Recognition: 2 theorem links
· Lean TheoremTARNet: A Temporal-Aware Multi-Scale Architecture for Closed-Set Speaker Identification
Pith reviewed 2026-05-11 03:15 UTC · model grok-4.3
The pith
TARNet models speaker traits at multiple time scales through a multi-stage encoder with tailored dilations to produce stronger closed-set identification embeddings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
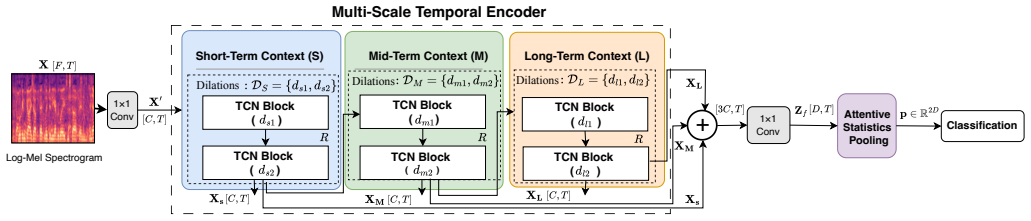
TARNet is a lightweight Temporal-Aware Representation Network that explicitly models temporal information at multiple time scales using a multi-stage temporal encoder with stage-specific dilation configurations. The resulting multi-scale representations are fused and aggregated via an Attentive Statistics Pooling (ASP) module to produce a discriminative utterance-level speaker embedding. This design addresses the limited temporal modeling in existing architectures and yields higher identification accuracy.
What carries the argument
The multi-stage temporal encoder with stage-specific dilation configurations, which extracts and fuses complementary short-, mid-, and long-term speaker characteristics before attentive statistics pooling.
If this is right
- TARNet produces higher accuracy than existing methods on the VoxCeleb1 and LibriSpeech datasets.
- The architecture keeps computational cost competitive with prior networks, supporting deployment in practical speaker identification systems.
- The multi-scale fusion step allows effective use of speaker cues that appear at different temporal resolutions.
- The overall design supplies a concrete architecture template for closed-set tasks that rely on temporal voice patterns.
Where Pith is reading between the lines
- The same staged dilation pattern could be tested on open-set speaker verification or on related audio tasks such as language identification.
- Adjusting the number of stages or the exact dilation values might produce further accuracy-efficiency trade-offs on new datasets.
- Because the encoder is modular, it could be inserted into other speech pipelines that currently use single-scale temporal layers.
Load-bearing premise
Stage-specific dilation configurations will capture and fuse complementary short-, mid-, and long-term speaker characteristics without needing extensive task-specific tuning or introducing scale-specific noise.
What would settle it
An ablation on VoxCeleb1 or LibriSpeech that removes the stage-specific dilations and shows no drop in identification accuracy would indicate that the multi-scale temporal design is not responsible for the reported gains.
Figures


read the original abstract
Closed-Set speaker identification aims to assign a speech utterance to one of a predefined set of enrolled speakers and requires robust modeling of speaker-specific characteristics across multiple temporal scales. While recent deep learning approaches have achieved strong performance, many existing architectures provide limited mechanisms for modeling temporal dependencies across different time scales, which can restrict the effective use of complementary short-, mid-, and long-term speaker characteristics. In this paper, we propose TARNet, a lightweight Temporal-Aware Representation Network for closed-set speaker identification. TARNet explicitly models temporal information at multiple time scales using a multi-stage temporal encoder with stage-specific dilation configurations. The resulting multi-scale representations are fused and aggregated via an Attentive Statistics Pooling (ASP) module to produce a discriminative utterance-level speaker embedding. Experiments on the VoxCeleb1 and LibriSpeech datasets show that TARNet outperforms state-of-the-art methods while maintaining competitive computational complexity, making it suitable for practical speaker identification systems. The code is publicly available at https://github.com/YassinTERRAF/TARNet.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TARNet, a lightweight architecture for closed-set speaker identification that uses a multi-stage temporal encoder with stage-specific dilation rates to explicitly capture and fuse short-, mid-, and long-term speaker characteristics, followed by Attentive Statistics Pooling (ASP) to produce utterance-level embeddings. Experiments on VoxCeleb1 and LibriSpeech are reported to show outperformance over prior SOTA methods at competitive computational cost, with public code released.
Significance. If the multi-scale temporal modeling proves robust, TARNet could offer a practical, efficient alternative for speaker identification systems by better exploiting complementary temporal scales without excessive complexity. The public code release is a clear strength that supports reproducibility.
major comments (3)
- [§4] §4 (Experiments) and Table 2/3: Performance claims of outperformance on VoxCeleb1 and LibriSpeech rest on single-run results without error bars, multiple seeds, or statistical tests; this makes it impossible to determine whether reported gains are reliable or could be due to training variance.
- [§3.2] §3.2 (Multi-stage temporal encoder): The central architectural claim depends on stage-specific dilation configurations delivering complementary multi-scale fusion, yet no ablation is presented comparing stage-specific vs. uniform dilations or isolating each stage's contribution; without this, it is unclear whether gains derive from the proposed mechanism or from ASP/other components.
- [§4.3] §4.3 (Ablation studies): The manuscript provides no ablation or sensitivity analysis on the chosen dilation rates per stage, leaving the weakest assumption (robust scale-specific fusion without task-specific tuning) untested and the source of any advantage opaque.
minor comments (2)
- [§3.2] Notation for dilation rates and stage indices could be clarified with an explicit table or diagram in §3.2 to avoid ambiguity when reproducing the architecture.
- [Abstract] The abstract and §1 would benefit from a brief statement of the exact number of enrolled speakers and utterance lengths used in the closed-set evaluation protocol.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on experimental rigor and the need for targeted ablations. We address each major comment below and will incorporate the requested analyses into the revised manuscript to strengthen the claims.
read point-by-point responses
-
Referee: [§4] §4 (Experiments) and Table 2/3: Performance claims of outperformance on VoxCeleb1 and LibriSpeech rest on single-run results without error bars, multiple seeds, or statistical tests; this makes it impossible to determine whether reported gains are reliable or could be due to training variance.
Authors: We agree that single-run results limit the ability to assess reliability due to training variance. In the revised manuscript, we will rerun the main experiments on VoxCeleb1 and LibriSpeech with at least five random seeds, reporting mean accuracy and standard deviation in Tables 2 and 3. Where feasible, we will also include paired statistical tests (e.g., McNemar or t-tests) to evaluate the significance of the reported gains over baselines. revision: yes
-
Referee: [§3.2] §3.2 (Multi-stage temporal encoder): The central architectural claim depends on stage-specific dilation configurations delivering complementary multi-scale fusion, yet no ablation is presented comparing stage-specific vs. uniform dilations or isolating each stage's contribution; without this, it is unclear whether gains derive from the proposed mechanism or from ASP/other components.
Authors: The stage-specific dilation rates are motivated by the need to explicitly capture short-, mid-, and long-term speaker traits, as described in Section 3.2. To directly address the concern, we will add a new ablation table in the revised version comparing the full TARNet (stage-specific dilations) against variants with uniform dilation rates across all stages and against configurations that disable individual stages. This will isolate the contribution of the multi-scale design from the ASP module and other components. revision: yes
-
Referee: [§4.3] §4.3 (Ablation studies): The manuscript provides no ablation or sensitivity analysis on the chosen dilation rates per stage, leaving the weakest assumption (robust scale-specific fusion without task-specific tuning) untested and the source of any advantage opaque.
Authors: We acknowledge that sensitivity analysis on the specific dilation rates (e.g., [1,2,4] per stage) would better substantiate the design choice. In the revision, we will extend Section 4.3 with additional experiments testing alternative dilation configurations (such as [2,4,8] and [1,3,5]) and report their impact on identification accuracy on both datasets. This will demonstrate the robustness of the selected rates without requiring per-task retuning. revision: yes
Circularity Check
No circularity; empirical architecture proposal with dataset validation
full rationale
The paper proposes TARNet as a new multi-stage temporal encoder architecture with stage-specific dilations and ASP fusion for closed-set speaker identification. Claims of outperformance rest entirely on training and evaluation experiments on VoxCeleb1 and LibriSpeech, with no mathematical derivation, first-principles prediction, or self-referential reduction presented. No equations, uniqueness theorems, or fitted inputs are invoked in a load-bearing way that collapses to the paper's own definitions or prior self-citations. This is a standard empirical ML contribution whose central claims are externally falsifiable via replication on the cited datasets.
Axiom & Free-Parameter Ledger
free parameters (1)
- stage-specific dilation rates
axioms (1)
- domain assumption Speaker-specific characteristics remain consistent and complementary across short-, mid-, and long-term temporal scales in speech.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat 8-tick periodicity and orbit structure echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
multi-stage temporal encoder with stage-specific dilation configurations... dilations {1,2},{4,8},{16,32}... repeated R=3 times
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
TARNet explicitly models temporal information at multiple time scales using a multi-stage temporal encoder
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Yassin Terraf and Youssef Iraqi, “Robust feature extraction using temporal context averaging for speaker identification in diverse acoustic environments,”IEEE Access, vol. 12, pp. 14094–14115, 2024
work page 2024
-
[2]
V oice biometric: A technology for voice-based authentication,
Nilu Singh, Alka Agrawal, and R. A. Khan, “V oice biometric: A technology for voice-based authentication,”Adv. Sci. Eng. Med., vol. 10, no. 7–8, pp. 754–759, 2018
work page 2018
-
[3]
Forensic speaker and gender identification from mobile voice samples,
Gulshan et al. Gouri, “Forensic speaker and gender identification from mobile voice samples,”Appl. Acoust., vol. 222, pp. 110074, 2024
work page 2024
-
[4]
Text-independent speaker identification through feature fusion,
Rashid et al. Jahangir, “Text-independent speaker identification through feature fusion,”IEEE Access, vol. 8, pp. 32187–32202, 2020
work page 2020
-
[5]
DNN-Based speaker identification using prosodic features,
Arifan Rahman and Wahyu Catur Wibowo, “DNN-Based speaker identification using prosodic features,” inProc. ICACSIS, 2021, pp. 1–7
work page 2021
-
[6]
Late fusion dnn for robust speaker identification using raw waveforms,
Daniele Salvati, Carlo Drioli, and Gian Luca Foresti, “Late fusion dnn for robust speaker identification using raw waveforms,”Expert Syst. Appl., vol. 222, pp. 119750, 2023
work page 2023
-
[7]
V oxceleb: Large-scale speaker verification in the wild,
Arsha Nagrani, Joon Son Chung, Weidi Xie, and Andrew Zisserman, “V oxceleb: Large-scale speaker verification in the wild,”Comput. Speech Lang., vol. 60, pp. 101027, 2020
work page 2020
-
[8]
Delving into voxceleb: Environment invariant speaker recognition,
Joon Son Chung, Jaesung Huh, and Seongkyu Mun, “Delving into voxceleb: Environment invariant speaker recognition,” inProc. Odyssey, 2020, pp. 349–356
work page 2020
-
[9]
Speaker identification from emotional and noisy speech using learned voice segregation,
Shibani et al. Hamsa, “Speaker identification from emotional and noisy speech using learned voice segregation,”Expert Syst. Appl., vol. 224, pp. 119871, 2023
work page 2023
-
[10]
Harnessing Wav2Vec2 and cnns for robust speaker identification,
Or Haim et al. Anidjar, “Harnessing Wav2Vec2 and cnns for robust speaker identification,”Expert Syst. Appl., vol. 255, pp. 124671, 2024
work page 2024
-
[11]
Yassin Terraf and Youssef Iraqi, “TOSD-Net: a cnn-transformer archi- tecture for robust frame-level overlapping speech detection in diverse acoustic conditions,” inText, Speech, and Dialogue. 2026, pp. 72–83, Springer Nature Switzerland
work page 2026
-
[12]
Temporal convolutional networks: A unified approach to action segmentation,
Colin Lea, Rene Vidal, Austin Reiter, and Gregory D Hager, “Temporal convolutional networks: A unified approach to action segmentation,” in European conference on computer vision. Springer, 2016, pp. 47–54
work page 2016
-
[13]
Yassin Terraf and Youssef Iraqi, “CoMISI: multimodal speaker iden- tification in diverse audio-visual conditions through cross-modal inter- action,” inNeural Information Processing. 2026, pp. 61–77, Springer Nature Singapore
work page 2026
-
[14]
Attentive statistics pooling for deep speaker embedding,
Koji Okabe, Takafumi Koshinaka, and Koichi Shinoda, “Attentive statistics pooling for deep speaker embedding,” inProc. Interspeech, 2018, pp. 2252–2256
work page 2018
-
[15]
Librispeech: An asr corpus based on public domain audio books,
Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur, “Librispeech: An asr corpus based on public domain audio books,” in Proc. IEEE ICASSP, 2015, pp. 5206–5210
work page 2015
-
[16]
Noreen,Computer-Intensive Methods for Testing Hypotheses, Wiley, 1989
Eric W. Noreen,Computer-Intensive Methods for Testing Hypotheses, Wiley, 1989
work page 1989
-
[17]
Learning a similarity metric discriminatively, with application to face verification,
Sumit Chopra, Raia Hadsell, and Yann LeCun, “Learning a similarity metric discriminatively, with application to face verification,” inProc. IEEE CVPR, 2005, pp. 539–546
work page 2005
-
[18]
In defence of metric learning for speaker recognition,
Joon Son et al. Chung, “In defence of metric learning for speaker recognition,” inProc. Interspeech, 2020, pp. 2977–2981
work page 2020
-
[19]
Deep cnns with self-attention for speaker identification,
Nguyen Nang An, Nguyen Quang Thanh, and Yanbing Liu, “Deep cnns with self-attention for speaker identification,”IEEE Access, vol. 7, pp. 85327–85337, 2019
work page 2019
-
[20]
ResNeXt and Res2Net structures for speaker verification,
Tianyan Zhou, Yong Zhao, and Jian Wu, “ResNeXt and Res2Net structures for speaker verification,” inProc. IEEE SLT, 2021, pp. 301– 307
work page 2021
-
[21]
X-Vectors: robust dnn embeddings for speaker recognition,
David et al. Snyder, “X-Vectors: robust dnn embeddings for speaker recognition,” inProc. IEEE ICASSP, 2018, pp. 5329–5333
work page 2018
-
[22]
Brecht Desplanques, Jenthe Thienpondt, and Kris Demuynck, “ECAPA- TDNN: emphasized channel attention, propagation and aggregation in tdnn-based speaker verification,” inProc. Interspeech, 2020, pp. 3830– 3834
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.