Recognition: no theorem link
Incentivizing User Data Contributions for LLM Improvement under Withdrawal Rights
Pith reviewed 2026-05-11 01:45 UTC · model grok-4.3
The pith
Cost reporting plus personalized assignments lets platforms collect user data for LLMs only when the total meets the improvement threshold, avoiding subsidy waste.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Mechanisms that combine truthful cost reporting with centralized personalized contribution assignments and withdrawal rights eliminate inefficient provision by collecting data only when the aggregate meets the sustainable improvement threshold, converting infeasible cases into null outcomes rather than incurring subsidy expenditure without gains.
What carries the argument
The withdrawal-enabled mechanism with cost reporting and centralized personalized assignment, which filters contributions to proceed only when the pre-verified improvement threshold is reached.
If this is right
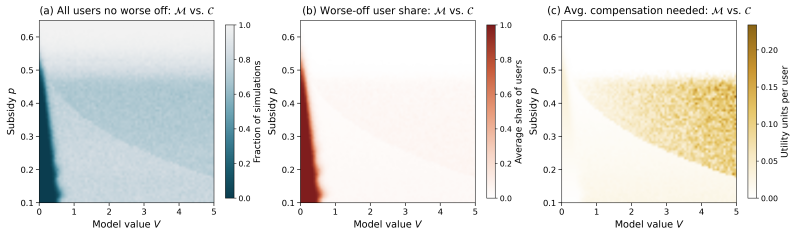
- Decentralized subsidy responses frequently produce payments without reaching the improvement threshold.
- Adding withdrawal rights after personalized assignment prevents subsidy leakage by turning infeasible cases into null outcomes.
- The simultaneous withdrawal protocol achieves the lowest total cost across contributors.
- The small-first sequential withdrawal protocol increases participation and raises the probability of crossing the improvement threshold.
Where Pith is reading between the lines
- A platform could choose the simultaneous protocol when cost minimization is the priority and the sequential protocol when maximizing the chance of usable data matters more.
- The design implies that verifiable improvement thresholds must be defined in advance for the filtering benefit to hold.
- If withdrawal rights are made credible and costless, truthful cost reporting becomes more likely under the mechanism.
Load-bearing premise
Users report their private costs truthfully when the platform asks for them.
What would settle it
Run a controlled experiment in which users report costs, receive personalized assignments, and may withdraw; check whether any subsidy is paid in a round where the final collected data falls short of the declared improvement threshold.
Figures







read the original abstract
The continued improvement of large language models (LLMs) increasingly depends on eliciting high-quality, user-generated data, yet such data are costly to provide and often withheld due to privacy and effort concerns. This creates a fundamental design challenge: how to incentivize data contribution when model improvements require coordinated, threshold-level inputs, while contributions remain privately costly and partially reversible. We develop and theoretically analyze incentive mechanisms for user data contribution that explicitly account for threshold effects and reversibility, focusing on how subsidies and withdrawal rights can be jointly designed to overcome coordination failure. As a natural benchmark, we first consider subsidy-based incentives, under which users respond to posted payments with privately optimal floor contributions. These decentralized responses may fall below the improvement threshold, resulting in subsidy expenditure without model improvements. We then analyze mechanisms with withdrawal rights, in which users report costs, the provider centrally assigns contribution burdens, and users may withdraw before training. We prove that combining cost reporting with personalized assignment can eliminate inefficient provision by ensuring that data are collected only when improvement is sustainable, converting infeasible instances into a null outcome rather than subsidy leakage. Finally, we compare two withdrawal protocols. The simultaneous protocol can achieve lower total cost, while the small-first sequential protocol better incentivizes participation, encouraging greater data provision and thereby increasing the probability of crossing the improvement threshold.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops and analyzes incentive mechanisms for eliciting costly, privately held user data to improve LLMs when contributions must meet a coordination threshold and users retain withdrawal rights before training. It first studies decentralized subsidy-based incentives under which users choose floor contributions, which can result in subsidy expenditure without crossing the improvement threshold. It then examines mechanisms in which users report costs, the provider makes personalized burden assignments, and users may withdraw; the central result is a proof that this combination eliminates inefficient provision by collecting data only when improvement is sustainable, converting infeasible instances into a null outcome rather than subsidy leakage. The paper concludes by comparing a simultaneous withdrawal protocol (lower total cost) with a small-first sequential protocol (higher participation and threshold-crossing probability).
Significance. If the equilibrium analysis and proofs hold, the work supplies a clean theoretical template for threshold-based data elicitation that respects reversibility and avoids leakage, which is directly relevant to practical LLM fine-tuning pipelines that rely on user-generated data. The explicit comparison of withdrawal protocols supplies a concrete trade-off that practitioners could test. The contribution is modest in scope but well-targeted; its value hinges on whether the incentive-compatibility argument is fully rigorous rather than assumed.
major comments (2)
- [Abstract / mechanisms with withdrawal rights] Abstract and the section analyzing mechanisms with withdrawal rights: the central claim that 'combining cost reporting with personalized assignment can eliminate inefficient provision' presupposes truthful reporting of private costs, yet no payment rule (VCG-style, withdrawal-adjusted, or otherwise) is exhibited that renders truth-telling a dominant strategy. Without such a rule, users can strategically misreport to alter their assigned burden or withdrawal probability, breaking the mapping from true costs to sustainable collection and undermining the conversion of infeasible instances to null outcomes.
- [Comparison of withdrawal protocols] The section on withdrawal protocols: the comparison between simultaneous and small-first sequential protocols is presented as achieving different objectives (lower total cost vs. higher participation), but the manuscript supplies no equilibrium characterization or welfare bounds showing when one protocol Pareto-dominates the other once strategic withdrawal and misreporting are admitted.
minor comments (1)
- The abstract would be clearer if it briefly stated the functional form of the improvement threshold and the users' quasi-linear utility (cost minus payment plus value of model improvement).
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important gaps in the incentive-compatibility and equilibrium analysis. We address each major point below and will revise the manuscript accordingly to strengthen the formal arguments without altering the core claims.
read point-by-point responses
-
Referee: [Abstract / mechanisms with withdrawal rights] Abstract and the section analyzing mechanisms with withdrawal rights: the central claim that 'combining cost reporting with personalized assignment can eliminate inefficient provision' presupposes truthful reporting of private costs, yet no payment rule (VCG-style, withdrawal-adjusted, or otherwise) is exhibited that renders truth-telling a dominant strategy. Without such a rule, users can strategically misreport to alter their assigned burden or withdrawal probability, breaking the mapping from true costs to sustainable collection and undermining the conversion of infeasible instances to null outcomes.
Authors: We agree that the current draft does not exhibit an explicit payment rule making truthful cost reporting a dominant strategy, which leaves the incentive-compatibility argument incomplete. In the revision we will add a withdrawal-adjusted VCG-style payment rule: each user i receives payment equal to the reported cost of the marginal user whose inclusion determines whether the threshold is met, minus the externality imposed on others. This rule ensures that misreporting cannot improve a user's net utility (payment minus true cost) while preserving the property that data collection occurs only when the reported costs permit sustainable improvement, converting infeasible instances to null outcomes. The revised proof will explicitly verify dominant-strategy incentive compatibility under this rule. revision: yes
-
Referee: [Comparison of withdrawal protocols] The section on withdrawal protocols: the comparison between simultaneous and small-first sequential protocols is presented as achieving different objectives (lower total cost vs. higher participation), but the manuscript supplies no equilibrium characterization or welfare bounds showing when one protocol Pareto-dominates the other once strategic withdrawal and misreporting are admitted.
Authors: The current analysis compares the two protocols under the assumption of truthful reporting to isolate the cost-participation trade-off. We acknowledge that a complete characterization under strategic misreporting and withdrawal is absent. In revision we will add a section deriving equilibrium participation rates and welfare bounds for both protocols once the incentive-compatible payment rule is in place. Specifically, we will show that the simultaneous protocol yields lower expected total cost conditional on threshold crossing, while the small-first sequential protocol raises the probability of crossing when users anticipate the payment rule, and we will identify parameter regions (cost distributions and threshold values) where one protocol yields higher ex-ante welfare. We do not claim general Pareto dominance but will supply the requested bounds. revision: partial
Circularity Check
No significant circularity; theoretical proof is self-contained
full rationale
The paper conducts a standard mechanism-design analysis of subsidy and withdrawal-based incentives for threshold data contributions. Its central result is a proof that cost reporting plus personalized assignment converts infeasible cases to null outcomes rather than leakage. This follows from explicit assumptions (truthful reporting, verifiable thresholds, costless withdrawal) and equilibrium analysis rather than any reduction of a prediction to a fitted parameter or self-citation chain. No equations are shown to be tautological by construction, and the derivation does not rename known results or smuggle ansatzes via prior self-work. The analysis remains independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Users have privately known costs for providing data
- domain assumption Model improvement occurs only above a collective contribution threshold
Reference graph
Works this paper leans on
-
[1]
Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei
Paul F. Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences.Advances in Neural Information Processing Systems, 30, 2017
work page 2017
-
[2]
Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul F
Nisan Stiennon, Long Ouyang, Jeff Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul F. Christiano. Learning to summarize with human feedback.Advances in Neural Information Processing Systems, 33:3008–3021, 2020
work page 2020
-
[3]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
work page 2022
-
[4]
Alvin Toffler.The third wave: The classic study of tomorrow. Bantam, 2022
work page 2022
-
[5]
George Ritzer and Nathan Jurgenson. Production, consumption, prosumption: The nature of capitalism in the age of the digital ‘prosumer’.Journal of consumer culture, 10(1):13–36, 2010
work page 2010
-
[6]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Roman Ring, et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Position: Will we run out of data? limits of llm scaling based on human-generated data
Pablo Villalobos, Anson Ho, Jaime Sevilla, Tamay Besiroglu, Lennart Heim, and Marius Hobbhahn. Position: Will we run out of data? limits of llm scaling based on human-generated data. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[9]
A survey on efficient large language model training: From data- centric perspectives
Jie Luo, Bing Wu, Xiaolin Luo, et al. A survey on efficient large language model training: From data- centric perspectives. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 30904–30920, 2025
work page 2025
-
[10]
Brown, Dawn Song, Úlfar Erlingsson, et al
Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-V oss, Katherine Lee, Adam Roberts, Tom B. Brown, Dawn Song, Úlfar Erlingsson, et al. Extracting training data from large language models. In30th USENIX Security Symposium (USENIX Security 21), pages 2633–2650, 2021
work page 2021
-
[11]
The economics of privacy.Journal of Economic Literature, 54(2):442–492, 2016
Alessandro Acquisti, Curtis Taylor, and Liad Wagman. The economics of privacy.Journal of Economic Literature, 54(2):442–492, 2016
work page 2016
-
[12]
Daron Acemoglu, Ali Makhdoumi, Azarakhsh Malekian, and Asu Ozdaglar. Too much data: Prices and inefficiencies in data markets.American Economic Journal: Microeconomics, 14(4):218–256, 2022
work page 2022
-
[13]
Mark Bagnoli and Michael McKee. V oluntary contribution games: Efficient private provision of public goods.Economic Inquiry, 29(2):351–366, 1991
work page 1991
-
[14]
Leslie M Marx and Steven A Matthews. Dynamic voluntary contribution to a public project.The Review of Economic Studies, 67(2):327–358, 2000
work page 2000
-
[15]
Collective action: fifty years later.Public Choice, 164:195–216, 2015
Todd Sandler. Collective action: fifty years later.Public Choice, 164:195–216, 2015
work page 2015
-
[16]
Antonio A. Ginart, Melody Y . Guan, Gregory Valiant, and James Zou. Making ai forget you: Data deletion in machine learning.Advances in Neural Information Processing Systems, 32:3518–3531, 2019
work page 2019
- [17]
-
[18]
The economics of social data.The RAND Journal of Economics, 53(2):263–296, 2022
Dirk Bergemann, Alessandro Bonatti, and Tan Gan. The economics of social data.The RAND Journal of Economics, 53(2):263–296, 2022
work page 2022
-
[19]
A survey on data markets.arXiv preprint arXiv:2411.07267, 2024
Jun Zhang, Yuxin Bi, Meng Cheng, and Qiang Yang. A survey on data markets.arXiv preprint arXiv:2411.07267, 2024
-
[20]
Rotello, and Sai Praneeth Karimireddy
Dongyang Fan, Tyler J. Rotello, and Sai Praneeth Karimireddy. Do data valuations make good data prices? arXiv preprint arXiv:2504.05563, 2025
-
[21]
Sequential contributions to public goods.Journal of Public Economics, 53(2):165–186, 1994
Hal R Varian. Sequential contributions to public goods.Journal of Public Economics, 53(2):165–186, 1994
work page 1994
-
[22]
Parimal Kanti Bag and Santanu Roy. On sequential and simultaneous contributions under incomplete information.International Journal of Game Theory, 40(1):119–145, 2011
work page 2011
-
[23]
T. R. Palfrey and H. Rosenthal. Participation and the provision of discrete public goods: a strategic analysis. Journal of Public Economics, 24(2):171–193, 1984
work page 1984
-
[24]
R. T. A. Croson and M. B. Marks. Step returns in threshold public goods: A meta-and experimental analysis.Experimental Economics, 2(3):239–259, 2000
work page 2000
-
[25]
John B. Van Huyck, Raymond C. Battalio, and Richard O. Beil. Tacit coordination games, strategic uncertainty, and coordination failure.The American Economic Review, 80(1):234–248, 1990
work page 1990
-
[26]
Hoang, and Bryan Kian Hsiang Low
Rachael Hwee Ling Sim, Yehong Zhang, N. Hoang, and Bryan Kian Hsiang Low. Incentives in private collaborative machine learning.Advances in Neural Information Processing Systems, 36:7555–7593, 2023
work page 2023
-
[27]
Esther Schuch, Tum Nhim, and Andries Richter. Coordinating on good and bad outcomes in threshold games–evidence from an artefactual field experiment in cambodia.Ecological Economics, 232:108547, 2025
work page 2025
-
[28]
A. Baranski, E. Reuben, and A. Riedl. The role of fairness ideals in coordination failure and success. CESifo Working Paper No. 12195, 2025. 11 NeurIPS Paper Checklist 1.Claims Question: Do the main claims made in the abstract and introduction accurately reflect the paper’s contributions and scope? Answer: [Yes]. Justification: The abstract and introducti...
work page 2025
-
[29]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants and whether IRB approvals were obtained? Answer: [N/A]. Justification: The paper does not involve human subjects, so IRB approval is not applicable. 16.Declaration of LLM usage Question:...
work page 2005
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.