Recognition: no theorem link
Gradient Starvation in Binary-Reward GRPO: Why Group-Mean Centering Fails and Why the Simplest Fix Works
Pith reviewed 2026-05-11 03:19 UTC · model grok-4.3
The pith
Group-mean centering in GRPO produces zero advantage for all-correct or all-wrong response groups, starving the policy of gradient under binary rewards, but the fixed sign advantage A=2r-1 restores the signal and raises GSM8K accuracy from
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
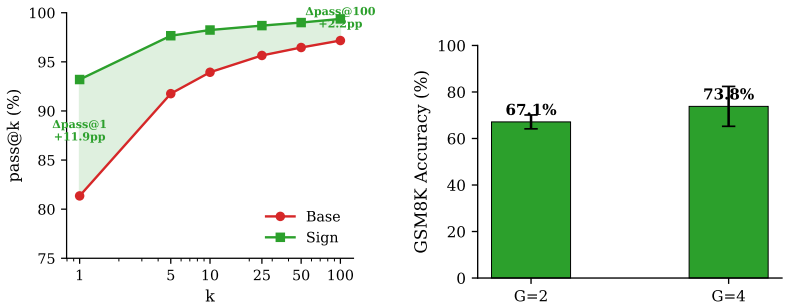
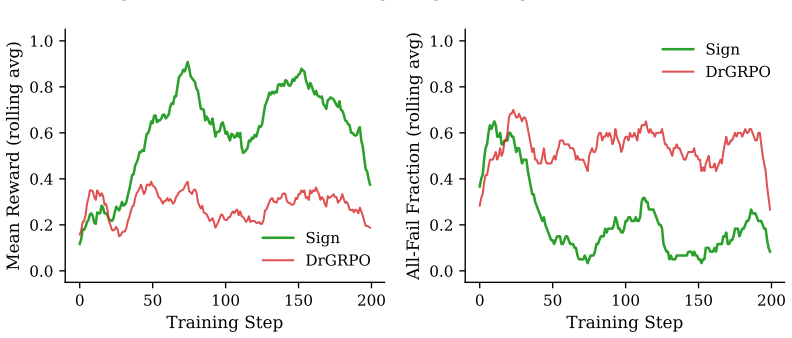
When every response in a group is correct or every response is wrong, the centered advantage in GRPO is exactly zero, so the policy receives no learning signal. The true degeneracy rate always exceeds the i.i.d. Bernoulli prediction by Jensen's inequality. The fixed-reference Sign advantage A=2r-1 performs pass@G failure descent by increasing the probability that at least one sample in the group succeeds, yielding 73.8 percent accuracy versus 28.4 percent for the standard normalized group-mean DrGRPO at group size four on GSM8K.
What carries the argument
The fixed-reference Sign advantage A=2r-1, which assigns +1 to correct responses and -1 to incorrect responses without subtracting the group mean, supplying a consistent learning signal and enabling pass@G failure descent.
If this is right
- At group size four the degeneracy rate reaches 0.69, exceeding Bernoulli predictions.
- Pass@k analysis shows the main benefit is search compression rather than large capacity expansion.
- The accuracy gain is directionally consistent on Llama-3.1-8B and positive on MATH-500 transfer.
- The sign advantage increases the probability that at least one sample in the group succeeds.
Where Pith is reading between the lines
- Many existing GRPO training runs on math tasks may be silently discarding large fractions of updates due to zero-advantage groups.
- The same centering failure could affect other group-based RL methods that use binary or sparse rewards.
- Combining the sign advantage with existing normalization techniques may yield further gains without increasing compute.
Load-bearing premise
The large observed accuracy gain is caused by the pass@G mechanism of the sign advantage rather than differences in normalization, learning-rate schedules, or other unstated training details between the two formulations.
What would settle it
Re-train the identical model and setup with both advantage formulations while locking normalization, learning-rate schedules, and optimizer settings to be exactly the same, then measure whether the 45-point accuracy gap on GSM8K disappears.
Figures


read the original abstract
Group Relative Policy Optimization (GRPO) is a standard algorithm for reinforcement learning from verifiable rewards, but its group-mean-centered advantage can fail under binary rewards. The failure mode is gradient starvation: when every response in a group is correct or every response is wrong, the centered advantage is exactly zero and the policy receives no learning signal. We prove that the true degeneracy rate always exceeds the i.i.d. Bernoulli prediction by Jensen's inequality, and observe a 0.69 degeneracy rate at group size four in logged Qwen3.5-9B GSM8K training. We then show that the fixed-reference Sign advantage, $A=2r-1$, performs pass@$G$ failure descent by increasing the probability that at least one sample in the group succeeds. On the full GSM8K test set across seven seeds, Sign reaches 73.8% accuracy versus 28.4% for standard normalized group-mean DrGRPO at group size four, a 45.4 point gain with $p<0.0001$. The effect is directionally consistent on Llama-3.1-8B and positive but underpowered on a MATH-500 transfer check. Pass@$k$ analysis indicates that the main benefit is search compression rather than large capacity expansion, aligning the empirical gains with recent RLVR ceiling observations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that group-mean centering in GRPO produces gradient starvation under binary rewards, as the advantage is identically zero whenever all responses in a group are correct or all are incorrect. It proves via Jensen's inequality that the observed degeneracy rate necessarily exceeds the i.i.d. Bernoulli prediction, reports a 0.69 degeneracy rate at group size 4 in Qwen3.5-9B GSM8K training, and introduces the fixed-reference Sign advantage A=2r-1, which performs pass@G failure descent. Empirically, Sign yields 73.8% accuracy versus 28.4% for standard normalized group-mean DrGRPO on the full GSM8K test set across seven seeds (p<0.0001), with directionally consistent gains on Llama-3.1-8B and a MATH-500 transfer check; pass@k analysis attributes the benefit to search compression.
Significance. If the mechanistic attribution holds under fully controlled conditions, the work is significant for RLVR research: it isolates a concrete, previously under-appreciated degeneracy in a widely adopted algorithm, supplies a parameter-free remedy, and supplies both a Jensen-based proof and multi-seed statistical evidence. The pass@k interpretation that links the gains to search compression rather than capacity expansion is a further strength that connects the result to recent RLVR ceiling observations.
major comments (1)
- The central empirical claim attributes the 45.4-point GSM8K accuracy gap to the pass@G failure-descent property of the Sign advantage. However, the abstract (and the corresponding experimental section) does not state that the baseline 'standard normalized group-mean DrGRPO' and the Sign method were trained with identical learning-rate schedules, optimizer settings, gradient clipping thresholds, batch construction, or data filtering. Because Sign(A=2r-1) is un-normalized while the baseline is explicitly normalized, effective gradient magnitudes differ; any compensatory hyper-parameter adjustment would constitute an uncontrolled variable that prevents isolating the advantage formulation as the cause of the observed gain.
minor comments (2)
- The abbreviation 'DrGRPO' appears in the abstract without prior definition or citation; a parenthetical expansion on first use would improve readability for readers unfamiliar with the variant.
- The degeneracy-rate observation (0.69 at group size 4) would be strengthened by reporting the per-seed values or standard error, allowing readers to assess variability directly.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The concern about experimental controls is well-taken and directly addressable. We confirm that all other training elements were held identical and will revise the manuscript to make this explicit.
read point-by-point responses
-
Referee: The central empirical claim attributes the 45.4-point GSM8K accuracy gap to the pass@G failure-descent property of the Sign advantage. However, the abstract (and the corresponding experimental section) does not state that the baseline 'standard normalized group-mean DrGRPO' and the Sign method were trained with identical learning-rate schedules, optimizer settings, gradient clipping thresholds, batch construction, or data filtering. Because Sign(A=2r-1) is un-normalized while the baseline is explicitly normalized, effective gradient magnitudes differ; any compensatory hyper-parameter adjustment would constitute an uncontrolled variable that prevents isolating the advantage formulation as the cause of the observed gain.
Authors: We confirm that the baseline and Sign runs used identical hyperparameters in every respect: the same learning-rate schedule (linear warmup to 1e-6 followed by cosine decay), AdamW optimizer (betas 0.9/0.95, epsilon 1e-8), gradient clipping threshold (norm 1.0), batch construction (prompts with exactly 4 responses per group), and data filtering (standard GSM8K training split with no additional curation). The sole difference was the advantage estimator itself. No compensatory adjustments were made to any hyperparameter to offset the un-normalized scale of A=2r-1; the gradient-magnitude difference is an intrinsic feature of the proposed fix. We will add an explicit paragraph in the experimental setup section documenting these controls and noting that the normalization difference is intentional and unadjusted. This revision isolates the advantage formulation as the causal variable. revision: yes
Circularity Check
No significant circularity; derivation relies on independent inequality and direct definition
full rationale
The paper's core theoretical claim applies Jensen's inequality to show the degeneracy rate exceeds the i.i.d. Bernoulli case; this is a standard external inequality with no reduction to fitted parameters or self-referential equations. The Sign advantage is introduced by the explicit definition A=2r-1 with no parameters, fitting, or circular dependence on the target result. Empirical observations (degeneracy rate 0.69, accuracy gains) are reported as measurements rather than derived predictions that collapse to inputs. No load-bearing self-citations, uniqueness theorems from prior author work, or ansatzes smuggled via citation appear in the derivation chain. The pass@G mechanism explanation follows directly from the advantage definition without circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Rewards are strictly binary (0 or 1) for each response in a group.
- standard math Jensen's inequality applies to the expectation over group reward configurations.
Reference graph
Works this paper leans on
-
[1]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Pondé de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models.arXiv preprint arXiv:2106.09685,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783,
-
[5]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
URL https: //huggingface.co/Qwen/Qwen3.5-9B. Model card. John Schulman, Philipp Moritz, Sergey Levine, Michael I. Jordan, and Pieter Abbeel. High- dimensional continuous control using generalized advantage estimation.arXiv preprint arXiv:1506.02438,
work page internal anchor Pith review arXiv
-
[6]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y .K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathe- matical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Single-stream policy optimization.arXiv preprint arXiv:2509.13232,
Zhongwen Xu and Zihan Ding. Single-stream policy optimization.arXiv preprint arXiv:2509.13232,
-
[9]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. DAPO: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in LLMs beyond the base model? arXiv preprint arXiv:2504.13837,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Exgrpo: Learning to reason from experience
Runzhe Zhan, Yafu Li, Zhi Wang, Xiaoye Qu, Dongrui Liu, Jing Shao, Derek F. Wong, and Yu Cheng. ExGRPO: Learning to reason from experience.arXiv preprint arXiv:2510.02245,
-
[13]
arXiv preprint arXiv:2602.03025 , year=
Haitian Zhong, Jixiu Zhai, Lei Song, Jiang Bian, Qiang Liu, and Tieniu Tan. Reward- conditioned group relative policy optimization for multi-turn tool calling agents.arXiv preprint arXiv:2602.03025,
-
[14]
=q G: E[∇θL0 ·1{N= 0}] =q G ·c· −∇θp q =−c·q G−1∇θp.(8) Since∇ θqG =Gq G−1∇θq=−Gq G−1∇θp, we have: E[∇θL0 ·1{N= 0}] = c G ∇θqG =− c G ∇θpass@G. Gradient descent on L0 therefore performs gradient ascent onpass@G= 1−q G. For Sign advantage, c= 1, giving full-strength descent on the failure probabilityq G. Since d dppass@k=k(1−p) k−1 >0 for 0< p <1 , increas...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.