Recognition: no theorem link
EditTransfer++: Toward Faithful and Efficient Visual-Prompt-Guided Image Editing
Pith reviewed 2026-05-11 01:55 UTC · model grok-4.3
The pith
EditTransfer++ trains diffusion models on visual example pairs alone by removing text conditioning and reshaping sampling to deliver more faithful and faster image edits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
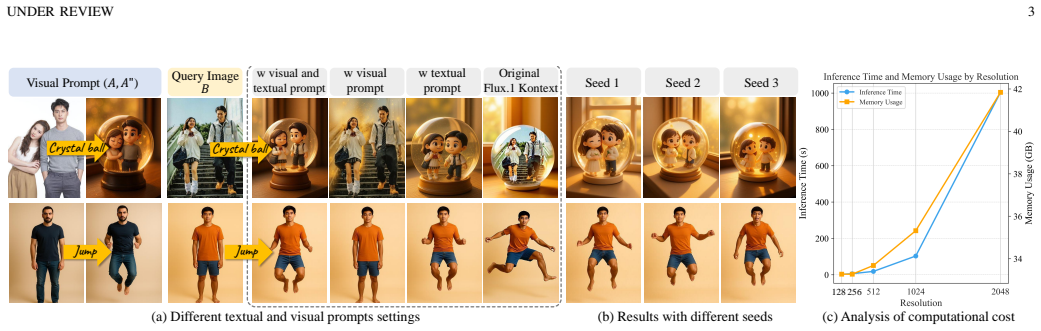
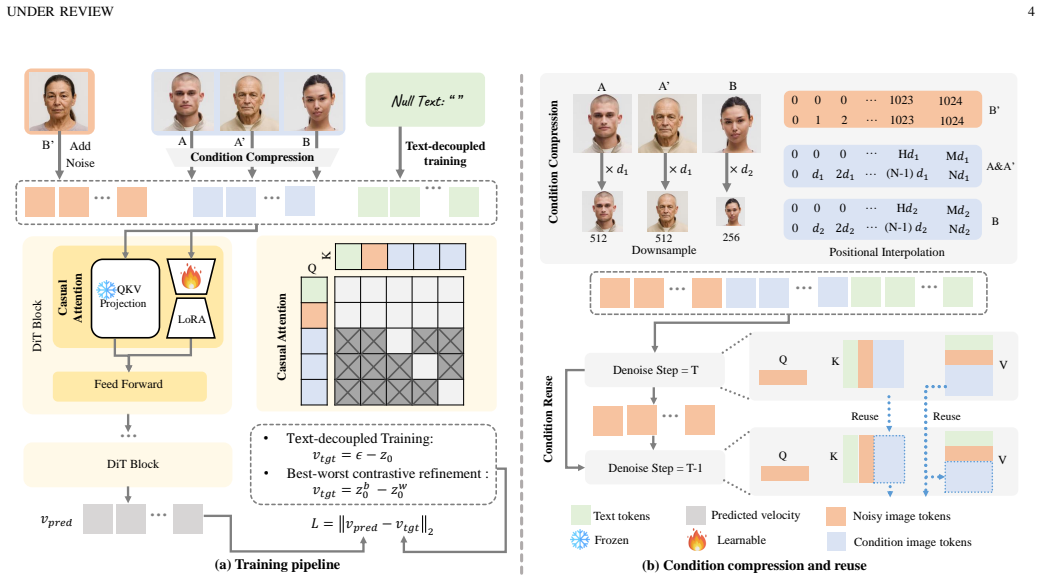
EditTransfer++ mitigates textual dominance through text-decoupled training that removes text conditioning during fine-tuning, compelling the model to infer transformations solely from visual evidence. On this visually grounded base, a best-worst contrastive refinement mechanism reshapes denoising trajectories to suppress unfaithful generations and improve seed-to-seed consistency. A condition compression and reuse strategy reduces token redundancy to support efficient 1024-pixel editing.
What carries the argument
Text-decoupled fine-tuning that removes text conditioning combined with best-worst contrastive refinement of denoising trajectories.
If this is right
- The model supports purely visual prompts at inference while still allowing optional text guidance.
- Denoising produces more consistent outputs across different random seeds.
- High-resolution images with a 1024-pixel long edge can be generated with reduced computation.
- Visual prompt faithfulness exceeds that of prior diffusion-transformer editing methods on existing benchmarks.
Where Pith is reading between the lines
- The same decoupling and compression steps could be tested on other token-heavy diffusion tasks such as video generation or multi-image in-context reasoning.
- Removing text bias during adaptation might reduce the data needed to teach new visual transformations compared with text-heavy fine-tuning.
- If the contrastive refinement generalizes, it offers a lightweight way to improve sampling stability in any conditional diffusion model.
Load-bearing premise
Removing text during fine-tuning will make the model learn the intended visual transformations from example pairs without losing necessary capabilities, and contrastive selection will reliably steer sampling away from unfaithful results.
What would settle it
Generate edited images on held-out visual prompt pairs from EditTransfer-Bench where the output fails to reproduce the demonstrated transformation despite clear visual examples, or measure that inference time for 1024-pixel images does not decrease while faithfulness scores remain unchanged.
Figures












read the original abstract
Visual-prompt-guided edit transfer aims to learn image transformations directly from example pairs, offering more precise and controllable editing than purely text-driven approaches. However, existing diffusion transformer-based methods often fail to faithfully reproduce the demonstrated edits due to structural mismatches between the task and the backbone, including a pretrained bias toward textual conditioning and inherent stochastic instability during sampling. To bridge this gap, we present EditTransfer++, a framework that combines progressively structured training with an efficient conditioning scheme to improve both visual prompt faithfulness and inference efficiency. We first mitigate textual dominance with a text-decoupled training strategy that removes text conditioning during fine-tuning, compelling the model to infer transformations solely from visual evidence while still supporting optional text guidance at inference. On top of this visually grounded model, a best-worst contrastive refinement mechanism reshapes the denoising trajectories to suppress unfaithful generations and improve consistency across random seeds. To alleviate the computational bottleneck of high-resolution in-context editing, we further introduce a condition compression and reuse strategy that reduces token redundancy and enables efficient generation of images with a 1024-pixel long edge. Extensive experiments on existing benchmarks and the proposed EditTransfer-Bench show that EditTransfer++ achieves state-of-the-art visual prompt faithfulness with substantially faster inference than prior methods, suggesting a promising direction for scalable prompt-guided image editing and broader visual in-context learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EditTransfer++, a diffusion-transformer framework for visual-prompt-guided image editing. It uses text-decoupled fine-tuning to reduce pretrained textual bias and force learning from visual example pairs, a best-worst contrastive refinement step to reshape denoising trajectories toward more faithful outputs, and a condition-compression/reuse strategy to enable efficient 1024-pixel inference. Experiments on existing benchmarks plus the new EditTransfer-Bench report state-of-the-art visual-prompt faithfulness together with substantially faster inference than prior methods.
Significance. If the empirical gains are robust, the work would represent a meaningful engineering advance in controllable, text-light image editing and visual in-context learning. The combination of bias-mitigation training, trajectory reshaping, and token compression directly targets two practical bottlenecks (faithfulness and speed) that have limited deployment of prompt-guided editing at high resolution.
major comments (3)
- [Methods (contrastive refinement)] Methods section on best-worst contrastive refinement: the manuscript describes the mechanism at a high level but supplies neither a derivation showing how the contrastive loss alters the reverse-process distribution nor an analysis of its effect on trajectory diversity versus faithfulness. This is load-bearing for the central claim that the reported faithfulness gains on EditTransfer-Bench can be attributed to the proposed refinement rather than to other training choices.
- [Training strategy] Training-strategy subsection on text-decoupled fine-tuning: the claim that removing text conditioning 'compels the model to infer transformations solely from visual evidence' is not accompanied by any measurement of capability loss or of how optional text is safely re-introduced at inference without reintroducing textual dominance. Both points are required to justify the faithfulness improvements.
- [Experiments] Experimental section and tables: the abstract asserts SOTA faithfulness and speed, yet the provided text contains no quantitative tables, ablation studies, or error analysis that would allow verification of the magnitude of the gains or isolation of each component's contribution.
minor comments (2)
- [Abstract / Introduction] The abstract refers to 'progressively structured training' and 'efficient conditioning scheme' without defining these terms; a short paragraph or diagram in the introduction would improve readability.
- [Condition compression] Notation for the condition-compression module is introduced without an accompanying equation or pseudocode; adding a compact formulation would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. We address each major comment point by point below. Where the comments identify areas needing additional detail or clarification, we will revise the manuscript accordingly to strengthen the presentation of our contributions.
read point-by-point responses
-
Referee: [Methods (contrastive refinement)] Methods section on best-worst contrastive refinement: the manuscript describes the mechanism at a high level but supplies neither a derivation showing how the contrastive loss alters the reverse-process distribution nor an analysis of its effect on trajectory diversity versus faithfulness. This is load-bearing for the central claim that the reported faithfulness gains on EditTransfer-Bench can be attributed to the proposed refinement rather than to other training choices.
Authors: We agree that a more rigorous derivation and analysis would better substantiate the role of the contrastive refinement. In the revised manuscript we will add a derivation showing how the best-worst contrastive loss modifies the reverse-process distribution, together with quantitative analysis of its effects on trajectory diversity and faithfulness. These additions will help isolate the refinement's contribution from other training choices. revision: yes
-
Referee: [Training strategy] Training-strategy subsection on text-decoupled fine-tuning: the claim that removing text conditioning 'compels the model to infer transformations solely from visual evidence' is not accompanied by any measurement of capability loss or of how optional text is safely re-introduced at inference without reintroducing textual dominance. Both points are required to justify the faithfulness improvements.
Authors: We acknowledge the need for explicit measurements. The revised version will include new experiments quantifying any capability loss from text-decoupled fine-tuning and will demonstrate, via controlled ablations, how optional text guidance can be re-introduced at inference time without restoring textual dominance. These results will be presented alongside the existing faithfulness metrics. revision: yes
-
Referee: [Experiments] Experimental section and tables: the abstract asserts SOTA faithfulness and speed, yet the provided text contains no quantitative tables, ablation studies, or error analysis that would allow verification of the magnitude of the gains or isolation of each component's contribution.
Authors: The full manuscript contains quantitative tables (Tables 1–3), component ablations (Section 4.3), and error analysis (supplementary material). To improve accessibility, we will expand the main experimental section with additional summary tables and a dedicated ablation table that isolates each component's contribution, ensuring all key results are directly verifiable in the primary text. revision: partial
Circularity Check
No circularity: empirical engineering contribution without self-referential derivations or fitted predictions.
full rationale
The paper describes a practical framework combining text-decoupled fine-tuning, best-worst contrastive refinement, and condition compression for visual-prompt-guided editing. No equations, derivations, or parameter-fitting steps are presented that reduce the claimed faithfulness or efficiency gains to quantities defined by the same inputs or self-citations. The abstract and skeptic summary frame the work as an empirical method relying on experimental benchmarks rather than mathematical self-definition or uniqueness theorems imported from prior author work. Central assumptions about overriding text bias and reshaping denoising trajectories are stated as design choices validated by results, not as closed loops where outputs equal inputs by construction. This is a standard non-circular empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Prompt-to-prompt image editing with cross attention control,
A. Hertz, R. Mokady, J. Tenenbaum, K. Aberman, Y . Pritch, and D. Cohen-Or, “Prompt-to-prompt image editing with cross attention control,” inICLR, 2023
work page 2023
-
[2]
Masactrl: Tuning-free mutual self-attention control for consistent image synthesis and editing,
M. Cao, X. Wang, Z. Qi, Y . Shan, X. Qie, and Y . Zheng, “Masactrl: Tuning-free mutual self-attention control for consistent image synthesis and editing,” inICCV, 2023
work page 2023
-
[3]
Instructpix2pix: Learning to follow image editing instructions,
T. Brooks, A. Holynski, and A. A. Efros, “Instructpix2pix: Learning to follow image editing instructions,” inCVPR, 2023
work page 2023
-
[4]
Z. Zhang, J. Xie, Y . Lu, Z. Yang, and Y . Yang, “In-context edit: Enabling instructional image editing with in-context generation in large scale diffusion transformer,” inNeurIPS, 2025
work page 2025
-
[5]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
B. F. Labs, S. Batifol, A. Blattmann, F. Boesel, S. Consul, C. Diagne, T. Dockhorn, J. English, Z. English, P. Esseret al., “Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space,”arXiv preprint arXiv:2506.15742, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Visual prompting via image inpainting,
A. Bar, Y . Gandelsman, T. Darrell, A. Globerson, and A. A. Efros, “Visual prompting via image inpainting,” inNeurIPS, 2022
work page 2022
-
[7]
Images speak in images: A generalist painter for in-context visual learning,
X. Wang, W. Wang, Y . Cao, C. Shen, and T. Huang, “Images speak in images: A generalist painter for in-context visual learning,” inCVPR, 2023. UNDER REVIEW 13
work page 2023
-
[8]
Imagebrush: Learning visual in-context instructions for exemplar-based image manipulation,
Y . Yang, H. Peng, Y . Shen, Y . Yang, H. Hu, L. Qiu, H. Koikeet al., “Imagebrush: Learning visual in-context instructions for exemplar-based image manipulation,” inNeurIPS, 2023
work page 2023
-
[9]
Edit transfer: Learning image editing via vision in-context relations,
L. Chen, Q. Mao, Y . Gu, and M. Z. Shou, “Edit transfer: Learning image editing via vision in-context relations,”arXiv preprint arXiv:2503.13327, 2025
-
[10]
Visualcloze: A universal image generation framework via visual in-context learning,
Z.-Y . Li, R. Du, J. Yan, L. Zhuo, Z. Li, P. Gao, Z. Ma, and M.-M. Cheng, “Visualcloze: A universal image generation framework via visual in-context learning,” inICCV, 2025
work page 2025
-
[11]
Relationadapter: Learning and transferring visual relation with diffusion transformers,
Y . Gong, Y . Song, Y . Li, C. Li, and Y . Zhang, “Relationadapter: Learning and transferring visual relation with diffusion transformers,” inNeurIPS, 2025
work page 2025
-
[12]
Pairedit: Learning semantic variations for exemplar-based image editing,
H. Lu, J. Chen, Z. Yang, A. T. Gnanha, F. L. Wang, L. Qing, and X. Mao, “Pairedit: Learning semantic variations for exemplar-based image editing,” inNeurIPS, 2025
work page 2025
-
[13]
Personalized vision via visual in-context learning,
Y . Jiang, Y . Gu, Y . Song, I. Tsang, and M. Z. Shou, “Personalized vision via visual in-context learning,”arXiv preprint arXiv:2509.25172, 2025
-
[14]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers,” inICCV, 2023
work page 2023
-
[15]
Multi-modality cross attention network for image and sentence matching,
X. Wei, T. Zhang, Y . Li, Y . Zhang, and F. Wu, “Multi-modality cross attention network for image and sentence matching,” inCVPR, 2020
work page 2020
-
[16]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” inNeurIPS, 2020
work page 2020
-
[17]
Denoising diffusion implicit models,
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” inICLR, 2021
work page 2021
-
[18]
Dreambooth: Fine tuning text-to-image diffusion models for subject- driven generation,
N. Ruiz, Y . Li, V . Jampani, Y . Pritch, M. Rubinstein, and K. Aberman, “Dreambooth: Fine tuning text-to-image diffusion models for subject- driven generation,” inCVPR, 2023
work page 2023
-
[19]
Processpainter: Learning to draw from sequence data,
Y . Song, S. Huang, C. Yao, H. Ci, X. Ye, J. Liu, Y . Zhang, and M. Z. Shou, “Processpainter: Learning to draw from sequence data,” inSIGGRAPH Asia, 2024
work page 2024
-
[20]
Stable-hair: Real-world hair transfer via diffusion model,
Y . Zhang, Q. Zhang, Y . Song, J. Zhang, H. Tang, and J. Liu, “Stable-hair: Real-world hair transfer via diffusion model,” inAAAI, 2025
work page 2025
-
[21]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” inCVPR, 2022
work page 2022
-
[22]
In-context lora for diffusion transformers.arXiv preprint arXiv:2410.23775, 2024a
L. Huang, W. Wang, Z.-F. Wu, Y . Shi, H. Dou, C. Liang, Y . Feng, Y . Liu, and J. Zhou, “In-context lora for diffusion transformers,”arXiv preprint arXiv:2410.23775, 2024
-
[23]
Ominicontrol: Minimal and universal control for diffusion transformer,
Z. Tan, S. Liu, X. Yang, Q. Xue, and X. Wang, “Ominicontrol: Minimal and universal control for diffusion transformer,” inICCV, 2024
work page 2024
-
[24]
Easycontrol: Adding efficient and flexible control for diffusion transformer,
Y . Zhang, Y . Yuan, Y . Song, H. Wang, and J. Liu, “Easycontrol: Adding efficient and flexible control for diffusion transformer,” inICCV, 2025
work page 2025
-
[25]
Omniconsistency: Learning style- agnostic consistency from paired stylization data,
Y . Song, C. Liu, and M. Z. Shou, “Omniconsistency: Learning style- agnostic consistency from paired stylization data,” inNeurIPS, 2025
work page 2025
-
[26]
Y . Song, C. Liu, and M. Z. Shou, “Makeanything: Harnessing diffusion transformers for multi-domain procedural sequence generation,”arXiv preprint arXiv:2502.01572, 2025
-
[27]
Photodoodle: Learning artistic image editing from few-shot pairwise data,
S. Huang, Y . Song, Y . Zhang, H. Guo, X. Wang, M. Z. Shou, and J. Liu, “Photodoodle: Learning artistic image editing from few-shot pairwise data,” inICCV, 2025
work page 2025
-
[28]
Taming rectified flow for inversion and editing,
J. Wang, J. Pu, Z. Qi, J. Guo, Y . Ma, N. Huang, Y . Chen, X. Li, and Y . Shan, “Taming rectified flow for inversion and editing,” inICML, 2023
work page 2023
-
[29]
Stable flow: Vital layers for training- free image editing,
O. Avrahami, O. Patashnik, O. Fried, E. Nemchinov, K. Aberman, D. Lischinski, and D. Cohen-Or, “Stable flow: Vital layers for training- free image editing,” inCVPR, 2025
work page 2025
-
[30]
Dit4edit: Diffusion transformer for image editing,
K. Feng, Y . Ma, B. Wang, C. Qi, H. Chen, Q. Chen, and Z. Wang, “Dit4edit: Diffusion transformer for image editing,” inAAAI, 2025
work page 2025
-
[31]
Instruction-driven multi-weather image translation based on a large-scale image editing model,
Y . Feng, J. Li, and M. Zhou, “Instruction-driven multi-weather image translation based on a large-scale image editing model,”IEEE TIP, 2025
work page 2025
-
[32]
Consistent image layout editing with diffusion models,
T. Xia, Y . Zhang, T. Liu, and L. Zhang, “Consistent image layout editing with diffusion models,”IEEE TIP, 2025
work page 2025
-
[33]
Magicbrush: A manually annotated dataset for instruction-guided image editing,
K. Zhang, L. Mo, W. Chen, H. Sun, and Y . Su, “Magicbrush: A manually annotated dataset for instruction-guided image editing,” inNeurIPS, 2023
work page 2023
-
[34]
Hive: Harnessing human feedback for instructional visual editing,
S. Zhang, X. Yang, Y . Feng, C. Qin, C.-C. Chen, N. Yu, Z. Chen, H. Wang, S. Savarese, S. Ermonet al., “Hive: Harnessing human feedback for instructional visual editing,” inCVPR, 2024
work page 2024
-
[35]
Image style transfer using convolutional neural networks,
L. A. Gatys, A. S. Ecker, and M. Bethge, “Image style transfer using convolutional neural networks,” inCVPR, 2016
work page 2016
-
[36]
Cross-image attention for zero-shot appearance transfer,
Y . Alaluf, D. Garibi, O. Patashnik, H. Averbuch-Elor, and D. Cohen- Or, “Cross-image attention for zero-shot appearance transfer,” inSIG- GRAPH, 2024
work page 2024
-
[37]
Unpaired image-to-image translation using cycle-consistent adversarial networks,
J.-Y . Zhu, T. Park, P. Isola, and A. A. Efros, “Unpaired image-to-image translation using cycle-consistent adversarial networks,” inICCV, 2017
work page 2017
-
[38]
Attention distillation: A unified approach to visual characteristics transfer,
Y . Zhou, X. Gao, Z. Chen, and H. Huang, “Attention distillation: A unified approach to visual characteristics transfer,” inCVPR, 2025
work page 2025
-
[39]
Rego: Reference- guided outpainting for scenery image,
Y . Wang, Y . Wei, X. Qian, L. Zhu, and Y . Yang, “Rego: Reference- guided outpainting for scenery image,”IEEE TIP, 2024
work page 2024
-
[40]
Consistent image inpainting with pre-perception and cross-perception collaborative processes,
Y . Zhang, Y . Liu, H. Fan, R. Hu, J. Zhang, and Q. Wu, “Consistent image inpainting with pre-perception and cross-perception collaborative processes,”IEEE Transactions on Image Processing, 2025
work page 2025
-
[41]
Anydoor: Zero-shot object-level image customization,
X. Chen, L. Huang, Y . Liu, Y . Shen, D. Zhao, and H. Zhao, “Anydoor: Zero-shot object-level image customization,” inCVPR, 2024
work page 2024
-
[42]
Paint by example: Exemplar-based image editing with diffusion models,
B. Yang, S. Gu, B. Zhang, T. Zhang, X. Chen, X. Sun, D. Chen, and F. Wen, “Paint by example: Exemplar-based image editing with diffusion models,” inCVPR, 2023
work page 2023
-
[43]
Specref: A fast training-free baseline of specific reference-condition real image editing,
S. Chen and J. Huang, “Specref: A fast training-free baseline of specific reference-condition real image editing,” inICICML, 2023
work page 2023
-
[44]
Freeedit: Mask-free reference-based image editing with multi- modal instruction,
R. He, K. Ma, L. Huang, S. Huang, J. Gao, X. Wei, J. Dai, J. Han, and S. Liu, “Freeedit: Mask-free reference-based image editing with multi- modal instruction,”IEEE TPAMI, 2025
work page 2025
-
[45]
Zero-shot image editing with reference imitation,
X. Chen, Y . Feng, M. Chen, Y . Wang, S. Zhang, Y . Liu, Y . Shen, and H. Zhao, “Zero-shot image editing with reference imitation,” inNeurIPS, 2025
work page 2025
-
[46]
Pixels: Progressive image xemplar-based editing with latent surgery,
S. D. Biswas, M. Shreve, X. Li, P. Singhal, and K. Roy, “Pixels: Progressive image xemplar-based editing with latent surgery,” inAAAI, 2025
work page 2025
-
[47]
Poce: Pose- controllable expression editing,
R. Wu, Y . Yu, F. Zhan, J. Zhang, S. Liao, and S. Lu, “Poce: Pose- controllable expression editing,”IEEE TIP, 2023
work page 2023
-
[48]
Towards understanding cross and self-attention in stable diffusion for text-guided image editing,
B. Liu, C. Wang, T. Cao, K. Jia, and J. Huang, “Towards understanding cross and self-attention in stable diffusion for text-guided image editing,” inCVPR, 2024
work page 2024
-
[49]
What makes good examples for visual in-context learning?
Y . Zhang, K. Zhou, and Z. Liu, “What makes good examples for visual in-context learning?” inNeurIPS, 2023
work page 2023
-
[50]
Unifying image processing as visual prompting question answering,
Y . Liu, X. Chen, X. Ma, X. Wang, J. Zhou, Y . Qiao, and C. Dong, “Unifying image processing as visual prompting question answering,” inICML, 2024
work page 2024
-
[51]
Images speak in images: A generalist painter for in-context visual learning,
X. Wang, W. Wang, Y . Cao, C. Shen, and T. Huang, “Images speak in images: A generalist painter for in-context visual learning,” inCVPR, 2023
work page 2023
-
[52]
B. F. Labs, “Flux,” 2024. [Online]. Available: https://github.com/ black-forest-labs/flux
work page 2024
-
[53]
Flow straight and fast: Learning to generate and transfer data with rectified flow,
X. Liu, C. Gong, and Q. Liu, “Flow straight and fast: Learning to generate and transfer data with rectified flow,” inICLR, 2023
work page 2023
-
[54]
Flow matching for generative modeling,
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,” inICLR, 2023
work page 2023
-
[55]
Stylegan-nada: Clip-guided domain adaptation of image generators,
R. Gal, O. Patashnik, H. Maron, A. H. Bermano, G. Chechik, and D. Cohen-Or, “Stylegan-nada: Clip-guided domain adaptation of image generators,”ACM TOG, 2022
work page 2022
-
[56]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” inICLR, 2019
work page 2019
-
[57]
Splicing vit features for semantic appearance transfer,
N. Tumanyan, O. Bar-Tal, S. Bagon, and T. Dekel, “Splicing vit features for semantic appearance transfer,” inCVPR, 2022
work page 2022
-
[58]
OpenAI, “Gpt-4o system card,” 2024. [Online]. Available: https: //arxiv.org/abs/2410.21276
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.