Recognition: no theorem link
How to utilize failure demo data?: Effective data selection for imitation learning using distribution differences in attention mechanism
Pith reviewed 2026-05-11 02:05 UTC · model grok-4.3
The pith
Failure demonstrations can improve imitation learning policies when selected by measuring attention discrepancies between successes and failures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By learning latent representations of success-failure discrepancies and incorporating them into the attention mechanism, policies can be trained on both successful and selected failure demonstrations, with a post-training metric quantifying attention distribution differences to identify beneficial failure samples, leading to improved task success rates in simulations.
What carries the argument
The attention discrepancy metric that quantifies distribution differences in attention between failure samples and successful demonstrations to select data for training.
If this is right
- Imitation learning policies achieve higher success rates when augmented with carefully selected failure data.
- Robotic data collection becomes more efficient by retaining and using failure demonstrations instead of discarding them.
- The attention-based selection avoids the need for additional processing or iterative rollouts required by other methods.
- During inference, selecting the latent mode based on initial observation improves action stability.
Where Pith is reading between the lines
- Similar discrepancy metrics could be applied to other modalities like vision or language models in imitation learning.
- If the metric generalizes, it might reduce the amount of successful demonstrations needed by supplementing with failures.
- Testing on real robots would reveal if simulation results hold when failures are more variable.
Load-bearing premise
The assumption that attention discrepancy reliably identifies failure samples that improve policy performance without introducing bias or needing task-specific adjustments.
What would settle it
Training policies on the selected failure data and observing no improvement or degradation in task success rates compared to using only successful demonstrations.
Figures




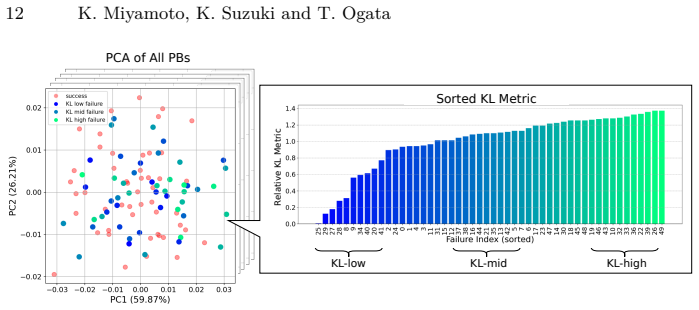
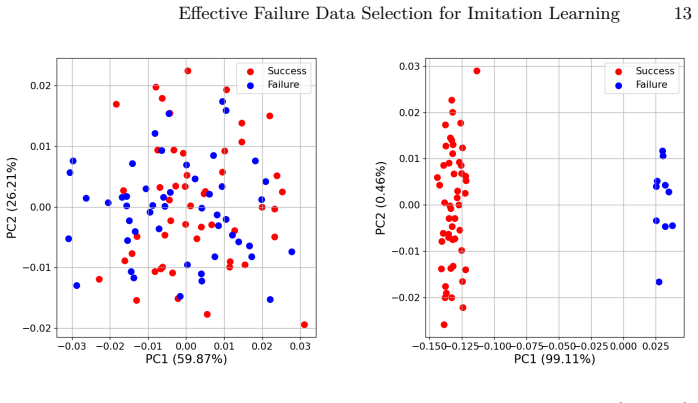
read the original abstract
Imitation learning for robotic tasks has relied primarily on policies trained only on successful demonstrations, although failures are unavoidable during human data collection. Many existing approaches for exploiting failure data require additional data processing or iterative policy updates through autonomous rollouts, making it difficult to directly and stably utilize failure data accumulated during data collection. In this work, we propose a method that learns latent representations of success-failure discrepancies and incorporates them into the attention mechanism. During inference, an appropriate latent mode is selected from the initial observation to improve action stability. Furthermore, we introduce a post-training metric that quantifies the attention discrepancy between each failure sample and successful demonstrations to select failure data. Simulation results show that the proposed method improves task success rates when trained with failure data and that the proposed metric identifies failure samples that are beneficial for learning when combined with successful demonstrations. These results suggest that the proposed method can support more efficient use of collected demonstrations in robotic data collection pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes learning latent representations of success-failure discrepancies and embedding them in the attention mechanism for imitation learning policies. At inference, a latent mode is chosen from the initial observation to stabilize actions. A post-training attention discrepancy metric is defined to quantify differences between failure samples and successful demonstrations, enabling selection of beneficial failure data. Simulation experiments are reported to show higher task success rates when training with the selected failure data combined with successful demonstrations, suggesting more efficient use of collected robotic data.
Significance. If the central claims hold under rigorous validation, the work could provide a practical, non-iterative approach to incorporating failure demonstrations directly into imitation learning without extra processing or autonomous rollouts. The attention-based discrepancy metric offers a novel lens for data selection that might improve data efficiency in robotic pipelines. However, the current simulation evidence is too thin to establish significance, as no quantitative improvements, baselines, or statistical details are supplied.
major comments (2)
- [Simulation Results / Abstract] The central claim that the post-training attention discrepancy metric reliably identifies failure samples that improve policy performance rests on simulation results, yet the abstract (and presumably the results section) supplies no information on baselines, trial counts, statistical tests, or ablation studies. This leaves the reported success-rate improvements impossible to evaluate for magnitude, reliability, or dependence on the selection criterion versus data volume.
- [Method and Evaluation] The assumption that attention discrepancies capture causally relevant success-failure differences (rather than spurious patterns such as trajectory length or state coverage) is load-bearing for the data-selection claim, but no experiments test this against alternative explanations or task-specific attention artifacts.
minor comments (2)
- [Abstract] The abstract would be strengthened by including at least one quantitative result or task description to convey the scale of improvement.
- [Method] Clarify the exact formulation of the attention discrepancy metric and the inference-time latent-mode selection procedure, including any hyperparameters.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for major revision. We agree that the simulation results require more detailed reporting and that the core assumption of the attention discrepancy metric needs stronger validation against alternative explanations. We will revise the manuscript to address both points and respond to each major comment below.
read point-by-point responses
-
Referee: [Simulation Results / Abstract] The central claim that the post-training attention discrepancy metric reliably identifies failure samples that improve policy performance rests on simulation results, yet the abstract (and presumably the results section) supplies no information on baselines, trial counts, statistical tests, or ablation studies. This leaves the reported success-rate improvements impossible to evaluate for magnitude, reliability, or dependence on the selection criterion versus data volume.
Authors: We agree that the current presentation of results does not provide sufficient detail for independent evaluation. In the revised manuscript we will expand both the abstract and the results section to report the specific baselines (training on successful demonstrations only, on all failure data without selection, and on randomly selected failure data), the number of independent trials per condition, the statistical tests used to assess significance, and ablation studies isolating the contribution of the selection metric versus simply increasing data volume. These additions will make the magnitude and reliability of the reported improvements transparent. revision: yes
-
Referee: [Method and Evaluation] The assumption that attention discrepancies capture causally relevant success-failure differences (rather than spurious patterns such as trajectory length or state coverage) is load-bearing for the data-selection claim, but no experiments test this against alternative explanations or task-specific attention artifacts.
Authors: We acknowledge that the manuscript currently lacks explicit controls for spurious correlations. In the revision we will add targeted ablation experiments that compare the attention-discrepancy metric against simple alternatives (trajectory-length difference, state-coverage difference) and against task-specific attention artifacts (e.g., by randomizing attention weights while preserving other factors). These new results will be presented to demonstrate whether the proposed metric indeed captures causally relevant success-failure information beyond the examined confounds. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper defines a novel attention-based latent representation for success-failure discrepancies and a post-training discrepancy metric for selecting failure demonstrations. These are then validated through independent simulation experiments that measure downstream task success rates when the selected data is added to training. No equations or steps reduce by construction to the inputs (no fitted parameters renamed as predictions, no self-definitional loops, and no load-bearing self-citations invoked to justify uniqueness or ansatzes). The evaluation criterion (success rate) is external to the selection metric, so the derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Imi- tation learning: A survey of learning methods
Ahmed Hussein, Mohamed Medhat Gaber, Eyad Elyan, and Chrisina Jayne. Imi- tation learning: A survey of learning methods. ACM Computing Surveys (CSUR) , 50(2):1–35, 2017
work page 2017
-
[2]
A sur- vey of imitation learning: Algorithms, recent developments, and challenges
Maryam Zare, Parham M Kebria, Abbas Khosravi, and Saeid Nahavandi. A sur- vey of imitation learning: Algorithms, recent developments, and challenges. IEEE Transactions on Cybernetics , 54(12):7173–7186, 2024
work page 2024
-
[3]
Qingwen Bu, Jisong Cai, Li Chen, Xiuqi Cui, Yan Ding, Siyuan Feng, Xindong He, Xu Huang, et al. Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems. In 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) . IEEE, 2025
work page 2025
-
[4]
Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn
Tony Z. Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning Fine- Grained Bimanual Manipulation with Low-Cost Hardware. In Proceedings of Robotics: Science and Systems (RSS) , 2023
work page 2023
-
[5]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Siyuan Feng, Yilun Du, Zhenjia Xu, Eric Cousineau, Benjamin Burch- fiel, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. In Proceedings of Robotics: Science and Systems (RSS) , 2023
work page 2023
-
[6]
Align- ing human intent from imperfect demonstrations with confidence-based inverse soft-q learning
Xizhou Bu, Wenjuan Li, Zhengxiong Liu, Zhiqiang Ma, and Panfeng Huang. Align- ing human intent from imperfect demonstrations with confidence-based inverse soft-q learning. IEEE Robotics and Automation Letters , 9(8):7150–7157, 2024
work page 2024
-
[7]
Real-time out-of-distribution failure prevention via multi-modal reasoning
Milan Ganai, Rohan Sinha, Christopher Agia, Daniel Morton, Luigi Di Lillo, and Marco Pavone. Real-time out-of-distribution failure prevention via multi-modal reasoning. In Proceedings of The 9th Conference on Robot Learning , volume 305 of Proceedings of Machine Learning Research , pages 283–308. PMLR, 2025
work page 2025
-
[8]
Motion retouch: Motion modification using four-channel bilateral control
Koki Inami, Sho Sakaino, and Toshiaki Tsuji. Motion retouch: Motion modification using four-channel bilateral control. In 2025 IEEE International Conference on Mechatronics (ICM), pages 1–6. IEEE, 2025
work page 2025
-
[9]
Fail2progress: Learning from real-world robot failures with stein variational inference
Yixuan Huang, Novella Alvina, Mohanraj Devendran Shanthi, and Tucker Her- mans. Fail2progress: Learning from real-world robot failures with stein variational inference. In Joseph Lim, Shuran Song, and Hae-Won Park, editors, Proceedings of The 9th Conference on Robot Learning , volume 305 of Proceedings of Machine Learning Research, pages 5581–5605. PMLR, ...
work page 2025
-
[10]
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
Ali Amin, Raichelle Aniceto, Ashwin Balakrishna, Kevin Black, Ken Conley, Grace Connors, James Darpinian, Karan Dhabalia, Jared DiCarlo, Danny Driess, et al. π∗ 0.6: a VLA That Learns From Experience. arXiv preprint arXiv:2511.14759, 2025
work page Pith review arXiv 2025
-
[11]
Learning from imperfect demonstrations with self-supervision for robotic manipulation
Kun Wu, Ning Liu, Zhen Zhao, Di Qiu, Jinming Li, Zhengping Che, Zhiyuan Xu, and Jian Tang. Learning from imperfect demonstrations with self-supervision for robotic manipulation. In 2025 IEEE International Conference on Robotics and Automation (ICRA) , pages 16899–16906. IEEE, 2025
work page 2025
-
[12]
Inverse reinforcement learning from failure
Kyriacos Shiarlis, Joao Messias, and Shimon Whiteson. Inverse reinforcement learning from failure. In Proceedings of the 2016 International Conference on Autonomous Agents & Multiagent Systems , pages 1060–1068, 2016
work page 2016
-
[13]
Learning from successful and failed demonstrations via optimization
Brendan Hertel and S Reza Ahmadzadeh. Learning from successful and failed demonstrations via optimization. In 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages 7807–7812. IEEE, 2021
work page 2021
-
[14]
Aha: A vision-language-model for detecting and reasoning over failures in robotic manip- ulation
Jiafei Duan, Wilbert Pumacay, Nishanth Kumar, Yi Ru Wang, Shulin Tian, Wen- tao Yuan, Ranjay Krishna, Dieter Fox, Ajay Mandlekar, and Yijie Guo. Aha: A vision-language-model for detecting and reasoning over failures in robotic manip- ulation. In 2nd CoRL Workshop on Learning Effective Abstractions for Planning , 2024
work page 2024
-
[15]
Imitation learn- ing from purified demonstrations
Yunke Wang, Minjing Dong, Yukun Zhao, Bo Du, and Chang Xu. Imitation learn- ing from purified demonstrations. In Proceedings of the 41st International Con- ference on Machine Learning , volume 235 of Proceedings of Machine Learning Research, pages 50313–50331. PMLR, 21–27 Jul 2024
work page 2024
-
[16]
Detecting incorrect visual demonstrations for improved policy learning
Mostafa Hussein and Momotaz Begum. Detecting incorrect visual demonstrations for improved policy learning. In Karen Liu, Dana Kulic, and Jeff Ichnowski, editors, Proceedings of The 6th Conference on Robot Learning , volume 205 of Proceedings of Machine Learning Research , pages 1817–1827. PMLR, 14–18 Dec 2023
work page 2023
-
[17]
Sergey Levine, Peter Pastor, Alex Krizhevsky, Julian Ibarz, and Deirdre Quillen. Learning hand-eye coordination for robotic grasping with deep learning and large- scale data collection. The International journal of robotics research , 37(4-5):421– 436, 2018
work page 2018
-
[18]
Self-organization of behavioral primitives as multiple attractor dynamics: a robot experiment
Jun Tani. Self-organization of behavioral primitives as multiple attractor dynamics: a robot experiment. In Proceedings of the International Joint Conference on Neural Networks, volume 1, pages 489–494, 2002
work page 2002
-
[19]
Kanata Suzuki and Tetsuya Ogata. Sensorimotor attention and language-based regressions in shared latent variables for integrating robot motion learning and llm. In 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 11872–11878, 2024
work page 2024
-
[20]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems , 30, 2017
work page 2017
-
[21]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
work page 2016
-
[22]
robosuite: A Modular Simulation Framework and Benchmark for Robot Learning
Yuke Zhu, Josiah Wong, Ajay Mandlekar, Roberto Martín-Martín, Abhishek Joshi, Kevin Lin, Soroush Nasiriany, and Yifeng Zhu. robosuite: A modular simulation framework and benchmark for robot learning. In arXiv preprint arXiv:2009.12293 , 2020
work page internal anchor Pith review arXiv 2009
-
[23]
Mujoco: A physics engine for model-based control
Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control. In 2012 IEEE/RSJ international conference on intelligent robots and systems , pages 5026–5033. IEEE, 2012
work page 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.