Recognition: no theorem link
A Scalable Recipe on SuperMUC-NG Phase 2: Efficient Large-Scale Training of Language Models
Pith reviewed 2026-05-11 02:17 UTC · model grok-4.3
The pith
Standard tensor, pipeline and data parallelism trains 175B language models at 10 percent of peak performance on SuperMUC-NG Phase 2.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By integrating tensor parallelism, pipeline parallelism, and sharded data parallelism with hyperparameter tuning on SuperMUC-NG Phase 2, the authors reach 10 percent of theoretical peak per-tile bf16 FLOPs for a 175B model using an unmodified publicly available software stack, together with 93 percent weak scaling efficiency and 82 percent strong scaling efficiency on 128 nodes.
What carries the argument
The combined strategy of tensor parallelism, pipeline parallelism, and sharded data parallelism that distributes model layers and data shards across GPU tiles while controlling communication costs.
If this is right
- Training of models up to 175 billion parameters becomes practical on this hardware with standard tools.
- High weak scaling efficiency supports efficient expansion to additional nodes for larger workloads.
- The same tuned combination delivers usable performance across a range of model sizes.
- Strong scaling to 128 nodes keeps training times manageable on the available accelerators.
Where Pith is reading between the lines
- The same balance of parallelism techniques could serve as a starting point on other systems that use similar GPU accelerators.
- Further tests on models beyond 175B parameters would reveal where additional tuning becomes necessary.
- Wider adoption of the recipe could increase the number of groups able to experiment with foundational models on public HPC resources.
Load-bearing premise
The measured throughput and scaling efficiencies obtained after tuning will be achieved by other users on the same system with the same standard software distributions and no extra engineering.
What would settle it
An independent run of the 175B model on SuperMUC-NG Phase 2 using the described parallelism settings and unmodified software that falls well below 10 percent of peak throughput or shows scaling efficiencies under 80 percent would undermine the accessibility claim.
Figures
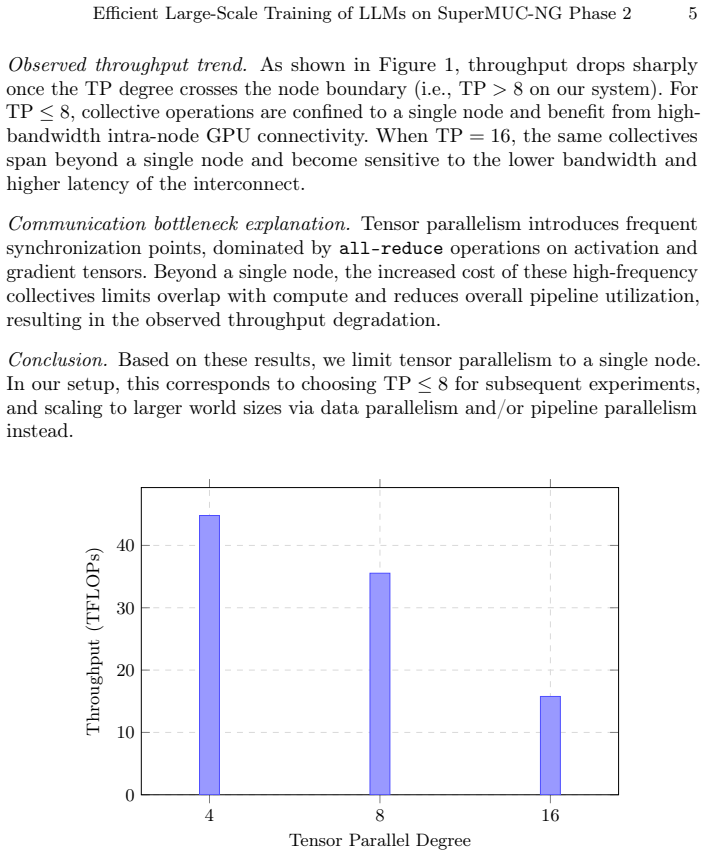

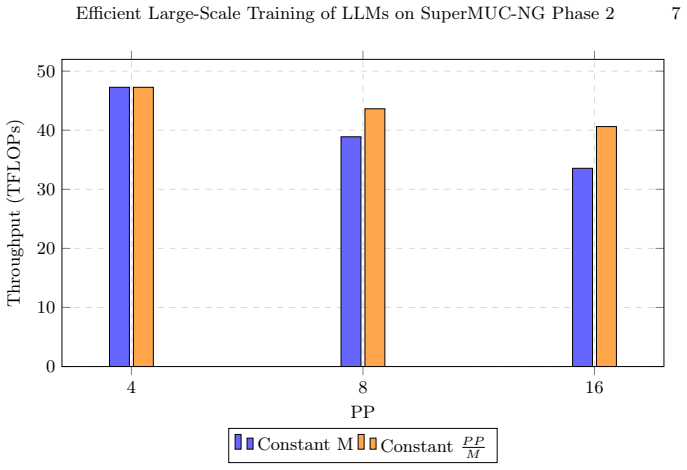
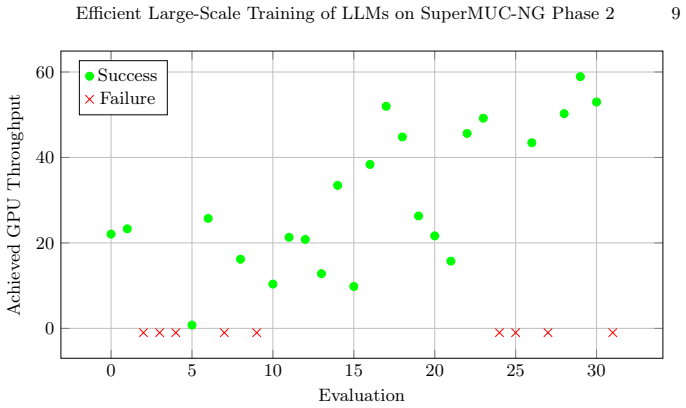

read the original abstract
Large Language Models (LLMs) continue to demonstrate superior performance with increasing scale, yet training models with billions to trillions of parameters requires staggering computational resources, e.g. a one-trillion-parameter GPT-style model requires an estimated 120 million exaflops. This challenge necessitates efficient distributed training strategies on cutting-edge High-Performance Computing (HPC) infrastructure. In this work, we explore the SuperMUC-NG Phase 2 (SMNG-P2) system at the Leibniz Supercomputing Centre (LRZ) in Garching, Germany, equipped with Intel Data Center GPU Max 1550 accelerators to extract the necessary computational power. We enable and investigate a comprehensive recipe of parallel training techniques, including tensor parallelism, pipeline parallelism, and sharded data parallelism, essential for facilitating the training of LLMs up to 175 billion-parameter scale on SMNG-P2. Through empirical assessment and extensive hyperparameter tuning, we analyze the complex interplay among these techniques and determine their impact on GPU computational efficiency. We identify an optimized combined strategy that yields high throughput and enables the efficient training of LLMs of varying sizes. Specifically, for the 175B model, we achieved per-tile throughput of 10% of theoretical peak per-tile bf16 FLOPs, employing an out-of-the-box publicly available software stack, utilizing standard distributions without further modification. This approach ensures broad accessibility, as our methodology can be replicated by any user on SMNG-P2 system without need for porting or specialized software engineering. Furthermore, we achieved 93% weak scaling efficiency and strong scaling efficiency of 82% on 128 nodes. This scalable recipe provides a crucial blueprint for efficiently utilizing advanced exascale systems for next-generation foundational model development.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a recipe for distributed training of LLMs up to 175B parameters on SuperMUC-NG Phase 2 (Intel Data Center GPU Max 1550) by combining tensor, pipeline, and sharded data parallelism. Through empirical tuning it reports 10% of theoretical per-tile BF16 peak FLOPs throughput for the 175B model, 93% weak-scaling efficiency, and 82% strong-scaling efficiency on 128 nodes, all achieved with an unmodified, publicly available software stack.
Significance. If the concrete configuration parameters are supplied, the work supplies a practical, hardware-specific blueprint that lowers the barrier for other users to train large models on this exascale-class system. The reported scaling numbers on real hardware constitute useful reference data for the distributed-training community.
major comments (2)
- [Abstract / §4] Abstract and §4 (Results): the central reproducibility claim—that the 10% peak throughput and scaling efficiencies can be matched by any user “without need for porting or specialized software engineering”—is load-bearing yet unsupported. The text states that the numbers were obtained after “extensive hyperparameter tuning” but does not list the final tensor-parallelism, pipeline-parallelism, data-parallelism degrees, micro-batch size, activation-checkpointing policy, or optimizer settings used for the 175B run. Without these values the recipe reduces to “repeat the same search,” contradicting the no-additional-engineering guarantee.
- [§3 / §4] §3 (Methodology) and §4: no raw throughput measurements, error bars, or exclusion criteria for the scaling experiments are provided. The 93% weak-scaling and 82% strong-scaling figures on 128 nodes cannot be independently verified or compared with other systems without the underlying per-node or per-tile numbers and the exact node counts at each scale point.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from a brief statement of the exact model architecture (hidden size, layers, attention heads) and the precise BF16 FLOP counting convention used to compute the 10% peak figure.
- [Figures] Figure captions and axis labels in the scaling plots should explicitly state the parallelism configuration and batch size for each curve.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of reproducibility and verifiability. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / §4] Abstract and §4 (Results): the central reproducibility claim—that the 10% peak throughput and scaling efficiencies can be matched by any user “without need for porting or specialized software engineering”—is load-bearing yet unsupported. The text states that the numbers were obtained after “extensive hyperparameter tuning” but does not list the final tensor-parallelism, pipeline-parallelism, data-parallelism degrees, micro-batch size, activation-checkpointing policy, or optimizer settings used for the 175B run. Without these values the recipe reduces to “repeat the same search,” contradicting the no-additional-engineering guarantee.
Authors: We agree that the absence of the final configuration parameters limits the immediate usability of the recipe and weakens the reproducibility claim. While the manuscript focuses on the combination of tensor, pipeline, and sharded data parallelism with an unmodified public software stack, providing the specific values for the 175B model is necessary to avoid requiring readers to repeat the tuning process. In the revised version we will add a table in §4 that explicitly lists the tensor-parallelism degree, pipeline-parallelism degree, data-parallelism degree, micro-batch size, activation-checkpointing policy, and optimizer settings used for the reported 175B run. This addition will directly support the claim that the approach can be replicated without specialized engineering. revision: yes
-
Referee: [§3 / §4] §3 (Methodology) and §4: no raw throughput measurements, error bars, or exclusion criteria for the scaling experiments are provided. The 93% weak-scaling and 82% strong-scaling figures on 128 nodes cannot be independently verified or compared with other systems without the underlying per-node or per-tile numbers and the exact node counts at each scale point.
Authors: We acknowledge that the scaling efficiencies cannot be fully verified or compared without the supporting raw data. The reported 93% weak-scaling and 82% strong-scaling figures on 128 nodes were derived from measured throughputs, yet the original submission did not include per-scale raw values, error bars, or criteria for excluding runs (e.g., those affected by transient system variability). In the revised manuscript we will expand §4 to include a table of per-node and per-tile throughput measurements at each scale point for both weak and strong scaling, together with standard deviations and notes on any exclusion criteria applied during data collection. revision: yes
Circularity Check
No circularity: purely empirical measurements with no derivation chain
full rationale
The paper reports direct hardware measurements of per-tile throughput (10% of theoretical bf16 peak) and scaling efficiencies (93% weak, 82% strong on 128 nodes) for a 175B model after hyperparameter tuning on SuperMUC-NG Phase 2. These are presented as experimental outcomes using an out-of-the-box software stack, not as outputs of any mathematical derivation, fitted model, or self-referential equation. No equations appear in the provided text, no parameters are fitted and then relabeled as predictions, and no self-citations are invoked to justify uniqueness or load-bearing premises. The claims are externally falsifiable by replication on the same system, satisfying the self-contained benchmark criterion.
Axiom & Free-Parameter Ledger
free parameters (1)
- parallelism degree combination
axioms (1)
- domain assumption Out-of-the-box public software stack requires no porting or modification on SMNG-P2
Reference graph
Works this paper leans on
-
[1]
Journal of Open Source Software10(110), 7975 (2025)
Balaprakash, P., Chard, R., Hall, D.M., Wild, S.M., Foster, I., Bouhlel, M.A., Ozik, J., Viquez, E., Choudhary, S., Archibald, R., et al.: Deephyper. Journal of Open Source Software10(110), 7975 (2025). https://doi.org/10.21105/joss.07975, https://joss.theoj.org/papers/10.21105/joss.07975
-
[2]
Brown, T.B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Nee- lakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A....
work page 2020
-
[3]
PaLM: Scaling Language Modeling with Pathways
Chowdhery, A., Narang, S., Devlin, J., Bosma, M., Mishra, G., Roberts, A., Barham, P., Chung, H.W., Sutton, C., Gehrmann, S., Schuh, P., Shi, K., Tsvyashchenko, S., Maynez, J., Rao, A., Barnes, P., Tay, Y., Shazeer, N., Prabhakaran, V., Reif, E., Du, N., Hutchinson, B., Pope, R., Bradbury, J., Austin, J., Isard, M., Gur-Ari, G., Yin, P., Duke, T., Levskay...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
arXiv preprint arXiv:2508.14117 (2025)
Cielo, S., Pöppl, A., Pribec, I.: Sycl for energy-efficient numerical astrophysics: the case of dpecho. arXiv preprint arXiv:2508.14117 (2025)
-
[5]
arXiv preprint arXiv:2312.12705 (2023)
Dash, S., Lyngaas, S., Varma, N., Treichler, S., Liesen, S.: Optimizing distributed training on frontier for large language models. arXiv preprint arXiv:2312.12705 (2023)
-
[6]
Proceedings of the 27th ACM Symposium on Operating Systems Principles (2018)
Harlap, A., Narayanan, D., Phanishayee, A., Seshadri, V., Dandekar, S., Ganger, G.R., Gibbons, P.B.: Pipedream: Fast and efficient pipeline parallel dnn training. Proceedings of the 27th ACM Symposium on Operating Systems Principles (2018)
work page 2018
-
[7]
Advances in Neural Information Processing Systems32 (2019)
Huang, Y., Cheng, Y., Bapna, A., Firat, O., Chen, D., Chen, M., Lee, H., Ngiam, J., Le, Q.V., Wu, Y., Chen, Z.: Gpipe: Efficient training of giant neural networks using pipeline parallelism. Advances in Neural Information Processing Systems32 (2019)
work page 2019
-
[8]
Intel: Intel data center gpu max 1550 product specifications (2023), https://www.intel.com/content/www/us/en/products/sku/232873/ intel-data-center-gpu-max-1550.html, accessed 2026-03-01
work page 2023
-
[9]
io/intel-extension-for-pytorch/, accessed 2026-03-01
Intel: Intel extension for pytorch documentation (2024),https://intel.github. io/intel-extension-for-pytorch/, accessed 2026-03-01
work page 2024
-
[10]
Intel: Intel extension for pytorch (github repository) (2024),https://github.com/ intel/intel-extension-for-pytorch, accessed 2026-03-01
work page 2024
-
[11]
Leibniz Supercomputing Centre of the Bavarian Academy of Sciences (LRZ): New supercomputer that offers more methods (supermuc-ng phase 2 in test) (Feb 2024), https://www.lrz.de/en/news/detail/ 2024-02-28-supermuc-ng-phase2-in-test-en, accessed 2026-03-01
work page 2024
-
[12]
Leibniz Supercomputing Centre of the Bavarian Academy of Sciences (LRZ): Probezeiteinessupercomputers:Supermuc-ngphase2pilotphase(May2024), https: //www.lrz.de/news/detail/2024-05-06-sng-2-pilotphase , accessed 2026-03-01
work page 2024
- [13]
- [14]
-
[15]
Microsoft: Megatron-deepspeed (github repository) (2024),https://github.com/ microsoft/Megatron-DeepSpeed, accessed 2026-03-01
work page 2024
-
[16]
Narayanan, D., Shoeybi, M., Casper, J., LeGresley, P., Patwary, M., Korthikanti, V., Vainbrand, D., Kashinkunti, P., Bernauer, J., Catanzaro, B., Phanishayee, A., Zaharia, M.: Efficient large-scale language model training on gpu clusters using megatron-lm. arXiv preprint (2021), arXiv:2104.04473v5
-
[17]
NVIDIA: Megatron-lm (github repository) (2024),https://github.com/NVIDIA/ Megatron-LM, accessed 2026-03-01 12 Ajay Navilarekal Rajgopal and Nikolai Solmsdorf
work page 2024
-
[18]
Radford, A., Narasimhan, K., Salimans, T., Sutskever, I.: Improv- ing language understanding by generative pre-training (2018), https: //cdn.openai.com/research-covers/language-unsupervised/language_ understanding_paper.pdf
work page 2018
-
[19]
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I.: Language models are unsupervised multitask learners (2019), https://cdn.openai.com/better-language-models/language_models_are_ unsupervised_multitask_learners.pdf
work page 2019
-
[20]
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He
Rajbhandari, S., Rasley, J., Ruwase, O., He, Y.: Zero: Memory optimizations toward training trillion parameter models. arXiv preprint arXiv:1910.02054 (2020)
-
[21]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Shoeybi, M., Patwary, M., Puri, R., LeGresley, P., Casper, J., Catanzaro, B.: Megatron-lm: Training multi-billion parameter language models using model paral- lelism. arXiv preprint arXiv:1909.08053 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[22]
Smith,S.,Patwary,M.,Norick,B.,LeGresley,P.,Rajbhandari,S.,Casper,J.,Liu,Z., Prabhumoye, S., Zerveas, G., Korthikanti, V., Zhang, E., Child, R., Aminabadi, R.Y., Bernauer, J., Song, X., Shoeybi, M., He, Y., Houston, M., Tiwary, S., Catanzaro, B.: Using deepspeed and megatron to train megatron-turing nlg 530b, a large-scale generative language model. arXiv ...
work page Pith review arXiv 2022
-
[23]
Advances in Neural Information Processing Systems30(2017)
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in Neural Information Processing Systems30(2017)
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.