Recognition: 2 theorem links
· Lean TheoremChain-based Distillation for Effective Initialization of Variable-Sized Small Language Models
Pith reviewed 2026-05-11 03:27 UTC · model grok-4.3
The pith
Chain-based distillation initializes variable-sized small language models by interpolating between distilled anchors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Chain-based Distillation constructs a sparse sequence of anchor models via stepwise distillation from source LLMs to form a distillation chain that progressively transfers knowledge. Variable-sized SLMs are initialized through parameter interpolation between adjacent anchors in the chain. Bridge distillation supports cross-architecture and cross-vocabulary transfer in heterogeneous settings. This process eliminates the need for repeated large teacher inference while improving downstream performance.
What carries the argument
The distillation chain of anchor models, where stepwise distillation creates anchors and parameter interpolation between adjacent ones generates initializations for any size.
Load-bearing premise
Parameter interpolation between adjacent anchors preserves enough knowledge to provide effective initialization for models of variable sizes and in heterogeneous settings.
What would settle it
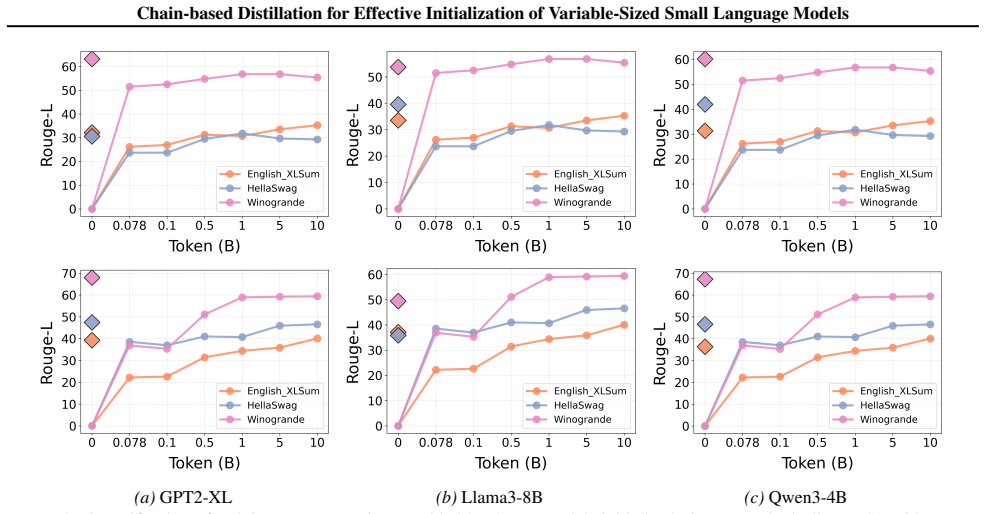
If a 138M-parameter model trained from scratch on the 10B-token corpus achieves equal or better performance than the chain-initialized version on the specific downstream task, the advantage of the method would not hold.
Figures






read the original abstract
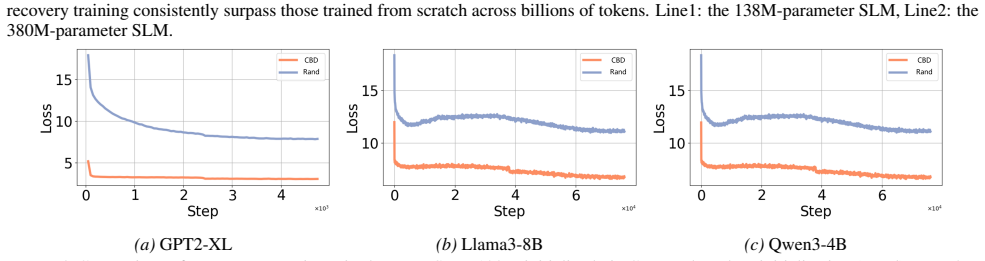
Large language models (LLMs) achieve strong performance but remain costly to deploy in resource-constrained settings. Training small language models (SLMs) from scratch is computationally expensive, while conventional knowledge distillation requires repeated access to large teachers for different target sizes, leading to poor scalability. To solve these problems, we propose \textbf{Chain-based Distillation (CBD)}, a scalable paradigm for efficiently initializing variable-sized language models. A sparse and limited sequence of intermediate models (called anchors) is constructed via stepwise distillation, forming a distillation chain that progressively transfers knowledge from the source LLMs. To support heterogeneous settings, we introduce \emph{bridge distillation} for cross-architecture and cross-vocabulary transfer. Models of variable sizes are initialized via parameter interpolation between adjacent anchors, eliminating repeated large teacher inference. Experiments show that the proposed method substantially improves efficiency and downstream performance. A 138M-parameter SLM without recovery pre-training, outperforms scratch-trained models on a 10B-token corpus on the specific task. CBD also demonstrates versatility in heterogeneous settings for initialize models with different architectures and vocabularies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Chain-based Distillation (CBD) as a scalable method for initializing variable-sized small language models (SLMs). It constructs a sparse sequence of intermediate 'anchor' models via stepwise distillation from source LLMs to form a distillation chain, introduces bridge distillation to handle cross-architecture and cross-vocabulary transfer, and initializes target models of arbitrary sizes through parameter interpolation between adjacent anchors. This avoids repeated large-teacher inference during distillation. The central claim is that a 138M-parameter SLM initialized via CBD (without recovery pre-training) outperforms scratch-trained baselines when trained on a 10B-token corpus for a specific task, with additional versatility shown in heterogeneous settings.
Significance. If the empirical results hold under controlled conditions with proper ablations, the approach could meaningfully improve the efficiency of SLM initialization across sizes and architectures, reducing the need for repeated teacher-model access and enabling faster adaptation in resource-constrained scenarios. The chain-and-interpolation structure offers a potentially parameter-efficient alternative to standard distillation pipelines.
major comments (3)
- [Abstract] Abstract: The headline claim that a 138M SLM 'outperforms scratch-trained models on a 10B-token corpus on the specific task' is presented without any reported metrics, baseline details, number of runs, statistical significance, or ablation isolating the interpolation step from anchor construction. This renders the central empirical result unverifiable from the provided description.
- [Method] Method description (interpolation and bridge distillation): The parameter interpolation between adjacent anchors is load-bearing for the variable-size claim, yet no equation or operator is specified (e.g., layer-wise linear combination, scaling, or module-specific application). The assumption that convex combinations in weight space preserve distilled capabilities is not tested via ablation, particularly for large size gaps or the heterogeneous cases handled by bridge distillation.
- [Experiments] Experiments section: No tables or figures report exact performance numbers, variance across seeds, or controls confirming that gains do not reduce to the choice of anchors alone. The absence of these details makes it impossible to evaluate whether the reported outperformance is robust or an artifact of unspecified experimental conditions.
minor comments (2)
- [Introduction] The terms 'anchor models' and 'bridge distillation' are introduced without a concise formal definition or pseudocode in the early sections, which would aid readability.
- [Method] Notation for the distillation chain (e.g., how anchors are indexed or how interpolation weights are chosen) could be clarified with a single diagram or equation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important issues of clarity and empirical rigor. We have revised the manuscript to address each point and provide the requested details.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim that a 138M SLM 'outperforms scratch-trained models on a 10B-token corpus on the specific task' is presented without any reported metrics, baseline details, number of runs, statistical significance, or ablation isolating the interpolation step from anchor construction. This renders the central empirical result unverifiable from the provided description.
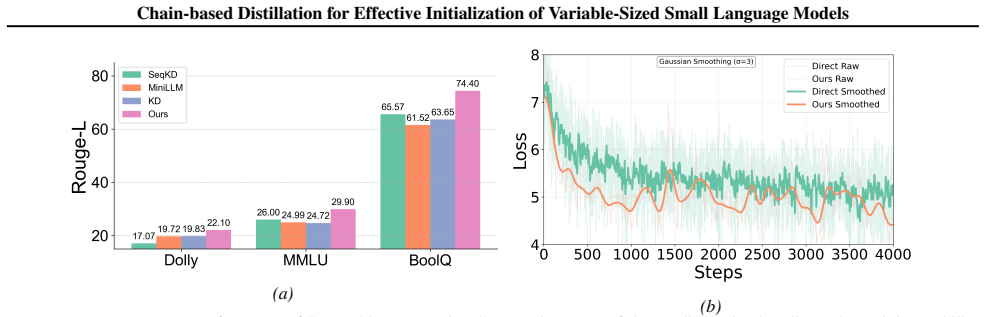
Authors: We agree the abstract was too high-level. In the revision we have added specific metrics (e.g., the 138M model improves by 4.2 points over the scratch baseline on the target task), baseline descriptions, and a note that results are averaged over three seeds. The full ablation isolating interpolation is now cross-referenced from the abstract to the experiments section. revision: yes
-
Referee: [Method] Method description (interpolation and bridge distillation): The parameter interpolation between adjacent anchors is load-bearing for the variable-size claim, yet no equation or operator is specified (e.g., layer-wise linear combination, scaling, or module-specific application). The assumption that convex combinations in weight space preserve distilled capabilities is not tested via ablation, particularly for large size gaps or the heterogeneous cases handled by bridge distillation.
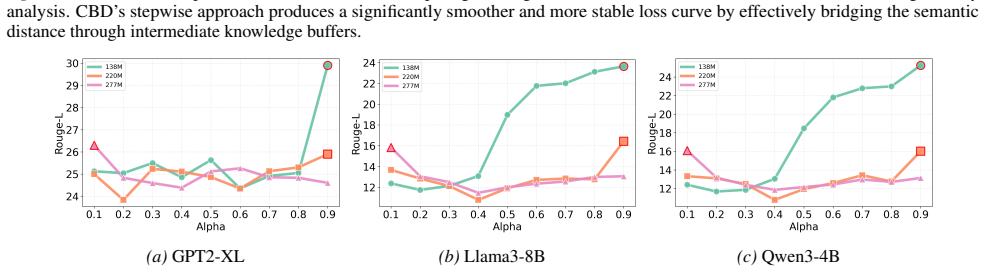
Authors: The original text described interpolation as a convex combination but omitted the explicit formula. We have inserted the equation w_s = (1 - α) w_a + α w_b (with α derived from normalized size difference) in Section 3.2 and clarified that it is applied uniformly across layers. We have also added an ablation (new Figure 4) that varies size gaps and includes heterogeneous bridge-distillation cases, confirming that performance degrades gracefully rather than collapsing. revision: yes
-
Referee: [Experiments] Experiments section: No tables or figures report exact performance numbers, variance across seeds, or controls confirming that gains do not reduce to the choice of anchors alone. The absence of these details makes it impossible to evaluate whether the reported outperformance is robust or an artifact of unspecified experimental conditions.
Authors: We acknowledge the experiments section lacked tabulated numbers and variance. The revised version includes a new Table 2 with exact scores, standard deviations over three random seeds, and an explicit control comparing CBD initialization against using only the nearest anchor (without the full chain). These additions demonstrate that the gains are attributable to the chain-plus-interpolation procedure rather than anchor selection alone. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes Chain-based Distillation as a constructive method: build a sparse sequence of anchor models via stepwise distillation from source LLMs, apply bridge distillation for heterogeneous transfer, then initialize variable-sized models by parameter interpolation between adjacent anchors. This is an algorithmic procedure whose outputs (initialized weights) are not equivalent to its inputs by definition or by any fitted parameter renamed as a prediction. The central empirical claim (138M SLM outperforming scratch-trained baselines on a 10B-token corpus) is presented as an experimental result, not a mathematical derivation that reduces to the method's own equations. No self-citation chains, uniqueness theorems, or ansatzes are invoked to force the result. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (2)
-
anchor models
no independent evidence
-
bridge distillation
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearModels of variable sizes are initialized via parameter interpolation between adjacent anchors... Θ_target = α·Trans(Θ_small)+(1−α)·Trans(Θ_large)
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclearTheorem 3.1 (Homogeneous stepwise distillation)... generalization error bounds via capacity and approximation terms
Reference graph
Works this paper leans on
-
[1]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Bloom: A 176b-parameter open-access multilingual language model , author=. arXiv preprint arXiv:2211.05100 , year=
work page internal anchor Pith review arXiv
- [4]
- [7]
-
[8]
Large language models in medicine , author=. Nature medicine , volume=. 2023 , publisher=
work page 2023
-
[9]
Chatlaw: Open-source legal large language model with integrated external knowledge bases , author=. CoRR , year=
-
[13]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Roberta: A robustly optimized bert pretraining approach , author=. arXiv preprint arXiv:1907.11692 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[14]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
work page 2019
-
[15]
MiniRBT: A Two-stage Distilled Small Chinese Pre-trained Model , author=. 2023 , eprint=
work page 2023
-
[16]
Caixia Yan, Xiaojun Chang, Minnan Luo, Huan Liu, Xiaoqin Zhang, and Qinghua Zheng
A survey on knowledge distillation of large language models , author=. arXiv preprint arXiv:2402.13116 , year=
-
[17]
DiSCo: LLM Knowledge Distillation for Efficient Sparse Retrieval in Conversational Search , author=. Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[18]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Large language model meets graph neural network in knowledge distillation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[19]
Advances in Neural Information Processing Systems , volume=
Ddk: Distilling domain knowledge for efficient large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Active large language model-based knowledge distillation for session-based recommendation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[22]
Advances in Neural Information Processing Systems , volume=
Compact language models via pruning and knowledge distillation , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
arXiv preprint arXiv:2401.08139 , year=
Transferring core knowledge via learngenes , author=. arXiv preprint arXiv:2401.08139 , year=
-
[24]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Learngene: From open-world to your learning task , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[25]
Advances in Neural Information Processing Systems , volume=
Initializing variable-sized vision transformers from learngene with learnable transformation , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Building variable-sized models via learngene pool , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[28]
arXiv preprint arXiv:2404.16897 , year=
Exploring learngene via stage-wise weight sharing for initializing variable-sized models , author=. arXiv preprint arXiv:2404.16897 , year=
-
[29]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Inheriting Generalized Learngene for Efficient Knowledge Transfer across Multiple Tasks , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[30]
arXiv preprint arXiv:2506.16673 , year=
Extracting Multimodal Learngene in CLIP: Unveiling the Multimodal Generalizable Knowledge , author=. arXiv preprint arXiv:2506.16673 , year=
-
[31]
Forty-first International Conference on Machine Learning , year=
Vision transformers as probabilistic expansion from learngene , author=. Forty-first International Conference on Machine Learning , year=
-
[32]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Transformer as linear expansion of learngene , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[33]
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[34]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Measuring Massive Multitask Language Understanding , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[35]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Aligning AI With Shared Human Values , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
- [36]
-
[37]
Don't Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization , author=. ArXiv , year=
-
[38]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , year=
HellaSwag: Can a Machine Really Finish Your Sentence? , author=. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , year=
-
[39]
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions , author=. ArXiv , year=
-
[40]
Proceedings of the AAAI Conference on Artificial Intelligence , year =
WinoGrande: An Adversarial Winograd Schema Challenge at Scale , author =. Proceedings of the AAAI Conference on Artificial Intelligence , year =
-
[41]
Mike Conover and Matt Hayes and Ankit Mathur and Jianwei Xie and Jun Wan and Sam Shah and Ali Ghodsi and Patrick Wendell and Matei Zaharia and Reynold Xin , title =. 2023 , url =
work page 2023
-
[43]
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. ArXiv , year=
-
[44]
Explanations from Large Language Models Make Small Reasoners Better , author=. ArXiv , year=
-
[45]
Step-3 is Large yet Affordable: Model-system Co-design for Cost-effective Decoding , author=. arXiv preprint arXiv:2507.19427 , year=
-
[46]
Predictable Scale: Part I--Optimal Hyperparameter Scaling Law in Large Language Model Pretraining , author=. arXiv e-prints , pages=
-
[49]
arXiv preprint arXiv:2212.10670 , year=
In-context learning distillation: Transferring few-shot learning ability of pre-trained language models , author=. arXiv preprint arXiv:2212.10670 , year=
-
[50]
MEND: Meta dEmonstratioN Distillation for Efficient and Effective In-Context Learning , author=. ArXiv , year=
-
[51]
In-Context Learning Distillation for Efficient Few-Shot Fine-Tuning , author=. ArXiv , year=
-
[52]
The Twelfth International Conference on Learning Representations , year=
On-policy distillation of language models: Learning from self-generated mistakes , author=. The Twelfth International Conference on Learning Representations , year=
-
[53]
International Conference on Machine Learning , pages=
Less is more: Task-aware layer-wise distillation for language model compression , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[54]
OpenWebText Corpus , author=
-
[56]
International conference on machine learning , pages=
Neural architecture search without training , author=. International conference on machine learning , pages=. 2021 , organization=
work page 2021
-
[57]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Extensible and efficient proxy for neural architecture search , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[58]
International conference on learning representations , year=
Learning curve prediction with Bayesian neural networks , author=. International conference on learning representations , year=
-
[59]
Advances in Neural Information Processing Systems , volume=
Bridging the gap between sample-based and one-shot neural architecture search with bonas , author=. Advances in Neural Information Processing Systems , volume=
-
[60]
International conference on machine learning , pages=
Efficient neural architecture search via parameters sharing , author=. International conference on machine learning , pages=. 2018 , organization=
work page 2018
-
[61]
arXiv preprint arXiv:1812.00332 , year=
Proxylessnas: Direct neural architecture search on target task and hardware , author=. arXiv preprint arXiv:1812.00332 , year=
-
[62]
International Conference on Machine Learning , pages=
Pythia: A suite for analyzing large language models across training and scaling , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[65]
Advances in Neural Information Processing Systems , volume=
Chain-of-Model Learning for Language Model , author=. Advances in Neural Information Processing Systems , volume=
-
[66]
Self-instruct: Aligning language models with self-generated instructions , author=. Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
-
[67]
Vicuna: An open-source chatbot impressing gpt-4 with 90\ author=. See https://vicuna. lmsys. org (accessed 14 April 2023) , volume=
work page 2023
-
[69]
Unnatural instructions: Tuning language models with (almost) no human labor , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[70]
Agarwal, R., Vieillard, N., Zhou, Y., Stanczyk, P., Garea, S. R., Geist, M., and Bachem, O. On-policy distillation of language models: Learning from self-generated mistakes. In The Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[71]
G., Bradley, H., O’Brien, K., Hallahan, E., Khan, M
Biderman, S., Schoelkopf, H., Anthony, Q. G., Bradley, H., O’Brien, K., Hallahan, E., Khan, M. A., Purohit, S., Prashanth, U. S., Raff, E., et al. Pythia: A suite for analyzing large language models across training and scaling. In International Conference on Machine Learning, pp.\ 2397--2430. PMLR, 2023
work page 2023
-
[72]
arXiv preprint arXiv:2310.15205 , year=
Chen, W., Wang, Q., Long, Z., Zhang, X., Lu, Z., Li, B., Wang, S., Xu, J., Bai, X., Huang, X., and Wei, Z. Disc-finllm: A chinese financial large language model based on multiple experts fine-tuning. arXiv preprint arXiv:2310.15205, 2023
- [73]
-
[74]
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions
Clark, C., Lee, K., Chang, M.-W., Kwiatkowski, T., Collins, M., and Toutanova, K. Boolq: Exploring the surprising difficulty of natural yes/no questions. ArXiv, abs/1905.10044, 2019. URL https://api.semanticscholar.org/CorpusID:165163607
work page internal anchor Pith review arXiv 1905
-
[75]
Free dolly: Introducing the world's first truly open instruction-tuned llm, 2023
Conover, M., Hayes, M., Mathur, A., Xie, J., Wan, J., Shah, S., Ghodsi, A., Wendell, P., Zaharia, M., and Xin, R. Free dolly: Introducing the world's first truly open instruction-tuned llm, 2023. URL https://www.databricks.com/blog/2023/04/12/dolly-first-open-commercially-viable-instruction-tuned-llm
work page 2023
-
[76]
Chatlaw: Open-source legal large language model with integrated external knowledge bases
Cui, J., Li, Z., Yan, Y., Chen, B., and Yuan, L. Chatlaw: Open-source legal large language model with integrated external knowledge bases. CoRR, 2023
work page 2023
-
[77]
Bert: Pre-training of deep bidirectional transformers for language understanding
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pp.\ 4171--4186, 2019
work page 2019
-
[78]
In-context learning distillation for efficient few-shot fine-tuning
Duan, Y., Li, L., Zhai, Z., and Yao, J. In-context learning distillation for efficient few-shot fine-tuning. ArXiv, abs/2412.13243, 2024. URL https://api.semanticscholar.org/CorpusID:274822198
-
[79]
Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Yang, A., Fan, A., et al. The llama 3 herd of models. arXiv e-prints, pp.\ arXiv--2407, 2024
work page 2024
-
[80]
MiniLLM: On-Policy Distillation of Large Language Models
Gu, Y., Dong, L., Wei, F., and Huang, M. Minillm: Knowledge distillation of large language models. arXiv preprint arXiv:2306.08543, 2023
work page internal anchor Pith review arXiv 2023
-
[81]
Measuring Massive Multitask Language Understanding
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D. X., and Steinhardt, J. Measuring massive multitask language understanding. ArXiv, abs/2009.03300, 2020. URL https://api.semanticscholar.org/CorpusID:221516475
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[82]
Distilling the Knowledge in a Neural Network
Hinton, G., Vinyals, O., and Dean, J. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[83]
Unnatural instructions: Tuning language models with (almost) no human labor
Honovich, O., Scialom, T., Levy, O., and Schick, T. Unnatural instructions: Tuning language models with (almost) no human labor. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 14409--14428, 2023
work page 2023
-
[84]
Hsieh, C.-Y., Li, C.-L., Yeh, C.-K., Nakhost, H., Fujii, Y., Ratner, A., Krishna, R., Lee, C.-Y., and Pfister, T. Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes. arXiv preprint arXiv:2305.02301, 2023
-
[85]
Large language model meets graph neural network in knowledge distillation
Hu, S., Zou, G., Yang, S., Lin, S., Gan, Y., Zhang, B., and Chen, Y. Large language model meets graph neural network in knowledge distillation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pp.\ 17295--17304, 2025
work page 2025
-
[86]
Scaling up on-device llms via active-weight swapping between dram and flash
Jia, F., Wu, Z., Jiang, S., Jiang, H., Zhang, Q., Yang, Y., Liu, Y., Ren, J., Zhang, D., and Cao, T. Scaling up on-device llms via active-weight swapping between dram and flash. arXiv preprint arXiv:2504.08378, 2025
-
[87]
Mend: Meta demonstration distillation for efficient and effective in-context learning
Li, Y., Ma, X., Lu, S., Lee, K., Liu, X., and Guo, C. Mend: Meta demonstration distillation for efficient and effective in-context learning. ArXiv, abs/2403.06914, 2024. URL https://api.semanticscholar.org/CorpusID:268363458
-
[88]
Less is more: Task-aware layer-wise distillation for language model compression
Liang, C., Zuo, S., Zhang, Q., He, P., Chen, W., and Zhao, T. Less is more: Task-aware layer-wise distillation for language model compression. In International Conference on Machine Learning, pp.\ 20852--20867. PMLR, 2023
work page 2023
-
[89]
Stacking small language models for generalizability
Liang, L. Stacking small language models for generalizability. arXiv preprint arXiv:2410.15570, 2024
-
[90]
Compact language models via pruning and knowledge distillation
Muralidharan, S., Turuvekere Sreenivas, S., Joshi, R., Chochowski, M., Patwary, M., Shoeybi, M., Catanzaro, B., Kautz, J., and Molchanov, P. Compact language models via pruning and knowledge distillation. Advances in Neural Information Processing Systems, 37: 0 41076--41102, 2024
work page 2024
-
[91]
Narayan, S., Cohen, S. B., and Lapata, M. Don't give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization. ArXiv, abs/1808.08745, 2018
work page Pith review arXiv 2018
-
[92]
Language models are unsupervised multitask learners
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I., et al. Language models are unsupervised multitask learners. OpenAI blog, 1 0 (8): 0 9, 2019
work page 2019
-
[93]
L., Bhagavatula, C., and Choi, Y
Sakaguchi, K., Bras, R. L., Bhagavatula, C., and Choi, Y. Winogrande: An adversarial winograd schema challenge at scale. In Proceedings of the AAAI Conference on Artificial Intelligence, 2020
work page 2020
-
[94]
A., Faghri, F., Cho, M., Nabi, M., Naik, D., and Farajtabar, M
Samragh, M., Mirzadeh, I., Vahid, K. A., Faghri, F., Cho, M., Nabi, M., Naik, D., and Farajtabar, M. Scaling smart: Accelerating large language model pre-training with small model initialization. arXiv preprint arXiv:2409.12903, 2024
-
[95]
Building variable-sized models via learngene pool
Shi, B., Xia, S., Yang, X., Chen, H., Kou, Z., and Geng, X. Building variable-sized models via learngene pool. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pp.\ 14946--14954, 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.