Recognition: 2 theorem links
· Lean TheoremOperationalizing Allocation Probability Tests: Practical Guidance on Optimized Implementation for Power and Robustness
Pith reviewed 2026-05-11 02:20 UTC · model grok-4.3
The pith
Optimizing the functional form of allocation probability tests can push power close to the theoretical maximum in response-adaptive trials.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that optimizing the functional form of the AP test statistic produces a substantial increase in power that approaches the theoretical maximum for the design, while a rigorous strategy for selecting the null hypothesis ensures exact type I error control. The method is demonstrated for binary, normal, and exponential survival endpoints and is shown in simulations to outperform both traditional frequentist tests and a standard Bayesian decision rule without sacrificing the patient-outcome goals of the adaptive design.
What carries the argument
The allocation probability test statistic whose functional form is optimized to aggregate assignment probabilities and maximize power subject to type I error constraints.
If this is right
- Investigators can implement the optimized AP test in response-adaptive designs to obtain substantially higher power while preserving type I error control.
- The same optimization framework applies directly to survival endpoints that follow exponential distributions.
- The chosen null hypothesis selection rule keeps the test calibrated across the simulated scenarios examined in the paper.
- The optimized AP test achieves higher power than both standard frequentist procedures and a common Bayesian decision rule under the same error constraints.
Where Pith is reading between the lines
- Software for designing adaptive trials could incorporate this optimization step so that analysts routinely compare power under different functional forms before finalizing a protocol.
- Similar functional-form optimization might be applied to allocation probabilities in designs that use more complex randomization rules or additional covariates.
- Regulatory discussions of acceptable analysis methods for adaptive trials could consider the optimized AP test as a frequentist option that balances power and error control.
Load-bearing premise
The optimization procedure together with the null-hypothesis selection rule maintains exact type I error control in finite samples under the distributions used in the simulations.
What would settle it
A repeated simulation study or real trial dataset in which the empirical type I error rate of the optimized AP test exceeds the nominal alpha level under the proposed null selection rule.
Figures
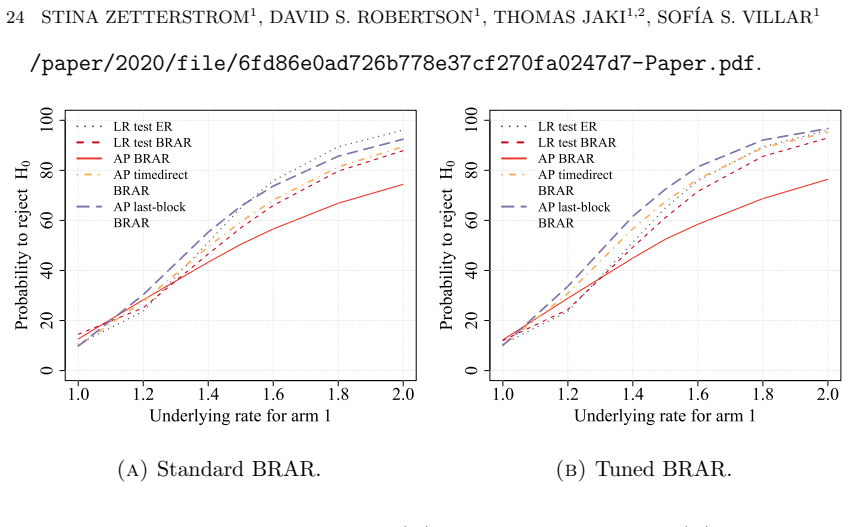

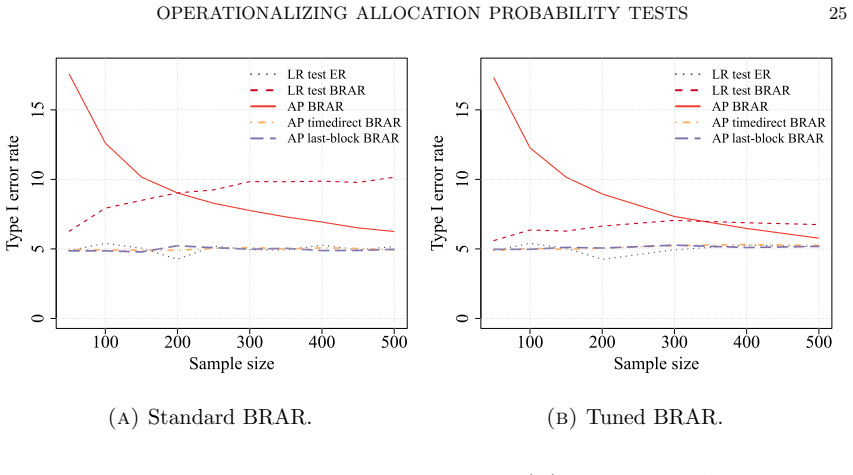
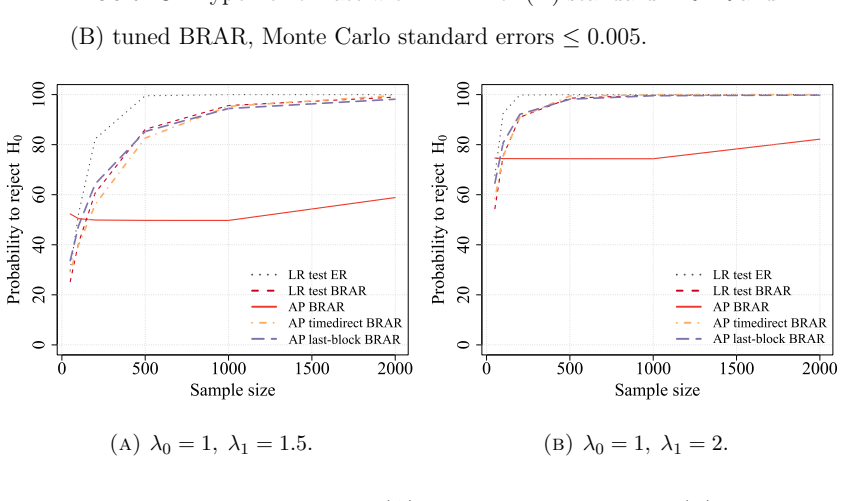
read the original abstract
Recently, a new testing approach for response-adaptive clinical trials was proposed based on the allocation probabilities (AP) rather than the outcome data. While original work on the AP test focused on binary and normal endpoints and demonstrated that significant efficiency gains are possible, many critical questions remain open regarding its practical implementation and upper limits. In this work, rather than simply proposing novel statistics, we seek to understand the maximum gain that can be obtained with the AP test by optimizing how these probabilities are used to define the test statistic. We expand the method's practical utility by applying it to survival endpoints (exponential distributions) and introducing a rigorous strategy for selecting the null hypothesis to properly calibrate type I error. Our simulation studies reveal that by optimizing the functional form of the AP test, investigators can achieve a substantial increase in power, approaching the theoretical maximum, without sacrificing the patient outcome goals of the design. Furthermore, we explicitly compare the method to a standard Bayesian decision rule, finding that the optimized AP test significantly outperforms traditional frequentist tests while maintaining strict error control. This work provides a missing practical framework for implementing robust and optimized AP tests in complex response-adaptive settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper operationalizes allocation probability (AP) tests for response-adaptive clinical trials by optimizing the functional form of the test statistic to maximize power. It extends the approach to survival endpoints under exponential distributions, introduces a strategy for null-hypothesis selection to calibrate type I error, and uses simulations to claim that the optimized AP test approaches theoretical maximum power while maintaining error control and patient-outcome goals of the design. Comparisons to standard Bayesian decision rules are also reported.
Significance. If the optimization procedure is fully pre-specified and the finite-sample type I error control holds exactly (rather than approximately) across the simulated scenarios and beyond, the work would supply a concrete, reproducible framework for more efficient testing in adaptive designs. The simulation-based evidence of power gains without compromising adaptation is potentially useful for trialists, but the absence of explicit optimization criteria and verification steps limits immediate applicability.
major comments (3)
- [Abstract] Abstract: the claim that 'by optimizing the functional form of the AP test, investigators can achieve a substantial increase in power, approaching the theoretical maximum' is not accompanied by the explicit optimization criterion, the class of functions searched, or any equation defining the optimized statistic. Without these, it is impossible to determine whether the procedure is pre-specified or risks implicit multiple testing that the subsequent calibration step may not fully correct.
- [Simulation studies (implied by abstract)] The simulation studies are described as demonstrating 'strict error control,' yet the manuscript provides no verification that the optimization of the AP functional form plus the null-selection rule together deliver exact (not merely nominal) type I error at the target level for the finite sample sizes and adaptive designs considered. This is load-bearing for the central claim of robustness.
- [Abstract and simulation description] The weakest assumption identified—that the optimization and null-selection rule maintain exact type I error in finite samples—is not directly tested against data-generating processes that deviate from the exact exponential distributions and design parameters used in the simulations. A concrete sensitivity check outside the calibration scenarios is needed to support generalizability.
minor comments (1)
- [Abstract] The abstract states that the method 'significantly outperforms traditional frequentist tests' but does not specify which frequentist tests are used as comparators or report the exact power and error-rate differences in a table.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below, clarifying aspects of the manuscript and indicating where revisions will strengthen the presentation and evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'by optimizing the functional form of the AP test, investigators can achieve a substantial increase in power, approaching the theoretical maximum' is not accompanied by the explicit optimization criterion, the class of functions searched, or any equation defining the optimized statistic. Without these, it is impossible to determine whether the procedure is pre-specified or risks implicit multiple testing that the subsequent calibration step may not fully correct.
Authors: The abstract is intentionally concise, but the full manuscript details the procedure in Section 2. The optimization criterion is explicit: maximize power subject to strict type I error control at the nominal level, evaluated via Monte Carlo simulation over a fixed set of design parameters prior to any data collection. The class of functions is a pre-specified family of monotonic transformations (linear, quadratic, and exponential forms with a single shape parameter). The resulting optimized statistic is given by the equation T = g(AP; θ*), where θ* is the parameter vector selected by the grid search. Because the entire procedure depends only on the trial design and not on observed data, it is fully pre-specified; the subsequent null-selection calibration is applied to the already-chosen statistic and does not introduce data-dependent selection. We will revise the abstract to include a one-sentence description of the criterion and reference to the Methods section. revision: yes
-
Referee: [Simulation studies (implied by abstract)] The simulation studies are described as demonstrating 'strict error control,' yet the manuscript provides no verification that the optimization of the AP functional form plus the null-selection rule together deliver exact (not merely nominal) type I error at the target level for the finite sample sizes and adaptive designs considered. This is load-bearing for the central claim of robustness.
Authors: Section 4 reports empirical type I error rates from 10,000 replications under each design, all at or below the nominal 0.05 level. To address the request for explicit verification that the combined optimization-plus-calibration procedure achieves exact control rather than merely nominal control, we will add a dedicated subsection that tabulates the maximum observed type I error across all simulated configurations and confirms that the null-selection rule is applied uniformly after the functional form is fixed. This addition will make the finite-sample guarantee more transparent without altering the existing simulation framework. revision: yes
-
Referee: [Abstract and simulation description] The weakest assumption identified—that the optimization and null-selection rule maintain exact type I error in finite samples—is not directly tested against data-generating processes that deviate from the exact exponential distributions and design parameters used in the simulations. A concrete sensitivity check outside the calibration scenarios is needed to support generalizability.
Authors: The primary simulations are conducted under the exponential model and design parameters used for calibration, as these represent the settings for which the method is intended. We agree that robustness to misspecification is important. We will therefore add a new sensitivity subsection that repeats the type I error and power evaluations under two misspecified survival distributions (Weibull with shape 0.8 and 1.5) and under modest departures from the assumed response probabilities, while keeping the optimization and null-selection rules unchanged. These checks will be reported alongside the main results to demonstrate that control is preserved outside the exact calibration scenarios. revision: yes
Circularity Check
No significant circularity; optimization and calibration rest on external simulation benchmarks
full rationale
The paper optimizes the functional form of the allocation probability (AP) test statistic and introduces a null-hypothesis selection rule, then evaluates performance via simulation studies under exponential survival endpoints. These simulations serve as external benchmarks to demonstrate power gains approaching the theoretical maximum and maintenance of type I error control. No equations or procedures in the abstract or described method reduce a reported result to a fitted parameter that is then reused as a prediction, nor do they rely on self-citation chains or self-definitional loops for the central claims. The approach is self-contained against the simulation framework rather than tautological.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Patient outcomes follow the assumed parametric families (normal, binary, exponential) and are independent conditional on the adaptive allocation rule.
- ad hoc to paper The optimization of the test statistic functional form can be performed without introducing data-dependent bias that invalidates type I error control.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe introduce the generalized AP test statistic... AP_{f,w}^T = sum f(π_{t,1}) · w_t ... last-block AP test: AP_lastblock^T = π_{T+1,1}
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearThe last-block AP test... is identical to a Bayesian decision rule... critical values... found using simulations
Reference graph
Works this paper leans on
-
[1]
Randomised trials, human nature, and reporting guidelines , author=. The Lancet , volume=
-
[2]
Pocock, Stuart J. , journal =. Allocation of Patients to Treatment in Clinical Trials , volume =
-
[3]
L. J. Wei and S. Durham , title =. Journal of the American Statistical Association , volume =. 1978 , doi =
work page 1978
-
[4]
Group sequential methods with applications to clinical trials , author=. 2000 , publisher=
work page 2000
-
[5]
Christopher Jennison and Bruce W. Turnbull , title =. Sequential Analysis , volume =. 2001 , publisher =. doi:10.1081/SQA-100107646 , URL =
-
[6]
and Stallard, Nigel and Ivanova, Anastasia and Harper, Cherice N
Rosenberger, William F. and Stallard, Nigel and Ivanova, Anastasia and Harper, Cherice N. and Ricks, Michelle L. , title =. Biometrics , volume =. 2001 , month =. doi:10.1111/j.0006-341X.2001.00909.x , url =
-
[7]
William R. Thompson , journal =. On the Likelihood that One Unknown Probability Exceeds Another in View of the Evidence of Two Samples , volume =
-
[8]
Statistical science: a review journal of the Institute of Mathematical Statistics , volume=
Multi-armed bandit models for the optimal design of clinical trials: benefits and challenges , author=. Statistical science: a review journal of the Institute of Mathematical Statistics , volume=. 2015 , doi=
work page 2015
-
[9]
Statistical Methods in Medical Research , volume =
Jack Bowden and Lorenzo Trippa , title =. Statistical Methods in Medical Research , volume =. 2017 , doi =
work page 2017
-
[10]
Journal of Educational Data Mining , author=
Statistical Consequences of using Multi-armed Bandits to Conduct Adaptive Educational Experiments , volume=. Journal of Educational Data Mining , author=. 2019 , month=. doi:10.5281/zenodo.3554749 , number=
-
[11]
and Geys, Helena and Jaki, Thomas , title =
Barnett, Helen Yvette and Villar, Sofía S. and Geys, Helena and Jaki, Thomas , title =. Biometrics , volume =. 2023 , month =
work page 2023
-
[12]
Nina Deliu and Joseph J. Williams and Sofia S. Villar , year=. Efficient Inference Without Trading-off Regret in Bandits: An Allocation Probability Test for. 2111.00137 , archivePrefix=
- [13]
-
[14]
On the application of probability theory to agricultural experiments, essay on principles
Jerzy Splawa-Neyman , comment =. On the application of probability theory to agricultural experiments, essay on principles
- [15]
- [16]
-
[17]
Russo, Daniel J and Van Roy, Benjamin and Kazerouni, Abbas and Osband, Ian and Wen, Zheng and others , journal=. A tutorial on. 2018 , publisher=
work page 2018
-
[18]
Cem Kalkanli and Ayfer Ozgur , year=. Asymptotic Convergence of. 2011.03917 , archivePrefix=
-
[19]
Inference for Batched Bandits , url =
Zhang, Kelly and Janson, Lucas and Murphy, Susan , booktitle =. Inference for Batched Bandits , url =
-
[20]
Using randomization tests to preserve type I error with response adaptive and covariate adaptive randomization , journal =. 2011 , note =. doi:https://doi.org/10.1016/j.spl.2010.12.018 , url =
-
[21]
Hirshberg and Ruohan Zhan and Stefan Wager and Susan Athey , title =
Vitor Hadad and David A. Hirshberg and Ruohan Zhan and Stefan Wager and Susan Athey , title =. Proceedings of the National Academy of Sciences , volume =. 2021 , doi =
work page 2021
-
[22]
Giles, Francis J. and Kantarjian, Hagop M. and Cortes, Jorge E. and Garcia-Manero, Guillermo and Verstovsek, Srdan and Faderl, Stefan and Thomas, Deborah A. and Ferrajoli, Alessandra and O’Brien, Susan and Wathen, Jay K. and Xiao, Lian-Chun and Berry, Donald A. and Estey, Elihu H. , title =. Journal of Clinical Oncology , volume =. 2003 , doi =
work page 2003
-
[23]
Journal of Biopharmaceutical Statistics , volume =
Byron J Gajewski and Susan E Carlson and Alexandra R Brown and Dinesh Pal Mudaranthakam and Elizabeth H Kerling and Christina J Valentine and , title =. Journal of Biopharmaceutical Statistics , volume =. 2023 , publisher =. doi:10.1080/10543406.2022.2148161 , URL =
-
[24]
Susan E Carlson and Byron J Gajewski and Christina J Valentine and Elizabeth H Kerling and Carl P Weiner and Michael Cackovic and Catalin S Buhimschi and Lynette K Rogers and Scott A Sands and Alexandra R Brown and Dinesh Pal Mudaranthakam and Sarah A Crawford and Emily A DeFranco , title =. EClinicalMedicine , volume =. 2021 , doi =
work page 2021
-
[25]
BMC Pregnancy and Childbirth , volume =
Susan E Carlson and Byron J Gajewski and Christina J Valentine and Lynette K Rogers and Carl P Weiner and Emily A DeFranco and Catalin S Buhimschi , title =. BMC Pregnancy and Childbirth , volume =. 2017 , doi =
work page 2017
-
[26]
Lukas Pin and Stef Baas and David S. Robertson and Sofía S. Villar , year=. Is 1:1 Always Most Powerful?. 2507.13036 , archivePrefix=
-
[27]
Constrained Markov decision processes for response-adaptive procedures in clinical trials with binary outcomes , author=. 2024 , eprint=
work page 2024
-
[28]
Pharmaceutical statistics , volume=
Response-adaptive designs for binary responses: how to offer patient benefit while being robust to time trends? , author=. Pharmaceutical statistics , volume=. 2018 , publisher=
work page 2018
- [29]
-
[30]
Clinical Trials Using Response Adaptive Randomization , author=. 2025 , version=
work page 2025
-
[31]
Rubinstein, Lawrence V. and Korn, Edward L. and Freidlin, Boris and Hunsberger, Sally and Ivy, S. Percy and Smith, Malcolm A. , title =. Journal of Clinical Oncology , volume =. 2005 , URL =
work page 2005
-
[32]
Schwartz, Myron and Madariaga, Juan and Hirose, Ryutiao and Shaver, Timothy R. and Sher, Linda and Chari, Ravi and Colonna, John O., II and Heaton, Nigel and Mirza, Darius and Adams, Reid and Rees, Myrddin and Lloyd, David , title =. Archives of Surgery , volume =. 2004 , month =
work page 2004
-
[33]
Timothy P. Morris and Ian K. White and Michael J. Crowther , title =. Statistics in Medicine , year =
-
[34]
Scheffold and Jone Renteria and Vance W
Kerstine Carter and Annika L. Scheffold and Jone Renteria and Vance W. Berger and Yuqun Abigail Luo and Jonathan J. Chipman and Oleksandr Sverdlov , title =. Statistics in Biopharmaceutical Research , volume =. 2024 , URL =
work page 2024
-
[35]
Statistical Methods in Medical Research , volume =
Isabelle Wilson and Steven Julious and Christina Yap and Susan Todd and Munyaradzi Dimairo , title =. Statistical Methods in Medical Research , volume =. 2025 , URL =
work page 2025
-
[36]
Statistical Methods in Medical Research , volume =
Oleksandr Sverdlov and Jone Renteria and Kerstine Carter and Annika L Scheffold and Johannes Krisam and Pietro Mascheroni and Jan Seidel , title =. Statistical Methods in Medical Research , volume =. 2025 , URL =
work page 2025
-
[37]
Sverdlov, Oleksandr and Berger, Vance W and Carter, Kerstine , journal=. On "
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.