Recognition: 2 theorem links
· Lean TheoremWhy Self-Inconsistency Arises in GNN Explanations and How to Exploit It
Pith reviewed 2026-05-11 02:10 UTC · model grok-4.3
The pith
Self-inconsistency in GNN explanations arises from context perturbation during re-explanation and is corrected by Self-Denoising in one pass
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Re-explanation-induced context perturbation is the direct cause of score variation in SI-GNN explanations; only edges whose latent signals are unstable to this perturbation become self-inconsistent, and Self-Denoising exploits the variation by calibrating the explanation subgraph in one additional forward pass.
What carries the argument
Self-Denoising (SD), a training-free post-processing step that compares original and re-explained importance scores to detect and adjust self-inconsistent edges caused by context perturbation
If this is right
- Self-inconsistent edges are identified simply by running the model once more on the explanation subgraph and comparing scores.
- Adjusting or removing these edges raises the fidelity of the explanation to the model's true decision process.
- The correction works on any SI-GNN without retraining or changes to the underlying architecture.
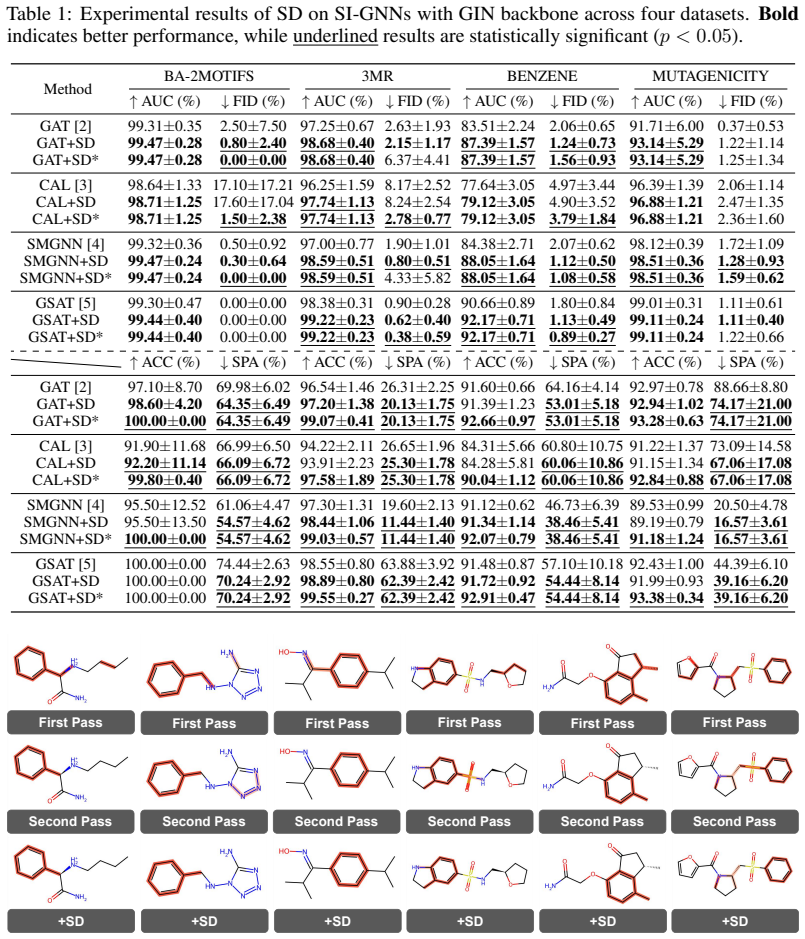
- Explanation quality improves across multiple frameworks, backbones, and datasets while adding only 4-6 percent computational cost.
- Conciseness regularization during explanation generation modulates how many edges exhibit unstable latent signals.
Where Pith is reading between the lines
- Explanation methods for other structured data may exhibit analogous inconsistency when subset selection changes surrounding context.
- Stability under re-application could become a standard diagnostic for any subgraph-based explanation technique.
- Explicitly encouraging stable signal assignment during model training might reduce the need for post-processing corrections.
- The same perturbation analysis could be applied to detect brittle explanations in non-graph models where input masking alters predictions.
Load-bearing premise
That edges whose importance scores change when the model is reapplied to the explanation subgraph do not provide stable evidence for the original prediction and that adjusting them therefore produces a more faithful explanation.
What would settle it
Measure whether the denoised explanation subgraph, when fed back to the model, produces both the original prediction and consistent importance scores on a second re-explanation, and compare the result against standard faithfulness metrics on benchmark datasets.
Figures




















read the original abstract
Recent work has observed that explanations produced by Self-Interpretable Graph Neural Networks (SI-GNNs) can be self-inconsistent: when the model is reapplied to its own explanatory graph subset, it may produce a different explanation. However, why self-inconsistency arises remains poorly understood. In this work, we first identify re-explanation-induced context perturbation as the direct cause of score variation. We then introduce a latent signal assignment hypothesis to explain why only some edges are sensitive to this perturbation, and analyze how conciseness regularization affects latent signal assignment. Given that self-inconsistent edges do not provide stable evidence for the model's prediction, we propose Self-Denoising (SD), a model-agnostic and training-free post-processing strategy that calibrates explanations with only one additional forward pass. Experiments across representative SI-GNN frameworks, backbone architectures, and benchmark datasets support our hypothesis and show that SD consistently improves explanation quality while adding only about 4--6\% computational overhead in practice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that self-inconsistency in explanations from Self-Interpretable Graph Neural Networks (SI-GNNs) arises due to re-explanation-induced context perturbation. It introduces a latent signal assignment hypothesis to account for why certain edges are sensitive to this perturbation, analyzes the role of conciseness regularization in modulating such assignments, and concludes that self-inconsistent edges lack stable evidence for the original prediction. Building on this, the authors propose Self-Denoising (SD), a model-agnostic and training-free post-processing method that calibrates explanations using only one additional forward pass, with experiments across SI-GNN frameworks, backbone architectures, and benchmark datasets purportedly showing consistent improvements in explanation quality at 4-6% added computational cost.
Significance. If the hypothesis is correct and SD demonstrably improves explanation fidelity without introducing re-explanation artifacts, the work would offer a practical, low-overhead contribution to GNN explainability. The training-free and model-agnostic nature, combined with the modest overhead, would make it readily adoptable. The analysis of context perturbation and regularization effects could also inform future SI-GNN design.
major comments (2)
- [Abstract and hypothesis section] Abstract and the section introducing the latent signal assignment hypothesis: the load-bearing claim that self-inconsistent edges 'do not provide stable evidence for the model's prediction' (and thus that adjusting them via SD improves fidelity) is inferred directly from score variation on the re-explained subgraph. No independent, ground-truth-free probe (such as measuring original-graph prediction agreement after masking the identified edges) is described to rule out the alternative that the inconsistency reflects valid context-dependent signals or re-explanation artifacts.
- [Experiments] Experimental section: the abstract asserts that experiments 'support our hypothesis and show that SD consistently improves explanation quality,' yet the manuscript provides no details on the precise fidelity metrics used, statistical tests, controls for re-explanation artifacts, or ablation isolating the effect of the latent signal assignment step from simple score thresholding.
minor comments (2)
- [Hypothesis and analysis] The definition and quantification of 'latent signal assignment' should be formalized (e.g., via an equation) to make the analysis of conciseness regularization reproducible.
- [Experiments] Computational overhead claims (4-6%) would benefit from a breakdown showing the cost of the additional forward pass versus any post-processing steps.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, indicating the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and hypothesis section] Abstract and the section introducing the latent signal assignment hypothesis: the load-bearing claim that self-inconsistent edges 'do not provide stable evidence for the model's prediction' (and thus that adjusting them via SD improves fidelity) is inferred directly from score variation on the re-explained subgraph. No independent, ground-truth-free probe (such as measuring original-graph prediction agreement after masking the identified edges) is described to rule out the alternative that the inconsistency reflects valid context-dependent signals or re-explanation artifacts.
Authors: We acknowledge that the claim is primarily supported by the observed score variation under re-explanation-induced context perturbation, as described in our latent signal assignment hypothesis. While this variation indicates instability in the assigned signals, we agree that an independent validation would strengthen the argument against alternatives such as valid context-dependent signals. In the revised manuscript, we will add a new analysis that measures the original model's prediction change on the full graph after masking the self-inconsistent edges identified by our method. This ground-truth-free probe will help confirm that these edges do not provide stable evidence and will be reported alongside the existing results. revision: yes
-
Referee: [Experiments] Experimental section: the abstract asserts that experiments 'support our hypothesis and show that SD consistently improves explanation quality,' yet the manuscript provides no details on the precise fidelity metrics used, statistical tests, controls for re-explanation artifacts, or ablation isolating the effect of the latent signal assignment step from simple score thresholding.
Authors: We agree that the experimental section would benefit from greater detail to support the claims. In the revision, we will expand it to: (1) explicitly define the fidelity metrics (e.g., how prediction agreement and explanation quality are quantified on the original graph to avoid re-explanation bias); (2) report statistical significance using paired tests such as the Wilcoxon signed-rank test across multiple random seeds and datasets; (3) describe controls for re-explanation artifacts, including comparisons against random perturbations of the same magnitude; and (4) include an ablation study that isolates the latent signal assignment step from simple score thresholding. These additions will clarify the specific contributions of our hypothesis and method. revision: yes
Circularity Check
No significant circularity; derivation remains independent of inputs
full rationale
The paper observes self-inconsistency via re-explanation, introduces a hypothesis for its cause (context perturbation and latent signal assignment), and defines Self-Denoising as a post-processing step that uses one additional forward pass to identify and calibrate inconsistent edges. This does not reduce any claimed prediction or result to a fitted quantity or self-citation by construction; the method is explicitly algorithmic and its benefits are asserted via external experiments on multiple frameworks and datasets rather than being equivalent to the initial observations. No load-bearing step matches the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions underlying self-interpretable GNN frameworks and existing explanation evaluation metrics
invented entities (1)
-
latent signal assignment
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We first identify re-explanation-induced context perturbation as the direct cause of score variation. We then introduce a latent signal assignment hypothesis...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Self-consistency improves the trustworthiness of self-interpretable gnns
Wenxin Tai, Ting Zhong, Goce Trajcevski, and Fan Zhou. Self-consistency improves the trustworthiness of self-interpretable gnns. InICLR, 2026
work page 2026
-
[2]
Petar Velickovic, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, and Yoshua Bengio. Graph attention networks. InICLR, 2018
work page 2018
-
[3]
Causal attention for interpretable and generalizable graph classification
Yongduo Sui, Xiang Wang, Jiancan Wu, Min Lin, Xiangnan He, and Tat-Seng Chua. Causal attention for interpretable and generalizable graph classification. InKDD, 2022
work page 2022
-
[4]
Beyond topological self-explainable gnns: A formal explainability perspective
Steve Azzolin, Sagar Malhotra, Andrea Passerini, and Stefano Teso. Beyond topological self-explainable gnns: A formal explainability perspective. InICML, 2025
work page 2025
-
[5]
Interpretable and generalizable graph learning via stochastic attention mechanism
Siqi Miao, Mia Liu, and Pan Li. Interpretable and generalizable graph learning via stochastic attention mechanism. InICML, 2025
work page 2025
-
[6]
Gnnexplainer: Generating explanations for graph neural networks.NeurIPS, 2019
Zhitao Ying, Dylan Bourgeois, Jiaxuan You, Marinka Zitnik, and Jure Leskovec. Gnnexplainer: Generating explanations for graph neural networks.NeurIPS, 2019
work page 2019
-
[7]
Parameterized explainer for graph neural network.NeurIPS, 2020
Dongsheng Luo, Wei Cheng, Dongkuan Xu, Wenchao Yu, Bo Zong, Haifeng Chen, and Xiang Zhang. Parameterized explainer for graph neural network.NeurIPS, 2020
work page 2020
-
[8]
Towards inductive and efficient explanations for graph neural networks.IEEE TPAMI, 2024
Dongsheng Luo, Tianxiang Zhao, Wei Cheng, Dongkuan Xu, Feng Han, Wenchao Yu, Xiao Liu, Haifeng Chen, and Xiang Zhang. Towards inductive and efficient explanations for graph neural networks.IEEE TPAMI, 2024
work page 2024
-
[9]
Cynthia Rudin. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead.Nature Machine Intelligence, 2019
work page 2019
-
[10]
Ronilo Ragodos, Tong Wang, Lu Feng, et al. From model explanation to data misinterpretation: Uncovering the pitfalls of post hoc explainers in business research.Arxiv, 2024
work page 2024
-
[11]
Redundancy undermines the trustworthiness of self-interpretable gnns
Wenxin Tai, Ting Zhong, Goce Trajcevski, and Fan Zhou. Redundancy undermines the trustworthiness of self-interpretable gnns. InICML, 2025
work page 2025
-
[12]
Attention is all you need.NeurIPS, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.NeurIPS, 2017
work page 2017
-
[13]
Interpretation and identification of causal mediation.Psychological Methods, 2014
Judea Pearl. Interpretation and identification of causal mediation.Psychological Methods, 2014
work page 2014
-
[14]
Discovering invariant rationales for graph neural networks
Yingxin Wu, Xiang Wang, An Zhang, Xiangnan He, and Tat-Seng Chua. Discovering invariant rationales for graph neural networks. InICLR, 2022
work page 2022
-
[15]
Graph neural networks including sparse interpretability.ArXiv, 2020
Chris Lin, Gerald J Sun, Krishna C Bulusu, Jonathan R Dry, and Marylens Hernandez. Graph neural networks including sparse interpretability.ArXiv, 2020
work page 2020
-
[16]
Graph information bottleneck for subgraph recognition
Junchi Yu, Tingyang Xu, Yu Rong, Yatao Bian, Junzhou Huang, and Ran He. Graph information bottleneck for subgraph recognition. InICLR, 2021
work page 2021
-
[17]
Improving subgraph recognition with variational graph information bottleneck
Junchi Yu, Jie Cao, and Ran He. Improving subgraph recognition with variational graph information bottleneck. InCVPR, pages 19396–19405, 2022
work page 2022
-
[18]
On explainability of graph neural networks via subgraph explorations
Hao Yuan, Haiyang Yu, Jie Wang, Kang Li, and Shuiwang Ji. On explainability of graph neural networks via subgraph explorations. InICML, 2021
work page 2021
-
[19]
Protgnn: Towards self-explaining graph neural networks
Zaixi Zhang, Qi Liu, Hao Wang, Chengqiang Lu, and Cheekong Lee. Protgnn: Towards self-explaining graph neural networks. InAAAI, 2022
work page 2022
-
[20]
A comprehensive survey on self-interpretable neural networks.Proceedings of the IEEE, 2025
Yang Ji, Ying Sun, Yuting Zhang, Zhigaoyuan Wang, Yuanxin Zhuang, Zheng Gong, Dazhong Shen, Chuan Qin, Hengshu Zhu, and Hui Xiong. A comprehensive survey on self-interpretable neural networks.Proceedings of the IEEE, 2025
work page 2025
-
[21]
Discovery of a structural class of antibiotics with explainable deep learning.Nature, 2024
Felix Wong, Erica J Zheng, Jacqueline A Valeri, Nina M Donghia, Melis N Anahtar, Satotaka Omori, Alicia Li, Andres Cubillos-Ruiz, Aarti Krishnan, Wengong Jin, et al. Discovery of a structural class of antibiotics with explainable deep learning.Nature, 2024. 10
work page 2024
-
[22]
Jiahua Rao, Shuangjia Zheng, Yutong Lu, and Yuedong Yang. Quantitative evaluation of explainable graph neural networks for molecular property prediction.Patterns, 2022
work page 2022
-
[23]
Kriege, Franka Bause, Kristian Kersting, Petra Mutzel, and Marion Neumann
Christopher Morris, Nils M. Kriege, Franka Bause, Kristian Kersting, Petra Mutzel, and Marion Neumann. Tudataset: A collection of benchmark datasets for learning with graphs. InICML Workshop, 2020
work page 2020
-
[25]
Understanding attention and general- ization in graph neural networks
Boris Knyazev, Graham W Taylor, and Mohamed Amer. Understanding attention and general- ization in graph neural networks. InNeurIPS, 2019
work page 2019
-
[26]
Gcan: Graph-aware co-attention networks for explainable fake news detection on social media
Yi Ju Lu and Cheng Te Li. Gcan: Graph-aware co-attention networks for explainable fake news detection on social media. InACL, 2020
work page 2020
-
[27]
Interpretable prototype-based graph information bottleneck
Sangwoo Seo, Sungwon Kim, and Chanyoung Park. Interpretable prototype-based graph information bottleneck. InNeurIPS, 2023
work page 2023
-
[28]
How interpretable are interpretable graph neural networks? InICML, 2024
Yongqiang Chen, Yatao Bian, Bo Han, and James Cheng. How interpretable are interpretable graph neural networks? InICML, 2024
work page 2024
-
[29]
Towards self-explainable graph neural network
Enyan Dai and Suhang Wang. Towards self-explainable graph neural network. InCIKM, 2021
work page 2021
-
[30]
Kergnns: Interpretable graph neural networks with graph kernels
Aosong Feng, Chenyu You, Shiqiang Wang, and Leandros Tassiulas. Kergnns: Interpretable graph neural networks with graph kernels. InAAAI, 2022
work page 2022
-
[31]
Feng Xia, Ciyuan Peng, Jing Ren, Falih Gozi Febrinanto, Renqiang Luo, Vidya Saikrishna, Shuo Yu, and Xiangjie Kong. Graph learning.ArXiv, 2025
work page 2025
-
[32]
Gnn explana- tions that do not explain and how to find them
Steve Azzolin, Stefano Teso, Bruno Lepri, Andrea Passerini, and Sagar Malhotra. Gnn explana- tions that do not explain and how to find them. InICLR, 2026
work page 2026
-
[33]
Patrick Billingsley.Convergence of probability measures. John Wiley & Sons, 2013
work page 2013
-
[34]
Torgny Lindvall.Lectures on the coupling method. Courier Corporation, 2002
work page 2002
-
[35]
Categorical reparameterization with gumbel-softmax
Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparameterization with gumbel-softmax. InICLR, 2017
work page 2017
-
[36]
How powerful are graph neural networks? InICLR, 2019
Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks? InICLR, 2019
work page 2019
-
[37]
Moghaddam, and Roger Wattenhofer
Lukas Faber, Amin K. Moghaddam, and Roger Wattenhofer. When comparing to ground truth is wrong: On evaluating gnn explanation methods. InKDD, 2021
work page 2021
-
[38]
Graphframex: Towards systematic evaluation of explainability methods for graph neural networks
Kenza Amara, Zhitao Ying, Zitao Zhang, Zhichao Han, Yang Zhao, Yinan Shan, Ulrik Bran- des, Sebastian Schemm, and Ce Zhang. Graphframex: Towards systematic evaluation of explainability methods for graph neural networks. InLOG, 2022
work page 2022
-
[39]
Explainability in graph neural networks: A taxonomic survey.IEEE TPAMI, 2022
Hao Yuan, Haiyang Yu, Shurui Gui, and Shuiwang Ji. Explainability in graph neural networks: A taxonomic survey.IEEE TPAMI, 2022
work page 2022
-
[40]
Reconsidering faithfulness in regular, self-explainable and domain invariant gnns
Steve Azzolin, Antonio Longa, Stefano Teso, Andrea Passerini, et al. Reconsidering faithfulness in regular, self-explainable and domain invariant gnns. InICLR, 2025
work page 2025
-
[41]
Inductive representation learning on large graphs.NeurIPS, 2017
Will Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation learning on large graphs.NeurIPS, 2017
work page 2017
-
[42]
Xavier Bresson and Thomas Laurent. Residual gated graph convnets.arXiv preprint arXiv:1711.07553, 2017. 11 A Extended Related Work Unlike post-hoc methods that explain GNNs after training, SI-GNNs integrate explanation generation into the learning pipeline to ensure the model’s rationale aligns with its prediction. Most of them follow a two-stage pipeline...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.