Recognition: 2 theorem links
· Lean TheoremTowards Photorealistic and Efficient Bokeh Rendering via Diffusion Framework
Pith reviewed 2026-05-12 03:00 UTC · model grok-4.3
The pith
A diffusion model jointly renders photorealistic bokeh and upsamples low-resolution images using masked attention and alternative training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
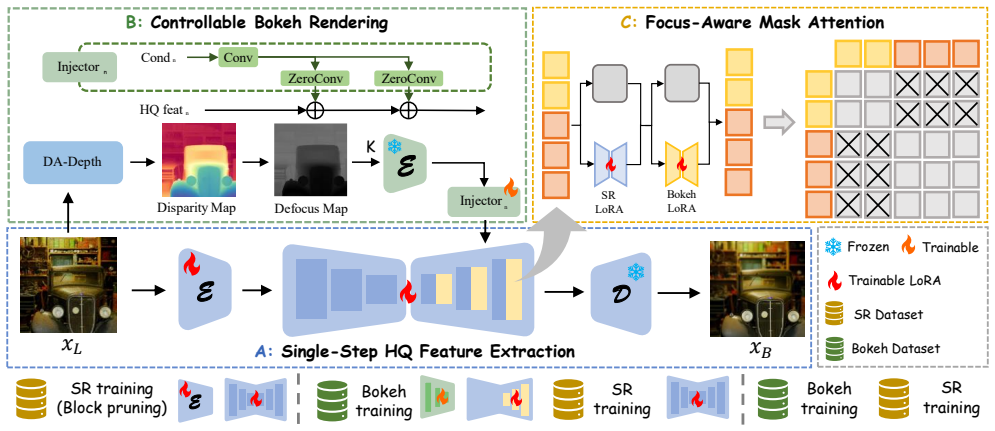
MagicBokeh is a unified diffusion-based framework that jointly optimizes bokeh rendering and super-resolution through an alternative training strategy and a focus-aware masked attention mechanism, while a degradation-aware depth module produces accurate depth from low-quality inputs, enabling efficient photorealistic bokeh on real-world low-resolution images.
What carries the argument
Focus-aware masked attention inside a diffusion model, paired with alternative training, that simultaneously controls focus preservation, background blur synthesis, and resolution recovery.
If this is right
- Bokeh rendering on mobile devices becomes a single efficient pass instead of a cascaded pipeline.
- High-zoom photos retain fine subject detail while receiving optically plausible background blur.
- Depth maps estimated from low-quality inputs become reliable enough to support other depth-dependent edits.
- Error accumulation between separate enhancement and rendering stages is avoided.
Where Pith is reading between the lines
- Diffusion models with region-specific masking may generalize to other paired tasks such as joint denoising and style transfer.
- The degradation-aware depth module could be tested on additional low-quality regimes like night scenes or heavy compression to check broader utility.
- Unified frameworks of this kind might eventually allow computational compensation for even smaller camera apertures in future hardware designs.
Load-bearing premise
The alternative training strategy and masked attention allow joint bokeh and super-resolution optimization without introducing new error accumulation or inaccurate depth estimates from degraded inputs.
What would settle it
Side-by-side perceptual and depth-accuracy tests on a held-out set of real high-zoom low-resolution photos comparing the single-stage output against a high-quality two-stage pipeline that first upsamples then renders bokeh.
Figures





read the original abstract
Existing mobile devices are constrained by compact optical designs, such as small apertures, which make it difficult to produce natural, optically realistic bokeh effects. Although recent learning-based methods have shown promising results, they still struggle with photos captured under high digital zoom levels, which often suffer from reduced resolution and loss of fine details. A naive solution is to enhance image quality before applying bokeh rendering, yet this two-stage pipeline reduces efficiency and introduces unnecessary error accumulation. To overcome these limitations, we propose MagicBokeh, a unified diffusion-based framework designed for high-quality and efficient bokeh rendering. Through an alternative training strategy and a focus-aware masked attention mechanism, our method jointly optimizes bokeh rendering and super-resolution, substantially improving both controllability and visual fidelity. Furthermore, we introduce degradation-aware depth module to enable more accurate depth estimation from low-quality inputs. Experimental results demonstrate that MagicBokeh efficiently produces photorealistic bokeh effects, particularly on real-world low-resolution images, paving the way for future advancements in bokeh rendering. Our code and models are available at https://github.com/vivoCameraResearch/MagicBokeh.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MagicBokeh, a unified diffusion-based framework for photorealistic bokeh rendering on low-resolution mobile images. It jointly optimizes bokeh rendering and super-resolution via an alternative training strategy and focus-aware masked attention mechanism, while introducing a degradation-aware depth module to improve depth estimation from degraded inputs, thereby avoiding error accumulation from separate enhancement and rendering stages.
Significance. If the experimental claims hold, the work offers a practical advance in computational photography by demonstrating efficient joint task optimization in diffusion models for real-world low-quality inputs, with potential impact on mobile device imaging pipelines. The public release of code and models supports reproducibility and further research.
minor comments (3)
- Abstract: The summary of experimental results mentions efficiency and photorealism on low-res images but omits any quantitative metrics, baseline comparisons, or ablation highlights; adding a brief quantitative statement would improve the abstract's informativeness without altering length substantially.
- Method section (architecture description): The focus-aware masked attention and degradation-aware depth module are introduced with diagrams and equations, but the precise formulation of the masked attention (e.g., how focus maps modulate the attention weights) could be expanded with a short pseudocode snippet for clarity.
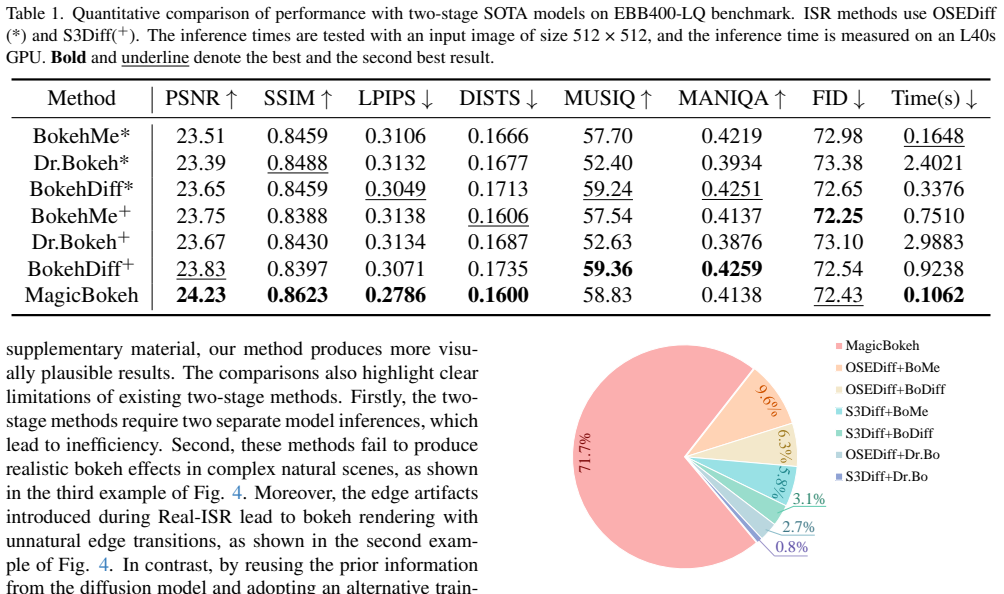
- Experiments: While comparisons to prior bokeh methods are presented, the paper would benefit from an explicit table summarizing runtime (e.g., FPS on standard hardware) alongside quality metrics to directly substantiate the efficiency claim.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our manuscript and for recommending minor revision. We appreciate the recognition of the practical contributions of MagicBokeh for efficient, photorealistic bokeh rendering on low-resolution mobile images.
Circularity Check
No significant circularity detected
full rationale
The paper proposes a new diffusion framework (MagicBokeh) with three explicitly described novel components: an alternative training strategy, focus-aware masked attention, and a degradation-aware depth module. These are introduced as architectural and procedural innovations to enable joint bokeh rendering and super-resolution without two-stage error accumulation. The central claims rest on these new elements plus experimental validation on external real-world low-resolution images, not on any reduction of outputs to fitted inputs, self-definitions, or load-bearing self-citations. No equations or derivations in the provided text equate predictions to their own training data by construction; the method is presented as an independent proposal whose performance is measured against baselines.
Axiom & Free-Parameter Ledger
free parameters (1)
- Diffusion process hyperparameters
axioms (1)
- domain assumption Diffusion models can be effectively conditioned for joint image-to-image tasks such as bokeh rendering and super-resolution.
invented entities (2)
-
Focus-aware masked attention mechanism
no independent evidence
-
Degradation-aware depth module
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearalternative training strategy and a focus-aware masked attention mechanism... degradation-aware depth module
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanreality_from_one_distinction unclearsingle-step diffusion framework... block pruning... LoRA
Reference graph
Works this paper leans on
-
[1]
Dc2: Dual-camera defocus control by learning to refocus
Hadi Alzayer, Abdullah Abuolaim, Leung Chun Chan, Yang Yang, Ying Chen Lou, Jia-Bin Huang, and Abhishek Kar. Dc2: Dual-camera defocus control by learning to refocus. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21488–21497, 2023. 2
work page 2023
-
[2]
Fast bilateral-space stereo for synthetic de- focus
Jonathan T Barron, Andrew Adams, YiChang Shih, and Car- los Hern´andez. Fast bilateral-space stereo for synthetic de- focus. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4466–4474, 2015. 3
work page 2015
-
[3]
Real-time, accurate depth of field using anisotropic diffusion and programmable graphics cards
Marcelo Bertalmio, Pere Fort, and Daniel Sanchez-Crespo. Real-time, accurate depth of field using anisotropic diffusion and programmable graphics cards. InProceedings. 2nd In- ternational Symposium on 3D Data Processing, Visualiza- tion and Transmission, 2004. 3DPVT 2004., pages 767–773. IEEE, 2004
work page 2004
-
[4]
Sterefo: Efficient image refocusing with stereo vision
Benjamin Busam, Matthieu Hog, Steven McDonagh, and Gregory Slabaugh. Sterefo: Efficient image refocusing with stereo vision. InProceedings of the IEEE/CVF international conference on computer vision workshops, pages 0–0, 2019. 3
work page 2019
-
[5]
Toward real-world single image super-resolution: A new benchmark and a new model
Jianrui Cai, Hui Zeng, Hongwei Yong, Zisheng Cao, and Lei Zhang. Toward real-world single image super-resolution: A new benchmark and a new model. InProceedings of the IEEE/CVF international conference on computer vision, pages 3086–3095, 2019. 10
work page 2019
-
[6]
Keyan Ding, Kede Ma, Shiqi Wang, and Eero P Simoncelli. Image quality assessment: Unifying structure and texture similarity.IEEE transactions on pattern analysis and ma- chine intelligence, 44(5):2567–2581, 2020. 5
work page 2020
-
[7]
Dave Epstein, Allan Jabri, Ben Poole, Alexei Efros, and Aleksander Holynski. Diffusion self-guidance for control- lable image generation.Advances in Neural Information Processing Systems, 36:16222–16239, 2023. 4
work page 2023
-
[8]
Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The kitti dataset.The in- ternational journal of robotics research, 32(11):1231–1237,
-
[9]
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilib- rium.Advances in neural information processing systems, 30, 2017. 5
work page 2017
-
[10]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 2, 3
work page 2020
-
[11]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022. 3
work page 2022
-
[12]
Sdmatte: Grafting diffusion models for interactive matting
Longfei Huang, Yu Liang, Hao Zhang, Jinwei Chen, Wei Dong, Lunde Chen, Wanyu Liu, Bo Li, and Peng-Tao Jiang. Sdmatte: Grafting diffusion models for interactive matting. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15229–15239, 2025. 3
work page 2025
-
[13]
Rendering natural camera bokeh effect with deep learning
Andrey Ignatov, Jagruti Patel, and Radu Timofte. Rendering natural camera bokeh effect with deep learning. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 418–419, 2020. 2
work page 2020
-
[14]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 4401–4410, 2019. 5
work page 2019
-
[15]
Musiq: Multi-scale image quality transformer
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. Musiq: Multi-scale image quality transformer. InProceedings of the IEEE/CVF international conference on computer vision, pages 5148–5157, 2021. 5
work page 2021
-
[16]
Bk-sdm: Architecturally compressed stable diffusion for efficient text-to-image generation
Bo-Kyeong Kim, Hyoung-Kyu Song, Thibault Castells, and Shinkook Choi. Bk-sdm: Architecturally compressed stable diffusion for efficient text-to-image generation. InWorkshop on Efficient Systems for Foundation Models@ ICML2023,
-
[17]
Dense text-to-image generation with attention modulation
Yunji Kim, Jiyoung Lee, Jin-Hwa Kim, Jung-Woo Ha, and Jun-Yan Zhu. Dense text-to-image generation with attention modulation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 7701–7711, 2023. 4
work page 2023
-
[18]
Berg, Wan-Yen Lo, Piotr Doll ´ar, and Ross Girshick
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C. Berg, Wan-Yen Lo, Piotr Doll ´ar, and Ross Girshick. Segment anything, 2023. 9
work page 2023
-
[19]
Depth-of-field render- ing by pyramidal image processing
Martin Kraus and Magnus Strengert. Depth-of-field render- ing by pyramidal image processing. InComputer graphics forum, pages 645–654. Wiley Online Library, 2007. 2
work page 2007
-
[20]
Real- time lens blur effects and focus control.ACM Transactions on Graphics (TOG), 29(4):1–7, 2010
Sungkil Lee, Elmar Eisemann, and Hans-Peter Seidel. Real- time lens blur effects and focus control.ACM Transactions on Graphics (TOG), 29(4):1–7, 2010. 2
work page 2010
-
[21]
Deep automatic natural image matting.arXiv preprint arXiv:2107.07235,
Jizhizi Li, Jing Zhang, and Dacheng Tao. Deep automatic natural image matting.arXiv preprint arXiv:2107.07235,
-
[22]
Ruibin Li, Qihua Zhou, Song Guo, Jie Zhang, Jing- cai Guo, Xinyang Jiang, Yifei Shen, and Zhenhua Han. Dissecting arbitrary-scale super-resolution capability from pre-trained diffusion generative models.arXiv preprint arXiv:2306.00714, 2023. 3
-
[23]
Lsdir: A large scale dataset for image restoration
Yawei Li, Kai Zhang, Jingyun Liang, Jiezhang Cao, Ce Liu, Rui Gong, Yulun Zhang, Hao Tang, Yun Liu, Denis Deman- dolx, et al. Lsdir: A large scale dataset for image restoration. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1775–1787, 2023. 5
work page 2023
-
[24]
Real-time high-resolution background matting
Shanchuan Lin, Andrey Ryabtsev, Soumyadip Sengupta, Brian L Curless, Steven M Seitz, and Ira Kemelmacher- Shlizerman. Real-time high-resolution background matting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8762–8771, 2021. 9
work page 2021
-
[25]
Diff- bir: Toward blind image restoration with generative diffusion prior
Xinqi Lin, Jingwen He, Ziyan Chen, Zhaoyang Lyu, Bo Dai, Fanghua Yu, Yu Qiao, Wanli Ouyang, and Chao Dong. Diff- bir: Toward blind image restoration with generative diffusion prior. InEuropean Conference on Computer Vision, pages 430–448. Springer, 2024. 3
work page 2024
-
[26]
Brian B Moser, Arundhati S Shanbhag, Federico Raue, Stanislav Frolov, Sebastian Palacio, and Andreas Dengel. Diffusion models, image super-resolution, and everything: A 13 survey.IEEE Transactions on Neural Networks and Learn- ing Systems, 2024. 3
work page 2024
-
[27]
Bokehme: When neural rendering meets classical rendering
Juewen Peng, Zhiguo Cao, Xianrui Luo, Hao Lu, Ke Xian, and Jianming Zhang. Bokehme: When neural rendering meets classical rendering. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16283–16292, 2022. 3, 6
work page 2022
-
[28]
Mpib: An mpi-based bokeh ren- dering framework for realistic partial occlusion effects
Juewen Peng, Jianming Zhang, Xianrui Luo, Hao Lu, Ke Xian, and Zhiguo Cao. Mpib: An mpi-based bokeh ren- dering framework for realistic partial occlusion effects. In European Conference on Computer Vision, pages 590–607. Springer, 2022. 2, 3, 5, 9
work page 2022
-
[29]
Matt Pharr, Wenzel Jakob, and Greg Humphreys.Physi- cally based rendering: From theory to implementation. MIT Press, 2023. 3
work page 2023
-
[30]
Michael Potmesil and Indranil Chakravarty. A lens and aper- ture camera model for synthetic image generation.ACM SIGGRAPH Computer Graphics, 15(3):297–305, 1981. 3
work page 1981
-
[31]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 2, 3
work page 2022
-
[32]
Adversarial diffusion distillation
Axel Sauer, Dominik Lorenz, Andreas Blattmann, and Robin Rombach. Adversarial diffusion distillation. InEuropean Conference on Computer Vision, pages 87–103. Springer,
-
[33]
Efficient multi-lens bokeh ef- fect rendering and transformation
Tim Seizinger, Marcos V Conde, Manuel Kolmet, Tom E Bishop, and Radu Timofte. Efficient multi-lens bokeh ef- fect rendering and transformation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1633–1642, 2023. 3
work page 2023
-
[34]
Caglar Senaras, M Khalid Khan Niazi, Gerard Lozanski, and Metin N Gurcan. Deepfocus: detection of out-of-focus re- gions in whole slide digital images using deep learning.PloS one, 13(10):e0205387, 2018. 3
work page 2018
-
[35]
Yichen Sheng, Zixun Yu, Lu Ling, Zhiwen Cao, Xuaner Zhang, Xin Lu, Ke Xian, Haiting Lin, and Bedrich Benes. Dr. bokeh: differentiable occlusion-aware bokeh rendering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4515–4525, 2024. 2, 3, 5, 6, 9
work page 2024
-
[36]
Indoor segmentation and support inference from rgbd images
Nathan Silberman, Derek Hoiem, Pushmeet Kohli, and Rob Fergus. Indoor segmentation and support inference from rgbd images. InComputer Vision–ECCV 2012: 12th Eu- ropean Conference on Computer Vision, Florence, Italy, Oc- tober 7-13, 2012, Proceedings, Part V 12, pages 746–760. Springer, 2012. 9
work page 2012
-
[37]
Fourier depth of field.ACM Transac- tions on Graphics (TOG), 28(2):1–12, 2009
Cyril Soler, Kartic Subr, Fr ´edo Durand, Nicolas Holzschuch, and Franc ¸ois Sillion. Fourier depth of field.ACM Transac- tions on Graphics (TOG), 28(2):1–12, 2009. 3
work page 2009
-
[38]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020. 2
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[39]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Ab- hishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equa- tions.arXiv preprint arXiv:2011.13456, 2020. 2
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[40]
Synthetic depth-of-field with a single-camera mobile phone
Neal Wadhwa, Rahul Garg, David E Jacobs, Bryan E Feld- man, Nori Kanazawa, Robert Carroll, Yair Movshovitz- Attias, Jonathan T Barron, Yael Pritch, and Marc Levoy. Synthetic depth-of-field with a single-camera mobile phone. ACM Transactions on Graphics (ToG), 37(4):1–13, 2018. 2, 3
work page 2018
-
[41]
Ex- ploring clip for assessing the look and feel of images
Jianyi Wang, Kelvin CK Chan, and Chen Change Loy. Ex- ploring clip for assessing the look and feel of images. InPro- ceedings of the AAAI conference on artificial intelligence, pages 2555–2563, 2023. 5
work page 2023
-
[42]
Deeplens: Shallow depth of field from a single image.arXiv preprint arXiv:1810.08100, 2018
Lijun Wang, Xiaohui Shen, Jianming Zhang, Oliver Wang, Zhe Lin, Chih-Yao Hsieh, Sarah Kong, and Huchuan Lu. Deeplens: Shallow depth of field from a single image.arXiv preprint arXiv:1810.08100, 2018. 2
-
[43]
Real-esrgan: Training real-world blind super-resolution with pure synthetic data
Xintao Wang, Liangbin Xie, Chao Dong, and Ying Shan. Real-esrgan: Training real-world blind super-resolution with pure synthetic data. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 1905–1914,
work page 1905
-
[44]
Sinsr: diffusion-based image super- resolution in a single step
Yufei Wang, Wenhan Yang, Xinyuan Chen, Yaohui Wang, Lanqing Guo, Lap-Pui Chau, Ziwei Liu, Yu Qiao, Alex C Kot, and Bihan Wen. Sinsr: diffusion-based image super- resolution in a single step. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 25796–25805, 2024. 3
work page 2024
-
[45]
Yuan Wang, Yuhao Wan, Siming Zheng, Bo Li, Qibin Hou, and Peng-Tao Jiang. Trust but verify: Adaptive condi- tioning for reference-based diffusion super-resolution via implicit reference correlation modeling.arXiv preprint arXiv:2602.01864, 2026. 3
-
[46]
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Si- moncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004. 5
work page 2004
-
[47]
Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distilla- tion.Advances in Neural Information Processing Systems, 36:8406–8441, 2023. 3
work page 2023
-
[48]
Component divide- and-conquer for real-world image super-resolution
Pengxu Wei, Ziwei Xie, Hannan Lu, Zongyuan Zhan, Qixi- ang Ye, Wangmeng Zuo, and Liang Lin. Component divide- and-conquer for real-world image super-resolution. InCom- puter Vision–ECCV 2020: 16th European Conference, Glas- gow, UK, August 23–28, 2020, Proceedings, Part VIII 16, pages 101–117. Springer, 2020. 10
work page 2020
-
[49]
Rongyuan Wu, Lingchen Sun, Zhiyuan Ma, and Lei Zhang. One-step effective diffusion network for real-world image super-resolution.Advances in Neural Information Process- ing Systems, 37:92529–92553, 2024. 3, 5, 6
work page 2024
-
[50]
Seesr: Towards semantics- aware real-world image super-resolution
Rongyuan Wu, Tao Yang, Lingchen Sun, Zhengqiang Zhang, Shuai Li, and Lei Zhang. Seesr: Towards semantics- aware real-world image super-resolution. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 25456–25467, 2024. 5
work page 2024
-
[51]
Realism control one-step diffusion for real-world im- age super resolution
Zongliang Wu, Siming Zheng, Peng-Tao Jiang, and Xin Yuan. Realism control one-step diffusion for real-world im- age super resolution. InProceedings of the AAAI Conference on Artificial Intelligence, pages 10906–10914, 2026. 3 14
work page 2026
-
[52]
Rui Xie, Chen Zhao, Kai Zhang, Zhenyu Zhang, Jun Zhou, Jian Yang, and Ying Tai. Addsr: Accelerating diffusion- based blind super-resolution with adversarial diffusion dis- tillation.arXiv preprint arXiv:2404.01717, 2024. 3
-
[53]
Depth any- thing v2.Advances in Neural Information Processing Sys- tems, 37:21875–21911, 2024
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiao- gang Xu, Jiashi Feng, and Hengshuang Zhao. Depth any- thing v2.Advances in Neural Information Processing Sys- tems, 37:21875–21911, 2024. 2, 5, 6, 8
work page 2024
-
[54]
Maniqa: Multi-dimension attention network for no-reference image quality assessment
Sidi Yang, Tianhe Wu, Shuwei Shi, Shanshan Lao, Yuan Gong, Mingdeng Cao, Jiahao Wang, and Yujiu Yang. Maniqa: Multi-dimension attention network for no-reference image quality assessment. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1191–1200, 2022. 5
work page 2022
-
[55]
Yang Yang, Siming Zheng, Qirui Yang, Jinwei Chen, Boxi Wu, Xiaofei He, Deng Cai, Bo Li, and Peng-Tao Jiang. Any- to-bokeh: Arbitrary-subject video refocusing with video dif- fusion model.arXiv preprint arXiv:2505.21593, 2025. 3
-
[56]
Fanghua Yu, Jinjin Gu, Zheyuan Li, Jinfan Hu, Xiangtao Kong, Xintao Wang, Jingwen He, Yu Qiao, and Chao Dong. Scaling up to excellence: Practicing model scaling for photo- realistic image restoration in the wild. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 25669–25680, 2024. 3
work page 2024
-
[57]
Mask guided matting via progressive refinement network
Qihang Yu, Jianming Zhang, He Zhang, Yilin Wang, Zhe Lin, Ning Xu, Yutong Bai, and Alan Yuille. Mask guided matting via progressive refinement network. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1154–1163, 2021. 9
work page 2021
-
[58]
Zongsheng Yue and Chen Change Loy. Difface: Blind face restoration with diffused error contraction.IEEE Transac- tions on Pattern Analysis and Machine Intelligence, 2024. 3
work page 2024
-
[59]
arXiv preprint arXiv:2409.17058 (2024)
Aiping Zhang, Zongsheng Yue, Renjing Pei, Wenqi Ren, and Xiaochun Cao. Degradation-guided one-step im- age super-resolution with diffusion priors.arXiv preprint arXiv:2409.17058, 2024. 3, 5, 6
-
[60]
Lin Zhang, Lei Zhang, and Alan C Bovik. A feature-enriched completely blind image quality evaluator.IEEE Transactions on Image Processing, 24(8):2579–2591, 2015. 5
work page 2015
-
[61]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023. 3
work page 2023
-
[62]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shecht- man, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 586–595, 2018. 5
work page 2018
-
[63]
Xuaner Zhang, Kevin Matzen, Vivien Nguyen, Dillon Yao, You Zhang, and Ren Ng. Synthetic defocus and look- ahead autofocus for casual videography.arXiv preprint arXiv:1905.06326, 2019. 2, 3
-
[64]
Bokehdiff: Neural lens blur with one-step diffusion.arXiv preprint arXiv:2507.18060, 2025
Chengxuan Zhu, Qingnan Fan, Qi Zhang, Jinwei Chen, Huaqi Zhang, Chao Xu, and Boxin Shi. Bokehdiff: Neural lens blur with one-step diffusion.arXiv preprint arXiv:2507.18060, 2025. 3, 6 15
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.