Recognition: 2 theorem links
· Lean TheoremGRaSp: Automatic Example Optimization for In-Context Learning in Low-Data Tasks
Pith reviewed 2026-05-11 02:02 UTC · model grok-4.3
The pith
GRaSp uses clustering, dimensionality reduction, and genetic search with adaptive mutation to select better in-context examples than random choice.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GRaSp generates a candidate pool, structures it with clustering and dimensionality reduction, and runs a genetic algorithm equipped with a diversity-adaptive mutation operator that moves from broad inter-cluster exploration to intra-cluster refinement; on non-synthetic data this produces example sets that reach 45.84 percent micro-F1 on financial NER, exceeding both zero-shot and random few-shot baselines, while synthetic pools perform no better than random selection.
What carries the argument
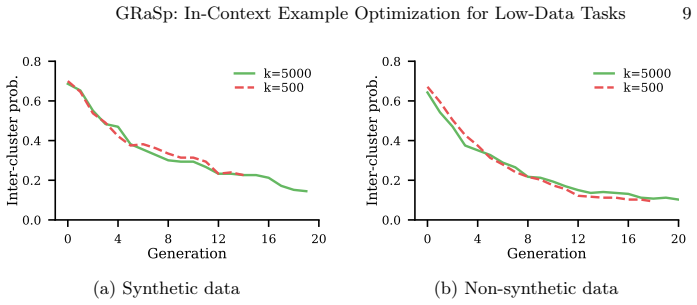
A genetic algorithm with custom diversity-adaptive mutation that operates on a candidate pool after it has been clustered and projected to lower dimensions.
If this is right
- Real distributional variety in the candidate pool is required for the optimization to exceed random baselines.
- The adaptive mutation enables an automatic shift from broad search across clusters to fine search within them as the population improves.
- The framework yields consistent gains over zero-shot and random few-shot on the evaluated NER task.
- Synthetic candidate pools alone are insufficient to realize the reported advantage.
Where Pith is reading between the lines
- The same three-stage process could be tested on other sequence-labeling or classification tasks where example quality matters.
- If the clustering step proves robust across domains, the method might lower the annotation cost needed to reach usable in-context performance.
- One could measure whether the discovered example sets remain effective when transferred to different language models without re-running the search.
Load-bearing premise
Clustering combined with dimensionality reduction on the candidate pool keeps enough task-relevant similarities intact for the genetic algorithm to locate example sets that generalize better than random selection.
What would settle it
Running the same evaluation on the identical non-synthetic pool and finding that random few-shot selection matches or exceeds GRaSp's micro-F1 score would show the optimization step adds no benefit.
Figures


read the original abstract
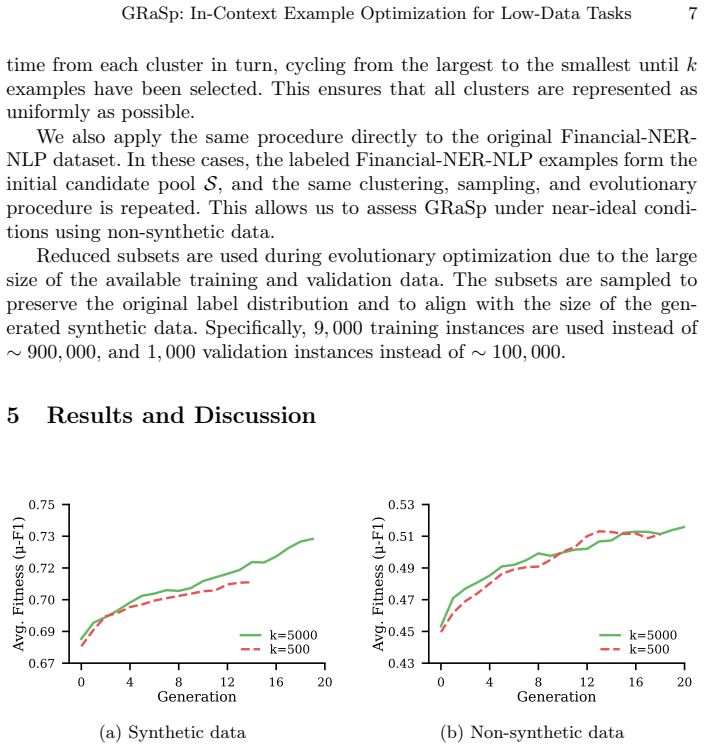
In-context learning enables large language models to adapt to new tasks, but their performance is highly sensitive to the selected examples. Finding effective demonstrations is particularly difficult in domain-specific, low-data settings where high-quality examples are scarce. We propose GRaSp, a three-stage framework for automatic in-context example optimization. By first generating a large synthetic candidate pool, then structuring it with clustering and dimensionality reduction, and finally using genetic algorithms to find the optimal in-context examples, the framework shows consistent improvements on the NER task. We also introduce a custom diversity-adaptive mutation mechanism, allowing it to transition from the initial broad inter-cluster exploration to focused intra-cluster refinement as the population converges. We evaluate GRaSp on financial named entity recognition (FiNER-139), comparing synthetic and human-annotated candidate pools across pool sizes of 500 and 5000. With non-synthetic data, GRaSp achieves 45.84% micro-F1, consistently outperforming both zero-shot and random few-shot baselines. Synthetic data matches the random baseline but does not exceed it, suggesting that distributional variety in the candidate pool is critical for generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GRaSp, a three-stage pipeline for optimizing in-context learning examples in low-data settings: (1) generation of a large synthetic candidate pool, (2) structuring via clustering and dimensionality reduction, and (3) search with a genetic algorithm that employs a custom diversity-adaptive mutation operator. On the financial NER task (FiNER-139), the method reports 45.84% micro-F1 using non-synthetic (human-annotated) pools, outperforming zero-shot and random few-shot baselines; synthetic pools yield performance indistinguishable from random selection. The authors conclude that distributional variety in the candidate pool is essential for the approach to generalize.
Significance. If the empirical claims are substantiated with full experimental protocols and ablations, GRaSp would demonstrate a practical, automated route to improving ICL performance when high-quality demonstrations are scarce. The contrast between synthetic and human-annotated pools supplies a concrete, falsifiable observation about the role of pool diversity. The custom mutation operator and the explicit three-stage decomposition are technically interesting contributions that could be adopted or extended in subsequent ICL work.
major comments (3)
- [Abstract] Abstract and evaluation section: the headline result of 45.84% micro-F1 is stated without any report of the number of independent runs, standard deviation, confidence intervals, or statistical tests against the zero-shot and random few-shot baselines. Because the central claim is an empirical performance improvement, the absence of these measures makes it impossible to judge whether the reported gain is reliable or reproducible.
- [Methods] Methods and evaluation: no ablation is presented that isolates the contribution of the genetic algorithm from the preceding clustering + dimensionality-reduction step. In particular, the performance of random selection within the same clustered pool is not reported; without this control it remains possible that any structured (non-random) selection would suffice and that the GA search itself adds no value.
- [Methods] Methods (clustering and dimensionality reduction): the framework assumes that generic embeddings followed by PCA/t-SNE/UMAP preserve distances that correlate with ICL utility (entity-context compatibility). No diagnostic is supplied—e.g., intra-cluster coherence metrics, correlation between embedding distance and downstream NER F1, or comparison of task-relevant vs. generic embeddings—to support this assumption. The synthetic-pool result (no gain over random) is consistent with the possibility that the reduced space collapses relevant distinctions.
minor comments (2)
- [Abstract] The abstract mentions experiments at pool sizes of 500 and 5000 but does not break down results or statistical comparisons by pool size; readers cannot tell whether the reported 45.84% holds uniformly or is driven by the larger pool.
- [Methods] The description of the diversity-adaptive mutation operator would benefit from a precise algorithmic listing (pseudocode or equations) rather than a high-level narrative, so that the transition from inter-cluster to intra-cluster exploration can be reproduced exactly.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on the empirical aspects of our work. We address each major comment below and will make the corresponding revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and evaluation section: the headline result of 45.84% micro-F1 is stated without any report of the number of independent runs, standard deviation, confidence intervals, or statistical tests against the zero-shot and random few-shot baselines. Because the central claim is an empirical performance improvement, the absence of these measures makes it impossible to judge whether the reported gain is reliable or reproducible.
Authors: We agree that reporting variability and statistical significance is crucial for validating the performance improvements. In the revised manuscript, we will include results from multiple independent runs with varying random seeds, providing mean micro-F1 scores along with standard deviations and confidence intervals. We will also perform and report appropriate statistical tests to compare GRaSp against the zero-shot and random few-shot baselines. revision: yes
-
Referee: [Methods] Methods and evaluation: no ablation is presented that isolates the contribution of the genetic algorithm from the preceding clustering + dimensionality-reduction step. In particular, the performance of random selection within the same clustered pool is not reported; without this control it remains possible that any structured (non-random) selection would suffice and that the GA search itself adds no value.
Authors: We concur that isolating the genetic algorithm's contribution is important. We will add an ablation study in the revised version that evaluates random selection from the structured (clustered and reduced) pool and compares it directly to the full GRaSp pipeline using the genetic algorithm. This will clarify the incremental benefit of the GA search. revision: yes
-
Referee: [Methods] Methods (clustering and dimensionality reduction): the framework assumes that generic embeddings followed by PCA/t-SNE/UMAP preserve distances that correlate with ICL utility (entity-context compatibility). No diagnostic is supplied—e.g., intra-cluster coherence metrics, correlation between embedding distance and downstream NER F1, or comparison of task-relevant vs. generic embeddings—to support this assumption. The synthetic-pool result (no gain over random) is consistent with the possibility that the reduced space collapses relevant distinctions.
Authors: We appreciate the call for supporting diagnostics on the embedding and dimensionality reduction steps. In the revision, we will provide intra-cluster coherence metrics, an analysis of the correlation between embedding distances and downstream ICL performance on the NER task, and a comparison between generic and task-adapted embeddings. These additions will strengthen the justification for our approach. We note that the observed difference between synthetic and human-annotated pools already suggests that pool diversity plays a key role, but the new analyses will address potential concerns about the reduced space. revision: yes
Circularity Check
No circularity: purely empirical evaluation on fixed benchmark
full rationale
The paper describes a procedural three-stage pipeline (synthetic pool generation, clustering+DR structuring, GA search with custom mutation) and reports measured micro-F1 on FiNER-139. The central result (45.84% with non-synthetic data) is an observed performance number against zero-shot and random baselines; no equation, prediction, or uniqueness claim reduces this number to a fitted parameter, self-citation, or input by construction. No self-definitional loops, fitted-input-as-prediction, or load-bearing self-citations appear in the provided text. The derivation chain is therefore self-contained experimental reporting.
Axiom & Free-Parameter Ledger
free parameters (2)
- GA hyperparameters (population size, generations, mutation rate, selection pressure)
- Number of clusters and target dimensionality after reduction
axioms (2)
- domain assumption Clustering and dimensionality reduction on the example pool preserve optimization-relevant similarities between examples.
- domain assumption Genetic algorithms equipped with the proposed adaptive mutation can locate higher-performing example sets than random sampling in the discrete selection space.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
three-stage framework... Generate... Reduce... Select... genetic algorithms... diversity-adaptive mutation... HDBSCAN... UMAP... micro-F1 on FiNER-139
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
GRaSp... clustering and dimensionality reduction... GA search with custom mutation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Natural Language Engineering30(5), 943–972 (2024)
Balkus, S., Yan, D.: Improving short text classification with augmented data using GPT-3. Natural Language Engineering30(5), 943–972 (2024). https://doi.org/10.1017/S1351324923000438
-
[2]
A survey on in-context learning
Dong, Q., Li, L., Dai, D., Zheng, C., Ma, J., Li, R., Xia, H., Xu, J., Wu, Z., Liu, T., Chang, B., Sun, X., Li, L., Sui, Z.: A survey on in-context learning. In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. pp. 1107–1128. Association for Computational Linguistics, Miami, Florida, USA (2024). https://doi.org/10.18...
-
[3]
In: Findings of the Association for Computational Linguistics: NAACL 2024
He, W., Liu, S., Zhao, J., Ding, Y., Lu, Y., Xi, Z., Gui, T., Zhang, Q., Huang, X.: Self-Demos: Eliciting out-of-demonstration generalizability in large language mod- els. In: Findings of the Association for Computational Linguistics: NAACL 2024. pp. 3829–3845. Association for Computational Linguistics, Mexico City, Mexico (2024). https://doi.org/10.18653...
-
[4]
In: Findings of the Association for Computational Linguistics: ACL- IJCNLP 2021
Kumar, S., Talukdar, P.: Reordering examples helps during priming-based few- shot learning. In: Findings of the Association for Computational Linguistics: ACL- IJCNLP 2021. pp. 4507–4518. Association for Computational Linguistics, Online (2021). https://doi.org/10.18653/v1/2021.findings-acl.395
-
[5]
In: Findings of the Association for Computational Linguistics: ACL 2024
Liu, H., Liu, J., Huang, S., Zhan, Y., Sun, H., Deng, W., Wei, F., Zhang, Q.: Se 2: Sequential example selection for in-context learning. In: Findings of the Association for Computational Linguistics: ACL 2024. pp. 5262–
work page 2024
-
[6]
https://doi.org/10.18653/v1/2024.findings-acl.312
Association for Computational Linguistics, Bangkok, Thailand (2024). https://doi.org/10.18653/v1/2024.findings-acl.312
-
[7]
Liu, J., Shen, D., Zhang, Y., Dolan, B., Carin, L., Chen, W.: What makes good in-context examples for GPT-3? In: Proceedings of Deep Learning Inside Out (Dee- LIO 2022): The 3rd Workshop on Knowledge Extraction and Integration for Deep Learning Architectures. pp. 100–114. Association for Computational Linguistics, Dublin, Ireland and Online (2022). https:...
-
[8]
Loukas, L., Fergadiotis, M., Chalkidis, I., Spyropoulou, E., Malakasiotis, P., An- droutsopoulos, I., Paliouras, G.: FiNER: Financial numeric entity recognition for XBRL tagging. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 4419–4431. Associa- tion for Computational Linguistics (2...
-
[9]
Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity
Lu, Y., Bartolo, M., Moore, A., Riedel, S., Stenetorp, P.: Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity. In: Proceedings of the 60th Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers). pp. 8086–8098. Association for Computational Linguistics, Dublin, Ireland (2022...
-
[10]
Sahoo, P., Singh, A.K., Saha, S., Jain, V., Chadha, A.: A systematic survey of prompt engineering in large language models: Techniques and applications (2024), arXiv:2402.07927
work page internal anchor Pith review arXiv 2024
-
[11]
Wu, S., Xie, J., Chen, J., Zhu, T., Zhang, K., Xiao, Y.: How easily do irrelevant inputs skew the responses of large language models? In: First Conference on Lan- guage Modeling (2024), https://openreview.net/forum?id=S7NVVfuRv8
work page 2024
-
[12]
In: Proceedings of the 38th International Conference on Machine Learning
Zhao, T.Z., Wallace, E., Feng, S., Klein, D., Singh, S.: Calibrate before use: Im- proving few-shot performance of language models. In: Proceedings of the 38th International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 139, pp. 12697–12706. PMLR (2021)
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.