Recognition: 2 theorem links
· Lean TheoremRuleSafe-VL: Evaluating Rule-Conditioned Decision Reasoning in Vision-Language Content Moderation
Pith reviewed 2026-05-11 03:10 UTC · model grok-4.3
The pith
Vision-language models struggle to recover how policy rules interact when making content moderation decisions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that moderation decisions depend on which rules activate, how those rules interact, and whether evidence is sufficient, yet current vision-language models cannot reliably perform these steps. RuleSafe-VL formalizes policies into atomic rules and typed relations to create diagnostic tasks that expose rule-relation recovery as the dominant bottleneck, with best performance at 64.8 Macro-F1, and decision-state prediction peaking at only 64.5 Macro-F1. The work therefore advocates shifting evaluation from final-label accuracy to assessment of the full rule-conditioned decision chain.
What carries the argument
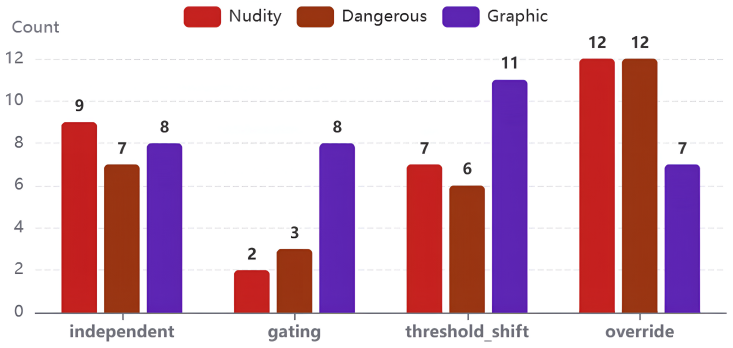
The rule-conditioned decision chain, which decomposes moderation into four tasks of identifying activated rules, recovering rule interactions, judging decision sufficiency, and resolving outcomes after supplying missing context.
If this is right
- Models achieving high scores on simple moderation labels may still apply policies incorrectly due to failures in tracking rule interactions.
- Safety-oriented models can perform substantially worse than general models on recovering rule relations.
- Diagnostic tasks that isolate rule identification and interaction steps can locate exact points of failure in multimodal decision systems.
- Reliable content moderation requires advances in modeling how multiple rules combine or conflict within a single case.
Where Pith is reading between the lines
- The same rule-interaction bottleneck may appear in other rule-governed multimodal tasks such as legal document review or medical guideline application.
- Training approaches that present rules as explicit graphs rather than implicit labels could reduce the observed performance gap.
- Hybrid architectures pairing vision-language processing with separate symbolic rule engines might bypass the current recovery failures.
Load-bearing premise
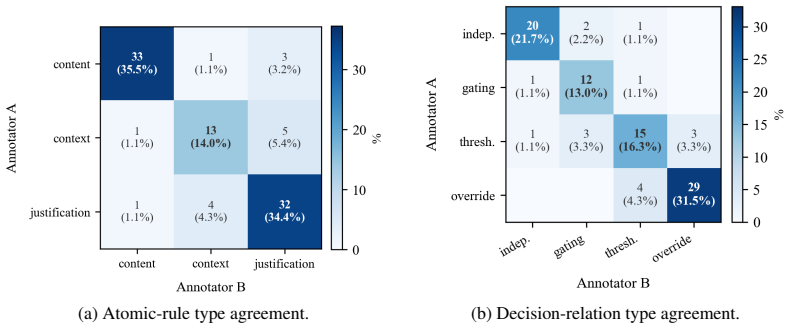
The 93 atomic rules and 92 typed rule relations derived from public policies are assumed to faithfully capture the structure and interactions of real moderation decisions without significant loss of context-dependent conditions.
What would settle it
A controlled experiment that supplies models with the full explicit rule graph and measures whether interaction-recovery Macro-F1 scores rise above 85 percent or remain near the current 65 percent ceiling.
Figures





read the original abstract
Platform content moderation applies explicit policy rules and context-dependent conditions to decide whether user content is allowed, restricted, or removed. A correct moderation outcome must therefore depend on which rules a case activates, how those rules interact, and whether the available evidence is sufficient. Current multimodal safety benchmarks largely reduce moderation to matching predefined final labels, leaving this underlying rule structure untested. As a result, a high benchmark score reveals little about whether a model applies the policy correctly or arrives at the correct label through superficial cues. To evaluate this rule-governed process, we introduce RuleSafe-VL, a benchmark for rule-conditioned decision reasoning in vision-language content moderation. Derived from publicly available platform moderation policies, RuleSafe-VL formalizes 93 atomic rules and 92 typed rule relations, yielding 2,166 context-sensitive image-text cases across three high-risk policy families. Its four diagnostic tasks decompose moderation into a rule-conditioned decision chain. They identify activated rules, recover rule interactions, judge decision sufficiency, and resolve outcomes once missing context is supplied. Experiments on 10 frontier, open-source, and safety-oriented VLMs reveal rule-relation recovery as the dominant bottleneck, where the best model reaches only 64.8 Macro-F1 and some safety-oriented models fall below 7 Macro-F1. Decision-state prediction also remains unreliable, peaking at 64.5 Macro-F1. RuleSafe-VL shifts moderation evaluation from final-label scoring toward diagnostic assessment of rule-conditioned decision reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RuleSafe-VL, a benchmark for assessing vision-language models on rule-conditioned decision reasoning in content moderation. It derives 93 atomic rules and 92 typed rule relations from public platform policies to create 2,166 context-sensitive image-text cases across three policy families. Four diagnostic tasks decompose the process into identifying activated rules, recovering rule interactions, judging decision sufficiency, and resolving outcomes with supplied context. Experiments on 10 frontier, open-source, and safety-oriented VLMs identify rule-relation recovery as the dominant bottleneck (best Macro-F1 of 64.8) and show unreliable decision-state prediction (peak Macro-F1 of 64.5).
Significance. If the rule formalization and task decomposition hold, the work provides a useful diagnostic alternative to final-label benchmarks for VLM safety evaluation, with concrete numbers across 10 models that pinpoint specific weaknesses in handling rule interactions. This could guide more targeted alignment efforts for high-stakes moderation applications.
major comments (1)
- [Abstract] Abstract: The central claim that rule-relation recovery is the dominant bottleneck (max 64.8 Macro-F1) and that low VLM performance reflects genuine reasoning deficits rests on the 93 atomic rules and 92 typed relations faithfully capturing real policy activation conditions and interactions. However, the abstract provides no details on the derivation process, expert validation, inter-annotator agreement, or back-testing against actual moderation outcomes, which is load-bearing for interpreting the results as evidence of model limitations rather than potential benchmark artifacts from oversimplification of context-dependent clauses.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for identifying an area where the abstract could better support interpretation of the results. We address the major comment below and are happy to revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that rule-relation recovery is the dominant bottleneck (max 64.8 Macro-F1) and that low VLM performance reflects genuine reasoning deficits rests on the 93 atomic rules and 92 typed relations faithfully capturing real policy activation conditions and interactions. However, the abstract provides no details on the derivation process, expert validation, inter-annotator agreement, or back-testing against actual moderation outcomes, which is load-bearing for interpreting the results as evidence of model limitations rather than potential benchmark artifacts from oversimplification of context-dependent clauses.
Authors: We agree that the abstract should briefly indicate how the rules and relations were obtained to ground the claims. Section 3 of the manuscript details the systematic extraction of the 93 atomic rules and 92 typed relations directly from publicly available platform policy documents across the three policy families. We will revise the abstract to include a short clause noting this derivation from official public policies. The rules were formalized by the authors from the source policy text following a structured protocol; because the source is the authoritative policy language itself, no separate expert validation round or inter-annotator agreement study was performed. Back-testing against real moderation decisions falls outside the scope of the benchmark, which is intentionally diagnostic of reasoning steps rather than end-to-end outcome prediction; we can add a clarifying sentence in the abstract or introduction to make this boundary explicit. These changes will help readers evaluate whether the reported bottlenecks reflect model limitations rather than benchmark construction. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper constructs RuleSafe-VL by formalizing 93 atomic rules and 92 typed relations extracted from external public platform policies, then defines four diagnostic tasks that decompose moderation decisions. It reports empirical VLM performance metrics (e.g., 64.8 Macro-F1 peak on rule-relation recovery) directly measured on 10 external models. No load-bearing claim reduces by construction to a fitted parameter, self-definition, or self-citation chain; the rule set functions as an independent input, and results are falsifiable against those models without internal circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Publicly available platform moderation policies can be formalized into 93 atomic rules and 92 typed relations that preserve the original decision logic.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/LogicAsFunctionalEquation.leanSatisfiesLawsOfLogic unclearRuleSafe-VL formalizes 93 atomic rules and 92 typed rule relations... four diagnostic tasks... rule-relation recovery as the dominant bottleneck
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel uncleartyped decision relations: threshold, override, gating, and independent
Reference graph
Works this paper leans on
-
[1]
Tarleton Gillespie.Custodians of the Internet: Platforms, Content Moderation, and the Hidden Decisions That Shape Social Media. Yale University Press, 2018
work page 2018
-
[2]
Robert Gorwa, Reuben Binns, and Christian Katzenbach. Algorithmic content moderation: Technical and political challenges in the automation of platform governance.Big Data & Society, 7(1), 2020
work page 2020
-
[3]
Douwe Kiela, Zeerak Waseem, Aki Celikyilmaz, Ming-Wei Chang, and Ishan Sanh. The hateful memes challenge: Detecting hate speech in multimodal memes.Advances in Neural Information Processing Systems (NeurIPS), 2020
work page 2020
-
[4]
Hannah Rose Kirk, Wenjie Yin, Bertie Vidgen, and Paul Röttger. Assessing the generalizability of the hateful memes challenge dataset.Workshop on Online Abuse and Harms (WOAH), 2021
work page 2021
-
[5]
Sara El-amrany et al. Guardharmem and harmdetect: a multimodal dataset and baseline for harmful meme detection.Social Network Analysis and Mining, 2025
work page 2025
-
[6]
Syed Hammad Ahmed, Muhammad Junaid Khan, and Gita Sukthankar. Enhanced mul- timodal content moderation of children’s videos using audiovisual fusion.arXiv preprint arXiv:2405.06128, 2024
-
[7]
Xin Liu, Yichen Zhu, Jindong Gu, Yunshi Lan, Chao Yang, and Yu Qiao. Mm-safetybench: A benchmark for safety evaluation of multimodal large language models.European Conference on Computer Vision (ECCV), 2024
work page 2024
-
[8]
Paul Röttger et al. Msts: A multimodal safety test suite for vision-language models.arXiv preprint arXiv:2501.10057, 2025
-
[9]
Yiqiao Jin, Minje Choi, Gaurav Verma, Jindong Wang, and Srijan Kumar. Mm-soc: Benchmark- ing multimodal large language models in social media platforms.Findings of the Association for Computational Linguistics (ACL), 2024
work page 2024
-
[10]
Benchmarking mllms on visually smuggled threats.OpenReview, 2025
Zhiyuan Li et al. Benchmarking mllms on visually smuggled threats.OpenReview, 2025
work page 2025
-
[11]
T. Davidson et al. Auditing multimodal large language models for context-aware content moderation. SocArXiv preprint, 2025
work page 2025
-
[12]
Guangzhi Sun, Xiao Zhan, Shutong Feng, Philip C. Woodland, and Jose M. Such. Case-bench: Context-aware safety benchmark for large language models.International Conference on Learning Representations (ICLR), 2025
work page 2025
-
[13]
Deepak Kumar, Yousef Anees AbuHashem, and Zakir Durumeric. Watch your language: Investigating content moderation with large language models.International AAAI Conference on Web and Social Media (ICWSM), 2024
work page 2024
-
[14]
N. AlDahoul et al. Advancing content moderation: Evaluating existing llm-based content moderation solutions and the role of context across media.arXiv preprint arXiv:2411.17123, 2024
-
[15]
Artificial intelligence risk management frame- work (ai rmf 1.0)
National Institute of Standards and Technology. Artificial intelligence risk management frame- work (ai rmf 1.0). Technical Report NIST AI 100-1, National Institute of Standards and Technology, 2023
work page 2023
-
[16]
Hee, Md Rafi Awal, Kim Traugott Wah Choo, and Roy Ka-Wei Lee
Haoran Wang, Michael S. Hee, Md Rafi Awal, Kim Traugott Wah Choo, and Roy Ka-Wei Lee. Evaluating GPT-3 generated explanations for hateful content moderation. InProceedings of the Thirty-Second International Joint Conference on Artificial Intelligence (IJCAI-23), pages 6255–6263. International Joint Conferences on Artificial Intelligence Organization, 2023. 10
work page 2023
-
[17]
doi:10.48550/arXiv.2505.11049 , abstract =
Yang Liu, Shu Zhai, Mengxiang Du, Ying Chen, Tianyu Cao, Hu Gao, Chen Wang, Xiang Li, Ke Wang, Jun Fang, Jing Zhang, and Bryan Hooi. Guardreasoner-vl: Safeguarding vlms via reinforced reasoning.arXiv preprint arXiv:2505.11049, 2025
-
[18]
Yue Yang, Ziwei Liu, Yuxuan Yuan, Yi Song, Xinyue Ma, Yifan Song, Xianjun Zeng, Lei Sun, Yu Wang, Haihong Zhou, Shiyu Cui, Zheng Gong, and Jiawei Zhang. BLM-Guard: Explainable multimodal ad moderation with chain-of-thought and policy-aligned rewards.arXiv preprint arXiv:2602.18193, 2026
-
[19]
Age appropriate de- sign: A code of practice for online services
Information Commissioner’s Office. Age appropriate de- sign: A code of practice for online services. https://ico. org.uk/for-organisations/uk-gdpr-guidance-and-resources/ childrens-information/childrens-code-guidance-and-resources/ age-appropriate-design-a-code-of-practice-for-online-services/ , 2020. Accessed 2026-05-07
work page 2020
-
[20]
Child online safety: Age-appropriate content
UK Government. Child online safety: Age-appropriate content. https://www.gov.uk/ guidance/child-online-safety-age-appropriate-content , 2021. Accessed 2026- 05-07
work page 2021
-
[21]
Violent or graphic content policies
YouTube Help. Violent or graphic content policies. https://support.google.com/ youtube/answer/2802008, 2026. Accessed 2026-05-07
-
[22]
Reddit Help. Do not post violent content. https://support.reddithelp.com/hc/en-us/ articles/360043513151-Do-not-post-violent-content , 2026. Accessed 2026-05-07
-
[23]
Approach to newsworthy content.https://transparency.meta
Meta Transparency Center. Approach to newsworthy content.https://transparency.meta. com/features/approach-to-newsworthy-content/, 2024. Accessed 2026-05-07
work page 2024
-
[24]
Videos of teachers hitting children
Oversight Board. Videos of teachers hitting children. https://www.oversightboard.com/ decision/bun-rn8jimnx/, 2025. Accessed 2026-05-07
work page 2025
-
[25]
OpenAI. Gpt-5.4. https://developers.openai.com/api/docs/models/gpt-5.4, 2026. Accessed: 2026-05-07
work page 2026
-
[26]
Google DeepMind. Gemini 3.1 pro model card. https://deepmind.google/models/ model-cards/gemini-3-1-pro/, 2026. Accessed: 2026-05-07
work page 2026
-
[27]
Anthropic. Claude opus 4.6 system card. https://www-cdn.anthropic.com/ 14e4fb01875d2a69f646fa5e574dea2b1c0ff7b5.pdf, 2026. Accessed: 2026-05-07
work page 2026
-
[28]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report. a...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Shuai Bai et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, Zhaokai Wang, Zhe Chen, Hongjie Zhang, Ganlin Yang, Haomin Wang, Qi Wei, Jinhui Yin, Wenhao Li, Erfei Cui, Guanzhou Chen, Zichen Ding, Changyao Tian, Zhenyu Wu, Jingjing Xie, Zehao Li, Bowen Yang, Yuchen Duan, Xuehui Wang, Songze L...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Lukas Helff, Felix Friedrich, Manuel Brack, Kristian Kersting, and Patrick Schramowski. Llavaguard: An open vlm-based framework for safeguarding vision datasets and models.arXiv preprint arXiv:2406.05113, 2024. 11 A Prompts A.1 Evaluation Prompt Overview Table 7 summarizes the prompt templates used for the diagnostic tasks and ablation settings. All promp...
-
[32]
source: the rule ID that affects another
-
[33]
target: the rule ID being affected
- [34]
-
[35]
rationale: brief explanation of why this relation exists Output a JSON object with a "decision_relations" array. Example: { "decision_relations": [ {"source": "AR1", "target": "AR2", "type": "gating", "rationale": "AR1 is a prerequisite for AR2"} ] } If no relations exist, output: {"decision_relations": []} Output only the JSON, no additional text. Task 3...
-
[36]
ClaimsQuestion: Do the main claims made in the abstract and introduction accurately reflect the paper’s contributions and scope? Answer: [Yes] Justification: The abstract and introduction state the paper’s main scope as evaluating rule-conditioned decision reasoning in vision-language content moderation. The claimed contributions match the benchmark formu...
-
[37]
LimitationsQuestion: Does the paper discuss the limitations of the work performed by the authors? Answer: [Yes] Justification: The paper discusses scope limitations in the conclusion and appendix. In particular, RuleSafe-VL is grounded in publicly available policies, covers three high-risk visually grounded policy families, and uses controlled audience-pu...
-
[38]
It proposes a benchmark formulation, dataset construction protocol, and empirical evaluation
Theory assumptions and proofsQuestion: For each theoretical result, does the paper provide the full set of assumptions and a complete proof? Answer: [N/A] Justification: The paper does not present theoretical results or formal proofs. It proposes a benchmark formulation, dataset construction protocol, and empirical evaluation
-
[39]
Experimental result reproducibilityQuestion: Does the paper fully disclose all the information needed to reproduce the main experimental results of the paper to the extent that it affects the main claims and/or conclusions of the paper? Answer: [Yes] Justification: The paper describes the evaluated model groups, task definitions, primary metrics, structur...
-
[40]
Open access to data and codeQuestion: Does the paper provide open access to the data and code, with sufficient instructions to faithfully reproduce the main experimental results, as described in supplemental material? Answer: [Yes] Justification: The paper includes dataset documentation and release details in Appendix F. We will release the dataset, promp...
-
[41]
Experimental setting/detailsQuestion: Does the paper specify all the training and test details necessary to understand the results? Answer: [Yes] Justification: The paper specifies the benchmark tasks, model groups, evaluation metrics, prompt-based evaluation setup, structured output requirements, and parsing rules. Additional prompt templates, task-speci...
-
[42]
Experiment statistical significanceQuestion: Does the paper report error bars suitably and correctly defined or other appropriate information about the statistical significance of the experiments? Answer: [No] Justification: The main benchmark results are deterministic evaluations against fixed labels, and the paper reports exact scores rather than statis...
-
[43]
Experiments compute resourcesQuestion: For each experiment, does the paper provide sufficient information on the computer resources needed to reproduce the experiments? Answer: [Yes] 36 Justification: The paper reports the evaluated model set and prompt-based evaluation protocol. Appendix E includes implementation details for running the evaluation, inclu...
-
[44]
Code of ethicsQuestion: Does the research conducted in the paper conform, in every respect, with the NeurIPS Code of Ethics? Answer: [Yes] Justification: The work is designed for safety evaluation and benchmark construction. The paper documents harmful-content handling, intended use, prohibited use, privacy filtering, annotator safety considerations, and ...
-
[45]
Broader impactsQuestion: Does the paper discuss both potential positive societal impacts and negative societal impacts of the work performed? Answer: [Yes] Justification: Appendix F discusses intended positive uses for auditing and improving policy-grounded moderation systems, as well as risks such as misuse of harmful-content examples, over-reliance on a...
-
[46]
SafeguardsQuestion: Does the paper describe safeguards that have been put in place for responsible release of data or models that have a high risk for misuse? Answer: [Yes] Justification: The benchmark contains safety-sensitive moderation cases, so Appendix F describes release safeguards, intended-use restrictions, harmful-content handling, privacy filter...
-
[47]
Licenses for existing assetsQuestion: Are the creators or original owners of assets used in the paper properly credited, and are the license and terms of use explicitly mentioned and properly respected? Answer: [Yes] Justification: The paper uses public policies, public benchmarks, and open image-text resources as source material. Appendix F documents sou...
-
[48]
New assetsQuestion: Are new assets introduced in the paper well documented and is the documentation provided alongside the assets? Answer: [Yes] Justification: The paper introduces RuleSafe-VL as a new benchmark asset. Appendix F provides dataset documentation, including data fields, source material, annotation process, intended use, release format, and m...
-
[49]
Crowdsourcing and research with human subjectsQuestion: For crowdsourcing experi- ments and research with human subjects, does the paper include the full text of instructions given to participants and screenshots, if applicable, as well as details about compensation, eligibility, and consent? Answer: [Yes] Justification: The paper uses trained expert anno...
-
[50]
Appendix F describes annotator safety procedures, exposure warnings, and data handling
Institutional review board approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board approval or an equivalent approval/review based on the requirements of your country or institution wa...
-
[51]
Declaration of LLM usageQuestion: Does the paper describe the usage of LLMs if it is an important, original, or non-standard component of the core methods in this research? Answer: [Yes] Justification: The paper discloses LLM use during dataset construction for drafting candidate case descriptions and provisional instance labeling. These outputs are used ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.