Recognition: no theorem link
Bridging the Programming Language Gap: Constructing a Multilingual Shared Semantic Space through AST Unification and Graph Matching
Pith reviewed 2026-05-11 03:13 UTC · model grok-4.3
The pith
By unifying AST node labels across languages and encoding paired graphs with a Graph Matching Network, functionally equivalent code is placed close together in a shared semantic space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
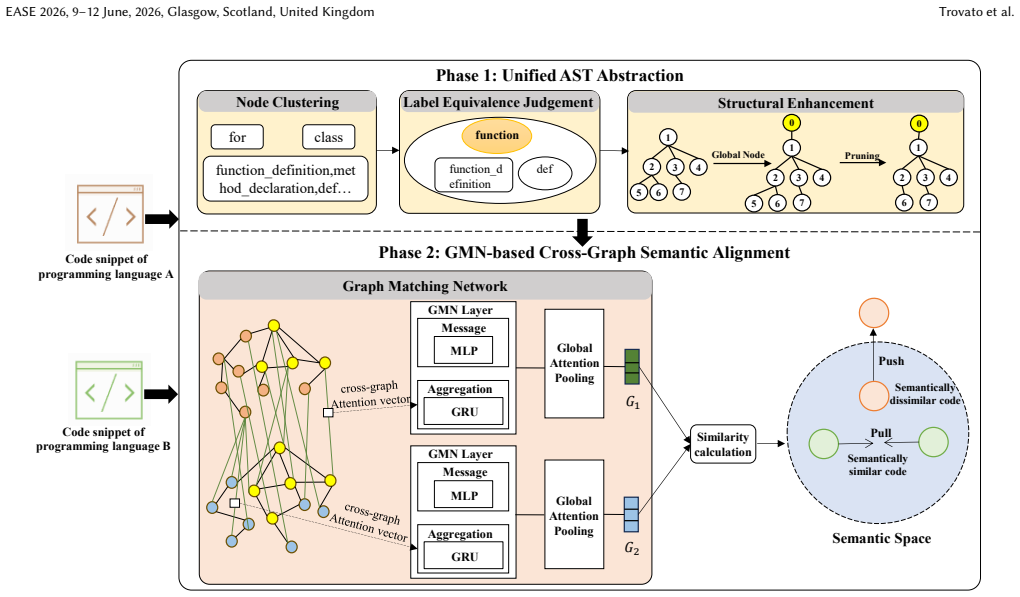
We first map the Abstract Syntax Tree node labels of the code snippets written in different programming languages into a unified label set, thus compressing high-dimensional language-specific tokens into a common embedding space. Then, we employ a Graph Matching Network to encode the paired AST graphs into semantic vectors that capture functional equivalence between programming languages in a unified code vector space. In such a way, we can eliminate the differences in syntax between different programming languages and achieve large gains on downstream tasks.
What carries the argument
Graph Matching Network operating on AST graphs whose node labels have been mapped to a single unified vocabulary, producing vectors that encode functional rather than syntactic similarity.
If this is right
- Cross-language clone detection reaches precision 99.94 percent, recall 99.92 percent, and F1 99.93 percent.
- Cross-language code retrieval lifts average MRR from 0.4909 to 0.5547, a 13 percent relative gain.
- Correct code snippets are ranked higher across languages because syntax differences no longer separate their vectors.
- The same pipeline applies to any pair of languages once their AST labels are unified.
Where Pith is reading between the lines
- The same vectors could be used for additional cross-language tasks such as automated refactoring or bug-pattern search without retraining from scratch.
- If the unification step proves sufficient on its own, simpler non-graph models might achieve comparable results at lower cost.
- Extending the label map to more languages would test whether the shared space remains coherent as the number of languages grows.
Load-bearing premise
Training on paired examples after label unification will make the model detect genuine functional equivalence instead of surface-level structural matches or patterns that happen to exist in the training data.
What would settle it
Run the trained model on a fresh collection of code pairs that perform identical computations but use dissimilar control flow or data structures never seen during training, then check whether similarity scores still align with the known functional matches.
Figures



read the original abstract
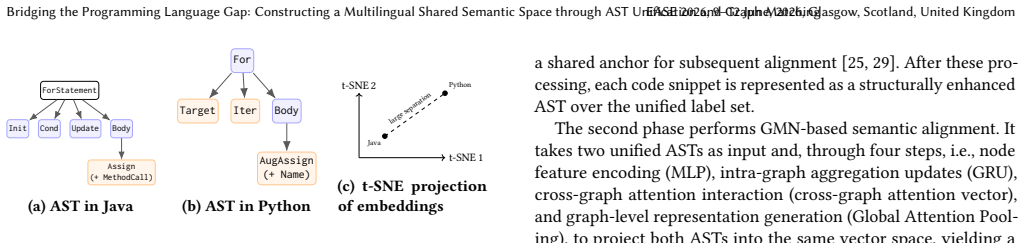
The lexical and syntactic disparities among different programming languages (e.g., Java and Python) pose significant challenges for multi-language software engineering tasks such as cross-language code clone detection and code retrieval, since queries or code snippets written in one programming language often fail to match equivalent artifacts in another. To bridge this gap between different programming languages, we proposed a novel approach to construct a multi-language shared semantic space, in which functionally equivalent source code written in different programming languages are close to each other. In this approach, we first map the Abstract Syntax Tree (AST) node labels of the code snippets written in different programming languages into a unified label set, thus compressing high-dimensional language-specific tokens into a common embedding space. Then, we employ a Graph Matching Network (GMN) to encode the paired AST graphs into "semantic vectors" that capture functional equivalence between programming languages in a unified code vector space. In such a way, we can eliminate the differences in syntax between different programming languages. To validate the effectiveness of this approach, we apply it to two downstream tasks, including cross-language clone detection and cross-language code retrieval. Experiments demonstrate that our approach substantially outperforms the state-of-the-art baselines in cross-language clone detection, improving Precision from 95.62% to 99.94%, Recall from 97.72% to 99.92%, and F1 score from 96.94% to 99.93%. In terms of cross-language code retrieval, our approach raises the average Mean Reciprocal Rank (MRR) from 0.4909 to 0.5547, showing an absolute gain of 0.0638 (13% relative improvement), which demonstrates its superior ability to rank correct code snippets high across multiple programming languages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes unifying AST node labels across programming languages into a shared set and training a Graph Matching Network (GMN) on paired AST graphs to embed functionally equivalent code into a common semantic vector space. It evaluates the approach on cross-language clone detection and code retrieval, claiming large gains over baselines (e.g., clone detection Precision rising from 95.62% to 99.94%, MRR from 0.4909 to 0.5547).
Significance. If the method reliably encodes functional equivalence rather than structural similarity, the work would advance multilingual software engineering by enabling more robust cross-language analysis tools. The combination of label unification and GMN is a reasonable technical choice, but the absence of supporting experimental controls limits the strength of the contribution.
major comments (2)
- [§5 (Experiments)] §5 (Experiments): No details are provided on construction of training/test pairs, verification of functional equivalence independent of the model, negative sampling strategy, or inclusion of hard negatives (structurally similar but semantically distinct examples). This directly undermines the central claim that the GMN learns a semantic space, as the reported gains could arise from exploiting isomorphism in the unified ASTs.
- [§5 (Experiments) and Abstract] §5 (Experiments) and Abstract: The large metric improvements (e.g., F1 from 96.94% to 99.93%) are presented without error bars, statistical significance tests, or ablation studies isolating AST unification from the GMN component. These omissions are load-bearing because they prevent assessment of whether the gains are robust or attributable to the proposed unification+GMN pipeline.
minor comments (2)
- [Method] Method section: An illustrative example of label unification (e.g., mapping Java 'MethodDeclaration' and Python 'FunctionDef' to a common token) would clarify the compression step.
- [Related Work] Related work: Additional citations to prior AST embedding and cross-language clone detection papers would better situate the contribution.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. The comments highlight important aspects of experimental rigor that we will address in the revision. We respond to each major comment below.
read point-by-point responses
-
Referee: [§5 (Experiments)] §5 (Experiments): No details are provided on construction of training/test pairs, verification of functional equivalence independent of the model, negative sampling strategy, or inclusion of hard negatives (structurally similar but semantically distinct examples). This directly undermines the central claim that the GMN learns a semantic space, as the reported gains could arise from exploiting isomorphism in the unified ASTs.
Authors: We agree that the current manuscript omits key experimental details necessary to fully support the semantic interpretation of the learned space. In the revised version, we will add a new subsection in §5 that explicitly describes: (i) the source and construction of training/test pairs from established cross-language datasets, (ii) independent verification of functional equivalence via test-case execution and manual sampling, (iii) the negative sampling procedure, and (iv) explicit inclusion of hard negatives chosen by high structural similarity (via tree-edit distance on unified ASTs) yet differing functionality. These additions will directly address the concern that gains may stem solely from isomorphism and will clarify how the GMN component contributes to semantic alignment beyond structural matching. revision: yes
-
Referee: [§5 (Experiments) and Abstract] §5 (Experiments) and Abstract: The large metric improvements (e.g., F1 from 96.94% to 99.93%) are presented without error bars, statistical significance tests, or ablation studies isolating AST unification from the GMN component. These omissions are load-bearing because they prevent assessment of whether the gains are robust or attributable to the proposed unification+GMN pipeline.
Authors: We acknowledge that the absence of error bars, significance testing, and component-wise ablations limits the ability to evaluate robustness and attribution. In the revision we will: (1) report all metrics with standard deviations across five independent runs using different random seeds, (2) include paired statistical significance tests (e.g., t-tests) comparing our method against baselines, and (3) add ablation experiments that isolate the effect of AST label unification alone, the GMN architecture alone, and their combination. These changes will allow readers to assess both the statistical reliability of the reported gains and the specific contribution of each element in the proposed pipeline. revision: yes
Circularity Check
No circularity: empirical method with independent evaluation
full rationale
The paper proposes AST label unification followed by training a Graph Matching Network on paired examples to produce semantic vectors, then reports empirical gains on clone detection (Precision/Recall/F1) and retrieval (MRR) tasks versus baselines. No equations, uniqueness theorems, or first-principles derivations are present that could reduce to fitted inputs or self-citations by construction. Performance numbers are obtained from standard train/test splits on downstream benchmarks and are not algebraically forced by any internal parameter. The work is self-contained as a neural architecture plus evaluation; no load-bearing self-citation chains or ansatz smuggling occur.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption AST node labels from different languages can be mapped to a single unified label set while preserving functional semantics
- domain assumption A Graph Matching Network can encode paired AST graphs into vectors that reflect functional equivalence across languages
Reference graph
Works this paper leans on
-
[1]
AtCoder Inc. 2025. AtCoder. https://atcoder.jp/ Accessed: 2025-09-10. Bridging the Programming Language Gap: Constructing a Multilingual Shared Semantic Space through AST Unification and Graph Matching EASE 2026, 9–12 June, 2026, Glasgow, Scotland, United Kingdom
work page 2025
-
[2]
Hongkai Chen, Zixin Luo, Jiahui Zhang, Lei Zhou, Xuyang Bai, Zeyu Hu, Chiew- Lan Tai, and Long Quan. 2021. Learning to match features with seeded graph matching network. InProceedings of the IEEE/CVF international conference on computer vision. 6301–6310
work page 2021
-
[3]
Xiao Cheng, Zhiming Peng, Lingxiao Jiang, Hao Zhong, Haibo Yu, and Jianjun Zhao. 2017. Clcminer: detecting cross-language clones without intermediates. IEICE TRANSACTIONS on Information and Systems100, 2 (2017), 273–284
work page 2017
-
[4]
Yuhao Cheng, Xiaoguang Zhu, Jiuchao Qian, Fei Wen, and Peilin Liu. 2022. Cross- modal graph matching network for image-text retrieval.ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM)18, 4 (2022), 1–23
work page 2022
- [5]
-
[6]
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, et al . 2020. CodeBERT: A Pre- Trained Model for Programming and Natural Languages. InFindings of the Asso- ciation for Computational Linguistics: EMNLP 2020. 1536–1547
work page 2020
-
[7]
Google. 2025. Google Code Jam. https://codingcompetitions.withgoogle.com/ codejam Accessed: 2025-09-10
work page 2025
-
[8]
Daya Guo, Shuai Lu, Nan Duan, Yanlin Wang, Ming Zhou, and Jian Yin. 2022. UniXcoder: Unified Cross-Modal Pre-training for Code Representation. InPro- ceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 7212–7225
work page 2022
-
[9]
Daya Guo, Shuo Ren, Shuai Lu, Zhangyin Feng, Duyu Tang, Shujie LIU, Long Zhou, Nan Duan, Alexey Svyatkovskiy, Shengyu Fu, et al. [n. d.]. GraphCode- BERT: Pre-training Code Representations with Data Flow. InInternational Con- ference on Learning Representations
-
[10]
Chi Han, Mingxuan Wang, Heng Ji, and Lei Li. 2021. Learning Shared Semantic Space for Speech-to-Text Translation. InFindings of the Association for Computa- tional Linguistics: ACL-IJCNLP 2021. 2214–2225
work page 2021
-
[11]
David Hovemeyer, Arto Hellas, Andrew Petersen, and Jaime Spacco. 2016. Control-flow-only abstract syntax trees for analyzing students’ programming progress. InProceedings of the 2016 ACM Conference on International Computing Education Research. 63–72
work page 2016
-
[12]
Guillaume Lample, Alexis Conneau, Marc’Aurelio Ranzato, Ludovic Denoyer, and Hervé Jégou. 2018. Word translation without parallel data. InInternational conference on learning representations
work page 2018
-
[13]
Maggie Lei, Hao Li, Ji Li, Namrata Aundhkar, and Dae-Kyoo Kim. 2022. Deep learning application on code clone detection: A review of current knowledge. Journal of Systems and Software184 (2022), 111141
work page 2022
-
[14]
Yujia Li, Chenjie Gu, Thomas Dullien, Oriol Vinyals, and Pushmeet Kohli. 2019. Graph matching networks for learning the similarity of graph structured objects. InInternational conference on machine learning. PMLR, 3835–3845
work page 2019
-
[15]
Xiang Ling, Lingfei Wu, Saizhuo Wang, Tengfei Ma, Fangli Xu, Alex X Liu, Chunming Wu, and Shouling Ji. 2021. Multilevel graph matching networks for deep graph similarity learning.IEEE Transactions on Neural Networks and Learning Systems34, 2 (2021), 799–813
work page 2021
-
[16]
George Mathew and Kathryn T Stolee. 2021. Cross-language code search using static and dynamic analyses. InProceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 205–217
work page 2021
-
[17]
Sunil Kumar Maurya, Xin Liu, and Tsuyoshi Murata. 2022. Simplifying approach to node classification in graph neural networks.Journal of Computational Science 62 (2022), 101695
work page 2022
-
[18]
Nikita Mehrotra, Akash Sharma, Anmol Jindal, and Rahul Purandare. 2023. Im- proving cross-language code clone detection via code representation learning and graph neural networks.IEEE Transactions on Software Engineering49, 11 (2023), 4846–4868
work page 2023
-
[19]
Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. Efficient estimation of word representations in vector space.arXiv preprint arXiv:1301.3781 (2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[20]
Gunter Mussbacher, Benoit Combemale, Jörg Kienzle, Lola Burgueño, Antonio Garcia-Dominguez, Jean-Marc Jézéquel, Gwendal Jouneaux, Djamel-Eddine Khel- ladi, Sébastien Mosser, Corinne Pulgar, et al. 2024. Polyglot software development: Wait, what?Ieee software41, 4 (2024), 124–133
work page 2024
-
[21]
Daniel Perez and Shigeru Chiba. 2019. Cross-language clone detection by learning over abstract syntax trees. In2019 IEEE/ACM 16th International Conference on Mining Software Repositories (MSR). IEEE, 518–528
work page 2019
-
[22]
Mohammed Rahaman and Julia Ive. 2024. Source Code is a Graph, Not a Sequence: A Cross-Lingual Perspective on Code Clone Detection. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 4: Student Research Workshop). 168–199
work page 2024
-
[23]
Franco Scarselli, Marco Gori, Ah Chung Tsoi, Markus Hagenbuchner, and Gabriele Monfardini. 2008. The graph neural network model.IEEE transactions on neural networks20, 1 (2008), 61–80
work page 2008
- [24]
-
[25]
Weisong Sun, Chunrong Fang, Yun Miao, Yudu You, Mengzhe Yuan, Yuchen Chen, Quanjun Zhang, An Guo, Xiang Chen, Yang Liu, et al . 2023. Abstract Syntax Tree for Programming Language Understanding and Representation: How Far Are We?CoRR(2023)
work page 2023
-
[26]
Zeina Swilam, Abeer Hamdy, and Andreas Pester. 2023. Cross-language code clone detection using abstract syntax tree and graph neural network. In2023 International Conference on Computer and Applications (ICCA). IEEE, 1–5
work page 2023
-
[27]
Chenning Tao, Qi Zhan, Xing Hu, and Xin Xia. 2022. C4: Contrastive cross- language code clone detection. InProceedings of the 30th IEEE/ACM international conference on program comprehension. 413–424
work page 2022
-
[28]
Laurens Van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-SNE. Journal of machine learning research9, 11 (2008)
work page 2008
-
[29]
Kesu Wang, Meng Yan, He Zhang, and Haibo Hu. 2022. Unified abstract syntax tree representation learning for cross-language program classification. InProceed- ings of the 30th IEEE/ACM International Conference on Program Comprehension. 390–400
work page 2022
-
[30]
Wenhan Wang, Ge Li, Bo Ma, Xin Xia, and Zhi Jin. 2020. Detecting code clones with graph neural network and flow-augmented abstract syntax tree. In2020 IEEE 27th International Conference on Software Analysis, Evolution and Reengineering (SANER). IEEE, 261–271
work page 2020
- [31]
-
[32]
Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang, and S Yu Philip. 2020. A comprehensive survey on graph neural networks.IEEE transactions on neural networks and learning systems32, 1 (2020), 4–24
work page 2020
-
[33]
Haoran Yang, Yu Nong, Shaowei Wang, and Haipeng Cai. 2024. Multi-language software development: Issues, challenges, and solutions.IEEE Transactions on Software Engineering50, 3 (2024), 512–533
work page 2024
-
[34]
Hao Yu, Wing Lam, Long Chen, Ge Li, Tao Xie, and Qianxiang Wang. 2019. Neural detection of semantic code clones via tree-based convolution. In2019 IEEE/ACM 27th International Conference on Program Comprehension (ICPC). IEEE, 70–80
work page 2019
-
[35]
Jian Zhang, Xu Wang, Hongyu Zhang, Hailong Sun, Kaixuan Wang, and Xudong Liu. 2019. A novel neural source code representation based on abstract syntax tree. In2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE). IEEE, 783–794
work page 2019
-
[36]
Linghao Zhang, Senlin Luo, Limin Pan, Zhouting Wu, and Kun Gong. 2024. FSD- CLCD: Functional semantic distillation graph learning for cross-language code clone detection.Engineering Applications of Artificial Intelligence133 (2024), 108199
work page 2024
- [37]
-
[38]
Zongxing Zhao, Zhaowei Liu, Yingjie Wang, Dong Yang, and Weishuai Che. 2024. RA-HGNN: Attribute completion of heterogeneous graph neural networks based on residual attention mechanism.Expert Systems with Applications243 (2024), 122945
work page 2024
- [39]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.