Recognition: 2 theorem links
· Lean TheoremDIMoE-Adapters: Dynamic Expert Evolution for Continual Learning in Vision-Language Models
Pith reviewed 2026-05-11 02:13 UTC · model grok-4.3
The pith
A dynamic mixture-of-experts adapter system lets vision-language models learn from new domains while preserving knowledge from previous ones by evolving experts dynamically.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
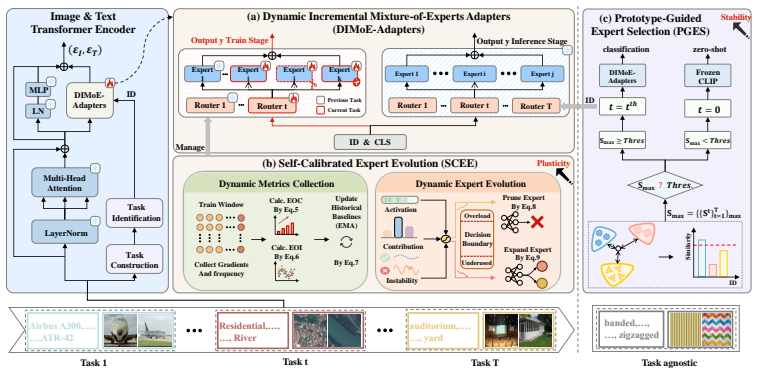
DIMoE-Adapters introduces a dynamic incremental mixture-of-experts adapters framework that evolves experts dynamically to balance stability and plasticity in continual learning for vision-language models, implemented via self-calibrated expert evolution that constructs and optimizes a sparse expert pool and prototype-guided expert selection that controls utilization based on the pool.
What carries the argument
Dynamic expert evolution paradigm, which builds and refines a sparse expert pool through optimization dynamics while using prototypes to select and allocate experts for each input.
If this is right
- Models adapt to new domains with less catastrophic forgetting than methods that use fixed parameter allocation.
- Expert utilization improves stability on both previously seen tasks and tasks from unseen domains.
- Sparse expert pools reduce redundant capacity while preserving the ability to incorporate new knowledge.
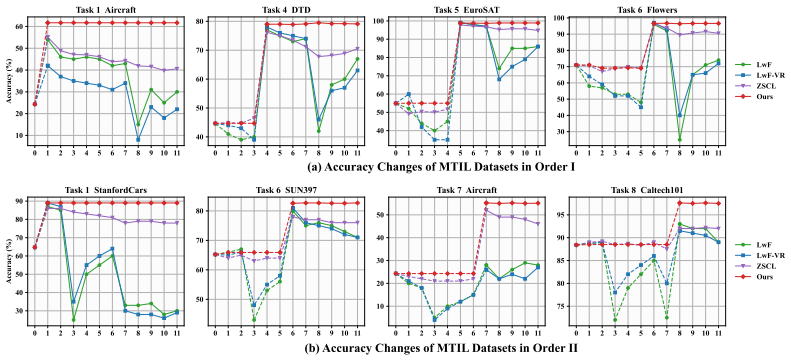
- Performance exceeds prior state-of-the-art methods across multiple multi-domain task-incremental learning settings.
Where Pith is reading between the lines
- The prototype-based selection could combine with retrieval-augmented techniques to handle even larger numbers of tasks.
- Applying the same evolution process to other modalities such as audio or pure text models would test whether the balance generalizes beyond vision-language pairs.
- The sparse pool construction might lower memory costs at inference time when deployed on resource-limited devices.
Load-bearing premise
The self-calibrated expert evolution and prototype-guided selection mechanisms will reliably balance plasticity and stability without introducing new forms of interference or requiring extensive hyperparameter tuning.
What would settle it
A controlled ablation that disables the expert evolution step and shows either increased forgetting on prior domains or failure to reach reported adaptation levels on new domains.
Figures





read the original abstract
Continual learning enables vision-language models to accumulate knowledge and adapt to evolving tasks without retraining from scratch. However, in multi-domain task-incremental learning, large domain shifts intensify the stability-plasticity dilemma. Most existing methods rely on fixed architectures with statically allocated parameters, which limits adaptation to new domains and aggravates catastrophic forgetting. To address these challenges, we propose DIMoE-Adapters, a Dynamic Incremental Mixture-of-Experts Adapters framework that introduces a dynamic expert evolution paradigm to balance stability and plasticity. This paradigm is implemented through two collaborative components: Self-Calibrated Expert Evolution (SCEE) and Prototype-Guided Expert Selection (PGES). SCEE constructs and evolves a sparse expert pool through expert optimization dynamics, improving plasticity while reducing redundant capacity. PGES controls expert utilization based on the pool shaped by SCEE, improving stability across both previously encountered and unseen tasks. Extensive experiments show that DIMoE-Adapters outperforms previous state-of-the-art methods across various settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DIMoE-Adapters, a Dynamic Incremental Mixture-of-Experts Adapters framework for continual learning in vision-language models facing multi-domain task-incremental settings. It introduces a dynamic expert evolution paradigm realized through two components: Self-Calibrated Expert Evolution (SCEE), which constructs and evolves a sparse expert pool via optimization dynamics, and Prototype-Guided Expert Selection (PGES), which controls utilization based on the evolved pool. The central claim is that this collaborative design balances stability and plasticity more effectively than fixed-architecture methods and outperforms prior state-of-the-art approaches across various settings.
Significance. If the empirical claims are substantiated, the work would be a meaningful contribution to continual learning for vision-language models. The shift from static parameter allocation to dynamic expert-pool evolution addresses a core limitation in handling large domain shifts, and the SCEE/PGES pairing offers a concrete mechanism for controlling capacity and utilization. Strengths include the focus on sparse evolution to reduce redundancy and the explicit aim of improving stability on both seen and unseen tasks.
major comments (3)
- [§4] §4 (Experiments): The outperformance claims over prior SOTA methods rest on results that lack ablations isolating SCEE and PGES from simple increases in total capacity or expert count. Without controls such as a fixed-pool MoE baseline or a version ablating prototype guidance, it remains unclear whether the reported gains derive from the proposed dynamic evolution paradigm or from unaccounted factors such as additional parameters.
- [§4.2] §4.2 (Ablation studies): No metrics are provided for interference or stability under domain shifts, such as per-expert activation entropy, cross-task gradient norms, or forgetting rates broken down by expert pool size. This omission leaves the central claim that SCEE/PGES reliably avoid new forms of interference vulnerable, as the abstract positions these mechanisms as collaborative heuristics without direct evidence of their dynamics.
- [§3.2] §3.2 (SCEE description): The expert optimization dynamics used to evolve the sparse pool are not accompanied by analysis of pool-size stability (e.g., oscillation bounds or convergence criteria across domain shifts). If pool size varies uncontrollably, the claimed reduction in redundant capacity and improvement in plasticity could be compromised.
minor comments (2)
- [§3.3] Notation for the prototype-guided selection in PGES could be clarified with an explicit equation showing how prototype similarity modulates expert routing probabilities.
- [Figure 2] Figure 2 (method overview) would benefit from annotations indicating the exact points at which SCEE updates the pool and PGES performs selection during a task increment.
Simulated Author's Rebuttal
We sincerely thank the referee for the thorough review and valuable suggestions. We have carefully considered each comment and will revise the manuscript accordingly to address the concerns raised.
read point-by-point responses
-
Referee: [§4] The outperformance claims over prior SOTA methods rest on results that lack ablations isolating SCEE and PGES from simple increases in total capacity or expert count. Without controls such as a fixed-pool MoE baseline or a version ablating prototype guidance, it remains unclear whether the reported gains derive from the proposed dynamic evolution paradigm or from unaccounted factors such as additional parameters.
Authors: We agree that isolating the contributions of SCEE and PGES through targeted ablations is crucial for substantiating our claims. In the revised manuscript, we will add a fixed-pool MoE baseline maintaining equivalent total capacity and an ablation study removing the prototype guidance in PGES. These additions will clarify that the performance gains stem from the dynamic expert evolution rather than mere increases in parameters. revision: yes
-
Referee: [§4.2] No metrics are provided for interference or stability under domain shifts, such as per-expert activation entropy, cross-task gradient norms, or forgetting rates broken down by expert pool size. This omission leaves the central claim that SCEE/PGES reliably avoid new forms of interference vulnerable, as the abstract positions these mechanisms as collaborative heuristics without direct evidence of their dynamics.
Authors: We acknowledge the need for quantitative metrics to demonstrate the interference avoidance. We will incorporate per-expert activation entropy, cross-task gradient norms, and task-specific forgetting rates as functions of pool size in the ablation studies. This will provide direct evidence supporting the collaborative design of SCEE and PGES in maintaining stability under domain shifts. revision: yes
-
Referee: [§3.2] The expert optimization dynamics used to evolve the sparse pool are not accompanied by analysis of pool-size stability (e.g., oscillation bounds or convergence criteria across domain shifts). If pool size varies uncontrollably, the claimed reduction in redundant capacity and improvement in plasticity could be compromised.
Authors: We will enhance the description in §3.2 with an analysis of pool-size stability. Specifically, we will report the variation in pool size across different domain shifts, including empirical bounds on oscillations and convergence behavior observed in our experiments. This will substantiate that the evolution process remains controlled and does not introduce uncontrolled redundancy. revision: yes
Circularity Check
No circularity: empirical proposal of new architecture with external validation
full rationale
The paper proposes DIMoE-Adapters as a novel framework using SCEE (Self-Calibrated Expert Evolution) and PGES (Prototype-Guided Expert Selection) to address stability-plasticity in multi-domain continual learning. The central claims rest on introducing these components and reporting empirical outperformance across settings, without any equations, derivations, or predictions that reduce by construction to fitted inputs or self-defined quantities. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked; the method is presented as a self-contained architectural innovation evaluated on benchmarks. This matches the default non-circular case for empirical ML papers.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearSCEE constructs and evolves a sparse expert pool through expert optimization dynamics... Gradient-Based Metrics... I_curr and V_curr... Expert Pruning... Pi = I(fi < γ_prune)·I(I_curr/H_I <1-γ_prune)
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclearPGES... task-specific prototypes... Gaussian mixture... St(x) = max_k (-1/2 d²_t,k(x) - 1/2 ln|Σt,k|)
Reference graph
Works this paper leans on
-
[1]
Continual lifelong learning with neural networks: A review.Neural networks, 2019
German I Parisi, Ronald Kemker, Jose L Part, Christopher Kanan, and Stefan Wermter. Continual lifelong learning with neural networks: A review.Neural networks, 2019
work page 2019
-
[2]
Matthias De Lange, Rahaf Aljundi, Marc Masana, Sarah Parisot, Xu Jia, Aleš Leonardis, Gregory Slabaugh, and Tinne Tuytelaars. A continual learning survey: Defying forgetting in classification tasks.IEEE transactions on pattern analysis and machine intelligence (TPAMI), 2021
work page 2021
-
[3]
Pietro Buzzega, Matteo Boschini, Angelo Porrello, Davide Abati, and Simone Calderara. Dark experience for general continual learning: a strong, simple baseline.Advances in neural information processing systems (NeurIPS), 2020
work page 2020
-
[4]
Continual learning through synaptic intelligence
Friedemann Zenke, Ben Poole, and Surya Ganguli. Continual learning through synaptic intelligence. InInternational conference on machine learning (ICML), 2017
work page 2017
-
[5]
Hanul Shin, Jung Kwon Lee, Jaehong Kim, and Jiwon Kim. Continual learning with deep generative replay.Advances in neural information processing systems (NeurIPS), 2017
work page 2017
-
[6]
Gcr: Gradient coreset based replay buffer selection for continual learning
Rishabh Tiwari, Krishnateja Killamsetty, Rishabh Iyer, and Pradeep Shenoy. Gcr: Gradient coreset based replay buffer selection for continual learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
work page 2022
-
[7]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning (ICML), 2021
work page 2021
-
[8]
Learning to prompt for vision-language models.International Journal of Computer Vision (IJCV), 2022
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Learning to prompt for vision-language models.International Journal of Computer Vision (IJCV), 2022
work page 2022
-
[9]
Preventing zero-shot transfer degradation in continual learning of vision-language models
Zangwei Zheng, Mingyuan Ma, Kai Wang, Ziheng Qin, Xiangyu Yue, and Yang You. Preventing zero-shot transfer degradation in continual learning of vision-language models. InProceedings of the IEEE/CVF international conference on computer vision (ICCV), 2023
work page 2023
-
[10]
Boosting continual learning of vision-language models via mixture-of-experts adapters
Jiazuo Yu, Yunzhi Zhuge, Lu Zhang, Ping Hu, Dong Wang, Huchuan Lu, and You He. Boosting continual learning of vision-language models via mixture-of-experts adapters. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[11]
Self-expansion of pre-trained models with mixture of adapters for continual learning
Huiyi Wang, Haodong Lu, Lina Yao, and Dong Gong. Self-expansion of pre-trained models with mixture of adapters for continual learning. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10087–10098, 2025
work page 2025
-
[12]
Incremental embedding learning via zero-shot translation
Kun Wei, Cheng Deng, Xu Yang, and Maosen Li. Incremental embedding learning via zero-shot translation. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2021
work page 2021
-
[13]
Andrei A Rusu, Neil C Rabinowitz, Guillaume Desjardins, Hubert Soyer, James Kirkpatrick, Koray Kavukcuoglu, Razvan Pascanu, and Raia Hadsell. Progressive neural networks.arXiv preprint arXiv:1606.04671, 2016. 10
work page internal anchor Pith review arXiv 2016
-
[14]
Packnet: Adding multiple tasks to a single network by iterative pruning
Arun Mallya and Svetlana Lazebnik. Packnet: Adding multiple tasks to a single network by iterative pruning. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition (CVPR), 2018
work page 2018
-
[15]
Compress to one point: neural collapse for pre-trained model-based class-incremental learning
Kun Wei, Zhe Xu, and Cheng Deng. Compress to one point: neural collapse for pre-trained model-based class-incremental learning. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2025
work page 2025
-
[16]
Gradient episodic memory for continual learning
David Lopez-Paz and Marc’Aurelio Ranzato. Gradient episodic memory for continual learning. Advances in neural information processing systems (NeurIPS), 2017
work page 2017
-
[17]
icarl: Incremental classifier and representation learning
Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H Lampert. icarl: Incremental classifier and representation learning. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition (CVPR, 2017
work page 2017
-
[18]
Riccardo V olpi, Hongseok Namkoong, Ozan Sener, John C Duchi, Vittorio Murino, and Silvio Savarese. Generalizing to unseen domains via adversarial data augmentation.Advances in neural information processing systems (NeurIPS), 2018
work page 2018
-
[19]
Menglin Jia, Luming Tang, Bor-Chun Chen, Claire Cardie, Serge Belongie, Bharath Hariharan, and Ser-Nam Lim. Visual prompt tuning. InEuropean conference on computer vision (ECCV). Springer, 2022
work page 2022
-
[20]
Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing.ACM computing surveys, 2023
work page 2023
-
[21]
Parameter-efficient transfer learning for nlp
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for nlp. InInternational conference on machine learning (ICML), 2019
work page 2019
-
[22]
K-adapter: Infusing knowledge into pre-trained models with adapters
Ruize Wang, Duyu Tang, Nan Duan, Zhongyu Wei, Xuan-Jing Huang, Jianshu Ji, Guihong Cao, Daxin Jiang, and Ming Zhou. K-adapter: Infusing knowledge into pre-trained models with adapters. InFindings of the Association for Computational Linguistics (ACL), 2021
work page 2021
-
[23]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. In International Conference on Learning Representations (ICLR), 2022
work page 2022
-
[24]
Saurav Jha, Dong Gong, and Lina Yao. Clap4clip: Continual learning with probabilistic finetuning for vision-language models.Advances in neural information processing systems (NeurIPS), 2024
work page 2024
-
[25]
Dualprompt: Complementary prompting for rehearsal-free continual learning
Zifeng Wang, Zizhao Zhang, Sayna Ebrahimi, Ruoxi Sun, Han Zhang, Chen-Yu Lee, Xiaoqi Ren, Guolong Su, Vincent Perot, Jennifer Dy, et al. Dualprompt: Complementary prompting for rehearsal-free continual learning. InEuropean conference on computer vision (ECCV). Springer, 2022
work page 2022
-
[26]
Adaptive mixtures of local experts.Neural computation, 1991
Robert A Jacobs, Michael I Jordan, Steven J Nowlan, and Geoffrey E Hinton. Adaptive mixtures of local experts.Neural computation, 1991
work page 1991
-
[27]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[28]
Expert gate: Lifelong learning with a network of experts
Rahaf Aljundi, Punarjay Chakravarty, and Tinne Tuytelaars. Expert gate: Lifelong learning with a network of experts. InProceedings of the IEEE conference on computer vision and pattern recognition (CVPR), 2017
work page 2017
-
[29]
Lifelong language pretraining with distribution-specialized experts
Wuyang Chen, Yanqi Zhou, Nan Du, Yanping Huang, James Laudon, Zhifeng Chen, and Claire Cui. Lifelong language pretraining with distribution-specialized experts. InInternational Conference on Machine Learning (ICML), 2023. 11
work page 2023
-
[30]
Peng Gao, Shijie Geng, Renrui Zhang, Teli Ma, Rongyao Fang, Yongfeng Zhang, Hongsheng Li, and Yu Qiao. Clip-adapter: Better vision-language models with feature adapters.International Journal of Computer Vision (IJCV), 2024
work page 2024
-
[31]
arXiv preprint arXiv:2403.07652 , year=
Quzhe Huang, Zhenwei An, Nan Zhuang, Mingxu Tao, Chen Zhang, Yang Jin, Kun Xu, Liwei Chen, Songfang Huang, and Yansong Feng. Harder tasks need more experts: Dynamic routing in moe models.arXiv preprint arXiv:2403.07652, 2024
-
[32]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. Gshard: Scaling giant models with condi- tional computation and automatic sharding.arXiv preprint arXiv:2006.16668, 2020
work page internal anchor Pith review arXiv 2006
-
[33]
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 2022
work page 2022
-
[34]
Zhizhong Li and Derek Hoiem. Learning without forgetting.IEEE transactions on pattern analysis and machine intelligence (TPAMI), 2017
work page 2017
-
[35]
Robust fine-tuning of zero-shot models
Mitchell Wortsman, Gabriel Ilharco, Jong Wook Kim, Mike Li, Simon Kornblith, Rebecca Roelofs, Raphael Gontijo Lopes, Hannaneh Hajishirzi, Ali Farhadi, Hongseok Namkoong, et al. Robust fine-tuning of zero-shot models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), 2022
work page 2022
-
[36]
Synthetic data is an elegant gift for continual vision-language models
Bin Wu, Wuxuan Shi, Jinqiao Wang, and Mang Ye. Synthetic data is an elegant gift for continual vision-language models. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), 2025
work page 2025
-
[37]
Learn and ensemble bridge adapters for multi-domain task incremental learning
Ziqi Gu, Chunyan Xu, Wenxuan Fang, Xin Liu, Yide Qiu, and Zhen Cui. Learn and ensemble bridge adapters for multi-domain task incremental learning. InAdvances in neural information processing systems (NeurIPS), 2025
work page 2025
-
[38]
Yuxuan Ding, Lingqiao Liu, Chunna Tian, Jingyuan Yang, and Haoxuan Ding. Don’t stop learning: Towards continual learning for the clip model.arXiv preprint arXiv:2207.09248, 2022
-
[39]
Dytox: Trans- formers for continual learning with dynamic token expansion
Arthur Douillard, Alexandre Ramé, Guillaume Couairon, and Matthieu Cord. Dytox: Trans- formers for continual learning with dynamic token expansion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), 2022
work page 2022
-
[40]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[41]
When does label smoothing help? Advances in neural information processing systems (NeurIPS), 2019
Rafael Müller, Simon Kornblith, and Geoffrey E Hinton. When does label smoothing help? Advances in neural information processing systems (NeurIPS), 2019
work page 2019
-
[42]
Visualizing and understanding convolutional networks
Matthew D Zeiler and Rob Fergus. Visualizing and understanding convolutional networks. In European conference on computer vision (ECCV). Springer, 2014
work page 2014
-
[43]
Jason Yosinski, Jeff Clune, Yoshua Bengio, and Hod Lipson. How transferable are features in deep neural networks?Advances in neural information processing systems (NeurIPS), 27, 2014
work page 2014
-
[44]
Maithra Raghu, Chiyuan Zhang, Jon Kleinberg, and Samy Bengio. Transfusion: Understanding transfer learning for medical imaging.Advances in neural information processing systems (NeurIPS), 2019
work page 2019
-
[45]
Acceleration of stochastic approximation by averaging
Boris T Polyak and Anatoli B Juditsky. Acceleration of stochastic approximation by averaging. SIAM journal on control and optimization, 1992
work page 1992
-
[46]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009. 12
work page 2009
-
[47]
Der: Dynamically expandable representation for class incremental learning
Shipeng Yan, Jiangwei Xie, and Xuming He. Der: Dynamically expandable representation for class incremental learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), 2021
work page 2021
-
[48]
Prithviraj Dhar, Rajat Vikram Singh, Kuan-Chuan Peng, Ziyan Wu, and Rama Chellappa. Learning without memorizing. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), 2019
work page 2019
-
[49]
Moment matching for multi-source domain adaptation
Xingchao Peng, Qinxun Bai, Xide Xia, Zijun Huang, Kate Saenko, and Bo Wang. Moment matching for multi-source domain adaptation. InProceedings of the IEEE/CVF international conference on computer vision (ICCV), 2019
work page 2019
-
[50]
Fine-Grained Visual Classification of Aircraft
Subhransu Maji, Esa Rahtu, Juho Kannala, Matthew Blaschko, and Andrea Vedaldi. Fine- grained visual classification of aircraft.arXiv preprint arXiv:1306.5151, 2013
work page internal anchor Pith review arXiv 2013
-
[51]
Li Fei-Fei, Rob Fergus, and Pietro Perona. Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories. In2004 conference on computer vision and pattern recognition workshop (CVPRW). IEEE, 2004
work page 2004
-
[52]
Describing textures in the wild
Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Describing textures in the wild. InProceedings of the IEEE conference on computer vision and pattern recognition (CVPR), 2014
work page 2014
-
[53]
Patrick Helber, Benjamin Bischke, Andreas Dengel, and Damian Borth. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2019
work page 2019
-
[54]
Automated flower classification over a large number of classes
Maria-Elena Nilsback and Andrew Zisserman. Automated flower classification over a large number of classes. In2008 Sixth Indian conference on computer vision, graphics & image processing. IEEE, 2008
work page 2008
-
[55]
Food-101–mining discriminative components with random forests
Lukas Bossard, Matthieu Guillaumin, and Luc Van Gool. Food-101–mining discriminative components with random forests. InEuropean conference on computer vision (ECCV). Springer, 2014
work page 2014
-
[56]
Li Deng. The mnist database of handwritten digit images for machine learning research [best of the web].IEEE signal processing magazine, 2012
work page 2012
-
[57]
Omkar M Parkhi, Andrea Vedaldi, Andrew Zisserman, and CV Jawahar. Cats and dogs. In 2012 IEEE conference on computer vision and pattern recognition (CVPR). IEEE, 2012
work page 2012
-
[58]
3d object representations for fine- grained categorization
Jonathan Krause, Michael Stark, Jia Deng, and Li Fei-Fei. 3d object representations for fine- grained categorization. InProceedings of the IEEE international conference on computer vision workshops (ICCVW), 2013
work page 2013
-
[59]
Avg.”) and the final accuracy after learning all tasks (“Last
Jianxiong Xiao, James Hays, Krista A Ehinger, Aude Oliva, and Antonio Torralba. Sun database: Large-scale scene recognition from abbey to zoo. In2010 IEEE computer society conference on computer vision and pattern recognition (CVPR). IEEE, 2010. 13 A Additional Implementation Details Hyperparameter Settings.For the MTIL benchmark, we use a batch size of 1...
work page 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.