Recognition: 2 theorem links
· Lean TheoremDiffusion-APO: Trajectory-Aware Direct Preference Alignment for Video Diffusion Transformers
Pith reviewed 2026-05-11 01:55 UTC · model grok-4.3
The pith
Diffusion-APO aligns video diffusion models by synchronizing training noise distributions with inference denoising trajectories to strengthen preference optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
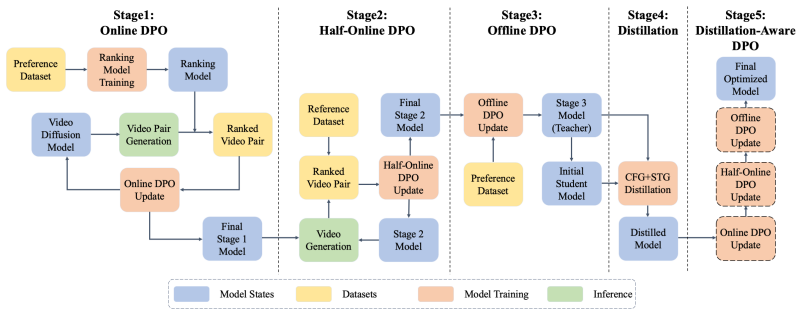
Diffusion-APO is a trajectory-aware algorithm that resolves misalignment in direct preference alignment for video diffusion transformers by synchronizing training noise with inference-time denoising paths to maximize gradient signal efficacy. This is realized through a unified RLHF framework that combines online ranking, half-online anchoring, offline refinement, and distillation-aware drift correction, enabling scalable alignment without scalar-reward policy gradients.
What carries the argument
Trajectory-aware synchronization of training noise distributions with inference denoising paths, which aligns the noise schedules used in optimization to those encountered at generation time so that preference gradients become more effective.
If this is right
- Diffusion-APO outperforms standard DPO and GRPO baselines in visual quality and instruction following on video tasks.
- The method preserves generative fidelity when the model is accelerated after alignment.
- The modular framework supports flexible multi-stage alignment under varying data and compute budgets without scalar rewards.
- No reliance on complex reward models is needed for the preference optimization step.
Where Pith is reading between the lines
- The same noise-trajectory matching idea could be tested on image or 3D diffusion models that share the training-inference gap.
- Stronger gradients might shorten the number of preference-tuning steps required to reach a target quality level.
- Combining Diffusion-APO with existing distillation or quantization techniques could further cut inference latency while retaining alignment gains.
Load-bearing premise
Matching the noise distributions seen during training to those encountered at inference will reliably improve gradient signals and produce better results than current DPO or GRPO baselines without adding new instabilities.
What would settle it
A side-by-side evaluation on the same video generation benchmarks in which models trained with Diffusion-APO receive equal or lower human preference scores for visual quality and instruction following than models trained with standard DPO or GRPO.
Figures








read the original abstract
Efficiently aligning large-scale video diffusion models with human intent requires a scalable and trajectory-aware pathway that bridges the inherent discrepancy between training noise distributions and practical inference trajectories. While existing paradigms such as Direct Preference Optimization (DPO) and Group Relative Policy Optimization (GRPO) attempt to address this, they are often hindered by either reliance on bias-prone, complex reward models or suboptimal timestep sampling. In this paper, we propose Diffusion-APO (Aligned Preference Optimization), a trajectory-aware algorithm that resolves this misalignment by synchronizing training noise with inference-time denoising paths to maximize gradient signal efficacy. To translate this algorithmic innovation into a practical solution, we introduce a unified and modular RLHF framework that integrates online ranking, half-online anchoring, offline refinement, and distillation-aware drift correction. This framework enables flexible, multi-stage preference alignment across diverse data and computational constraints without relying on scalar-reward-based policy gradients. Through extensive experiments, we demonstrate that Diffusion-APO consistently outperforms standard baselines in visual quality and instruction following, while effectively preserving generative fidelity during model acceleration, providing a robust, end-to-end pathway for scalable video diffusion alignment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Diffusion-APO, a trajectory-aware direct preference optimization method for video diffusion transformers. It aims to bridge the gap between training noise distributions and inference trajectories by synchronizing them to enhance gradient signal efficacy. A modular RLHF framework is proposed, combining online ranking, half-online anchoring, offline refinement, and distillation-aware drift correction. The authors claim through extensive experiments that this approach outperforms baselines in visual quality and instruction following while preserving generative fidelity.
Significance. Should the noise synchronization and multi-stage alignment prove effective and stable, this could represent a meaningful step forward in aligning video diffusion models with human preferences in a scalable manner, reducing dependence on potentially biased reward models. It may influence future work on preference optimization for generative models in computer vision.
major comments (2)
- Abstract: The statement that Diffusion-APO 'consistently outperforms standard baselines in visual quality and instruction following' is presented without any quantitative evidence, error bars, specific metrics, or named baselines, which is critical for substantiating the central claim of improved gradient efficacy via trajectory synchronization.
- Abstract: No derivation or equation is provided for how the training noise is synchronized with inference-time denoising paths, leaving open whether this mechanism reliably maximizes gradient signal or introduces new biases, as assumed in the method.
minor comments (2)
- Consider adding a figure or diagram in the method section to illustrate the noise synchronization process and the multi-stage framework.
- The abstract is quite dense; breaking it into clearer sentences could improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, indicating revisions where appropriate to improve clarity and substantiation.
read point-by-point responses
-
Referee: Abstract: The statement that Diffusion-APO 'consistently outperforms standard baselines in visual quality and instruction following' is presented without any quantitative evidence, error bars, specific metrics, or named baselines, which is critical for substantiating the central claim of improved gradient efficacy via trajectory synchronization.
Authors: We agree that the abstract would benefit from greater specificity to support its claims. The full manuscript presents quantitative results with named baselines (including DPO and GRPO), specific metrics, and error bars in the experimental evaluation. To directly address this point, we will revise the abstract to briefly reference key quantitative improvements from those experiments. revision: yes
-
Referee: Abstract: No derivation or equation is provided for how the training noise is synchronized with inference-time denoising paths, leaving open whether this mechanism reliably maximizes gradient signal or introduces new biases, as assumed in the method.
Authors: The trajectory-aware noise synchronization is formally derived with supporting equations in Section 3 of the manuscript, where we detail the alignment between training noise distributions and inference denoising paths to improve gradient signals. Abstracts conventionally omit derivations for brevity. We will revise the abstract to include a concise reference to this synchronization mechanism. Ablation studies in the paper confirm improved performance and stability without evidence of introduced biases. revision: partial
Circularity Check
No circularity in visible derivation chain
full rationale
The provided abstract and description introduce Diffusion-APO as an algorithmic proposal that synchronizes training noise with inference trajectories to address misalignment in video diffusion models, extending DPO/GRPO without any equations, derivations, or parameter fits shown. No self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations appear in the text. The multi-stage framework (online ranking, drift correction, etc.) is presented as a practical implementation rather than a closed loop reducing to its inputs by construction. The derivation chain is therefore self-contained as a novel framing and engineering contribution.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Existing DPO and GRPO are hindered by bias-prone reward models or suboptimal timestep sampling
- ad hoc to paper Synchronizing training noise with inference denoising paths improves preference alignment
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearwe propose Diffusion-APO ... by synchronizing training noise with inference-time denoising paths to maximize gradient signal efficacy
-
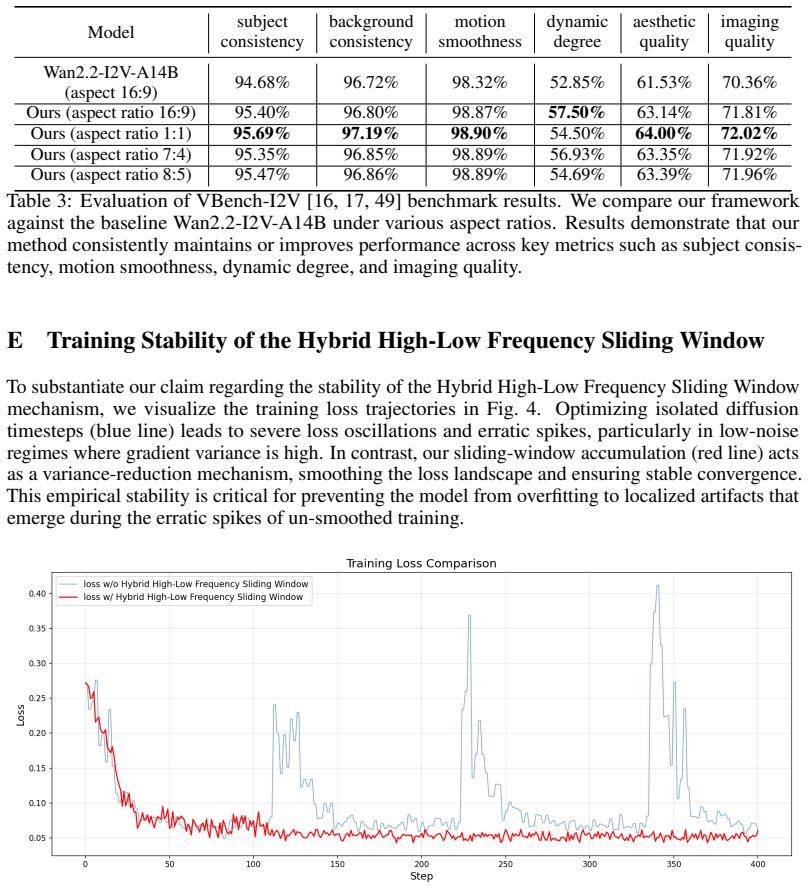
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclearhybrid high-low frequency sliding-window gradient accumulation strategy ... Whigh = {t|0.8T≤t≤T} and Wlow = {t|0≤t<0.8T}
Reference graph
Works this paper leans on
-
[1]
Y . Bai, S. Kadavath, S. Kundu, A. Askell, J. Kernion, A. Jones, A. Chen, A. Goldie, A. Mirhoseini, C. McKinnon, et al. Constitutional ai: Harmlessness from ai feedback.arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [2]
-
[3]
O. Bar-Tal, H. Chefer, O. Tov, C. Herrmann, R. Paiss, S. Zada, A. Ephrat, J. Hur, G. Liu, A. Raj, et al. Lumiere: A space-time diffusion model for video generation. InSIGGRAPH Asia 2024 Conference Papers, pages 1–11, 2024
work page 2024
-
[4]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
A. Blattmann, T. Dockhorn, S. Kulal, D. Mendelevitch, M. Kilian, D. Lorenz, Y . Levi, Z. English, V . V oleti, A. Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
A. Blattmann, R. Rombach, H. Ling, T. Dockhorn, S. W. Kim, S. Fidler, and K. Kreis. Align your latents: High-resolution video synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22563–22575, 2023
work page 2023
- [6]
-
[7]
H. Chen, M. Xia, Y . He, Y . Zhang, X. Cun, S. Yang, J. Xing, Y . Liu, Q. Chen, X. Wang, et al. Videocrafter1: Open diffusion models for high-quality video generation.arXiv preprint arXiv:2310.19512, 2023
work page internal anchor Pith review arXiv 2023
-
[8]
H. Chen, Y . Zhang, X. Cun, M. Xia, X. Wang, C. Weng, and Y . Shan. Videocrafter2: Overcoming data limitations for high-quality video diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7310–7320, 2024
work page 2024
-
[9]
Z. Chen, Y . Deng, H. Yuan, K. Ji, and Q. Gu. Self-play fine-tuning converts weak language models to strong language models. InInternational Conference on Machine Learning, pages 6621–6642. PMLR, 2024
work page 2024
-
[10]
Y . Guo, C. Yang, A. Rao, Z. Liang, Y . Wang, Y . Qiao, M. Agrawala, D. Lin, and B. Dai. Animated- iff: Animate your personalized text-to-image diffusion models without specific tuning. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[11]
J. Ho, W. Chan, C. Saharia, J. Whang, R. Gao, A. Gritsenko, D. P. Kingma, B. Poole, M. Norouzi, D. J. Fleet, et al. Imagen video: High definition video generation with diffusion models.arXiv preprint arXiv:2210.02303, 2022
work page internal anchor Pith review arXiv 2022
-
[12]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
work page 2020
- [13]
-
[14]
J. Ho, T. Salimans, A. Gritsenko, W. Chan, M. Norouzi, and D. J. Fleet. Video diffusion models.Advances in neural information processing systems, 35:8633–8646, 2022
work page 2022
-
[15]
W. Hong, M. Ding, W. Zheng, X. Liu, and J. Tang. Cogvideo: Large-scale pretraining for text-to-video generation via transformers. InThe Eleventh International Conference on Learning Representations, 2022
work page 2022
-
[16]
Z. Huang, Y . He, J. Yu, F. Zhang, C. Si, Y . Jiang, Y . Zhang, T. Wu, Q. Jin, N. Chanpaisit, Y . Wang, X. Chen, L. Wang, D. Lin, Y . Qiao, and Z. Liu. VBench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
work page 2024
-
[17]
Z. Huang, F. Zhang, X. Xu, Y . He, J. Yu, Z. Dong, Q. Ma, N. Chanpaisit, C. Si, Y . Jiang, Y . Wang, X. Chen, Y .-C. Chen, L. Wang, D. Lin, Y . Qiao, and Z. Liu. VBench++: Comprehensive and versatile benchmark suite for video generative models.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
- [18]
-
[19]
L. Khachatryan, A. Movsisyan, V . Tadevosyan, R. Henschel, Z. Wang, S. Navasardyan, and H. Shi. Text2video-zero: Text-to-image diffusion models are zero-shot video generators. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15954–15964, 2023
work page 2023
-
[20]
J. Li, Y . Cui, T. Huang, Y . Ma, C. Fan, Y . Cheng, M. Yang, Z. Zhong, and L. Bo. Mixgrpo: Unlocking flow-based grpo efficiency with mixed ode-sde.arXiv preprint arXiv:2507.21802, 2025
work page internal anchor Pith review arXiv 2025
-
[21]
J. Li, W. Feng, T.-J. Fu, X. Wang, S. Basu, W. Chen, and W. Y . Wang. T2v-turbo: Breaking the quality bottleneck of video consistency model with mixed reward feedback.Advances in neural information processing systems, 37:75692–75726, 2024
work page 2024
-
[22]
S. Li, K. Kallidromitis, A. Gokul, Y . Kato, and K. Kozuka. Aligning diffusion models by optimizing human utility.Advances in Neural Information Processing Systems, 37:24897–24925, 2024
work page 2024
-
[23]
J. Liu, G. Liu, J. Liang, Y . Li, J. Liu, X. Wang, P. Wan, D. ZHANG, and W. Ouyang. Flow-grpo: Training flow matching models via online rl. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[24]
C. Meng, R. Rombach, R. Gao, D. Kingma, S. Ermon, J. Ho, and T. Salimans. On distillation of guided diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14297–14306, 2023
work page 2023
-
[25]
Sora: Creating video from text.https://openai.com/sora, 2024
OpenAI. Sora: Creating video from text.https://openai.com/sora, 2024
work page 2024
- [26]
-
[27]
W. Peebles and S. Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
work page 2023
-
[28]
Prabhudesai, M., Goyal, A., Pathak, D., and Fragkiadaki, K
M. Prabhudesai, R. Mendonca, Z. Qin, K. Fragkiadaki, and D. Pathak. Video diffusion alignment via reward gradients.arXiv preprint arXiv:2407.08737, 2024
-
[29]
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
work page 2023
-
[30]
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
work page 2022
-
[31]
T. Salimans and J. Ho. Progressive distillation for fast sampling of diffusion models. InInternational Conference on Learning Representations, 2022
work page 2022
-
[32]
T. Seedance, H. Chen, S. Chen, X. Chen, Y . Chen, Y . Chen, Z. Chen, F. Cheng, T. Cheng, X. Cheng, et al. Seedance 1.5 pro: A native audio-visual joint generation foundation model.arXiv preprint arXiv:2512.13507, 2025
-
[33]
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [34]
-
[35]
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole. Score-based generative mod- eling through stochastic differential equations. InInternational Conference on Learning Representations, 2021
work page 2021
-
[36]
K. A. Team. Kling: A large-scale text-to-video generation model. https://klingai.kuaishou.com,
-
[37]
Kuaishou AI Technical Report
-
[38]
R. Villegas, M. Babaeizadeh, P.-J. Kindermans, H. Moraldo, H. Zhang, M. T. Saffar, S. Castro, J. Kunze, and D. Erhan. Phenaki: Variable length video generation from open domain textual description.arXiv preprint arXiv:2210.02399, 2022. 11
-
[39]
B. Wallace, M. Dang, R. Rafailov, L. Zhou, A. Lou, S. Purushwalkam, S. Ermon, C. Xiong, S. Joty, and N. Naik. Diffusion model alignment using direct preference optimization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8228–8238, 2024
work page 2024
-
[40]
T. Wan, A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Coefficients-preserving sampling for reinforcement learning with flow matching
F. Wang and Z. Yu. Coefficients-preserving sampling for reinforcement learning with flow matching.arXiv preprint arXiv:2509.05952, 2025
-
[42]
J. Wang, H. Yuan, D. Chen, Y . Zhang, X. Wang, and S. Zhang. Modelscope text-to-video technical report. arXiv preprint arXiv:2308.06571, 2023
work page internal anchor Pith review arXiv 2023
-
[43]
Y . Wang, X. Chen, X. Ma, S. Zhou, Z. Huang, Y . Wang, C. Yang, Y . He, J. Yu, P. Yang, et al. Lavie: High-quality video generation with cascaded latent diffusion models.International Journal of Computer Vision, 133(5):3059–3078, 2025
work page 2025
-
[44]
J. Z. Wu, Y . Ge, X. Wang, S. W. Lei, Y . Gu, Y . Shi, W. Hsu, Y . Shan, X. Qie, and M. Z. Shou. Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation. InProceedings of the IEEE/CVF international conference on computer vision, pages 7623–7633, 2023
work page 2023
-
[45]
J. Xu, X. Liu, Y . Wu, Y . Tong, Q. Li, M. Ding, J. Tang, and Y . Dong. Imagereward: Learning and evaluating human preferences for text-to-image generation.Advances in Neural Information Processing Systems, 36:15903–15935, 2023
work page 2023
-
[46]
Z. Xue, J. Wu, Y . Gao, F. Kong, L. Zhu, M. Chen, Z. Liu, W. Liu, Q. Guo, W. Huang, et al. Dancegrpo: Unleashing grpo on visual generation.arXiv preprint arXiv:2505.07818, 2025
work page internal anchor Pith review arXiv 2025
-
[47]
Z. Yang, J. Teng, W. Zheng, M. Ding, S. Huang, J. Xu, Y . Yang, W. Hong, X. Zhang, G. Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer. InThe Thirteenth International Conference on Learning Representations, 2024
work page 2024
-
[48]
H. Yuan, S. Zhang, X. Wang, Y . Wei, T. Feng, Y . Pan, Y . Zhang, Z. Liu, S. Albanie, and D. Ni. Instructvideo: Instructing video diffusion models with human feedback. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6463–6474, 2024
work page 2024
- [49]
-
[50]
VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness
D. Zheng, Z. Huang, H. Liu, K. Zou, Y . He, F. Zhang, Y . Zhang, J. He, W.-S. Zheng, Y . Qiao, and Z. Liu. VBench-2.0: Advancing video generation benchmark suite for intrinsic faithfulness.arXiv preprint arXiv:2503.21755, 2025
work page internal anchor Pith review arXiv 2025
-
[51]
DiffusionNFT: Online Diffusion Reinforcement with Forward Process
K. Zheng, H. Chen, H. Ye, H. Wang, Q. Zhang, K. Jiang, H. Su, S. Ermon, J. Zhu, and M.-Y . Liu. Diffusionnft: Online diffusion reinforcement with forward process.arXiv preprint arXiv:2509.16117, 2025
work page internal anchor Pith review arXiv 2025
-
[52]
Magicvideo: Efficient video generation with latent diffusion models
D. Zhou, W. Wang, H. Yan, W. Lv, Y . Zhu, and J. Feng. Magicvideo: Efficient video generation with latent diffusion models.arXiv preprint arXiv:2211.11018, 2022. 12 A Limitations Although Diffusion-APO effectively mitigates train-inference timestep discrepancies, its optimization efficacy remains fundamentally bottlenecked by the fidelity of the preferenc...
-
[53]
Primary Criterion - Degree of Visual Distortion: • a) Severe Defects:Anomalies violating physical laws (e.g., anti-gravity cars, unnatural movement of objects without applied force), unnatural transitions/black screens/objects appearing or disappearing out of nowhere, severe anatomical distortions (severed limbs, misplaced facial features), or visible mos...
-
[54]
• Avoid selecting completely static or nearly motionless videos
Secondary Criterion - Dynamic Performance: • When both videos have no obvious distortions, prioritize the video with larger motion amplitude and a more vibrant visual dynamic. • Avoid selecting completely static or nearly motionless videos. Please compare Video 1 and Video 2, and outputONLYone of the following four options:
-
[55]
Video 1 has a lower degree of visual distortion
-
[56]
Video 2 has a lower degree of visual distortion
-
[57]
Both videos have similar degrees of distortion, but Video 1 features larger camera movement or richer human actions
-
[58]
Both videos have similar degrees of distortion, but Video 2 features larger camera movement or richer human actions. Prompt for Non-Human-Centric Videos <video><video> You are sequentially given two videos, Video 1 and Video 2. Please strictly evaluate them based on the following criteria and select the better video: Evaluate whether the following issues ...
-
[59]
• Unnatural twisting, deformation, merging, or blurring of objects
Severe Visual Anomalies (Any occurrence leads to an immediate low-quality rejec- tion): • Motions violating physical laws (unnatural movement/jittering/floating of objects without applied forces). • Unnatural twisting, deformation, merging, or blurring of objects. • Appearance of mosaics or digital glitches. • Sudden visual jumps, PPT-like fading, or disc...
-
[60]
• Sudden appearance of mosaics in the frame
Obvious Visual Issues: • Abnormal surface textures (suddenly floating, warping, or distorting). • Sudden appearance of mosaics in the frame. • Unnatural material representation (e.g., sudden changes in leather or metal textures). • Unnatural blurring or over-sharpening of object edges. • Illogical dynamic changes in patterns, motifs, or text. • Shadows an...
-
[61]
Visual Coherence Issues: • Discontinuous object motion trajectories. • Unnatural scene transitions. • Camera shaking or jittering
-
[62]
Dynamic Performance Evaluation: • Visual changes should be natural and smooth; avoid selecting essentially static videos. • When visual quality is comparable, prioritize the video with natural camera movements and dynamic visual changes. Please strictly inspect each video for the above issues, paying primary attention to Severe Visual Anomalies. If any se...
-
[63]
Video 1 has a lower degree of visual distortion/anomalies
-
[64]
Video 2 has a lower degree of visual distortion/anomalies
-
[65]
Both videos have similar degrees of distortion, but Video 1 features larger/better camera movement
-
[66]
Both videos have similar degrees of distortion, but Video 2 features larger/better camera movement. C.3 Evaluation Performance Evaluated on strictly aligned internal human-preference test sets, our specialized ranking models demonstrate exceptional precision and recall. TheHuman-Centric Ranking Modelachieves accuracy/recall rates of 91.8% and 94.2% across...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.