Recognition: no theorem link
FAVOR: Efficient Filter-Agnostic Vector ANNS Based on Selectivity-Aware Exclusion Distances
Pith reviewed 2026-05-11 02:34 UTC · model grok-4.3
The pith
FAVOR uses exclusion distances in HNSW graphs to push non-matching vectors away, delivering faster filtered vector search across all selectivity levels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
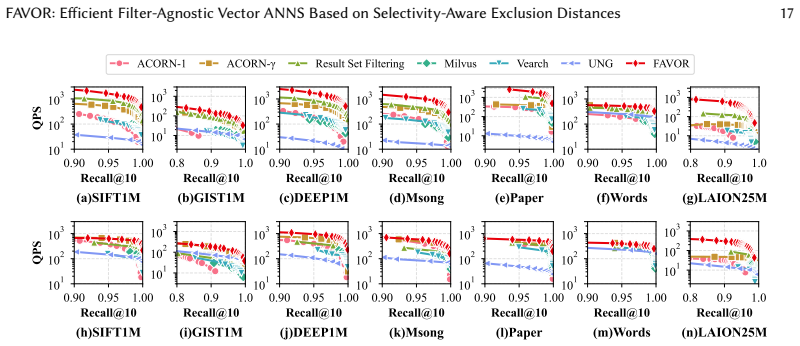
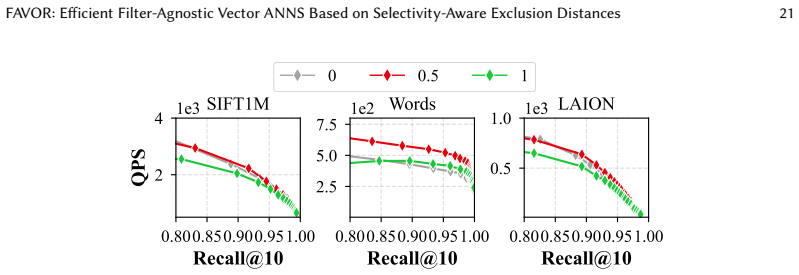
FAVOR presents a filter-agnostic ANNS architecture built on HNSW that adds an exclusion distance mechanism to dynamically increase distances to non-target vectors and decrease distances to valid candidates, thereby improving search efficiency without altering graph connectivity. A selectivity-driven selector estimates the fraction of vectors satisfying the filter and routes low-selectivity queries to a pre-filtering brute-force path while directing the rest to the optimized inline HNSW algorithm. Experiments on real-world datasets show this yields 1.3-5× higher QPS at Recall@10 = 95% versus prior methods for arbitrary filters.
What carries the argument
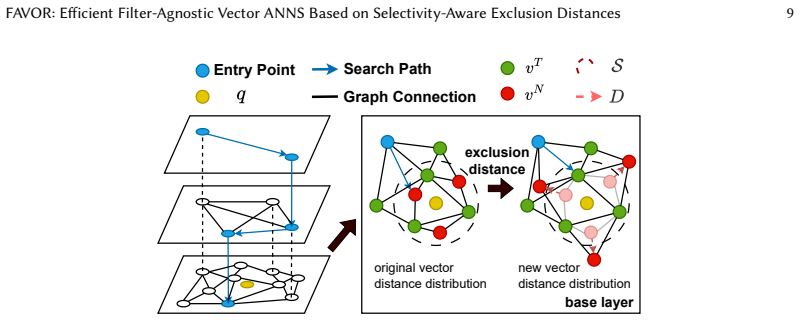
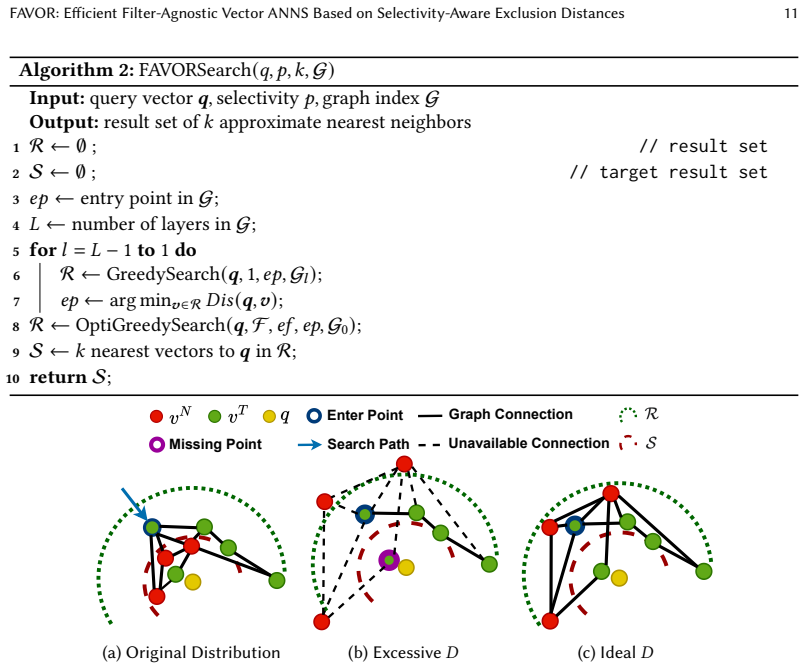
The exclusion distance mechanism inside HNSW-based inline filtering, which reshapes the vector distance distribution to favor target vectors for a given filter condition.
If this is right
- Consistent high throughput is obtained for arbitrary filter conditions instead of requiring filter-specific index variants.
- Low-selectivity queries avoid the inefficiency of traversing the full graph by switching to pre-filtering.
- Graph connectivity remains intact, so the same index supports both unfiltered and filtered searches.
- Selectivity estimation is integrated into the query path rather than treated as a separate preprocessing step.
Where Pith is reading between the lines
- The same exclusion-distance idea could be tested on other proximity graphs such as NSG or Vamana to see whether the gains transfer.
- Production systems might reduce the number of separate filtered indexes they maintain if one FAVOR-style index covers the full range of selectivity.
- The approach opens a route to adaptive query planning that also considers index size or memory constraints when choosing the search path.
Load-bearing premise
That the exclusion distance adjustment improves search speed without breaking the connectivity or reachability of valid candidates in the graph.
What would settle it
Measure recall and QPS on a dataset where many vectors have nearly identical attributes; if recall at 95% drops below the baseline or QPS gains disappear, the exclusion distance is not preserving search quality.
Figures








read the original abstract
Modern retrieval systems increasingly require integrating approximate nearest neighbor search (ANNS) with complex attribute filtering to handle hybrid queries in applications such as recommendation systems and retrieval-augmented generation (RAG). While HNSW-based inline-filtering methods show promise, existing approaches struggle to deliver high throughput under low-selectivity scenarios while balancing search efficiency, filtering generality, and index connectivity. To address these challenges, we propose FAVOR, an efficient filter-agnostic vector ANNS that supports arbitrary filtering conditions while maintaining stable performance across varying selectivity levels. FAVOR introduces three novel features: (1) an integrated architecture that unifies selectivity estimation and filtered ANNS execution, providing a cohesive solution for hybrid vector-attribute queries; (2) a HNSW-based inline-filtering algorithm that introduces an exclusion distance mechanism to dynamically reshape the vector distance distribution, pushing non-target vectors away from the query while promoting valid candidates toward the query, thus improving search efficiency without compromising generality or graph connectivity; and (3) a selectivity-driven search selector that estimates query selectivity and dynamically routes queries between a pre-filtering brute-force algorithm for low-selectivity cases and an optimized HNSW-based search algorithm for other scenarios, ensuring consistent performance. Extensive experiments on real-world datasets demonstrate that FAVOR achieves a 1.3-5$\times$ higher QPS at $Recall@10 = 95\%$ compared to state-of-the-art methods for arbitrary filtering conditions, while maintaining competitive performance even against tailored solutions in some filtering conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FAVOR, a filter-agnostic ANNS method for hybrid vector-attribute queries. It integrates selectivity estimation with an HNSW-based inline filtering algorithm that uses an exclusion distance mechanism to dynamically reshape distances (pushing non-matching vectors away while promoting valid candidates) and a selectivity-driven search selector that routes low-selectivity queries to pre-filtering brute-force and others to optimized HNSW search. The central claim is that this yields 1.3-5× higher QPS at Recall@10 = 95% versus state-of-the-art methods for arbitrary filtering conditions while remaining competitive with tailored solutions.
Significance. If the performance claims and recall guarantees hold, FAVOR would offer a practical, general-purpose advance for filtered ANNS in production retrieval systems (recommendation, RAG) by avoiding the need for per-filter indexes or custom connectivity while delivering stable throughput across selectivity regimes. The unification of selectivity estimation and search routing is a clear engineering strength.
major comments (2)
- [HNSW-based inline-filtering algorithm section] The exclusion-distance mechanism (described in the HNSW-based inline-filtering algorithm) lacks any analysis of its effect on HNSW traversal paths, greedy neighbor selection, or entry-point navigation. Because HNSW decisions depend on relative distance ordering, dynamically increasing distances for non-matching vectors can alter which edges are followed and potentially exclude valid filtered candidates that would have been reached under unmodified distances; no bound, ablation, or candidate-set-quality metric is provided to quantify this risk. This directly bears on the central QPS-at-95%-recall claim.
- [Experiments section] The experimental evaluation reports 1.3-5× QPS gains at Recall@10 = 95% but supplies no details on the precise baselines (including their filtering implementations), error bars across runs, data-partitioning or exclusion rules, or the exact selectivity ranges tested. Without these, it is impossible to verify that the gains are attributable to the exclusion-distance and selector components rather than implementation artifacts or favorable dataset properties.
minor comments (2)
- Notation for the exclusion distance and selectivity estimator should be introduced with explicit equations rather than prose descriptions to aid reproducibility.
- Figure captions for the QPS-recall curves should explicitly state the filtering conditions (e.g., attribute cardinality, selectivity) used in each panel.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation and reproducibility.
read point-by-point responses
-
Referee: [HNSW-based inline-filtering algorithm section] The exclusion-distance mechanism (described in the HNSW-based inline-filtering algorithm) lacks any analysis of its effect on HNSW traversal paths, greedy neighbor selection, or entry-point navigation. Because HNSW decisions depend on relative distance ordering, dynamically increasing distances for non-matching vectors can alter which edges are followed and potentially exclude valid filtered candidates that would have been reached under unmodified distances; no bound, ablation, or candidate-set-quality metric is provided to quantify this risk. This directly bears on the central QPS-at-95%-recall claim.
Authors: We appreciate the referee highlighting this aspect. The exclusion distance is applied exclusively to non-matching vectors while leaving distances to matching vectors unchanged, thereby preserving relative orderings among all valid candidates and the original graph connectivity. This design guides greedy selection toward matching vectors without introducing new edges or altering the index. Nevertheless, we acknowledge that an explicit analysis of traversal dynamics would further substantiate the claims. In the revision we will add an ablation study reporting candidate-set quality metrics (e.g., fraction of valid vectors visited) and traversal-path statistics under reshaped versus original distances, directly quantifying any impact on recall. revision: yes
-
Referee: [Experiments section] The experimental evaluation reports 1.3-5× QPS gains at Recall@10 = 95% but supplies no details on the precise baselines (including their filtering implementations), error bars across runs, data-partitioning or exclusion rules, or the exact selectivity ranges tested. Without these, it is impossible to verify that the gains are attributable to the exclusion-distance and selector components rather than implementation artifacts or favorable dataset properties.
Authors: We agree that additional experimental details are required for full reproducibility and attribution of results. In the revised manuscript we will expand the Experiments section to specify: (i) exact baseline implementations and their filtering strategies (pre-filter, post-filter, or inline), (ii) error bars or standard deviations from repeated runs, (iii) data-partitioning and exclusion rules, and (iv) the precise selectivity ranges evaluated on each dataset. These clarifications will confirm that the reported QPS improvements arise from the proposed exclusion-distance and selector mechanisms. revision: yes
Circularity Check
No circularity: algorithmic proposal supported by experiments, not self-referential derivations
full rationale
The paper describes FAVOR as an integrated architecture combining selectivity estimation, an HNSW-based inline-filtering algorithm with an exclusion distance mechanism, and a selectivity-driven search selector. These are presented as novel algorithmic features without any equations, parameter fittings, or derivations that reduce to their own inputs by construction. Performance claims (1.3-5× QPS at Recall@10=95%) are grounded in extensive experiments on real-world datasets rather than mathematical self-consistency or self-citations. No load-bearing steps invoke uniqueness theorems, ansatzes smuggled via prior work, or renaming of known results. The method is self-contained as an engineering construction whose validity rests on empirical evaluation, not tautological reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Quoc V. Le and Tomás Mikolov. 2014. Distributed Representations of Sentences and Documents. InICML, Vol. 32. JMLR.org, 1188–1196. http://proceedings.mlr.press/v32/le14.html
work page 2014
-
[2]
Martin Grohe. 2020. word2vec, node2vec, graph2vec, X2vec: Towards a Theory of Vector Embeddings of Structured Data. InPODS. ACM, 1–16. doi:10.1145/3375395.3387641
-
[3]
Patrick S. H. Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. InNeurIPS. https://proceedings.neurips.cc/paper/2020/hash/ 6b493230205f780e1bc26945df7481...
work page 2020
-
[4]
Rae, Erich Elsen, and Laurent , Vol
Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George van den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, Diego de Las Casas, Aurelia Guy, Jacob Menick, Roman Ring, Tom Hennigan, Saffron Huang, Loren Maggiore, Chris Jones, Albin Cassirer, Andy Brock, Michela Paganini, Geoffrey Irving, Ori...
work page 2026
-
[5]
Jianguo Wang, Xiaomeng Yi, Rentong Guo, Hai Jin, Peng Xu, Shengjun Li, Xiangyu Wang, Xiangzhou Guo, Chengming Li, Xiaohai Xu, Kun Yu, Yuxing Yuan, Yinghao Zou, Jiquan Long, Yudong Cai, Zhenxiang Li, Zhifeng Zhang, Yihua Mo, Jun Gu, Ruiyi Jiang, Yi Wei, and Charles Xie. 2021. Milvus: A Purpose-Built Vector Data Management System. In SIGMOD. ACM, 2614–2627....
- [6]
-
[7]
Yu A Malkov and Dmitry A Yashunin. 2018. Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs.TPAMI42, 4 (2018), 824–836
work page 2018
-
[8]
Yuzheng Cai, Jiayang Shi, Yizhuo Chen, and Weiguo Zheng. 2024. Navigating Labels and Vectors: A Unified Approach to Filtered Approximate Nearest Neighbor Search.SIGMOD2, 6, Article 246 (2024), 27 pages. doi:10.1145/3698822
-
[9]
Zhaoheng Li, Silu Huang, Wei Ding, Yongjoo Park, and Jianjun Chen. 2025. SIEVE: Effective Filtered Vector Search with Collection of Indexes.PVLDB18, 11 (2025), 4723–4736
work page 2025
-
[10]
Chaoji Zuo, Miao Qiao, Wenchao Zhou, Feifei Li, and Dong Deng. 2024. SeRF: Segment Graph for Range-Filtering Approximate Nearest Neighbor Search.SIGMOD2, 1 (2024), 69:1–69:26. doi:10.1145/3639324
-
[11]
Liana Patel, Peter Kraft, Carlos Guestrin, and Matei Zaharia. 2024. ACORN: Performant and Predicate-Agnostic Search Over Vector Embeddings and Structured Data.SIGMOD2, 3 (2024), 120. doi:10.1145/3654923
-
[12]
Guoyu Hu, Shaofeng Cai, Tien Tuan Anh Dinh, Zhongle Xie, Cong Yue, Gang Chen, and Beng Chin Ooi. 2025. HAKES: Scalable Vector Database for Embedding Search Service.PVLDB18, 9 (2025), 3049–3062. doi:10.14778/3746405.3746427
-
[13]
Alexandr Andoni and Piotr Indyk. 2008. Near-optimal hashing algorithms for approximate nearest neighbor in high dimensions.Commun. ACM51, 1 (2008), 117–122. doi:10.1145/1327452.1327494
-
[14]
Alexandr Andoni and Ilya P. Razenshteyn. 2015. Optimal Data-Dependent Hashing for Approximate Near Neighbors. InSTOC. 793–801. doi:10.1145/2746539.2746553
-
[15]
Razenshteyn, and Ludwig Schmidt
Alexandr Andoni, Piotr Indyk, Thijs Laarhoven, Ilya P. Razenshteyn, and Ludwig Schmidt. 2015. Practical and Optimal LSH for Angular Distance. InNeurIPS. 1225–1233. https://proceedings.neurips.cc/paper/2015/hash/ 2823f4797102ce1a1aec05359cc16dd9-Abstract.html
work page 2015
- [16]
-
[17]
Michael E. Houle and Michael Nett. 2015. Rank-Based Similarity Search: Reducing the Dimensional Dependence. TPAMI37, 1 (2015), 136–150. doi:10.1109/TPAMI.2014.2343223
-
[18]
Kejing Lu, Hongya Wang, Wei Wang, and Mineichi Kudo. 2020. VHP: Approximate Nearest Neighbor Search via Virtual Hypersphere Partitioning.PVLDB13, 9 (2020), 1443–1455. doi:10.14778/3397230.3397240
-
[19]
Marius Muja and David G. Lowe. 2014. Scalable Nearest Neighbor Algorithms for High Dimensional Data.TPAMI36, 11 (2014), 2227–2240. doi:10.1109/TPAMI.2014.2321376
-
[20]
Yury Malkov, Alexander Ponomarenko, Andrey Logvinov, and Vladimir Krylov. 2014. Approximate nearest neighbor algorithm based on navigable small world graphs.Inf. Syst.45 (2014), 61–68. doi:10.1016/J.IS.2013.10.006
-
[21]
Wei Wu, Junlin He, Yu Qiao, Guoheng Fu, Li Liu, and Jin Yu. 2022. HQANN: Efficient and Robust Similarity Search for Hybrid Queries with Structured and Unstructured Constraints. InCIKM. ACM, 4580–4584. doi:10.1145/3511808.3557610
-
[22]
Mengzhao Wang, Lingwei Lv, Xiaoliang Xu, Yuxiang Wang, Qiang Yue, and Jiongkang Ni. 2023. An Efficient and Robust Framework for Approximate Nearest Neighbor Search with Attribute Constraint. InNeurIPS. http://papers. nips.cc/paper_files/paper/2023/hash/32e41d6b0a51a63a9a90697da19d235d-Abstract-Conference.html
work page 2023
-
[23]
Gaurav Gupta, Jonah Yi, Benjamin Coleman, Chen Luo, Vihan Lakshman, and Anshumali Shrivastava. 2023. CAPS: A Practical Partition Index for Filtered Similarity Search.CoRRabs/2308.15014 (2023). doi:10.48550/ARXIV.2308.15014 arXiv:2308.15014
-
[24]
Siddharth Gollapudi, Neel Karia, Varun Sivashankar, Ravishankar Krishnaswamy, Nikit Begwani, Swapnil Raz, Yiyong Lin, Yin Zhang, Neelam Mahapatro, Premkumar Srinivasan, Amit Singh, and Harsha Vardhan Simhadri. 2023. Filtered- DiskANN: Graph Algorithms for Approximate Nearest Neighbor Search with Filters. InWWW. ACM, 3406–3416. doi:10.1145/3543507.3583552
-
[25]
Joshua Engels, Benjamin Landrum, Shangdi Yu, Laxman Dhulipala, and Julian Shun. 2024. Approximate Nearest Neighbor Search with Window Filters. InICML. OpenReview.net. https://openreview.net/forum?id=8t8zBaGFar
work page 2024
-
[26]
Yuexuan Xu, Jianyang Gao, Yutong Gou, Cheng Long, and Christian S. Jensen. 2024. iRangeGraph: Improvising Range- dedicated Graphs for Range-filtering Nearest Neighbor Search.SIGMOD2, 6 (2024), 239:1–239:26. doi:10.1145/3698814
-
[27]
Anqi Liang, Pengcheng Zhang, Bin Yao, Zhongpu Chen, Yitong Song, and Guangxu Cheng. 2024. UNIFY: Unified Index for Range Filtered Approximate Nearest Neighbors Search.PVLDB18, 4 (2024), 1118–1130. https://www.vldb. , Vol. 1, No. 1, Article . Publication date: May 2026. FAVOR: Efficient Filter-Agnostic Vector ANNS Based on Selectivity-Aware Exclusion Dista...
work page 2024
-
[28]
Chaoji Zuo and Dong Deng. 2023. ARKGraph: All-Range Approximate K-Nearest-Neighbor Graph.PVLDB16, 10 (2023), 2645–2658. doi:10.14778/3603581.3603601
-
[29]
Weijie Zhao, Shulong Tan, and Ping Li. 2022. Constrained Approximate Similarity Search on Proximity Graph.CoRR abs/2210.14958 (2022). doi:10.48550/ARXIV.2210.14958 arXiv:2210.14958
-
[30]
Gaurav Sehgal and Semih Salihoglu. 2025. NaviX: A Native Vector Index Design for Graph DBMSs With Robust Predicate-Agnostic Search Performance.PVLDB18, 11 (2025), 4438–4450. https://www.vldb.org/pvldb/vol18/p4438- sehgal.pdf
work page 2025
-
[31]
Jerzy W. Jaromczyk and Godfried T. Toussaint. 1992. Relative neighborhood graphs and their relatives.Proc. IEEE80, 9 (1992), 1502–1517. doi:10.1109/5.163414
-
[32]
1991.An introduction to probability theory and its applications, Volume 2
William Feller. 1991.An introduction to probability theory and its applications, Volume 2. Vol. 2. John Wiley & Sons
work page 1991
-
[33]
JFC Kingman. 1993.Poisson Processes. Oxford University Press, United Kingdom
work page 1993
- [34]
-
[35]
Norman R. Draper and Harry Smith. 1998.Applied Regression Analysis
work page 1998
-
[36]
Zeyu Wang, Haoran Xiong, Qitong Wang, Zhenying He, Peng Wang, Themis Palpanas, and Wei Wang. 2024. Dimensionality-Reduction Techniques for Approximate Nearest Neighbor Search: A Survey and Evaluation.IEEE Data Eng. Bull.48, 3 (2024), 63–80. http://sites.computer.org/debull/A24sept/p63.pdf
work page 2024
-
[37]
Sairaj Voruganti and M. Tamer Özsu. 2025. MIRAGE-ANNS: Mixed Approach Graph-based Indexing for Approximate Nearest Neighbor Search.SIGMOD3, 3, Article 188 (2025), 27 pages. doi:10.1145/3725325
-
[38]
Yun Peng, Byron Choi, Tsz Nam Chan, Jianye Yang, and Jianliang Xu. 2023. Efficient Approximate Nearest Neighbor Search in Multi-dimensional Databases.SIGMOD1, 1, Article 54 (2023), 27 pages. doi:10.1145/3588908
-
[39]
Yun Peng, Byron Choi, Tsz Nam Chan, and Jianliang Xu. 2022. LAN: Learning-based Approximate k-Nearest Neighbor Search in Graph Databases. InICDE. 2508–2521. doi:10.1109/ICDE53745.2022.00233
-
[40]
Mengxu Jiang, Zhi Yang, Fangyuan Zhang, Guanhao Hou, Jieming Shi, Wenchao Zhou, Feifei Li, and Sibo Wang. 2025. DIGRA: A Dynamic Graph Indexing for Approximate Nearest Neighbor Search with Range Filter.SIGMOD3, 3, Article 148 (2025), 26 pages. doi:10.1145/3725399
- [41]
-
[42]
Jianyang Gao, Yutong Gou, Yuexuan Xu, Yongyi Yang, Cheng Long, and Raymond Chi-Wing Wong. 2025. Practical and Asymptotically Optimal Quantization of High-Dimensional Vectors in Euclidean Space for Approximate Nearest Neighbor Search.SIGMOD3, 3, Article 202 (2025), 26 pages. doi:10.1145/3725413
-
[43]
Yutong Gou, Jianyang Gao, Yuexuan Xu, and Cheng Long. 2025. SymphonyQG: Towards Symphonious Integration of Quantization and Graph for Approximate Nearest Neighbor Search.SIGMOD3, 1, Article 80 (2025), 26 pages. doi:10.1145/3709730
-
[44]
Chuangxian Wei, Bin Wu, Sheng Wang, Renjie Lou, Chaoqun Zhan, Feifei Li, and Yuanzhe Cai. 2020. AnalyticDB-V: A Hybrid Analytical Engine Towards Query Fusion for Structured and Unstructured Data.PVLDB13, 12 (2020), 3152–3165. doi:10.14778/3415478.3415541
-
[45]
Yannis Chronis, Helena Caminal, Yannis Papakonstantinou, Fatma Özcan, and Anastasia Ailamaki. 2025. Filtered Vector Search: State-of-the-Art and Research Opportunities.PVLDB18, 12 (2025), 5488–5492. doi:10.14778/3750601.3750700
-
[46]
Fangyuan Zhang, Mengxu Jiang, Guanhao Hou, Jieming Shi, Hua Fan, Wenchao Zhou, Feifei Li, and Sibo Wang. 2025. Efficient Dynamic Indexing for Range Filtered Approximate Nearest Neighbor Search.SIGMOD3, 3, Article 152 (2025), 26 pages. doi:10.1145/3725401
-
[47]
Zhencan Peng, Miao Qiao, Wenchao Zhou, Feifei Li, and Dong Deng. 2025. Dynamic Range-Filtering Approximate Nearest Neighbor Search.PVLDB18, 10 (2025), 3256–3268. doi:10.14778/3748191.3748193 , Vol. 1, No. 1, Article . Publication date: May 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.