Recognition: 2 theorem links
· Lean TheoremVIMCAN: Visual-Inertial 3D Human Pose Estimation with Hybrid Mamba-Cross-Attention Network
Pith reviewed 2026-05-13 07:47 UTC · model grok-4.3
The pith
VIMCAN uses a Mamba and cross-attention hybrid to estimate 3D human poses from visual and inertial data more accurately than Transformers at real-time speeds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
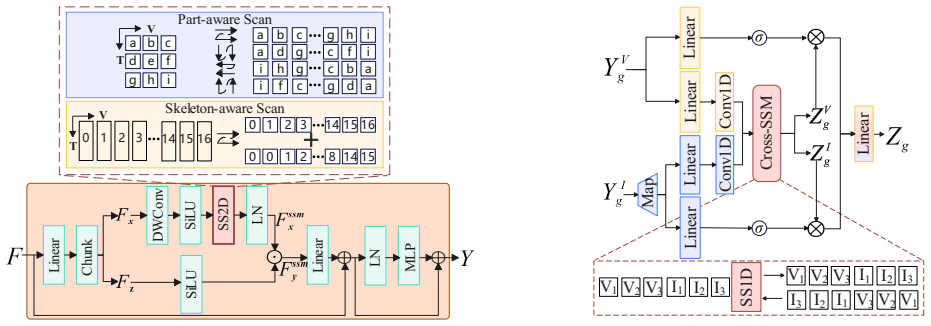
VIMCAN is a hybrid architecture combining Mamba's selective state-space modeling for efficient temporal sequence processing with cross-attention for spatial dependency capture in the fusion of RGB keypoints and IMU data, resulting in superior 3D human pose estimation performance with MPJPE values of 17.2 mm on TotalCapture and 45.3 mm on 3DPW while achieving real-time inference speeds exceeding 60 FPS on consumer hardware.
What carries the argument
Hybrid Mamba-Cross-Attention Network that performs visual-inertial fusion by using Mamba for temporal modeling and cross-attention for spatial reasoning.
If this is right
- Reports mean per-joint position error of 17.2 mm on the TotalCapture dataset
- Reports mean per-joint position error of 45.3 mm on the 3DPW dataset
- Outperforms previous Transformer-based and state-of-the-art methods in accuracy
- Supports inference at over 60 frames per second on consumer-grade hardware
Where Pith is reading between the lines
- Such efficient multimodal fusion could be applied to real-time motion capture for virtual reality experiences on mobile devices.
- Future tests on extended sequences might reveal whether the Mamba component maintains performance without the computational limits of attention models.
- Integration with additional sensor types could be explored to further improve robustness in challenging environments like low-light or fast motion.
Load-bearing premise
Mamba's selective state-space model paired with cross-attention can adequately capture the necessary temporal and spatial dependencies from combined RGB and IMU inputs without overfitting to specific datasets.
What would settle it
A test on a challenging dataset featuring extended durations or high motion complexity showing MPJPE above 50 mm or inference speed below 60 FPS would falsify the performance claims.
Figures




read the original abstract
The rapid advances in deep learning have significantly enhanced the accuracy of multimodal 3D human pose estimation (HPE). However, the state-of-the-art (SOTA) HPE pipelines still rely on Transformers, whose quadratic complexity makes real-time processing for long sequences impractical. Mamba addresses this issue through selective state-space modeling, enabling efficient sequence processing without sacrificing representational power. Nevertheless, it struggles to capture complex spatial dependencies in multimodal settings. To bridge this gap, we propose VIMCAN, a hybrid architecture that combines the efficient sequence modeling of Mamba with the spatial reasoning of Cross-Attention, and performs robust visual-inertial fusion and human pose estimation between RGB keypoints and wearable IMU data. By leveraging Mamba's dynamic parameterization for temporal modeling and Attention for spatial dependency extraction, VIMCAN achieves superior accuracy, with mean per-joint position errors (MPJPE) of 17.2 mm on TotalCapture and 45.3 mm on 3DPW. VIMCAN outperforms prior Transformer-based and other SOTA approaches while supporting real-time inference at over 60 frames per second on consumer-grade hardware. The source code is available at \href{https://github.com/Eddieyzp/VIMCAN}{this GitHub repository}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes VIMCAN, a hybrid architecture combining Mamba's selective state-space modeling for efficient temporal sequence processing with cross-attention for spatial multimodal fusion in visual-inertial 3D human pose estimation from RGB keypoints and wearable IMU data. It reports mean per-joint position errors (MPJPE) of 17.2 mm on TotalCapture and 45.3 mm on 3DPW, outperforming prior Transformer-based and other SOTA methods while achieving real-time inference above 60 FPS on consumer hardware. Source code is released via GitHub.
Significance. If the performance claims are substantiated, this work would advance real-time multimodal 3D HPE by replacing quadratic-complexity Transformers with linear-scaling Mamba for long sequences while retaining spatial reasoning via cross-attention. The hybrid fusion addresses a recognized gap in pure Mamba models for multimodal settings, and code availability supports reproducibility and extension to other sensor-fusion tasks.
major comments (2)
- [Abstract and Methods] Abstract and Methods: The headline MPJPE gains (17.2 mm on TotalCapture, 45.3 mm on 3DPW) are attributed to the Mamba-cross-attention interaction, yet no ablation studies isolate the contribution of the hybrid fusion operator versus pure Mamba, standard Transformer, or non-hybrid baselines under identical training. Without these, it is impossible to confirm that the architectural novelty, rather than training schedule or IMU preprocessing, drives the reported superiority.
- [Results] Results: Benchmark numbers are presented without error bars, standard deviations across runs, or explicit data-split and training-hyperparameter details. This omission weakens the claim of consistent outperformance over SOTA methods, as the central empirical result lacks the verification steps needed for statistical reliability.
minor comments (1)
- [Abstract] Abstract: The statement that source code is available should include the direct GitHub URL rather than a placeholder hyperlink for immediate accessibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and will revise the paper to incorporate additional analyses that strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [Abstract and Methods] Abstract and Methods: The headline MPJPE gains (17.2 mm on TotalCapture, 45.3 mm on 3DPW) are attributed to the Mamba-cross-attention interaction, yet no ablation studies isolate the contribution of the hybrid fusion operator versus pure Mamba, standard Transformer, or non-hybrid baselines under identical training. Without these, it is impossible to confirm that the architectural novelty, rather than training schedule or IMU preprocessing, drives the reported superiority.
Authors: We agree that targeted ablation studies are necessary to isolate the contribution of the hybrid Mamba-cross-attention fusion. While the manuscript reports end-to-end comparisons against Transformer-based and other SOTA baselines, it does not include component-wise ablations (e.g., pure Mamba, cross-attention only, or non-hybrid variants) trained under identical schedules and preprocessing. We will add these experiments in the revised manuscript, presenting a dedicated ablation table that quantifies the incremental gains from each design choice. revision: yes
-
Referee: [Results] Results: Benchmark numbers are presented without error bars, standard deviations across runs, or explicit data-split and training-hyperparameter details. This omission weakens the claim of consistent outperformance over SOTA methods, as the central empirical result lacks the verification steps needed for statistical reliability.
Authors: We acknowledge that reporting statistical variability strengthens the results. The manuscript and released code already specify the data splits and training hyperparameters, but we did not include error bars or standard deviations from multiple runs. In the revision we will rerun the key experiments with several random seeds, report mean MPJPE with standard deviations on both TotalCapture and 3DPW, and add these values to the main results table. revision: yes
Circularity Check
No circularity: empirical architecture evaluation with no self-referential derivations
full rationale
The paper introduces VIMCAN as a hybrid Mamba-Cross-Attention network for visual-inertial 3D human pose estimation, reporting MPJPE results of 17.2 mm on TotalCapture and 45.3 mm on 3DPW as direct empirical measurements. No equations, derivations, or parameter-fitting steps are described that reduce by construction to the inputs (e.g., no self-definitional scaling, fitted inputs renamed as predictions, or load-bearing self-citations). The architecture is presented as a novel combination of existing components (Mamba for temporal modeling, cross-attention for spatial fusion) evaluated on public benchmarks, with performance claims resting on experimental comparisons rather than tautological definitions or unverified uniqueness theorems. This is a standard empirical CV paper with self-contained results against external datasets.
Axiom & Free-Parameter Ledger
free parameters (1)
- network hyperparameters and training settings
axioms (2)
- domain assumption Mamba provides efficient long-sequence modeling without quadratic complexity
- domain assumption Cross-attention extracts useful spatial dependencies from multimodal inputs
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
hybrid architecture that combines the efficient sequence modeling of Mamba with the spatial reasoning of Cross-Attention... MPJPE of 17.2 mm on TotalCapture
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Mamba addresses this issue through selective state-space modeling, enabling efficient sequence processing... linear complexity O(L)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Pre-training a density-aware pose transformer for robust lidar-based 3d human pose estimation
Xiaoqi An, Lin Zhao, Chen Gong, Jun Li, and Jian Yang. Pre-training a density-aware pose transformer for robust lidar-based 3d human pose estimation. InAAAI, pages 1755– 1763, 2025. 1, 2
work page 2025
-
[2]
arXiv preprint arXiv:2404.17837 , year=
Yiming Bao, Xu Zhao, and Dahong Qian. Hybrid 3d hu- man pose estimation with monocular video and sparse imus. CoRR, abs/2404.17837, 2024. 6
-
[3]
Ju Dai, Hao Li, Rui Zeng, Junxuan Bai, Feng Zhou, and Jun- jun Pan. Kd-former: Kinematic and dynamic coupled trans- former network for 3d human motion prediction.Pattern Recognit., 143:109806, 2023. 2, 3
work page 2023
-
[4]
Tri Dao and Albert Gu. Transformers are ssms: General- ized models and efficient algorithms through structured state space duality. InICML, 2024. 2
work page 2024
-
[5]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces.arXiv Preprint arXiv: 2312.00752, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Mambavision: A hy- brid mamba-transformer vision backbone
Ali Hatamizadeh and Jan Kautz. Mambavision: A hy- brid mamba-transformer vision backbone. InCVPR, pages 25261–25270, 2025. 3
work page 2025
-
[7]
Mir Rayat Imtiaz Hossain and James J. Little. Exploit- ing temporal information for 3d human pose estimation. In ECCV, 2018. 5
work page 2018
-
[8]
Exploiting multimodal spatial-temporal patterns for video object tracking
Xiantao Hu, Ying Tai, Xu Zhao, Chen Zhao, Zhenyu Zhang, Jun Li, Bineng Zhong, and Jian Yang. Exploiting multimodal spatial-temporal patterns for video object tracking. InAAAI, pages 3581–3589, 2025. 2
work page 2025
-
[9]
Black, Otmar Hilliges, and Gerard Pons-Moll
Yinghao Huang, Manuel Kaufmann, Emre Aksan, Michael J. Black, Otmar Hilliges, and Gerard Pons-Moll. Deep inertial poser: learning to reconstruct human pose from sparse iner- tial measurements in real time.ACM Trans. Graph., 37(6): 185, 2018. 1, 2, 6
work page 2018
-
[10]
Yunlong Huang, Junshuo Liu, Ke Xian, and Robert Caim- ing Qiu. Posemamba: Monocular 3d human pose estimation with bidirectional global-local spatio-temporal state space model. InAAAI, pages 3842–3850, 2025. 2, 3, 7
work page 2025
-
[11]
Yifeng Jiang, Yuting Ye, Deepak Gopinath, Jungdam Won, Alexander W. Winkler, and C. Karen Liu. Transformer in- ertial poser: Real-time human motion reconstruction from sparse imus with simultaneous terrain generation. InSIG- GRAPH, pages 3:1–3:9. ACM, 2022. 1, 2
work page 2022
-
[12]
Sanghyeok Lee, Joonmyung Choi, and Hyunwoo J. Kim. Ef- ficientvim: Efficient vision mamba with hidden state mixer based state space duality. InCVPR, pages 14923–14933,
-
[13]
High-quality indoor scene 3d reconstruction with RGB-D cameras: A brief review.Comput
Jianwei Li, Wei Gao, Yihong Wu, Yangdong Liu, and Yan- fei Shen. High-quality indoor scene 3d reconstruction with RGB-D cameras: A brief review.Comput. Vis. Media, 8(3): 369–393, 2022. 1, 2
work page 2022
-
[14]
Visual-inertial fusion-based hu- man pose estimation: A review.IEEE Trans
Tong Li and Haoyong Yu. Visual-inertial fusion-based hu- man pose estimation: A review.IEEE Trans. Instrum. Meas., 72:1–16, 2023. 1, 2
work page 2023
-
[15]
Mhformer: Multi-hypothesis transformer for 3d hu- man pose estimation
Wenhao Li, Hong Liu, Hao Tang, Pichao Wang, and Luc Van Gool. Mhformer: Multi-hypothesis transformer for 3d hu- man pose estimation. InCVPR, pages 13137–13146, 2022. 1, 2
work page 2022
-
[16]
Jun Liu, Amir Shahroudy, Mauricio Perez, Gang Wang, Ling-Yu Duan, and Alex C. Kot. NTU RGB+D 120: A large- scale benchmark for 3d human activity understanding.IEEE Trans. Pattern Anal. Mach. Intell., 42(10):2684–2701, 2020. 1, 2
work page 2020
-
[17]
Liujun Liu, Jiewen Yang, Ye Lin, Peixuan Zhang, and Lihua Zhang. 3d human pose estimation with single image and in- ertial measurement unit (IMU) sequence.Pattern Recognit., 149:110175, 2024. 2, 6
work page 2024
-
[18]
Ruixu Liu, Ju Shen, He Wang, Chen Chen, Sen-Ching S. Cheung, and Vijayan K. Asari. Attention mechanism ex- ploits temporal contexts: Real-time 3d human pose recon- struction. InCVPR, pages 5063–5072, 2020. 1, 2
work page 2020
-
[19]
Vmamba: Visual state space model
Yue Liu, Yunjie Tian, Yuzhong Zhao, Hongtian Yu, Lingxi Xie, Yaowei Wang, Qixiang Ye, Jianbin Jiao, and Yunfan Liu. Vmamba: Visual state space model. InNeurIPS, 2024. 2, 3
work page 2024
-
[20]
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J. Black. SMPL: a skinned multi- person linear model.ACM Trans. Graph., 34(6):248:1– 248:16, 2015. 2
work page 2015
-
[21]
Mo- tionagformer: Enhancing 3d human pose estimation with a transformer- gcnformer network
Soroush Mehraban, Vida Adeli, and Babak Taati. Mo- tionagformer: Enhancing 3d human pose estimation with a transformer- gcnformer network. InWACV, pages 6905– 6915, 2024. 1, 2
work page 2024
-
[22]
Fusing monocu- lar images and sparse IMU signals for real-time human mo- tion capture
Shaohua Pan, Qi Ma, Xinyu Yi, Weifeng Hu, Xiong Wang, Xingkang Zhou, Jijunnan Li, and Feng Xu. Fusing monocu- lar images and sparse IMU signals for real-time human mo- tion capture. InSIGGRAPH Asia Conference, pages 116:1– 116:11, 2023. 5, 6
work page 2023
-
[23]
3d human pose estimation in video with tem- poral convolutions and semi-supervised training
Dario Pavllo, Christoph Feichtenhofer, David Grangier, and Michael Auli. 3d human pose estimation in video with tem- poral convolutions and semi-supervised training. InCVPR, pages 7753–7762, 2019. 1, 2, 5
work page 2019
-
[24]
NTU RGB+D: A large scale dataset for 3d human activity analysis
Amir Shahroudy, Jun Liu, Tian-Tsong Ng, and Gang Wang. NTU RGB+D: A large scale dataset for 3d human activity analysis. InCVPR, pages 1010–1019, 2016. 1, 2
work page 2016
-
[25]
Total capture: 3D human pose estimation fusing video and inertial sensors
Trumble, Matthew, Gilbert, Andrew, Malleson, Charles, Hilton, Adrian, Collomosse, and John P. Total capture: 3D human pose estimation fusing video and inertial sensors. In British Machine Vision Conference, 2017. 5, 6
work page 2017
-
[26]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InNeurIPS, pages 5998–6008, 2017. 1, 2
work page 2017
-
[27]
Timo von Marcard, Bodo Rosenhahn, Michael J. Black, and Gerard Pons-Moll. Sparse inertial poser: Automatic 3d hu- man pose estimation from sparse imus.Comput. Graph. Fo- rum, 36(2):349–360, 2017. 1, 2
work page 2017
-
[28]
Black, Bodo Rosenhahn, and Gerard Pons-Moll
Timo von Marcard, Roberto Henschel, Michael J. Black, Bodo Rosenhahn, and Gerard Pons-Moll. Recovering ac- curate 3d human pose in the wild using imus and a moving camera. InECCV, pages 614–631, 2018. 5
work page 2018
-
[29]
Baicun Wang, Ci Song, Xingyu Li, Huiying Zhou, Huay- ong Yang, and Lihui Wang. A deep learning-enabled visual-inertial fusion method for human pose estimation in occluded human-robot collaborative assembly scenarios. Robotics Comput. Integr. Manuf., 93:102906, 2025. 1, 2, 3, 6, 8
work page 2025
-
[30]
Peng Xu, Xiatian Zhu, and David A. Clifton. Multimodal learning with transformers: A survey.IEEE Trans. Pattern Anal. Mach. Intell., 45(10):12113–12132, 2023. 2, 4
work page 2023
-
[31]
RELI11D: A comprehensive multimodal human motion dataset and method
Ming Yan, Yan Zhang, Shuqiang Cai, Shuqi Fan, Xincheng Lin, Yudi Dai, Siqi Shen, Chenglu Wen, Lan Xu, Yuexin Ma, and Cheng Wang. RELI11D: A comprehensive multimodal human motion dataset and method. InCVPR, pages 2250– 2262, 2024. 1, 2
work page 2024
-
[32]
Transpose: real-time 3d human translation and pose estimation with six inertial sensors.ACM Trans
Xinyu Yi, Yuxiao Zhou, and Feng Xu. Transpose: real-time 3d human translation and pose estimation with six inertial sensors.ACM Trans. Graph., 40(4):86:1–86:13, 2021. 1, 2
work page 2021
-
[33]
Bruce X. B. Yu, Zhi Zhang, Yongxu Liu, Sheng-Hua Zhong, Yan Liu, and Chang Wen Chen. GLA-GCN: global-local adaptive graph convolutional network for 3d human pose es- timation from monocular video. InICCV, pages 8784–8795,
-
[34]
Mambaout: Do we really need mamba for vision? InCVPR, pages 4484–4496, 2025
Weihao Yu and Xinchao Wang. Mambaout: Do we really need mamba for vision? InCVPR, pages 4484–4496, 2025. 2, 3, 4
work page 2025
-
[35]
Pose magic: Efficient and temporally con- sistent human pose with a hybrid mamba-gcn network
Xinyi Zhang, Qiqi Bao, Qinpeng Cui, Wenming Yang, and Qingmin Liao. Pose magic: Efficient and temporally con- sistent human pose with a hybrid mamba-gcn network. In AAAI, pages 10248–10256, 2025. 3
work page 2025
-
[36]
Zhao and Jingdong. A review of wearable IMU (inertial- measurement-unit)-based pose estimation and drift reduction technologies.Journal of Physics: Conference Series, 1087: 042003, 2018. 2
work page 2018
-
[37]
Long Zhao, Xi Peng, Yu Tian, Mubbasir Kapadia, and Dim- itris N. Metaxas. Semantic graph convolutional networks for 3d human pose regression. InCVPR, pages 3425–3435,
-
[38]
Poseformerv2: Exploring frequency domain for efficient and robust 3d human pose estimation
Qitao Zhao, Ce Zheng, Mengyuan Liu, Pichao Wang, and Chen Chen. Poseformerv2: Exploring frequency domain for efficient and robust 3d human pose estimation. InCVPR, pages 8877–8886, 2023. 1, 2
work page 2023
-
[39]
3d human pose estima- tion with spatial and temporal transformers
Ce Zheng, Sijie Zhu, Mat ´ıas Mendieta, Taojiannan Yang, Chen Chen, and Zhengming Ding. 3d human pose estima- tion with spatial and temporal transformers. InICCV, pages 11636–11645, 2021. 1, 2
work page 2021
-
[40]
Vision mamba: Efficient visual representation learning with bidirectional state space model
Lianghui Zhu, Bencheng Liao, Qian Zhang, Xinlong Wang, Wenyu Liu, and Xinggang Wang. Vision mamba: Efficient visual representation learning with bidirectional state space model. InICML, 2024. 2
work page 2024
-
[41]
Motionbert: A unified perspective on learning human motion representations
Wentao Zhu, Xiaoxuan Ma, Zhaoyang Liu, Libin Liu, Wayne Wu, and Yizhou Wang. Motionbert: A unified perspective on learning human motion representations. InICCV, pages 15039–15053, 2023. 1, 2
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.