Recognition: 2 theorem links
· Lean TheoremCompositional Quantum Heuristics for Max-Clique Detection
Pith reviewed 2026-05-11 01:49 UTC · model grok-4.3
The pith
Compositional assembly of quantum circuits with symmetry bias produces trainable models that generalize to larger max-clique problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
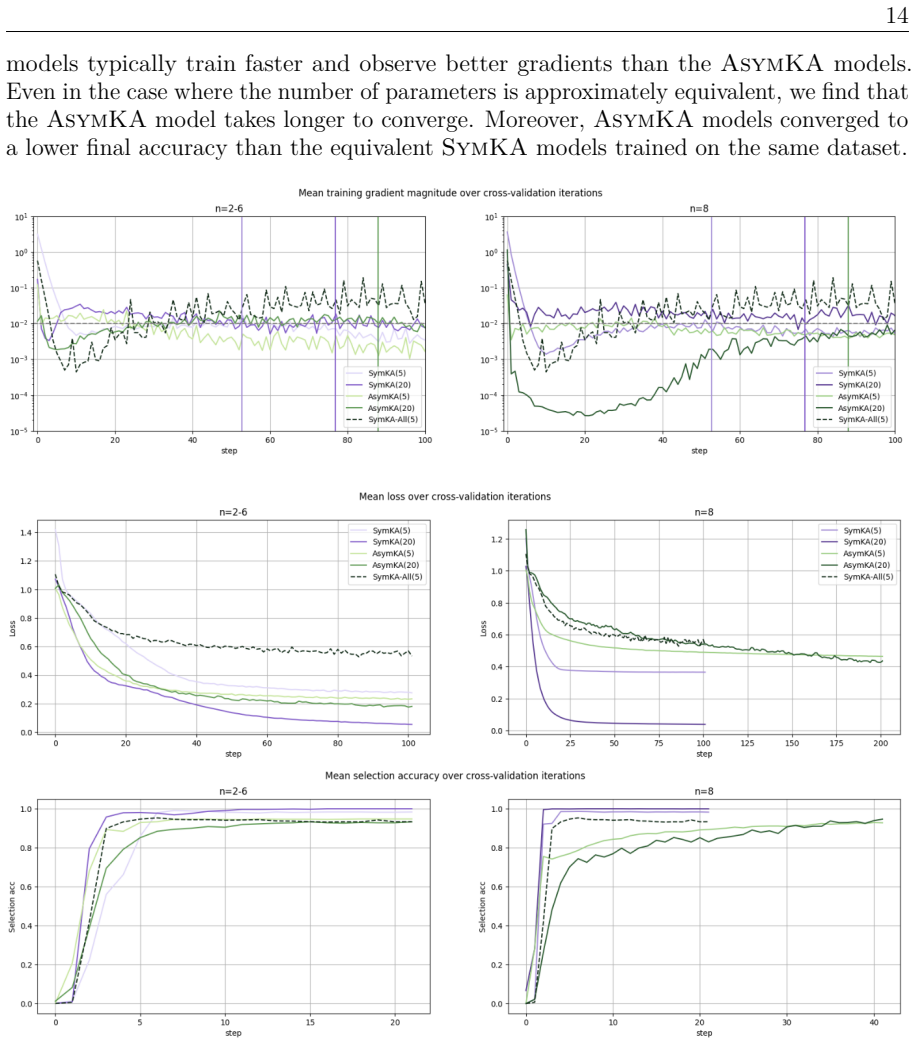
By assembling permutation-equivariant quantum graph neural networks from smaller subcomponents and equipping them with group-invariant loss functions, the models gain symmetry-induced inductive bias that produces superior training gradients and enables generalization to larger and more complex max-clique instances; the trained models are then deployed inside a recursive hybrid quantum-classical heuristic that improves inference accuracy and scalability.
What carries the argument
Compositional construction of permutation-equivariant quantum graph neural networks equipped with group-invariant loss functions to introduce symmetry-induced inductive bias.
If this is right
- The models exhibit superior training gradients through symmetry-induced bias.
- Trained models generalize to larger and more complex problem instances.
- A recursive hybrid quantum-classical heuristic guided by the learned models achieves improved inference accuracy and scalability.
Where Pith is reading between the lines
- The same symmetry-bias construction could be tested on other graph-based combinatorial problems such as maximum independent set or graph coloring.
- If the pattern holds, compositional symmetry might serve as a general design principle for avoiding barren plateaus across a wider range of parameterized quantum circuits.
- The hybrid recursive procedure points toward a practical integration path where quantum models supply local guidance inside larger classical search frameworks.
Load-bearing premise
Assembling subcomponents with group-invariant loss functions will reliably produce superior gradients and generalization on max-clique instances without loss of expressivity or introduction of new optimization pathologies.
What would settle it
If the compositional models trained on small graphs show no measurable improvement in gradient magnitude or generalization performance when tested on larger max-clique instances compared with non-compositional baselines, the central claim would be falsified.
Figures





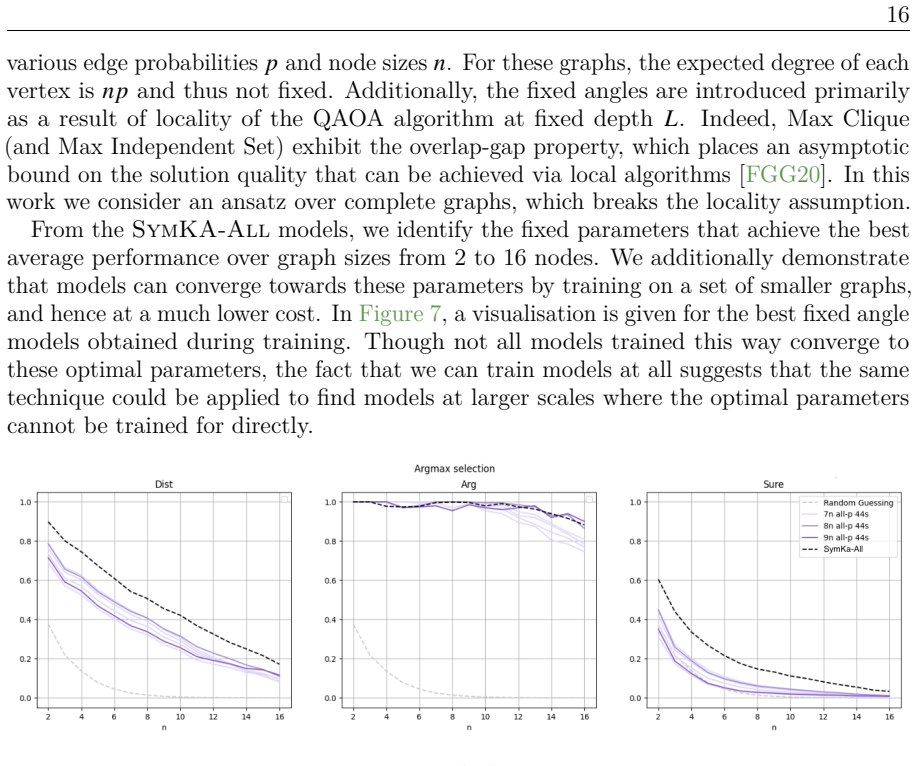













read the original abstract
Quantum machine learning holds the promise of combining the success of classical machine learning methods with the power of quantum computing, however one of the largest obstacles facing the field is the problem of barren plateaus. Parameterised quantum circuits offer a flexible framework for developing quantum machine learning models, but their practicality is constrained by a trade-off between trainability and classical simulability. In general, circuits that are sufficiently expressive to model complex behaviour often exhibit barren plateaus, where gradients vanish and optimisation fails. In this work we investigate a compositional approach to mitigate this trade-off by assembling larger quantum models from smaller subcomponents. To ensure trainability of these subcomponents, we describe a framework for constructing group-invariant loss functions, which introduce symmetry-induced inductive bias and lead to improved gradient behaviour and generalisation. In particular, we use this framework to design permutation-equivariant quantum graph neural networks for identifying maximal cliques in graphs. The models we construct exhibit superior training gradients through symmetry-induced bias, and our experiments demonstrate that the trained models generalise to larger, more complex problem instances. Finally, inspired by Quantum-Informed Recursive Optimisation Algorithms (arXiv:2308.13607), we implement a recursive hybrid quantum-classical heuristic using the learned quantum models to guide a classical search procedure, demonstrating improved inference accuracy and scalability. Together, these results suggest that compositional circuits could be a viable pathway towards scalable quantum learning models that remain challenging to reproduce classically.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a compositional construction of permutation-equivariant quantum graph neural networks by assembling smaller subcircuits equipped with group-invariant loss functions. This symmetry bias is claimed to yield improved gradient behavior during training and better generalization to larger max-clique instances. The authors further embed the trained models inside a recursive hybrid quantum-classical heuristic (inspired by prior Quantum-Informed Recursive Optimisation work) and report improved inference accuracy and scalability on combinatorial instances.
Significance. If the experimental claims are substantiated, the work supplies a concrete route to trainable, symmetry-constrained quantum models that remain classically hard to simulate, directly addressing the expressivity-trainability trade-off in parameterized quantum circuits. The explicit use of group-invariant losses and the recursive heuristic constitute reusable methodological contributions for quantum combinatorial optimization.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): the central claims of 'superior training gradients' and 'generalisation to larger, more complex problem instances' are asserted without any reported circuit depths, ansatz structure, optimizer hyperparameters, baseline comparisons, statistical significance tests, or train/test splits. These omissions render the quantitative support for the symmetry-induced bias claim unevaluable.
- [§3] §3 (Group-invariant loss framework): while the construction of permutation-equivariant losses is described, no explicit bound or scaling argument is given showing that the induced bias improves gradient variance relative to a non-invariant baseline of comparable expressivity. The manuscript should supply either a theorem or a controlled ablation that isolates the symmetry contribution from other architectural choices.
minor comments (2)
- [§2] Notation for the group action and the precise definition of the invariant loss should be introduced with a short table or diagram to aid readability for readers outside quantum group theory.
- [Figure 3] Figure captions for the recursive heuristic diagram should explicitly state the classical/quantum interface and the stopping criterion used in the reported runs.
Simulated Author's Rebuttal
We thank the referee for their careful reading of the manuscript and for the constructive comments. We address each major point below and will revise the manuscript to strengthen the presentation of our results.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the central claims of 'superior training gradients' and 'generalisation to larger, more complex problem instances' are asserted without any reported circuit depths, ansatz structure, optimizer hyperparameters, baseline comparisons, statistical significance tests, or train/test splits. These omissions render the quantitative support for the symmetry-induced bias claim unevaluable.
Authors: We agree that the experimental details provided are insufficient to allow full evaluation of the claims. In the revised manuscript we will report circuit depths, ansatz structures, optimizer hyperparameters, baseline comparisons, statistical significance tests, and the train/test splits used. These additions will make the quantitative support for the symmetry-induced bias claim evaluable. revision: yes
-
Referee: [§3] §3 (Group-invariant loss framework): while the construction of permutation-equivariant losses is described, no explicit bound or scaling argument is given showing that the induced bias improves gradient variance relative to a non-invariant baseline of comparable expressivity. The manuscript should supply either a theorem or a controlled ablation that isolates the symmetry contribution from other architectural choices.
Authors: We acknowledge that §3 does not contain an explicit bound or scaling argument. In the revised manuscript we will add a controlled ablation study that directly compares gradient variance and generalization performance between the group-invariant loss and a non-invariant baseline of comparable expressivity. This ablation isolates the symmetry contribution. A rigorous theorem establishing a general bound on gradient variance improvement lies outside the scope of the present work, but the requested empirical isolation will be provided. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper's derivation chain consists of a proposed compositional framework for building permutation-equivariant quantum graph neural networks via group-invariant loss functions, followed by experimental validation of improved gradients and generalization on max-clique problems, plus a recursive heuristic inspired by external prior work. No load-bearing step reduces a claimed result (such as superior trainability or scalability) to a definition, fitted parameter, or self-citation that presupposes the outcome; the symmetry bias is introduced as an inductive bias in the construction, and performance claims rest on reported experiments rather than being equivalent to the inputs by construction. The approach is self-contained against external benchmarks and does not invoke uniqueness theorems or ansatzes that collapse to prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Quantum dpll and generalized constraints in iterative quantum algorithms,
arXiv:2509.02689 [quant-ph]. [BJS11] Michael J. Bremner, Richard Jozsa, and Dan J. Shepherd. Classical simulation of commuting quantum computations implies collapse of the polynomial hierarchy.Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences, 467(2126):459–472, February
-
[2]
[BKKT20] Sergey Bravyi, Alexander Kliesch, Robert Koenig, and Eugene Tang
arXiv:1005.1407 [quant-ph]. [BKKT20] Sergey Bravyi, Alexander Kliesch, Robert Koenig, and Eugene Tang. Obstacles to State Preparation and Variational Optimization from Symmetry Protection.Physical Review Letters, 125(26):260505, December
-
[3]
arXiv:1910.08980 [quant-ph]. [CFGG02] Andrew M. Childs, Edward Farhi, Jeffrey Goldstone, and Sam Gutmann. Finding cliques by quantum adiabatic evolution.Quantum Info. Comput., 2(3):181–191, April
-
[4]
Scalable and interpretable quantum natural language processing: an implementation on trapped ions
arXiv:2409.08777 [quant-ph]. [DSG+25] Anna Maria Dziubyna, Tomasz Smierzchalski, Bartlomiej Gardas, Marek M. Rams, and Masoud Mohseni. Limitations of tensor-network approaches for optimization and sampling: A comparison to quantum and classical ising machines.Physical Review Applied, 23(5), May
-
[5]
arXiv:2406.17383 [quant-ph]. [FCHC23] Enrico Fontana, M. Cerezo, Zoe Holmes, and Patrick J. Coles. Lie algebraic structure of parameterized quantum circuits and barren plateaus.arXiv preprint arXiv:2309.07902,
-
[6]
The quantum approximate optimization algorithm needs to see the whole graph: A typical case,
arXiv:2004.09002 [quant-ph]. [Fin24] Jernej Rudi Finžgar. Quantum-Informed Recursive Optimization Algorithms.PRX Quantum, 5(2),
-
[7]
Fast Graph Representation Learning with PyTorch Geometric
arXiv:1903.02428 [cs]. [G+25] M. L. Goh et al. Lie-algebraic classical simulations for quantum computing.Under review / arXiv,
work page internal anchor Pith review arXiv 1903
-
[8]
[MMD25] Riccardo Molteni, Simon C. Marshall, and Vedran Dunjko. Quantum machine learning advantages beyond hardness of evaluation.arXiv preprint arXiv:2504.15964,
-
[9]
PyTorch: An Imperative Style, High-Performance Deep Learning Library
arXiv:1912.01703 [cs]. [PH06] Wayne Pullan and Holger H. Hoos. Dynamic local search for the maximum clique problem. Journal of Artificial Intelligence Research, 25:159–185,
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[10]
The Impact of Qubit Connectivity on Quantum Advantage in Noisy IQP Circuits
arXiv:2604.12635 [quant-ph]. [RAAB25] Erik Recio-Armengol, Shahnawaz Ahmed, and Joseph Bowles. Train on classical, deploy on quantum: scaling generative quantum machine learning to a thousand qubits, March
work page internal anchor Pith review Pith/arXiv arXiv
- [11]
-
[12]
arXiv:1905.10876 [quant-ph]. [SLCC22] Louis Schatzki, Martin Larocca, M. Cerezo, and Patrick J. Coles. Theoretical guarantees for permutation-equivariant quantum neural networks.arXiv preprint arXiv:2210.09974,
-
[13]
Classically simulating quantum circuits with local depolarizing noise
[TTT20] Yasuhiro Takahashi, Yuki Takeuchi, and Seiichiro Tani. Classically simulating quantum circuits with local depolarizing noise. In45th International Symposium on Mathematical Foun- dations of Computer Science (MFCS 2020), pages 83:1–83:13,
work page 2020
-
[14]
[WL21] Jonathan Wurtz and Danylo Lykov
Also arXiv:2001.08373. [WL21] Jonathan Wurtz and Danylo Lykov. The fixed angle conjecture for QAOA on regular MaxCut graphs, July
-
[15]
[WL25] Elisabeth Wybo and Martin Leib
arXiv:2107.00677 [quant-ph]. [WL25] Elisabeth Wybo and Martin Leib. Missing Puzzle Pieces in the Performance Landscape of the Quantum Approximate Optimization Algorithm.Quantum, 9:1892, October
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.