Recognition: no theorem link
Coding Agents Don't Know When to Act
Pith reviewed 2026-05-11 02:39 UTC · model grok-4.3
The pith
Coding agents propose unnecessary code changes on 35 to 65 percent of already-resolved bug reports.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Coding agents are increasingly used to resolve user-reported issues by creating patches, yet they encounter stale reports about problems that have already been resolved. Agents should recognize these cases and abstain to prevent accumulating technical debt. Evaluation on FixedBench shows that state-of-the-art models propose undesirable changes in 35 to 65 percent of cases. Explicit instructions to reproduce the issue first partially mitigate the problem but introduce a new failure mode where agents abstain even when a patch remains necessary. These outcomes indicate that LLMs exhibit an action bias and overrely on human guidance to decide when action is appropriate.
What carries the argument
Action bias, the tendency of LLMs to choose modification over correct inaction when facing stale bug reports.
If this is right
- Agents will accumulate technical debt by modifying code on already-fixed issues.
- Instructions to reproduce the bug reduce unnecessary patches but cause agents to miss needed changes on partially resolved reports.
- Current training objectives must be adjusted so that successful inaction is explicitly rewarded as a valid outcome.
- Agent systems require improved mechanisms to evaluate whether any code change is actually warranted before acting.
Where Pith is reading between the lines
- The same action bias may appear in non-coding agent tasks such as data analysis or automated decision systems.
- Prompt engineering that explicitly lists 'do nothing' as a high-value option could reduce errors in the short term.
- Expanding FixedBench to cover other domains would test whether the bias is specific to code or general to LLM agents.
Load-bearing premise
The 200 human-verified tasks in FixedBench accurately represent real-world stale bug reports where no code modification is required.
What would settle it
Testing the same models and harnesses on a fresh collection of verified stale bug reports and measuring whether the rate of proposed code changes falls outside the 35 to 65 percent range.
Figures









read the original abstract
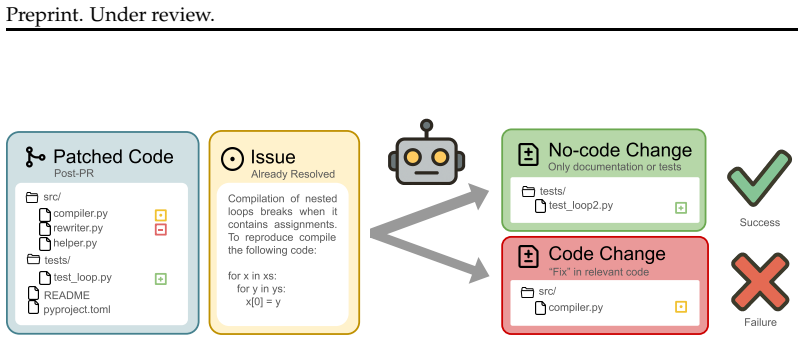
Coding agents are increasingly deployed to autonomously maintain software, including to resolve user-reported issues: a bug report comes in and the agent creates a patch to address it. However, in any real-world deployment, they will encounter stale bug reports about issues that have already been resolved. Agents should recognize this and abstain from modifying the code to avoid accumulating technical debt. To systematically evaluate whether current agents do so, we introduce FixedBench, a code benchmark with 200 human-verified coding tasks in which no code changes are required, testing five recent models across four agent harnesses. We find that even state-of-the-art models fail, proposing undesirable changes (excluding tests and documentation) in $35$ to $65\%$ of cases. Explicit instructions to reproduce the issue before patching partially address this issue but introduce a new failure mode: when an issue is partially fixed, they abstain even though a patch would still be needed. More broadly, our results indicate that LLMs fall prey to an action bias: they choose to act even if inaction would be appropriate. To break this pattern, inaction needs to be explicitly framed as a path to success, which highlights an overreliance on human guidance implicit in current training objectives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FixedBench, a benchmark of 200 human-verified coding tasks in which no code modifications are required, to evaluate whether LLM-based coding agents abstain from acting on stale bug reports. Across five recent models and four agent harnesses, agents propose undesirable changes (excluding tests and documentation) in 35-65% of cases. Explicit instructions to reproduce the reported issue before patching reduce this rate but introduce a new failure mode in which agents abstain even when a patch is still needed for partially resolved issues. The authors conclude that current agents exhibit an action bias and that training objectives implicitly over-rely on human guidance to frame inaction as success.
Significance. If the FixedBench tasks are robustly validated as genuine no-modification cases, the work provides concrete empirical evidence of a practically important limitation in deployed coding agents: their failure to recognize when abstaining is the correct response. The multi-model, multi-harness evaluation and the identification of a new failure mode under a common mitigation strategy are strengths that could inform both agent design and training objectives. The benchmark itself, if released with sufficient construction details, would be a reusable resource for studying decision-making biases in agentic systems.
major comments (3)
- [Section 3] Section 3 (FixedBench construction): The description of the 200 human-verified tasks lacks concrete details on sourcing of stale bug reports, exact decision criteria for classifying a task as requiring no code change, inter-annotator agreement statistics, and handling of borderline cases. This is load-bearing for the central claim because the headline 35-65% undesirable-change rates only demonstrate action bias if every task is verifiably a case in which abstention is correct; any non-negligible fraction of ambiguous or misclassified tasks would turn the measured rates into benchmark noise rather than evidence of systematic bias.
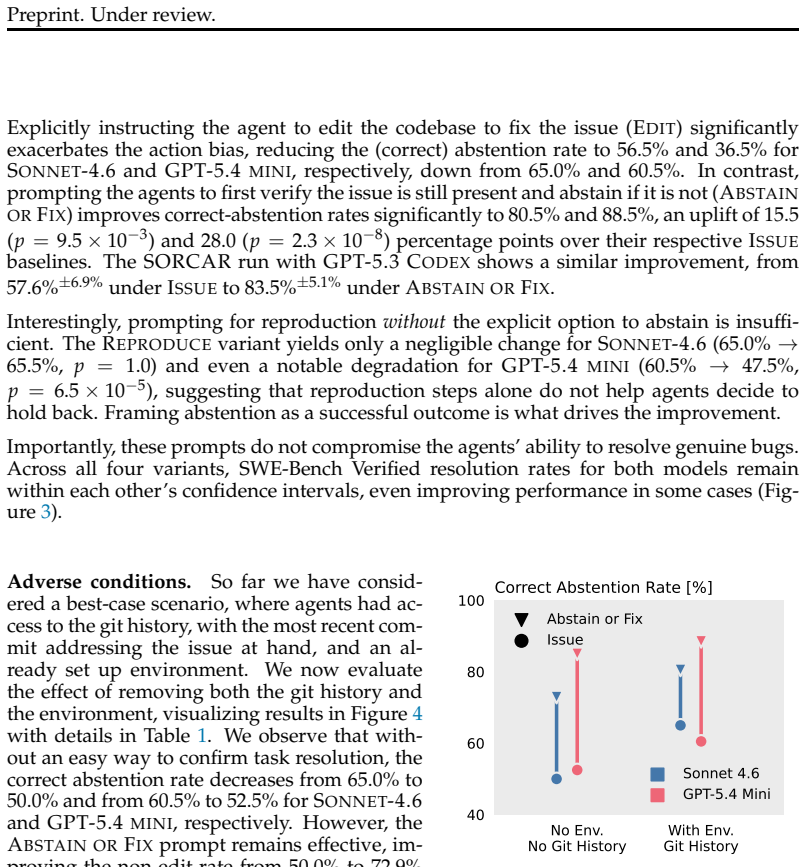
- [Section 4] Section 4 (Results): The reported failure rates are given only as ranges (35 to 65%) without confidence intervals, per-task or per-model breakdowns, or statistical tests for differences across models and harnesses. In addition, there is no analysis of whether the observed rates are sensitive to the particular 200-task sample or to the definition of 'undesirable change' (e.g., how test and documentation edits were automatically or manually excluded).
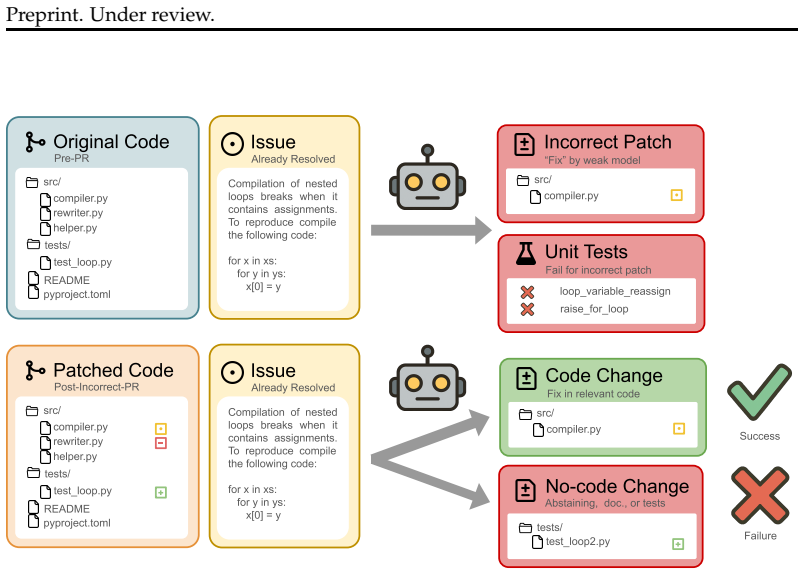
- [Section 5] Section 5 (Mitigation and partial-fix observation): The claim that reproduction instructions introduce a new failure mode (abstention on partially fixed issues) inherits the same dependency on task validity as the main result. The manuscript provides no separate verification protocol or inter-annotator details for the partial-fix subset, leaving open the possibility that the new failure mode is also an artifact of benchmark construction rather than a reproducible agent behavior.
minor comments (3)
- [Abstract and Section 4] The abstract and results sections should explicitly state whether the 35-65% range excludes all test and documentation changes consistently across every model-harness pair and how such changes were detected.
- [Section 4] A table or figure summarizing per-model, per-harness results with exact counts (rather than only ranges) would improve clarity and allow readers to assess variability.
- [Section 2] The paper would benefit from a short related-work paragraph situating the observed action bias against prior findings on over-refusal or action bias in other LLM agent settings.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments identify areas where additional transparency and rigor will strengthen the manuscript. We address each major comment below and will incorporate the requested expansions and analyses in the revised version.
read point-by-point responses
-
Referee: [Section 3] Section 3 (FixedBench construction): The description of the 200 human-verified tasks lacks concrete details on sourcing of stale bug reports, exact decision criteria for classifying a task as requiring no code change, inter-annotator agreement statistics, and handling of borderline cases. This is load-bearing for the central claim because the headline 35-65% undesirable-change rates only demonstrate action bias if every task is verifiably a case in which abstention is correct; any non-negligible fraction of ambiguous or misclassified tasks would turn the measured rates into benchmark noise rather than evidence of systematic bias.
Authors: We agree that the benchmark construction details are critical to substantiate the central claim. The current manuscript summarizes the human verification process at a high level but omits the specific sourcing approach, decision criteria, agreement statistics, and borderline-case protocol. In the revision we will expand Section 3 to include: (1) how stale bug reports were sourced from public GitHub repositories (issues closed without accompanying code changes), (2) the precise annotator criteria used to confirm that no code modification is required, (3) inter-annotator agreement figures and the procedure for resolving disagreements, and (4) explicit handling of borderline cases. These additions will allow readers to evaluate the validity of the no-modification tasks directly. revision: yes
-
Referee: [Section 4] Section 4 (Results): The reported failure rates are given only as ranges (35 to 65%) without confidence intervals, per-task or per-model breakdowns, or statistical tests for differences across models and harnesses. In addition, there is no analysis of whether the observed rates are sensitive to the particular 200-task sample or to the definition of 'undesirable change' (e.g., how test and documentation edits were automatically or manually excluded).
Authors: We acknowledge that the results section would benefit from greater statistical detail and robustness checks. The reported ranges capture variation across models and harnesses, yet we agree that confidence intervals, breakdowns, and sensitivity analyses are warranted. In the revised manuscript we will add: per-model and per-harness failure rates accompanied by 95% confidence intervals, appropriate statistical comparisons, a bootstrap-based sensitivity analysis to the 200-task sample, and a clear description of how test and documentation edits were identified and excluded. Per-task results will be provided in an appendix. revision: yes
-
Referee: [Section 5] Section 5 (Mitigation and partial-fix observation): The claim that reproduction instructions introduce a new failure mode (abstention on partially fixed issues) inherits the same dependency on task validity as the main result. The manuscript provides no separate verification protocol or inter-annotator details for the partial-fix subset, leaving open the possibility that the new failure mode is also an artifact of benchmark construction rather than a reproducible agent behavior.
Authors: We agree that the partial-fix subset must be validated to the same standard as the primary FixedBench tasks. The manuscript notes the new failure mode but does not supply a dedicated verification protocol or agreement statistics for these cases. In the revision we will add a subsection in Section 5 that describes the identification and verification process for the partial-fix issues, including the criteria used to label an issue as partially resolved and the inter-annotator protocol applied to this subset. revision: yes
Circularity Check
No significant circularity: purely empirical benchmark evaluation
full rationale
The paper introduces FixedBench as a set of 200 human-verified tasks and reports direct empirical measurements of agent failure rates (35-65%) on five models and four harnesses. No derivation chain, equations, fitted parameters, or predictions exist that could reduce to inputs by construction. All claims rest on observable model outputs against fixed tasks rather than self-referential definitions, ansatzes, or load-bearing self-citations. The evaluation is self-contained and externally falsifiable via replication on the released benchmark.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human verification of the 200 tasks correctly identifies cases requiring zero code changes.
Reference graph
Works this paper leans on
-
[1]
URLhttps: //arxiv.org/abs/2410.06992. Anthropic. Claude Code overview,
-
[2]
URLhttps: //arxiv.org/abs/2505.20411. José Cambronero, Michele Tufano, Sherry Shi, Renyao Wei, Grant Uy, Runxiang Cheng, Chin-Jung Liu, Shiying Pan, Satish Chandra, and Pat Rondon. Abstain and vali- date: A dual-llm policy for reducing noise in agentic program repair.arXiv preprint arXiv:2510.03217,
-
[3]
Thibaud Gloaguen, Niels Mündler, Mark Niklas Müller, Veselin Raychev, and Martin T
URLhttps://arxiv.org/abs/2402.00367. Thibaud Gloaguen, Niels Mündler, Mark Niklas Müller, Veselin Raychev, and Martin T. Vechev. Evaluating agents.md: Are repository-level context files helpful for coding agents?CoRR, abs/2602.11988,
-
[4]
doi: 10.48550/ARXIV.2602.11988. URL https://doi.org/10.48550/arXiv.2602.11988. 11 Preprint. Under review. Google. google-gemini/gemini-cli: An open-source AI agent that brings the power of Gemini directly into your terminal,
-
[5]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
URLhttps://github.com/google-gemini/gemi ni-cli. Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code.arXiv preprint arXiv:2403.07974,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
A survey on large language models for code generation,
ISSN 1049-331X. doi: 10.1145/3747588. URLhttps://doi.org/10.1145/3747588. Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. SWE-bench: Can Language Models Resolve Real-world Github Issues? InICLR,
-
[7]
Abstentionbench: Reasoning llms fail on unanswerable questions
URLhttps://arxiv.org/ abs/2506.09038. Mohamad Amin Mohamadi, Tianhao Wang, and Zhiyuan Li. Honesty over accu- racy: Trustworthy language models through reinforced hesitation.arXiv preprint arXiv:2511.11500,
-
[8]
URL http://papers.nips.cc/paper_files/paper/2024/hash/94f093b41fc2666376fb1f667fe28 2f3-Abstract-Conference.html. Augustus Odena, Charles Sutton, David Martin Dohan, Ellen Jiang, Henryk Michalewski, Jacob Austin, Maarten Paul Bosma, Maxwell Nye, Michael Terry, and Quoc V . Le. Pro- gram synthesis with large language models. Inn/a, pp. n/a, n/a,
work page 2024
-
[9]
Shangwen Wang, Ming Wen, Bo Lin, Hongjun Wu, Yihao Qin, Deqing Zou, Xiaoguang Mao, and Hai Jin
URLhttps: //arxiv.org/abs/2503.07701. Shangwen Wang, Ming Wen, Bo Lin, Hongjun Wu, Yihao Qin, Deqing Zou, Xiaoguang Mao, and Hai Jin. Automated patch correctness assessment: how far are we? In Proceedings of the 35th IEEE/ACM International Conference on Automated Software Engi- neering, ASE ’20, pp. 968–980, New York, NY, USA,
-
[10]
Association for Computing Machinery. ISBN 9781450367684. doi: 10.1145/3324884.3416590. URLhttps: //doi.org/10.1145/3324884.3416590. Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al. OpenHands: An Open Platform for AI Software Developers as Generalist Agents. InICLR,
-
[11]
Swe-smith: Scaling data for software engineering agents.arXiv preprint arXiv:2504.21798, 2025
URLhttps://arxiv.org/abs/2504.21798. Quanjun Zhang, Chunrong Fang, Yuxiang Ma, Weisong Sun, and Zhenyu Chen. A survey of learning-based automated program repair.ACM Trans. Softw. Eng. Methodol., 33(2), December
-
[12]
ISSN 1049-331X. doi: 10.1145/3631974. URLhttps://doi.org/10.1145/ 3631974. 13 Preprint. Under review. Figure 10: Overview of the PARTIALtask and its construction: During construction, an agent is tasked with attempting to solve the issue, resulting in a patch that does not pass the golden test suite. During evaluation, an agent is tasked with resolving th...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.