Recognition: no theorem link
SafeTune: Search-based Harmfulness Minimisation for Large Language Models
Pith reviewed 2026-05-11 02:32 UTC · model grok-4.3
The pith
SafeTune reduces harmful responses from Qwen3.5 0.8B while increasing relevance through search over hyperparameters and prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
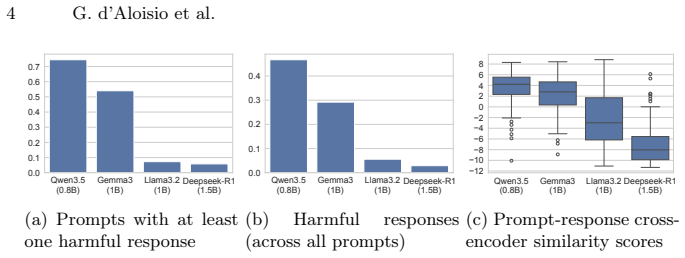
SafeTune is a multi-objective search-based approach to mitigate harmfulness while increasing response relevance through hyperparameter tuning and system prompt engineering. Initial evaluation shows that SafeTune significantly reduces the rate of harmful responses generated by Qwen3.5 0.8B and increases prompt-response relevance, both with large effect sizes. Among the parameters explored, encouraging greater repetition in responses is most impactful in reducing harmfulness while increasing relevance.
What carries the argument
Multi-objective search over hyperparameters such as repetition and over system prompts to jointly minimize harm and maximize relevance.
Load-bearing premise
That the multi-objective search on hyperparameters and prompts will reliably reduce harm and increase relevance across models and contexts without introducing new unintended behaviors or biases.
What would settle it
Applying SafeTune to other LLMs besides Qwen3.5 0.8B and measuring whether harmful response rates fall and relevance rises without new problems appearing.
Figures


read the original abstract
The widespread adoption of Large Language Models (LLMs) raises concerns about the potential harmfulness of their responses. In this paper, we first investigate the harmfulness of responses from four general-purpose LLMs. Next, we propose SafeTune, a multi-objective search-based approach to mitigate harmfulness while increasing response relevance through hyperparameter tuning and system prompt engineering. Our initial evaluation shows that SafeTune significantly reduces the rate of harmful responses generated by Qwen3.5 0.8B and increases prompt-response relevance (both with a large effect size). Among the parameters we explore, we also find that encouraging greater repetition in responses is most impactful in reducing harmfulness while increasing relevance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SafeTune, a multi-objective search-based method that optimizes LLM hyperparameters and system prompts to reduce response harmfulness while increasing prompt-response relevance. It first surveys harmfulness in four general-purpose LLMs, then reports that SafeTune applied to Qwen3.5 0.8B yields statistically notable reductions in harmful response rate and gains in relevance (both with large effect sizes), with greater repetition emerging as the most impactful parameter.
Significance. If the underlying harm and relevance metrics prove robust and generalizable, SafeTune would provide a lightweight, training-free alternative to conventional alignment methods for improving LLM safety. The emphasis on repetition as a high-impact lever and the multi-objective framing could usefully inform prompt-engineering practice, but the absence of concrete evaluation protocols currently prevents assessment of whether these gains reflect genuine safety improvements or metric-specific artifacts.
major comments (3)
- [Evaluation section] Evaluation section (and abstract): The headline claim of large-effect-size reductions in harmful response rate for Qwen3.5 0.8B is presented without any description of the harmfulness detector (LLM judge, keyword list, benchmark, or human guidelines), the evaluation prompts, inter-rater reliability, or statistical tests. Because SafeTune searches over prompts and repetition parameters on the same distribution used for reporting, this omission directly undermines both the harm-reduction and relevance-increase results; the search could simply be producing outputs that evade the particular detector.
- [Method and Results sections] Method and Results sections: The multi-objective search is described as jointly optimizing harm and relevance, yet no held-out test set, cross-validation procedure, or external baseline comparisons are mentioned. Without these, it is impossible to determine whether the reported gains generalize beyond the search distribution or simply reflect overfitting to the (unspecified) evaluation metric.
- [Results section] Results section: The claim that 'encouraging greater repetition' is the most impactful parameter for simultaneously lowering harm and raising relevance requires explicit operationalization of repetition (e.g., n-gram overlap, sentence-level metrics) and evidence that the effect is not an artifact of how the harm classifier scores repetitive text. This is load-bearing for the parameter-sensitivity conclusion.
minor comments (2)
- [Abstract and Introduction] The abstract and introduction would benefit from a brief statement of the four LLMs surveyed and the precise definition of 'prompt-response relevance' used in the multi-objective objective.
- [Method section] Notation for the search objectives and the repetition parameter should be introduced consistently when first used.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments correctly identify areas where greater transparency and rigor are needed in the evaluation and methodological descriptions. We address each major comment below and will make corresponding revisions to the manuscript.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section (and abstract): The headline claim of large-effect-size reductions in harmful response rate for Qwen3.5 0.8B is presented without any description of the harmfulness detector (LLM judge, keyword list, benchmark, or human guidelines), the evaluation prompts, inter-rater reliability, or statistical tests. Because SafeTune searches over prompts and repetition parameters on the same distribution used for reporting, this omission directly undermines both the harm-reduction and relevance-increase results; the search could simply be producing outputs that evade the particular detector.
Authors: We agree that the Evaluation section and abstract require substantially more detail on the harmfulness assessment procedure. In the revised manuscript we will add a complete specification of the detector (including its implementation, prompt template if applicable, and any validation steps), the exact evaluation prompts, inter-rater or reliability statistics, and the statistical tests with effect-size reporting. To address the risk that the search merely evades the detector, we will also report results on a held-out prompt set that was not used during the multi-objective search, thereby demonstrating that the observed reductions are not limited to the optimization distribution. revision: yes
-
Referee: [Method and Results sections] Method and Results sections: The multi-objective search is described as jointly optimizing harm and relevance, yet no held-out test set, cross-validation procedure, or external baseline comparisons are mentioned. Without these, it is impossible to determine whether the reported gains generalize beyond the search distribution or simply reflect overfitting to the (unspecified) evaluation metric.
Authors: The absence of an explicit held-out evaluation protocol is a genuine limitation in the current draft. We will revise the Method section to describe the prompt distribution, introduce a held-out test partition, and document the cross-validation or split procedure used for final reporting. We will also add comparisons against simple baselines (standard system prompts and single-objective tuning) to provide external context and help readers assess whether the gains exceed what would be expected from overfitting to the particular metric. revision: yes
-
Referee: [Results section] Results section: The claim that 'encouraging greater repetition' is the most impactful parameter for simultaneously lowering harm and raising relevance requires explicit operationalization of repetition (e.g., n-gram overlap, sentence-level metrics) and evidence that the effect is not an artifact of how the harm classifier scores repetitive text. This is load-bearing for the parameter-sensitivity conclusion.
Authors: We accept that the current treatment of repetition is insufficiently precise. In the revised Results section we will define repetition operationally (e.g., via n-gram overlap ratios and sentence-level repetition counts induced by the system prompt) and present the parameter-sensitivity analysis with these metrics. To rule out classifier artifacts we will add a supplementary check consisting of manual inspection of a random sample of responses together with an alternative harm metric; this will show whether the harm reduction persists when repetition is controlled for. revision: yes
Circularity Check
No significant circularity in SafeTune derivation
full rationale
The paper describes an empirical search-based tuning procedure (hyperparameter and prompt optimization) followed by separate evaluation measurements on harmfulness and relevance. No equations, self-definitions, or fitted parameters are relabeled as independent predictions. No load-bearing self-citations or uniqueness theorems appear in the provided text. The central claims rest on reported experimental outcomes rather than reducing to inputs by construction. This is the expected non-circular outcome for an applied search/optimization paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2509.24384 (2025)
Yang, L.et al.: HarmMetric Eval: Benchmarking Metrics and Judges for LLM Harmfulness Assessment. arXiv preprint arXiv:2509.24384 (2025)
-
[2]
d’Aloisio, G., Fadahunsi, T., Choy, J., Moussa, R., Sarro, F.: SustainDiffusion: Optimising the social and environmental sustainability of Stable Diffusion models. In: ICSE (2026)
work page 2026
-
[3]
d’Alosio, G., Hort, M., Moussa, R., Sarro, F.: FairRF: Multi-Objective Search for Single and Intersectional Software Fairness. In: ICSE-SEIS (2026)
work page 2026
-
[4]
Gong, J.et al.: Greenstableyolo: Optimizing inference time and image quality of text-to-image generation. In: SSBSE (2024)
work page 2024
-
[5]
Sarro, F.: Search-Based Software Engineering in the Era of Modern Software Sys- tems. In: 2023 IEEE (RE) (2023)
work page 2023
-
[6]
Corbo, S.et al.: How Toxic Can You Get? Search-Based Toxicity Testing for Large Language Models. TSE (2025)
work page 2025
-
[7]
Zhuo, T.Y., Huang, Y., Chen, C., Du, X., Xing, Z.: Bypassing Guardrails: Lessons Learned from Red Teaming ChatGPT. TOSEM (2025)
work page 2025
-
[8]
Mazeika, M.et al.: HarmBench: a standardized evaluation framework for auto- mated red teaming and robust refusal. In: ICML (2024)
work page 2024
-
[9]
Reimers, N., Gurevych, I.: Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In: EMNLP (2019)
work page 2019
-
[10]
Deb, K., Pratap, A., Agarwal, S., Meyarivan, T.: A fast and elitist multiobjective genetic algorithm: NSGA-II. Trans. Evol. Comp (2002)
work page 2002
-
[11]
Deb, K., Sindhya, K., Okabe, T.: Self-adaptive simulated binary crossover for real- parameter optimization. In: GECCO (2007)
work page 2007
-
[12]
Cochran, W.G.: Some methods for strengthening the commonχ2 tests. Biometrics (1954)
work page 1954
-
[13]
Guerreiro, A.P., Fonseca, C.M., Paquete, L.: The Hypervolume Indicator: Compu- tational Problems and Algorithms. ACM Computing Surveys (2021)
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.