Recognition: no theorem link
OphEdit: Training-Free Text-Guided Editing of Ophthalmic Surgical Videos
Pith reviewed 2026-05-11 03:06 UTC · model grok-4.3
The pith
OphEdit edits ophthalmic surgical videos with text prompts by reusing attention value tensors to hold eye anatomy fixed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
OphEdit captures Attention Value (V) tensors from the source ophthalmic surgical video through deterministic second-order ODE inversion and selectively injects those tensors into the conditional classifier-free guidance branch during denoising. This mechanism keeps the eye's anatomical geometry and temporal structure intact while the text prompt steers semantic alterations such as instrument swaps and procedural phase changes.
What carries the argument
Deterministic second-order ODE inversion that extracts and re-injects Attention Value (V) tensors into the conditional CFG branch of the denoising process.
If this is right
- Instrument swaps and changes in surgical phase can be applied directly to real footage while the surrounding eye tissue and timing remain unchanged.
- Edited videos exhibit higher structural fidelity and temporal consistency than those produced by video editors trained on everyday scenes.
- Large collections of diverse, automatically annotated ophthalmic surgical videos can be produced from a small set of base recordings without additional data capture or model fine-tuning.
- The same stored tensors can be reused across multiple different text prompts on the identical source video.
Where Pith is reading between the lines
- The inversion-and-injection pattern might transfer to editing videos of other high-precision procedures whose anatomy must stay fixed.
- If the attention tensors prove sufficient for eye geometry, they could also support quantitative measurements of how much a prompt alters versus preserves specific structures.
- Synthetic datasets generated this way could be used to test whether downstream AI models for surgical phase recognition improve when trained on edited rather than purely real videos.
Load-bearing premise
The attention value tensors stored from the original video encode enough of the eye's anatomical geometry to let text prompts change instruments or steps without breaking structural fidelity or frame-to-frame consistency.
What would settle it
Run the editor on a video containing a clear anatomical landmark such as the optic disc or a specific vessel pattern, then check whether the edited output under a prompt for instrument replacement shows the landmark moved, deformed, or temporally jittering across frames.
Figures


read the original abstract
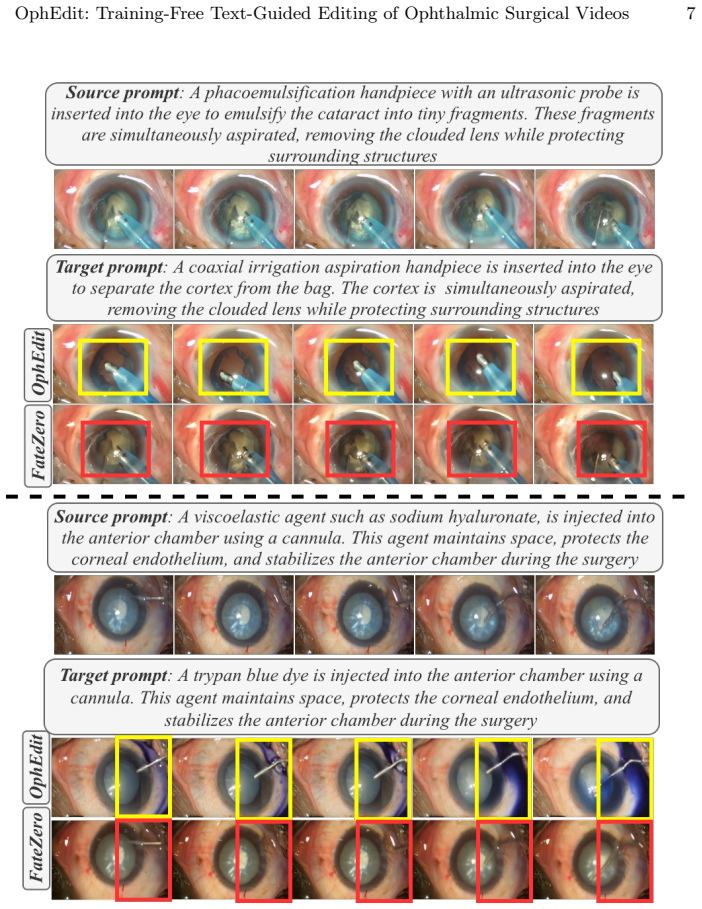
High-fidelity surgical video generation can greatly improve medical training and the development of AI, adapting these generative models for precise video editing remains a formidable challenge. Modifying surgical attributes, such as instrument tissue interactions or procedural phases is challenging due to the strict anatomical and temporal constraints. In this paper, we propose OphEdit, a novel training-free framework for the text-guided editing of ophthalmic surgical videos. Our approach leverages a deterministic second-order ODE inversion pipeline to capture Attention Value (V) tensors from the original video. By selectively injecting these stored tensors into the conditional Classifier-Free Guidance (CFG) branch during the denoising phase, OphEdit rigorously preserves the intricate anatomical geometry of the eye while seamlessly mapping text-driven semantic modifications onto the video stream. Clinical evaluations demonstrates that OphEdit effectively handles complex surgical transformations, such as instrument swaps and procedural variations, with superior structural fidelity and temporal consistency compared to natural-domain video editors. Our work represents the first application of training-free video editing in the ophthalmic surgical domain, offering a scalable solution for generating diverse, annotated medical datasets without the need for exhaustive manual recording or costly model fine-tuning. The code and prompts can be accessed at https://github.com/ophedit/OphEdit
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces OphEdit, a training-free text-guided editing framework for ophthalmic surgical videos. It uses deterministic second-order ODE inversion to capture Attention Value (V) tensors from the source video and selectively injects them into the conditional Classifier-Free Guidance (CFG) branch during denoising, with the goal of preserving eye anatomy while applying text-driven semantic edits such as instrument swaps. The authors assert that clinical evaluations show superior structural fidelity and temporal consistency relative to natural-domain video editors, position the work as the first training-free approach in this domain, and highlight its utility for scalable generation of annotated medical datasets. Code and prompts are released publicly.
Significance. If the empirical claims are substantiated, the method could meaningfully support creation of diverse, annotated ophthalmic video datasets for AI training without manual recording or fine-tuning costs. The training-free design and public code release are clear strengths that aid reproducibility and adoption. However, the current lack of quantitative validation limits the assessed impact.
major comments (3)
- [Abstract] Abstract: The central claim that 'clinical evaluations demonstrates that OphEdit effectively handles complex surgical transformations... with superior structural fidelity and temporal consistency' is unsupported by any quantitative metrics, error bars, baseline details, ablation results, or statistical comparisons. This is load-bearing for the superiority assertion over natural-domain editors.
- [§3] §3 (Method, ODE inversion and V-tensor injection): The approach rests on the premise that V tensors recovered via deterministic second-order ODE inversion encode fine anatomical geometry (vessel patterns, tissue boundaries, specular reflections) sufficiently to enable lossless structural fidelity under text conditioning. No reconstruction metrics, inversion-fidelity ablations, or domain-specific validation for ophthalmic content are reported, leaving the preservation claim unverified.
- [§4] §4 (Experiments/Clinical evaluations): No details are supplied on the evaluation protocol, the specific natural-domain baselines compared, the number of videos or raters, or any objective measures (e.g., temporal consistency scores, structural similarity). This absence prevents verification of the reported superiority.
minor comments (2)
- [Abstract] Abstract: Subject-verb agreement error in 'Clinical evaluations demonstrates'; should read 'demonstrate'.
- [§3] The manuscript would benefit from explicit notation for the second-order ODE solver and the precise injection points of the V tensors (e.g., which attention layers and timesteps).
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review of our manuscript. The comments highlight important areas where additional rigor and transparency are needed to substantiate our claims. We address each major comment point by point below and will incorporate the necessary revisions to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'clinical evaluations demonstrates that OphEdit effectively handles complex surgical transformations... with superior structural fidelity and temporal consistency' is unsupported by any quantitative metrics, error bars, baseline details, ablation results, or statistical comparisons. This is load-bearing for the superiority assertion over natural-domain editors.
Authors: We agree that the abstract's assertion regarding clinical evaluations requires stronger quantitative backing to support the superiority claims. In the revised manuscript, we will update the abstract to explicitly reference the evaluation protocol, including objective metrics such as SSIM for structural fidelity, optical-flow-based temporal consistency scores, and statistical comparisons with baselines. These will be tied directly to the expanded results in §4, ensuring the claims are evidence-based rather than qualitative only. revision: yes
-
Referee: [§3] §3 (Method, ODE inversion and V-tensor injection): The approach rests on the premise that V tensors recovered via deterministic second-order ODE inversion encode fine anatomical geometry (vessel patterns, tissue boundaries, specular reflections) sufficiently to enable lossless structural fidelity under text conditioning. No reconstruction metrics, inversion-fidelity ablations, or domain-specific validation for ophthalmic content are reported, leaving the preservation claim unverified.
Authors: The referee correctly identifies that the current manuscript lacks explicit reconstruction metrics or ablations validating the inversion step for ophthalmic anatomy. Although the selective V-tensor injection mechanism is designed to retain fine details such as vessel patterns and specular reflections, we acknowledge the need for empirical verification. We will add inversion-fidelity ablations in the revised §3 (or a new appendix), reporting metrics including PSNR and SSIM between source and reconstructed frames, along with qualitative examples demonstrating preservation of eye-specific features under the deterministic second-order ODE process. revision: yes
-
Referee: [§4] §4 (Experiments/Clinical evaluations): No details are supplied on the evaluation protocol, the specific natural-domain baselines compared, the number of videos or raters, or any objective measures (e.g., temporal consistency scores, structural similarity). This absence prevents verification of the reported superiority.
Authors: We concur that §4 currently omits critical details on the evaluation protocol, which limits verifiability. In the revision, we will fully expand this section to specify the protocol, including the exact number of ophthalmic surgical videos evaluated, the number and qualifications of clinical raters, the precise natural-domain baselines (e.g., specific video editing methods adapted from Stable Video Diffusion or similar frameworks), and objective measures such as temporal consistency via frame-wise optical flow error and structural similarity via SSIM. Error bars, ablation studies, and statistical tests will also be included to substantiate the reported advantages in structural fidelity and temporal consistency. revision: yes
Circularity Check
No significant circularity; OphEdit applies established ODE inversion and CFG techniques to a new domain
full rationale
The paper presents a training-free framework that reuses deterministic second-order ODE inversion to extract Attention Value (V) tensors and selectively injects them into the CFG branch during denoising. These components are drawn from prior literature on video editing rather than derived within the paper. The central claim is an empirical demonstration of applicability to ophthalmic surgical videos, supported by clinical evaluations, without any load-bearing step that reduces by construction to fitted parameters, self-citations, or renamed inputs. No equations or premises equate the output to the input by definition. The derivation chain is self-contained and externally grounded in independently developed inversion and guidance methods.
Axiom & Free-Parameter Ledger
free parameters (1)
- CFG guidance scale
axioms (1)
- domain assumption Attention Value (V) tensors from deterministic second-order ODE inversion capture the eye's anatomical geometry
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Bai, J., He, T., Wang, Y., Guo, J., Hu, H., Liu, Z., Bian, J.: Uniedit: A unified tuning-free framework for video motion and appearance editing. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 10171–10180 (2025)
work page 2025
-
[2]
Cong, Y., Xu, M., Simon, C., Chen, S., Ren, J., Xie, Y., Perez-Rua, J.M., Rosen- hahn, B., Xiang, T., He, S.: Flatten: optical flow-guided attention for consistent text-to-video editing. arXiv preprint arXiv:2310.05922 (2023)
-
[3]
Classifier-Free Diffusion Guidance
Ho, J., Salimans, T.: Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
In: International Con- ference on Medical Image Computing and Computer-Assisted Intervention
Holm, F., Ünver, G., Ghazaei, G., Navab, N.: Cat-sg: A large dynamic scene graph dataset for fine-grained understanding of cataract surgery. In: International Con- ference on Medical Image Computing and Computer-Assisted Intervention. pp. 96–106. Springer (2025)
work page 2025
-
[5]
Streamdit: Real-time streaming text-to-video generation
Kodaira, A., Hou, T., Hou, J., Georgopoulos, M., Juefei-Xu, F., Tomizuka, M., Zhao, Y.: Streamdit: Real-time streaming text-to-video generation. arXiv preprint arXiv:2507.03745 (2025)
-
[6]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Kong, W., Tian, Q., Zhang, Z., Min, R., Dai, Z., Zhou, J., Xiong, J., Li, X., Wu, B., Zhang, J., et al.: Hunyuanvideo: A systematic framework for large video generative models. arXiv preprint arXiv:2412.03603 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Li, W., Hu, M., Wang, G., Liu, L., Zhou, K., Ning, J., Guo, X., Ge, Z., Gu, L., He, J.: Ophora: a large-scale data-driven text-guided ophthalmic surgical video generation model. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 425–435. Springer (2025)
work page 2025
-
[8]
Mezzina, M., De Backer, P., Vercauteren, T., Blaschko, M., Mottrie, A., Tuyte- laars, T.: Surgeons versus computer vision: a comparative analysis on surgical phase recognition capabilities: M. mezzina et al. International Journal of Com- puter Assisted Radiology and Surgery20(6), 1283–1291 (2025)
work page 2025
-
[9]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Qi, C., Cun, X., Zhang, Y., Lei, C., Wang, X., Shan, Y., Chen, Q.: Fatezero: Fusing attentions for zero-shot text-based video editing. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 15932–15942 (2023)
work page 2023
-
[10]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 10684– 10695 (2022)
work page 2022
-
[11]
Denoising Diffusion Implicit Models
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[12]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y., Hong, W., Zhang, X., Feng, G., et al.: Cogvideox: Text-to-video diffusion models with an expert transformer. arXiv preprint arXiv:2408.06072 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Open-Sora: Democratizing Efficient Video Production for All
Zheng, Z., Peng, X., Yang, T., Shen, C., Li, S., Liu, H., Zhou, Y., Li, T., You, Y.: Open-sora: Democratizing efficient video production for all. arXiv preprint arXiv:2412.20404 (2024)
work page internal anchor Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.