Recognition: no theorem link
Lightweight Unpaired Smartphone ISP Transfer with Semantic Pseudo-Pairing
Pith reviewed 2026-05-11 02:08 UTC · model grok-4.3
The pith
Semantic pseudo-pairs built from DINOv2 embeddings and fused Gromov-Wasserstein transport let a 7K-parameter CNN perform color rendering on unpaired RAW smartphone images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
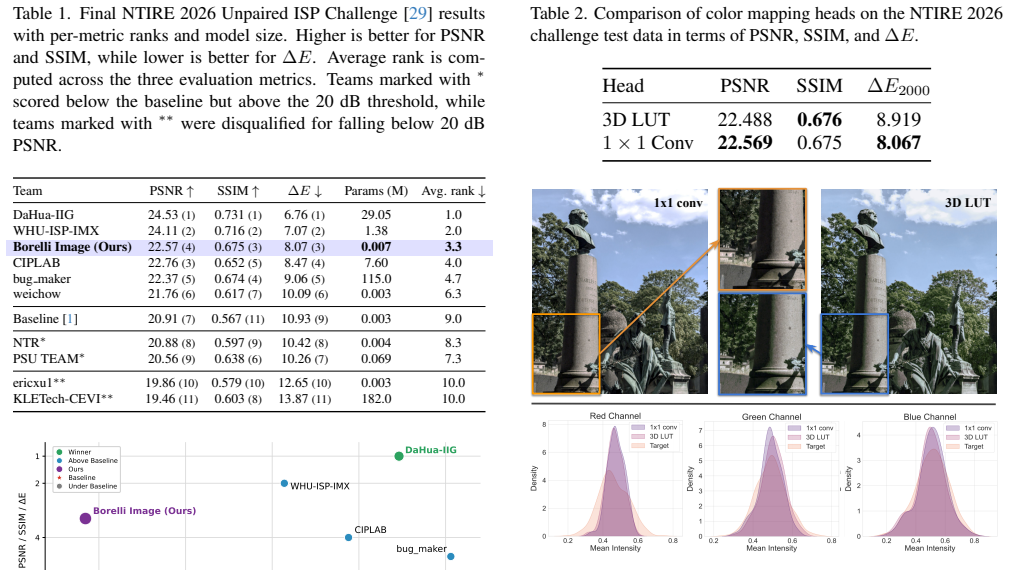
The central claim is that semantic embeddings from DINOv2 combined with fused Gromov-Wasserstein optimal transport can generate sufficiently accurate pseudo-pairs between unpaired RAW and target RGB images; these pairs then support training a 7K-parameter CNN focused solely on color rendering, which achieves 22.569 PSNR, 0.675 SSIM and 8.067 ΔE on the hidden test set and ranks third in SSIM and ΔE among challenge entries.
What carries the argument
Semantic pseudo-pairing, which extracts DINOv2 embeddings from reconstructed images and matches RAW-to-RGB domains via fused Gromov-Wasserstein optimal transport at image and patch levels to create training pairs.
If this is right
- Adversarial losses become unnecessary once semantic alignment supplies the training signal.
- Restricting the network to color-only operations on 7K parameters reduces artifacts and improves stability.
- Multi-scale matching (image plus patch) supplies both global context and local consistency.
- The approach improves all reported metrics over the provided baseline on the final test set.
Where Pith is reading between the lines
- The same semantic-matching recipe could extend to other unpaired low-level tasks such as denoising or white-balance correction where paired data is scarce.
- Vision-transformer features appear to capture color-relevant semantics better than low-level statistics for cross-domain pairing.
- The extreme parameter count suggests the method could run in real time on mobile hardware once the pseudo-pair stage is replaced by a learned matcher.
Load-bearing premise
The pseudo-pairs generated by DINOv2 and fused Gromov-Wasserstein transport are accurate enough in both semantics and alignment that the CNN learns correct color mapping without inheriting large errors from the unpaired data.
What would settle it
Training the same 7K-parameter CNN on a baseline without the pseudo-pair step and observing that PSNR drops below 22, SSIM falls below 0.67, or ΔE rises above 8 on the identical hidden test set would falsify the claim that the semantic pairs are the enabling factor.
Figures







read the original abstract
Unpaired smartphone ISP is a challenging problem due to the lack of scene and color alignment between RAW and target RGB images. Many existing methods either require paired data or rely heavily on adversarial training, which can become unstable in the unpaired setting. In this work, we present a simple and effective approach developed for the NTIRE 2026 Learned Smartphone ISP Challenge with Unpaired Data. Our method first reconstructs larger images from training patches to recover global context. Then, we extract semantic embeddings with DINOv2, and use fused Gromov-Wasserstein (FGW) optimal transport to build pseudo pairs between RAW and RGB images at both image and patch levels. This semantic matching allows us to partially alleviate the unpairedness of the data and build these pseudo input-target pairs. Based on these pseudo pairs, we train a lightweight CNN with only 7K parameters for color rendering. The network is designed to be compact and focus on color transformation rather than structural change, which helps reduce artifacts and improve training stability. Our challenge submission achieves 22.569 PSNR, 0.675 SSIM, and 8.067 $\Delta E$ on the final hidden test set, significantly improving over the baseline and achieving the 3rd best SSIM and $\Delta E$ among all challenge entries. Our code is available at github.com/nuniniyujin/Unpaired-ISP .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a lightweight method for unpaired smartphone ISP transfer developed for the NTIRE 2026 challenge. It reconstructs full-resolution images from training patches to recover global context, extracts DINOv2 semantic embeddings, applies fused Gromov-Wasserstein optimal transport to construct pseudo-pairs between RAW inputs and RGB targets at both image and patch levels, and trains a compact 7K-parameter CNN focused solely on color rendering. The submission reports 22.569 PSNR, 0.675 SSIM, and 8.067 ΔE on the hidden test set, improving over the baseline and ranking 3rd in SSIM and ΔE among entries. Code is released publicly.
Significance. If the semantic pseudo-pairs prove sufficiently photometrically aligned, the work demonstrates that a non-adversarial, extremely compact CNN can deliver competitive unpaired ISP performance without the training instabilities common in GAN-based approaches. The 7K-parameter design is a clear practical advantage for on-device deployment. Public code availability is a strength that enables direct verification and reuse.
major comments (2)
- [§3.2] §3.2 (Semantic Pseudo-Pairing): The central assumption that FGW transport on DINOv2 embeddings yields pseudo-pairs whose color statistics are close enough to the unknown true RAW-to-RGB mapping is load-bearing for the claim of effective color rendering. DINOv2 features are largely invariant to low-level photometry and were trained on RGB rather than RAW sensor data; no quantitative check (color histogram divergence, illuminant consistency, or comparison to any available paired subset) is reported to confirm alignment. If mismatched regions are paired, the 7K CNN may learn biased mappings whose challenge scores do not generalize.
- [§4] §4 (Experiments): The reported challenge metrics lack ablations isolating the contribution of image-level versus patch-level FGW matching, the image-reconstruction step, or the choice of DINOv2 layer. Without these, it is difficult to determine whether the 3rd-place SSIM/ΔE ranking stems from the semantic pseudo-pairing or from other factors such as the lightweight architecture or challenge-specific regularization.
minor comments (2)
- [Abstract / §3.1] The abstract and method description state that larger images are reconstructed from patches, but the exact procedure (overlap handling, blending, or artifact mitigation) is not detailed enough for full reproducibility.
- Table or figure showing example pseudo-pairs (input RAW, matched RGB target, and resulting rendered output) would help readers assess visual quality of the constructed pairs.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and describe the revisions planned for the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Semantic Pseudo-Pairing): The central assumption that FGW transport on DINOv2 embeddings yields pseudo-pairs whose color statistics are close enough to the unknown true RAW-to-RGB mapping is load-bearing for the claim of effective color rendering. DINOv2 features are largely invariant to low-level photometry and were trained on RGB rather than RAW sensor data; no quantitative check (color histogram divergence, illuminant consistency, or comparison to any available paired subset) is reported to confirm alignment. If mismatched regions are paired, the 7K CNN may learn biased mappings whose challenge scores do not generalize.
Authors: We appreciate the referee's identification of this key assumption. While DINOv2 provides semantic features that correlate with scene content and thus with plausible color mappings in natural images, we acknowledge the absence of explicit photometric validation in the original submission. In the revised manuscript, we will add quantitative analysis in §3.2, including Earth Mover's Distance between color histograms of pseudo-paired vs. randomly paired images and visual inspection of aligned patches for illuminant consistency. We will also explicitly discuss the limitation that DINOv2 was pretrained on RGB data. However, a direct comparison to a paired subset is not possible given the unpaired challenge data. revision: partial
-
Referee: [§4] §4 (Experiments): The reported challenge metrics lack ablations isolating the contribution of image-level versus patch-level FGW matching, the image-reconstruction step, or the choice of DINOv2 layer. Without these, it is difficult to determine whether the 3rd-place SSIM/ΔE ranking stems from the semantic pseudo-pairing or from other factors such as the lightweight architecture or challenge-specific regularization.
Authors: We agree that isolating these components would clarify the source of the performance gains. In the revised manuscript, we will expand §4 with new ablation tables on the validation set reporting PSNR, SSIM, and ΔE for: (i) image-level FGW only, patch-level FGW only, and the combined setting; (ii) with and without the full-image reconstruction step; and (iii) embeddings from different DINOv2 layers. These results will be presented alongside the final challenge metrics to demonstrate the contribution of each design choice. revision: yes
- Direct quantitative comparison of pseudo-pairs against a paired subset is not feasible, as the NTIRE 2026 challenge provides only unpaired data and no such paired validation set is available.
Circularity Check
No circularity: pseudo-pair construction uses external models and is independent of final metrics
full rationale
The paper's chain proceeds from external DINOv2 embeddings and FGW optimal transport to construct pseudo-pairs, followed by training a compact CNN on those pairs and reporting performance on a hidden challenge test set. No equation or claim reduces the reported PSNR/SSIM/ΔE values to a fit on the same quantities, nor does any load-bearing step rely on self-citation or rename a known result. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- CNN model weights
axioms (2)
- domain assumption DINOv2 provides semantically meaningful embeddings for both RAW and RGB images
- domain assumption Fused Gromov-Wasserstein optimal transport can align the distributions of RAW and RGB semantic features effectively
invented entities (1)
-
semantic pseudo-pairs
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Learned lightweight smartphone isp with unpaired data
Andrei Arhire and Radu Timofte. Learned lightweight smartphone isp with unpaired data. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1878–1887, 2025. 2, 3, 6, 7
work page 2025
-
[2]
Tim Brooks, Ben Mildenhall, Tianfan Xue, Jiawen Chen, Dillon Sharlet, and Jonathan T. Barron. Unprocessing images for learned raw denoising.Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11036–11045, 2019. 2
work page 2019
-
[3]
Chen Chen, Qifeng Chen, Jia Xu, and Vladlen Koltun. Learning to see in the dark. InProceedings of the IEEE Con- ference on Computer Vision and Pattern Recognition, pages 3291–3300, 2018. 2
work page 2018
-
[4]
A probabilistic image jigsaw puzzle solver
Taeg Sang Cho, Shai Avidan, and William T Freeman. A probabilistic image jigsaw puzzle solver. In2010 IEEE Computer society conference on computer vision and pattern recognition, pages 183–190. IEEE, 2010. 11
work page 2010
-
[5]
Reference-free estimation of struc- tural and perceptual metrics for single-frame isp pipelines
Yujin Cho, Sira Ferradans, Jean-Michel Morel, Gabriele Fac- ciolo, and Thomas Eboli. Reference-free estimation of struc- tural and perceptual metrics for single-frame isp pipelines. Available at SSRN 6418896. 4
-
[6]
Nilut: Conditional neural implicit 3d lookup tables for image enhancement
Marcos V Conde, Javier Vazquez-Corral, Michael S Brown, and Radu Timofte. Nilut: Conditional neural implicit 3d lookup tables for image enhancement. InProceedings of the AAAI Conference on Artificial Intelligence, pages 1371– 1379, 2024. 2
work page 2024
-
[7]
Marco Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport.Advances in neural information pro- cessing systems, 26, 2013. 2, 4
work page 2013
-
[8]
Leon A. Gatys, Alexander S. Ecker, and Matthias Bethge. Image style transfer using convolutional neural networks. In CVPR, 2016. 5
work page 2016
-
[9]
Deep joint demosaicking and denoising.ACM Transactions on Graphics (ToG), 35(6):1–12, 2016
Micha ¨el Gharbi, Gaurav Chaurasia, Sylvain Paris, and Fr´edo Durand. Deep joint demosaicking and denoising.ACM Transactions on Graphics (ToG), 35(6):1–12, 2016. 4
work page 2016
-
[10]
Micha ¨el Gharbi, Jiawen Chen, Jonathan T Barron, Samuel W Hasinoff, and Fr´edo Durand. Deep bilateral learning for real- time image enhancement.ACM Transactions on Graphics (TOG), 36(4):1–12, 2017. 2
work page 2017
-
[11]
Samuel W Hasinoff, Dillon Sharlet, Ryan Geiss, Andrew Adams, Jonathan T Barron, Florian Kainz, Jiawen Chen, and Marc Levoy. Burst photography for high dynamic range and low-light imaging on mobile cameras.ACM Transactions on Graphics (ToG), 35(6):1–12, 2016. 2
work page 2016
-
[12]
Yuanming Hu, Hao He, Chenxi Xu, Baoyuan Wang, and Stephen Lin. Exposure: A white-box photo post-processing framework.ACM Transactions on Graphics (TOG), 37(2): 1–17, 2018. 2
work page 2018
-
[13]
Multimodal unsupervised image-to-image translation
Xun Huang, Ming-Yu Liu, Serge Belongie, and Jan Kautz. Multimodal unsupervised image-to-image translation. In Proceedings of the European conference on computer vision (ECCV), pages 172–189, 2018. 3
work page 2018
-
[14]
Replac- ing mobile camera isp with a single deep learning model
Andrey Ignatov, Radu Timofte, and Luc Van Gool. Replac- ing mobile camera isp with a single deep learning model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 536–537,
-
[15]
Pynet-v2 mobile: Efficient on-device photo processing with neural networks
Andrey Ignatov, Grigory Malivenko, Radu Timofte, Yu Tseng, Yu-Syuan Xu, Po-Hsiang Yu, Cheng-Ming Chiang, Hsien-Kai Kuo, Min-Hung Chen, Chia-Ming Cheng, et al. Pynet-v2 mobile: Efficient on-device photo processing with neural networks. In2022 26th International Conference on Pattern Recognition (ICPR), pages 677–684. IEEE, 2022. 2
work page 2022
-
[16]
Microisp: processing 32mp photos on mobile devices with deep learning
Andrey Ignatov, Anastasia Sycheva, Radu Timofte, Yu Tseng, Yu-Syuan Xu, Po-Hsiang Yu, Cheng-Ming Chiang, Hsien-Kai Kuo, Min-Hung Chen, Chia-Ming Cheng, et al. Microisp: processing 32mp photos on mobile devices with deep learning. InEuropean Conference on Computer Vision, pages 729–746. Springer, 2022. 2
work page 2022
-
[17]
Image-to-image translation with conditional adver- sarial networks
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. Image-to-image translation with conditional adver- sarial networks. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1125–1134,
-
[18]
Heewon Kim and Kyoung Mu Lee. Learning controllable isp for image enhancement.IEEE Transactions on Image Processing, 33:867–880, 2024. 2
work page 2024
-
[19]
Fei Li, Wenbo Hou, and Peng Jia. Rmfa-net: A neural isp for real raw to rgb image reconstruction.arXiv preprint arXiv:2406.11469, 2024. 2
-
[20]
Jae Hyun Lim and Jong Chul Ye. Geometric gan.arXiv preprint arXiv:1705.02894, 2017. 6
-
[21]
Color enhancement using global parameters and local features learning
Enyu Liu, Songnan Li, and Shan Liu. Color enhancement using global parameters and local features learning. InPro- ceedings of the Asian conference on computer vision, 2020. 2
work page 2020
-
[22]
Ming-Yu Liu, Thomas Breuel, and Jan Kautz. Unsupervised image-to-image translation networks.Advances in neural in- formation processing systems, 30, 2017. 3
work page 2017
-
[23]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 6
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[24]
Color matching using hypernetwork- based kolmogorov-arnold networks
Artem Nikonorov, Georgy Perevozchikov, Andrei Ko- repanov, Nancy Mehta, Mahmoud Afifi, Egor Ershov, and Radu Timofte. Color matching using hypernetwork- based kolmogorov-arnold networks. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 7099–7109, 2025. 3
work page 2025
-
[25]
Augmented cyclic consistency regulariza- tion for unpaired image-to-image translation
Takehiko Ohkawa, Naoto Inoue, Hirokatsu Kataoka, and Nakamasa Inoue. Augmented cyclic consistency regulariza- tion for unpaired image-to-image translation. In2020 25th International Conference on Pattern Recognition (ICPR), pages 362–369. IEEE, 2021. 2
work page 2021
-
[26]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 2, 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Rawformer: Unpaired raw-to-raw translation for learnable camera isps
Georgy Perevozchikov, Nancy Mehta, Mahmoud Afifi, and Radu Timofte. Rawformer: Unpaired raw-to-raw translation for learnable camera isps. InEuropean Conference on Com- puter Vision, pages 231–248, 2024. 3
work page 2024
-
[28]
Georgy Perevozchikov, Nancy Mehta, Egor Ershov, and Radu Timofte. Experts-guided unbalanced optimal trans- port for isp learning from unpaired and/or paired data.arXiv preprint arXiv:2512.05635, 2025. 3
-
[29]
NTIRE 2026 Challenge on Learned Smartphone ISP with Unpaired Data: Methods and Results
Georgy Perevozchikov, Daniil Vladimirov, Radu Timofte, et al. NTIRE 2026 Challenge on Learned Smartphone ISP with Unpaired Data: Methods and Results . InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR) Workshops, 2026. 2, 7
work page 2026
-
[30]
Adap- tive color transfer with relaxed optimal transport
Julien Rabin, Sira Ferradans, and Nicolas Papadakis. Adap- tive color transfer with relaxed optimal transport. In2014 IEEE international conference on image processing (ICIP), pages 4852–4856. IEEE, 2014. 3
work page 2014
- [31]
-
[32]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Karen Simonyan and Andrew Zisserman. Very deep convo- lutional networks for large-scale image recognition.arXiv preprint arXiv:1409.1556, 2015. 5
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[33]
Matheus Souza and Wolfgang Heidrich. Metaisp–exploiting global scene structure for accurate multi-device color rendi- tion.arXiv preprint arXiv:2401.03220, 2024. 8
-
[34]
Hyperparameter optimization in black-box image processing using differentiable proxies
Ethan Tseng, Felix Yu, Yuting Yang, Fahim Mannan, Karl ST Arnaud, Derek Nowrouzezahrai, Jean-Franc ¸ois Lalonde, and Felix Heide. Hyperparameter optimization in black-box image processing using differentiable proxies. ACM Trans. Graph., 38(4):27–1, 2019. 2
work page 2019
-
[35]
Neural photo-finishing.ACM Trans
Ethan Tseng, Yuxuan Zhang, Lars Jebe, Xuaner Zhang, Zhi- hao Xia, Yifei Fan, Felix Heide, and Jiawen Chen. Neural photo-finishing.ACM Trans. Graph., 41(6):238–1, 2022. 2, 5
work page 2022
-
[36]
W-net: Two- stage u-net with misaligned data for raw-to-rgb mapping
Kwang-Hyun Uhm, Seung-Wook Kim, Seo-Won Ji, Sung- Jin Cho, Jun-Pyo Hong, and Sung-Jea Ko. W-net: Two- stage u-net with misaligned data for raw-to-rgb mapping. In 2019 IEEE/CVF International Conference on Computer Vi- sion Workshop (ICCVW), pages 3636–3642. IEEE, 2019. 2
work page 2019
-
[37]
Fused gromov-wasserstein distance for structured objects.Algorithms, 13(9), 2020
Titouan Vayer, Laetitia Chapel, Remi Flamary, Romain Tavenard, and Nicolas Courty. Fused gromov-wasserstein distance for structured objects.Algorithms, 13(9), 2020. 2, 4
work page 2020
-
[38]
C ´edric Villani.Optimal transport : old and new / C ´edric Villani. Springer, Berlin, 2009. 4
work page 2009
-
[39]
Real-esrgan: Training real-world blind super-resolution with pure synthetic data
Xintao Wang, Liangbin Xie, Chao Dong, and Ying Shan. Real-esrgan: Training real-world blind super-resolution with pure synthetic data. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 1905–1914,
work page 1905
-
[40]
Handheld multi-frame super- resolution.ACM Transactions on Graphics (ToG), 38(4):1– 18, 2019
Bartlomiej Wronski, Ignacio Garcia-Dorado, Manfred Ernst, Damien Kelly, Michael Krainin, Chia-Kai Liang, Marc Levoy, and Peyman Milanfar. Handheld multi-frame super- resolution.ACM Transactions on Graphics (ToG), 38(4):1– 18, 2019. 2
work page 2019
-
[41]
Reconfigisp: Reconfigurable camera image process- ing pipeline
Ke Yu, Zexian Li, Yue Peng, Chen Change Loy, and Jin- wei Gu. Reconfigisp: Reconfigurable camera image process- ing pipeline. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4248–4257, 2021. 2
work page 2021
-
[42]
Cycleisp: Real image restoration via improved data synthesis
Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, Ming-Hsuan Yang, and Ling Shao. Cycleisp: Real image restoration via improved data synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2696– 2705, 2020. 2
work page 2020
-
[43]
Hui Zeng, Jianrui Cai, Lida Li, Zisheng Cao, and Lei Zhang. Learning image-adaptive 3d lookup tables for high perfor- mance photo enhancement in real-time.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(4):2058– 2073, 2020. 2
work page 2058
-
[44]
Ffdnet: Toward a fast and flexible solution for cnn-based image denoising
Kai Zhang, Wangmeng Zuo, and Lei Zhang. Ffdnet: Toward a fast and flexible solution for cnn-based image denoising. IEEE Transactions on Image Processing, 27(9):4608–4622,
-
[45]
Multimodal style transfer via graph cuts
Yulun Zhang, Chen Fang, Yilin Wang, Zhaowen Wang, Zhe Lin, Yun Fu, and Jimei Yang. Multimodal style transfer via graph cuts. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5943–5951, 2019. 3
work page 2019
-
[46]
Learning raw-to-srgb mappings with inaccurately aligned supervision
Zhilu Zhang, Haolin Wang, Ming Liu, Ruohao Wang, Jiawei Zhang, and Wangmeng Zuo. Learning raw-to-srgb mappings with inaccurately aligned supervision. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4348–4358, 2021. 2
work page 2021
-
[47]
Unpaired image-to-image translation using cycle- consistent adversarial networks
Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. Unpaired image-to-image translation using cycle- consistent adversarial networks. InProceedings of the IEEE international conference on computer vision, pages 2223– 2232, 2017. 3 Lightweight Unpaired Smartphone ISP Transfer with Semantic Pseudo-Pairing Supplementary Material A. Image stitching ...
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.