Recognition: no theorem link
Can LLMs Solve Science or Just Write Code? Evaluating Quantum Solver Generation
Pith reviewed 2026-05-12 04:15 UTC · model grok-4.3
The pith
Iterative refinement against classical results raises LLM success at generating quantum solvers, but numerical inaccuracies remain the dominant failure mode in stronger models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
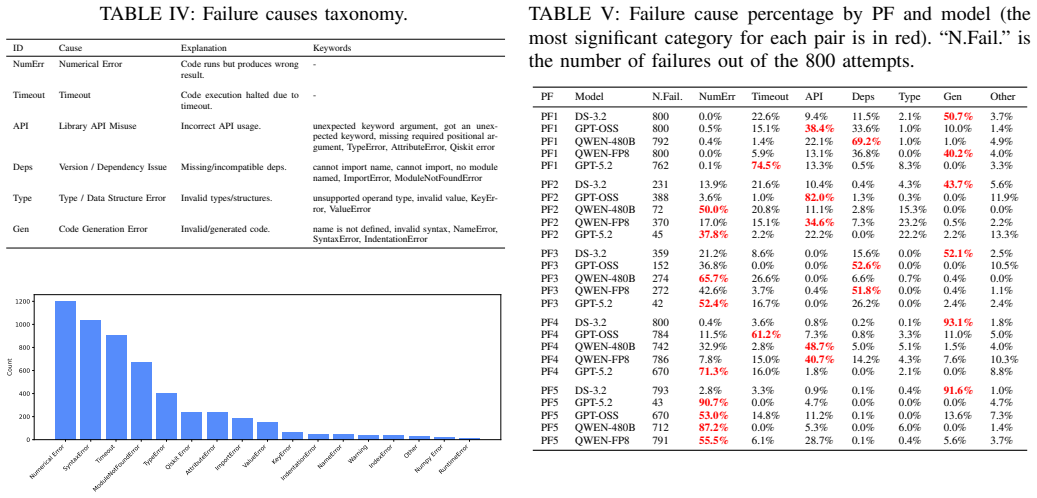
Q-SAGE demonstrates that an iterative generate-execute-compare-refine cycle can increase the fraction of LLM-generated quantum solvers that match classical reference results within tolerance across multiple problem classes, yet the same cycle reveals that more capable models primarily fail by returning numerically inaccurate outputs rather than by producing non-executable code.
What carries the argument
Q-SAGE, the iterative refinement loop that runs the LLM-generated quantum script, compares its numerical output to a classical solver, and feeds the discrepancy back for script revision until agreement falls inside a tolerance threshold.
If this is right
- Iterative refinement can substantially increase the rate at which LLM-generated quantum solvers produce acceptable numerical results.
- The added loop raises total computational cost through repeated executions and comparisons.
- More powerful models move their errors from execution failures to numerical inaccuracies.
- LLM-based quantum software generation still requires external verification to reach scientific reliability.
Where Pith is reading between the lines
- The same verification loop could be applied to other scientific computing tasks where a classical reference oracle exists.
- Tolerance thresholds must be chosen with domain-specific knowledge, since loose values may mask real algorithmic errors.
- The observed shift in failure modes suggests that future work on LLM quantum code should target numerical stability rather than syntax alone.
Load-bearing premise
That numerical agreement with a classical solver within a fixed tolerance is sufficient proof that the generated quantum code is scientifically correct.
What would settle it
A case in which an LLM-generated solver matches the classical result within tolerance on the test instances but deviates on a slight variant of the problem or under different parameter values.
Figures




read the original abstract
Large Language Models (LLMs) show strong capabilities in code generation, motivating their use in automated quantum solver development. However, in quantum computing, successful execution of generated code is not sufficient: correctness depends on numerically accurate results, which are sensitive to non-trivial mappings, hybrid quantum-classical workflows, and algorithm-specific approximations. This work introduces Q-SAGE, an iterative methodology to evaluate LLMs' capability in generating quantum solvers for scientific problems. The methodology adopts an iterative approach by executing the script generated by the LLM, comparing the result with the result of a classical solver, and refining the script until the two results match within a tolerance threshold. We empirically evaluated the methodology with five families of scientific problems of different complexities and five LLMs, both open source and proprietary. The results show that iterative refinement substantially improves success rates, but introduces a significant computational overhead. Moreover, as model capability increases, failure modes shift from execution errors to numerical inaccuracies, highlighting the current limitations of LLM-based quantum software.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Q-SAGE, an iterative methodology in which LLMs generate quantum solver scripts, execute them, compare outputs to classical solver results within a tolerance, and refine until agreement. It evaluates five LLMs on five families of scientific problems, reporting that iteration raises success rates at the cost of overhead and that stronger models shift from execution errors to numerical inaccuracies.
Significance. If the experimental protocol is fully specified and reproducible, the work would usefully document current limits of LLM-generated quantum code for scientific use, particularly the observation that capability gains move failures downstream to numerical fidelity rather than syntax or runtime errors.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experimental Evaluation): success rates, improvement from iteration, and the reported shift in failure modes are presented without stating the number of trials per LLM-problem pair, the exact tolerance thresholds applied to each problem family, the statistical tests used, or the procedure for selecting the five problem families. These omissions are load-bearing for all quantitative claims.
- [§3] §3 (Q-SAGE Methodology): success is declared when the LLM-generated script's output matches a classical solver result inside an unspecified tolerance. This treats the classical result as ground truth and does not address whether mismatches could stem from valid quantum approximations, hybrid workflow choices, or floating-point behavior rather than LLM defects. The central evaluation loop therefore risks overstating correctness.
minor comments (2)
- [§1] The five problem families and their complexities are referenced in the abstract but not enumerated with concrete examples or references in the main text; this should be added for reproducibility.
- [§3] Notation for the tolerance threshold and the refinement loop termination condition is introduced without a dedicated equation or pseudocode block.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and indicate the revisions made to improve clarity, reproducibility, and balance in the evaluation.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experimental Evaluation): success rates, improvement from iteration, and the reported shift in failure modes are presented without stating the number of trials per LLM-problem pair, the exact tolerance thresholds applied to each problem family, the statistical tests used, or the procedure for selecting the five problem families. These omissions are load-bearing for all quantitative claims.
Authors: We agree these details are necessary for full reproducibility and to support the quantitative claims. In the revised version, §4 now specifies 10 independent trials per LLM-problem pair, the exact tolerance thresholds used for each family (1e-6 for linear systems and eigenvalue problems, 1e-4 for optimization and simulation tasks), the use of paired t-tests to assess significance of iteration improvements, and the selection procedure for the five problem families (chosen for diversity in computational complexity, presence of known classical reference implementations, and relevance to quantum algorithm benchmarks). The abstract has been updated to note these experimental parameters. revision: yes
-
Referee: [§3] §3 (Q-SAGE Methodology): success is declared when the LLM-generated script's output matches a classical solver result inside an unspecified tolerance. This treats the classical result as ground truth and does not address whether mismatches could stem from valid quantum approximations, hybrid workflow choices, or floating-point behavior rather than LLM defects. The central evaluation loop therefore risks overstating correctness.
Authors: The concern is valid: classical results serve as a practical reference but cannot capture every valid quantum approximation or hybrid design choice. We have revised §3 to state the assumption explicitly (problems were selected only where exact classical solutions exist), to describe how the tolerance is set to accommodate floating-point variation, and to add a limitations paragraph acknowledging that numerical agreement does not prove the absence of deeper algorithmic issues. The evaluation loop is framed as a pragmatic correctness proxy rather than an absolute proof of correctness. revision: partial
Circularity Check
No circularity: purely empirical evaluation against external classical solvers
full rationale
The paper describes an iterative empirical methodology (Q-SAGE) that generates code with LLMs, executes it, and checks numerical agreement against independent classical solver outputs for five problem families. No mathematical derivations, fitted parameters, ansatzes, or uniqueness theorems appear in the provided text or abstract. Success is defined by external comparison rather than any internal self-referential construction. Self-citations, if present, are not load-bearing for any claimed result. This matches the default case of a self-contained empirical study with no reduction of outputs to inputs by definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Classical solvers provide accurate ground truth for the chosen quantum problems
Reference graph
Works this paper leans on
-
[1]
Simulating physics with computers,
R. P. Feynman, “Simulating physics with computers,” inFeynman and computation. cRc Press, 2018, pp. 133–153
work page 2018
-
[2]
Quantum chemistry in the age of quantum computing,
Y . Cao, J. Romero, J. P. Olson, M. Degroote, P. D. Johnson, M. Kieferov ´a, I. D. Kivlichan, T. Menke, B. Peropadre, N. P. Sawaya et al., “Quantum chemistry in the age of quantum computing,”Chemical reviews, vol. 119, no. 19, pp. 10 856–10 915, 2019
work page 2019
-
[3]
Quantum computational chemistry,
S. McArdle, S. Endo, A. Aspuru-Guzik, S. C. Benjamin, and X. Yuan, “Quantum computational chemistry,”Reviews of Modern Physics, vol. 92, no. 1, p. 015003, 2020
work page 2020
-
[4]
M. A. Nielsen and I. L. Chuang,Quantum computation and quantum information. Cambridge university press, 2010
work page 2010
-
[5]
Quantum software engineering: Roadmap and challenges ahead,
J. M. Murillo, J. Garcia-Alonso, E. Moguel, J. Barzen, F. Leymann, S. Ali, T. Yue, P. Arcaini, R. P ´erez-Castillo, I. Garc ´ıa-Rodr´ıguez de Guzm´an, M. Piattini, A. Ruiz-Cort ´es, A. Brogi, J. Zhao, A. Miranskyy, and M. Wimmer, “Quantum software engineering: Roadmap and challenges ahead,”ACM Trans. Softw. Eng. Methodol., vol. 34, no. 5, May 2025. [Onlin...
-
[6]
LLMLOOP: Improving LLM-generated code and tests through auto- mated iterative feedback loops,
R. Ravi, D. Bradshaw, S. Ruberto, G. Jahangirova, and V . Terragni, “LLMLOOP: Improving LLM-generated code and tests through auto- mated iterative feedback loops,” in2025 IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, 2025, pp. 930–934
work page 2025
-
[7]
Using ChatGPT to enhance learning in physics courses for engineers,
V . Robledo-Rella, A. Gonzalez-Nucamendi, L. Neri, R. M. Garc ´ıa- Castel´an, and J. Noguez, “Using ChatGPT to enhance learning in physics courses for engineers,” inICERI2023 Proceedings. IATED, 2023, pp. 9044–9050
work page 2023
-
[8]
ChatGPT in physics education: A pilot study on easy-to- implement activities,
P. Bitzenbauer, “ChatGPT in physics education: A pilot study on easy-to- implement activities,”Contemporary Educational Technology, vol. 15, no. 3, p. ep430, 2023
work page 2023
-
[9]
Quantum many-body physics calculations with large language models,
H. Pan, N. Mudur, W. Taranto, M. Tikhanovskaya, S. Venugopalan, Y . Bahri, M. P. Brenner, and E.-A. Kim, “Quantum many-body physics calculations with large language models,”Communications Physics, vol. 8, no. 1, p. 49, 2025
work page 2025
-
[10]
A PennyLane-Centric Dataset to Enhance LLM-based Quantum Code Generation using RAG
A. Basit, N. Innan, M. H. Asif, M. Shao, M. Kashif, A. Marchisio, and M. Shafique, “Pennylang: Pioneering llm-based quantum code generation with a novel pennylane-centric dataset,”arXiv preprint arXiv:2503.02497, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
https: //arxiv.org/abs/2504.14557 15
C. Campbell, H. M. Chen, W. Luk, and H. Fan, “Enhancing LLM-based quantum code generation with multi-agent optimization and quantum error correction,”arXiv preprint arXiv:2504.14557, 2025
-
[12]
Quanbench: Benchmarking quan- tum code generation with large language models,
X. Guo, M. Wang, and J. Zhao, “Quanbench: Benchmarking quan- tum code generation with large language models,”arXiv preprint arXiv:2510.16779, 2025
-
[13]
Programming quantum computers with large language models,
E. R. Henderson, J. M. Henderson, J. Ange, and M. A. Thornton, “Programming quantum computers with large language models,” arXiv preprint, vol. arXiv:2506.18125, 2025. [Online]. Available: https://arxiv.org/abs/2506.18125
-
[14]
Solving strongly correlated electron models on a quantum computer,
D. Wecker, M. B. Hastings, N. Wiebe, B. K. Clark, C. Nayak, and M. Troyer, “Solving strongly correlated electron models on a quantum computer,”Physical Review A, vol. 92, no. 6, p. 062318, 2015
work page 2015
-
[15]
Many-body physics with individually controlled rydberg atoms,
A. Browaeys and T. Lahaye, “Many-body physics with individually controlled rydberg atoms,”Nature Physics, vol. 16, no. 2, pp. 132–142, 2020
work page 2020
-
[16]
The hub- bard model: A computational perspective,
M. Qin, T. Sch ¨afer, S. Andergassen, P. Corboz, and E. Gull, “The hub- bard model: A computational perspective,”Annual Review of Condensed Matter Physics, vol. 13, no. 1, pp. 275–302, 2022
work page 2022
-
[17]
S. Stanisic, J. L. Bosse, F. M. Gambetta, R. A. Santos, W. Mruczkiewicz, T. E. O’Brien, E. Ostby, and A. Montanaro, “Observing ground-state properties of the fermi-hubbard model using a scalable algorithm on a quantum computer,”Nature communications, vol. 13, no. 1, p. 5743, 2022
work page 2022
-
[18]
Ising formulations of many np problems,
A. Lucas, “Ising formulations of many np problems,”Frontiers in physics, vol. 2, p. 74887, 2014
work page 2014
-
[19]
A variational eigenvalue solver on a photonic quantum processor,
A. Peruzzo, J. McClean, P. Shadbolt, M.-H. Yung, X.-Q. Zhou, P. J. Love, A. Aspuru-Guzik, and J. L. O’brien, “A variational eigenvalue solver on a photonic quantum processor,”Nature communications, vol. 5, no. 1, p. 4213, 2014
work page 2014
-
[20]
Real-time dynamics of lattice gauge theories with a few-qubit quantum computer,
E. A. Martinez, C. A. Muschik, P. Schindler, D. Nigg, A. Erhard, M. Heyl, P. Hauke, M. Dalmonte, T. Monz, P. Zolleret al., “Real-time dynamics of lattice gauge theories with a few-qubit quantum computer,” Nature, vol. 534, no. 7608, pp. 516–519, 2016
work page 2016
-
[21]
Self-verifying variational quantum simulation of lattice models,
C. Kokail, C. Maier, R. van Bijnen, T. Brydges, M. K. Joshi, P. Jurcevic, C. A. Muschik, P. Silvi, R. Blatt, C. F. Rooset al., “Self-verifying variational quantum simulation of lattice models,”Nature, vol. 569, no. 7756, pp. 355–360, 2019
work page 2019
-
[22]
Digital quantum simulation of the schwinger model and symmetry protection with trapped ions,
N. H. Nguyen, M. C. Tran, Y . Zhu, A. M. Green, C. H. Alderete, Z. Davoudi, and N. M. Linke, “Digital quantum simulation of the schwinger model and symmetry protection with trapped ions,”PRX quantum, vol. 3, no. 2, p. 020324, 2022
work page 2022
-
[23]
Quantum computing for high-energy physics: State of the art and challenges,
A. Di Meglio, K. Jansen, I. Tavernelli, C. Alexandrou, S. Arunachalam, C. W. Bauer, K. Borras, S. Carrazza, A. Crippa, V . Croftet al., “Quantum computing for high-energy physics: State of the art and challenges,”Prx quantum, vol. 5, no. 3, p. 037001, 2024
work page 2024
-
[24]
Ground-state energy estimation of the water molecule on a trapped-ion quantum computer,
Y . Nam, J.-S. Chen, N. C. Pisenti, K. Wright, C. Delaney, D. Maslov, K. R. Brown, S. Allen, J. M. Amini, J. Apisdorfet al., “Ground-state energy estimation of the water molecule on a trapped-ion quantum computer,”npj Quantum Information, vol. 6, no. 1, p. 33, 2020
work page 2020
-
[25]
Evaluating the evidence for expo- nential quantum advantage in ground-state quantum chemistry,
S. Lee, J. Lee, H. Zhai, Y . Tong, A. M. Dalzell, A. Kumar, P. Helms, J. Gray, Z.-H. Cui, W. Liuet al., “Evaluating the evidence for expo- nential quantum advantage in ground-state quantum chemistry,”Nature communications, vol. 14, no. 1, p. 1952, 2023
work page 1952
-
[26]
A survey on large language models for code generation.ACM Trans
J. Jiang, F. Wang, J. Shen, S. Kim, and S. Kim, “A survey on large language models for code generation,”ACM Trans. Softw. Eng. Methodol., vol. 35, no. 2, Jan. 2026. [Online]. Available: https://doi.org/10.1145/3747588
-
[27]
Exploring LLM-driven expla- nations for quantum algorithms,
G. d’Aloisio, S. Fortz, C. Hanna, D. Fortunato, A. Bensoussan, E. Mendiluze Usandizaga, and F. Sarro, “Exploring LLM-driven expla- nations for quantum algorithms,” inProceedings of the 18th ACM/IEEE international symposium on empirical software engineering and mea- surement, 2024, pp. 475–481
work page 2024
-
[28]
A. Tranter, P. J. Love, F. Mintert, and P. V . Coveney, “A comparison of the bravyi–kitaev and jordan–wigner transformations for the quantum simulation of quantum chemistry,”Journal of chemical theory and computation, vol. 14, no. 11, pp. 5617–5630, 2018
work page 2018
-
[29]
The bravyi-kitaev transfor- mation for quantum computation of electronic structure,
J. T. Seeley, M. J. Richard, and P. J. Love, “The bravyi-kitaev transfor- mation for quantum computation of electronic structure,”The Journal of chemical physics, vol. 137, no. 22, 2012
work page 2012
-
[30]
Fermionic quantum computation,
S. B. Bravyi and A. Y . Kitaev, “Fermionic quantum computation,” Annals of Physics, vol. 298, no. 1, pp. 210–226, 2002
work page 2002
-
[31]
Quantum measurements and the Abelian Stabilizer Problem
A. Y . Kitaev, “Quantum measurements and the abelian stabilizer prob- lem,”arXiv preprint quant-ph/9511026, 1995
work page internal anchor Pith review arXiv 1995
-
[32]
Initial state preparation for quantum chemistry on quantum computers,
S. Fomichev, K. Hejazi, M. S. Zini, M. Kiser, J. Fraxanet, P. A. M. Casares, A. Delgado, J. Huh, A.-C. V oigt, J. E. Muelleret al., “Initial state preparation for quantum chemistry on quantum computers,”PRX Quantum, vol. 5, no. 4, p. 040339, 2024
work page 2024
-
[33]
Perspectives of quantum annealing: Methods and implementations,
P. Hauke, H. G. Katzgraber, W. Lechner, H. Nishimori, and W. D. Oliver, “Perspectives of quantum annealing: Methods and implementations,” Reports on Progress in Physics, vol. 83, no. 5, p. 054401, 2020
work page 2020
-
[34]
S. Lloyd, “Universal quantum simulators,”Science, vol. 273, no. 5278, pp. 1073–1078, 1996
work page 1996
-
[35]
Hamiltonian simulation algorithms for near-term quantum hardware,
L. Clinton, J. Bausch, and T. Cubitt, “Hamiltonian simulation algorithms for near-term quantum hardware,”Nature communications, vol. 12, no. 1, p. 4989, 2021
work page 2021
-
[36]
End-to-end complexity for simulating the schwinger model on quantum computers,
K. Sakamoto, H. Morisaki, J. Haruna, E. Itou, K. Fujii, and K. Mitarai, “End-to-end complexity for simulating the schwinger model on quantum computers,”Quantum, vol. 8, p. 1474, 2024
work page 2024
-
[37]
From quantum matter to high-temperature superconductivity in copper oxides,
B. Keimer, S. A. Kivelson, M. R. Norman, S. Uchida, and J. Zaanen, “From quantum matter to high-temperature superconductivity in copper oxides,”Nature, vol. 518, no. 7538, pp. 179–186, 2015
work page 2015
-
[38]
Dynamical quantum phase transitions in the transverse-field ising model,
M. Heyl, A. Polkovnikov, and S. Kehrein, “Dynamical quantum phase transitions in the transverse-field ising model,”Physical review letters, vol. 110, no. 13, p. 135704, 2013
work page 2013
-
[39]
Quantum annealing in the transverse ising model,
T. Kadowaki and H. Nishimori, “Quantum annealing in the transverse ising model,”Physical Review E, vol. 58, no. 5, p. 5355, 1998
work page 1998
-
[40]
Simulated quantum computation of molecular energies,
A. Aspuru-Guzik, A. D. Dutoi, P. J. Love, and M. Head-Gordon, “Simulated quantum computation of molecular energies,”Science, vol. 309, no. 5741, pp. 1704–1707, 2005
work page 2005
-
[41]
A. Arcuri and L. Briand, “A practical guide for using statistical tests to assess randomized algorithms in software engineering,” inIntl. Conf. on Software Engineering, 2011, pp. 1–10
work page 2011
-
[42]
A critique and improvement of the cl common language effect size statistics of mcgraw and wong,
A. Vargha and H. D. Delaney, “A critique and improvement of the cl common language effect size statistics of mcgraw and wong,”Journal of Educational and Behavioral Statistics, vol. 25, no. 2, pp. 101–132, 2000
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.