automation , volume=. 1994 , publisher=
work page 1994
- [31]
-
[32]
Proceedings of the twenty-first international conference on Machine learning , pages=
Apprenticeship learning via inverse reinforcement learning , author=. Proceedings of the twenty-first international conference on Machine learning , pages=
-
[33]
IEEE Transactions on Control Systems Technology , year=
Constrained inverse optimal control with application to a human manipulation task , author=. IEEE Transactions on Control Systems Technology , year=
-
[34]
Approximate Dynamic Programming: Solving the curses of dimensionality , author=. 2007 , publisher=
work page 2007
-
[35]
Dynamic programming and optimal control 3rd edition, volume
Bertsekas, Dimitri P , journal=. Dynamic programming and optimal control 3rd edition, volume
-
[36]
IEEE Transactions on Automatic Control , volume=
A sensitivity-based data augmentation framework for model predictive control policy approximation , author=. IEEE Transactions on Automatic Control , volume=. 2021 , publisher=
work page 2021
-
[37]
2016 IEEE Symposium Series on Computational Intelligence (SSCI) , pages=
Learning the optimal state-feedback using deep networks , author=. 2016 IEEE Symposium Series on Computational Intelligence (SSCI) , pages=. 2016 , organization=
work page 2016
-
[38]
Computers & Chemical Engineering , volume=
Industrial, large-scale model predictive control with structured neural networks , author=. Computers & Chemical Engineering , volume=. 2021 , publisher=
work page 2021
-
[39]
2008 IEEE/RSJ International Conference on Intelligent Robots and Systems , pages=
Learning robot motion control with demonstration and advice-operators , author=. 2008 IEEE/RSJ International Conference on Intelligent Robots and Systems , pages=. 2008 , organization=
work page 2008
-
[40]
Journal of Artificial Intelligence Research , volume=
Interactive policy learning through confidence-based autonomy , author=. Journal of Artificial Intelligence Research , volume=
-
[41]
arXiv preprint arXiv:2008.00524 , year=
Interactive imitation learning in state-space , author=. arXiv preprint arXiv:2008.00524 , year=
-
[42]
2019 IEEE 58th Conference on Decision and Control (CDC) , pages=
Sample-based learning model predictive control for linear uncertain systems , author=. 2019 IEEE 58th Conference on Decision and Control (CDC) , pages=. 2019 , organization=
work page 2019
-
[43]
2021 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Adversarial Differentiable Data Augmentation for Autonomous Systems , author=. 2021 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2021 , organization=
work page 2021
-
[44]
2021 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Generalization in reinforcement learning by soft data augmentation , author=. 2021 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2021 , organization=
work page 2021
-
[45]
Deep Neural Network Approximation of Nonlinear Model Predictive Control , author=. IFAC-PapersOnLine , volume=. 2020 , publisher=
work page 2020
-
[46]
Mathematical Programming Computation , volume=
Optimal sensitivity based on IPOPT , author=. Mathematical Programming Computation , volume=. 2012 , publisher=
work page 2012
-
[47]
Towards global optimization , volume=
The application of Bayesian methods for seeking the extremum , author=. Towards global optimization , volume=
-
[48]
Journal of Global optimization , volume=
Efficient global optimization of expensive black-box functions , author=. Journal of Global optimization , volume=. 1998 , publisher=
work page 1998
-
[49]
Proceedings of the IEEE , volume=
Taking the human out of the loop: A review of Bayesian optimization , author=. Proceedings of the IEEE , volume=. 2015 , publisher=
work page 2015
-
[50]
A new method of locating the maximum point of an arbitrary multipeak curve in the presence of noise , author=
-
[51]
Gaussian process optimization in the bandit setting: No regret and experimental design,
Gaussian process optimization in the bandit setting: No regret and experimental design , author=. arXiv preprint arXiv:0912.3995 , year=
-
[52]
On the likelihood that one unknown probability exceeds another in view of the evidence of two samples , author=. Biometrika , volume=. 1933 , publisher=
work page 1933
-
[53]
Advances in neural information processing systems , volume=
An empirical evaluation of thompson sampling , author=. Advances in neural information processing systems , volume=. 2011 , publisher=
work page 2011
- [54]
-
[55]
arXiv preprint arXiv:1406.2541 , year=
Predictive entropy search for efficient global optimization of black-box functions , author=. arXiv preprint arXiv:1406.2541 , year=
-
[56]
and Snoek, Jasper and Adams, Ryan P
Gelbart, Michael A. and Snoek, Jasper and Adams, Ryan P. , title =. Proceedings of the Thirtieth Conference on Uncertainty in Artificial Intelligence , pages =. 2014 , publisher =
work page 2014
- [57]
-
[58]
International Conference on Machine Learning , pages=
Safe exploration for optimization with Gaussian processes , author=. International Conference on Machine Learning , pages=. 2015 , organization=
work page 2015
-
[59]
Bayesian optimization with safety constraints: safe and automatic parameter tuning in robotics , author=. Machine Learning , pages=. 2021 , publisher=
work page 2021
-
[60]
Journal of Computational and Graphical Statistics , number=
Bayesian optimization via barrier functions , author=. Journal of Computational and Graphical Statistics , number=. 2021 , publisher=
work page 2021
-
[61]
International Conference on Machine Learning , pages=
On kernelized multi-armed bandits , author=. International Conference on Machine Learning , pages=. 2017 , organization=
work page 2017
-
[62]
Gaussian processes for machine learning , author=. 2006 , publisher=
work page 2006
-
[63]
Virtanen, Pauli and Gommers, Ralf and Oliphant, Travis E. and Haberland, Matt and Reddy, Tyler and Cournapeau, David and Burovski, Evgeni and Peterson, Pearu and Weckesser, Warren and Bright, Jonathan and. Nature Methods , year =
-
[64]
Linear programming under uncertainty , author=. Management science , volume=. 1955 , publisher=
work page 1955
-
[65]
Distributionally robust convex optimization , author=. Operations Research , volume=. 2014 , publisher=
work page 2014
-
[66]
Theory and applications of robust optimization , author=. SIAM review , volume=. 2011 , publisher=
work page 2011
-
[67]
Mathematics of operations research , volume=
Robust convex optimization , author=. Mathematics of operations research , volume=. 1998 , publisher=
work page 1998
-
[68]
SIAM Journal on Matrix Analysis and Applications , volume=
Robust solutions to least-squares problems with uncertain data , author=. SIAM Journal on Matrix Analysis and Applications , volume=. 1997 , publisher=
work page 1997
-
[69]
Technical note—convex programming with set-inclusive constraints and applications to inexact linear programming , author=. Operations research , volume=. 1973 , publisher=
work page 1973
-
[70]
Annals of Mathematics , pages=
Statistical decision functions which minimize the maximum risk , author=. Annals of Mathematics , pages=. 1945 , publisher=
work page 1945
-
[71]
Distributionally robust optimization under moment uncertainty with application to data-driven problems , author=. Operations research , volume=. 2010 , publisher=
work page 2010
-
[72]
Transactions of the ASME--Journal of Basic Engineering , Volume =
Kalman, Rudolph Emil , Title =. Transactions of the ASME--Journal of Basic Engineering , Volume =
-
[73]
B. P. G. Van Parys and D. Kuhn and P. J. Goulart and M. Morari , journal=. Distributionally Robust Control of Constrained Stochastic Systems , year=. doi:10.1109/TAC.2015.2444134 , ISSN=
-
[74]
Chance-constrained programming , author=. Management science , volume=. 1959 , publisher=
work page 1959
-
[75]
IFIP Conference on System Modeling and Optimization , pages=
Efficient nonlinear programming algorithms for chemical process control and operations , author=. IFIP Conference on System Modeling and Optimization , pages=. 2007 , organization=
work page 2007
-
[76]
Nonlinear programming: concepts, algorithms, and applications to chemical processes , author=. 2010 , publisher=
work page 2010
- [77]
-
[78]
Mathematical Programming Computation , volume=
CasADi—A software framework for nonlinear optimization and optimal control , author=. Mathematical Programming Computation , volume=. 2018 , publisher=
work page 2018
-
[79]
Mathematical programming , volume=
On the implementation of an interior-point filter line-search algorithm for large-scale nonlinear programming , author=. Mathematical programming , volume=. 2006 , publisher=
work page 2006
-
[80]
ACM Transactions on Mathematical Software (TOMS) , volume=
SUNDIALS: Suite of nonlinear and differential/algebraic equation solvers , author=. ACM Transactions on Mathematical Software (TOMS) , volume=. 2005 , publisher=
work page 2005
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.