Recognition: 2 theorem links
· Lean TheoremScalable Distributed Stochastic Optimization via Bidirectional Compression: Beyond Pessimistic Limits
Pith reviewed 2026-05-11 02:48 UTC · model grok-4.3
The pith
Bidirectional compression enables new distributed stochastic methods to scale time complexity with worker count under a structural assumption.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors propose Inkheart SGD and M4 as compressed methods for stochastic optimization. Using bidirectional compression under the additional structural assumption, the methods attain time complexities that improve with n in both the dimension-dependent communication term and the variance term, surpassing the pessimistic lower bound that holds without the assumption and that non-distributed or vanilla synchronous SGD can match.
What carries the argument
Bidirectional compression applied simultaneously in both worker-to-server and server-to-worker directions within Inkheart SGD and M4, which reduces overall communication time while supporting the improved convergence rates under the structural assumption.
If this is right
- Both the communication term proportional to d and the stochastic variance term can now improve simultaneously as n grows in homogeneous and heterogeneous settings.
- The new methods deliver better practical scaling than prior compression approaches or non-distributed baselines.
- The improved bounds apply directly to centralized, distributed, and federated learning with stochastic gradients.
- Increasing the number of workers yields concrete reductions in total runtime beyond what the pessimistic limits permitted.
Where Pith is reading between the lines
- Problems that naturally satisfy the structural assumption may see immediate gains from deploying these bidirectional methods at scale.
- Similar bidirectional compression ideas could be adapted to other distributed algorithms currently limited by analogous lower bounds.
- Empirical verification of the assumption on real datasets would clarify how broadly the scaling benefits apply.
- Future algorithm design may benefit from explicitly identifying and exploiting such structural properties to bypass theoretical barriers.
Load-bearing premise
An additional structural assumption on the problem or gradients is required to achieve the improved scaling, since the lower bound otherwise blocks better complexities.
What would settle it
An experiment on a problem that satisfies the structural assumption where the measured wall-clock time to reach a target accuracy fails to decrease with larger n in the manner predicted by the new bounds.
Figures





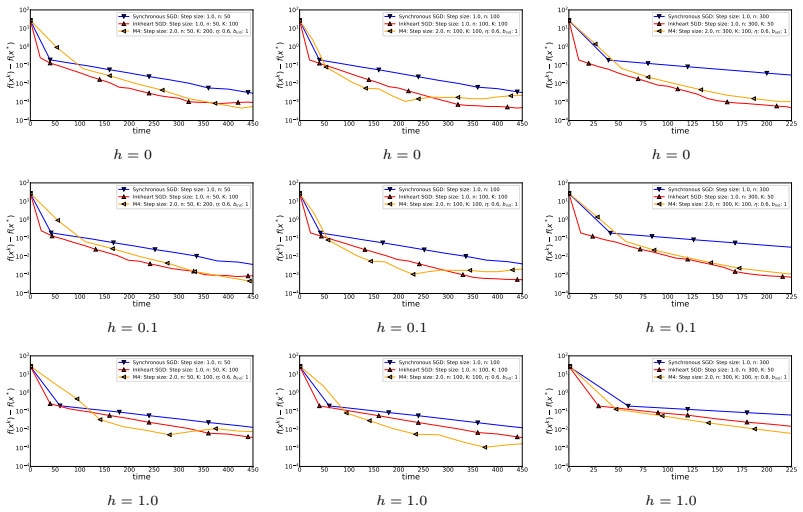
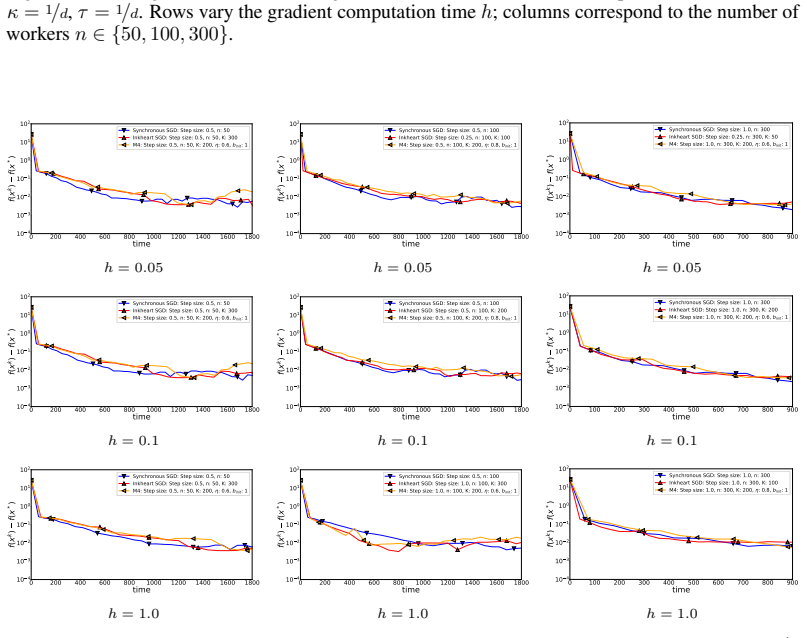






read the original abstract
In centralized, distributed, and federated learning with stochastic gradients and $n$ workers, it was recently shown that it is infeasible to find an $\varepsilon$-stationary point faster than $\tilde{\Omega}\left(\min\left\{\frac{d \kappa L \Delta}{\varepsilon} + \frac{h L \Delta}{\varepsilon} + \frac{h \sigma^2 L \Delta}{n \varepsilon^2},\; \frac{h \sigma^2 L \Delta}{\varepsilon^2} + \frac{h L \Delta}{\varepsilon}\right\}\right)$ seconds in both homogeneous and heterogeneous settings under standard assumptions: $L$-smoothness, $\sigma^2$-bounded unbiased stochastic gradients, and lower boundedness of the function, i.e., $f(x) \geq f^*$ for all $x \in \mathbb{R}^d$, where $\Delta = f(x^0) - f^*$, $h$ is the computation time, $\kappa$ is the communication speed between the workers and the server, and $d$ is the dimension of the iterates and gradients. This result is pessimistic since it does not allow a complexity in which both $\frac{d \kappa L \Delta}{\varepsilon}$ and $\frac{h \sigma^2 L \Delta}{\varepsilon^2}$ improve with $n$, even when using random sparsification techniques; moreover, this lower bound can be matched by either non-distributed SGD or vanilla Synchronous SGD, which reduces the impact of recent progress in the design of compression-based methods. In this work, we challenge this limitation and propose new compressed methods, Inkheart SGD and M4, and show that under an additional structural assumption, which is necessary due to the lower bound and which does not restrict the class of considered problems, we achieve new state-of-the-art time complexities that break this pessimistic barrier and allow scaling with the number of workers $n$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper shows that a recent lower bound establishes pessimistic time complexities for distributed stochastic optimization (homogeneous or heterogeneous) under standard L-smoothness, unbiased sigma^2-bounded stochastic gradients, and f >= f* assumptions; the bound cannot be improved in both the d kappa L Delta/epsilon and h sigma^2 L Delta/epsilon^2 terms simultaneously even with compression. It introduces two bidirectional-compression methods (Inkheart SGD and M4) that, under one additional structural assumption claimed to be necessary to evade the lower bound yet non-restrictive for the considered problem class, attain new state-of-the-art time complexities that scale with the number of workers n.
Significance. If the structural assumption is shown to hold for every problem obeying the standard assumptions and the complexity derivations are correct, the result would remove a fundamental barrier, allowing compressed distributed methods to provably outperform both non-distributed SGD and vanilla synchronous SGD in wall-clock time; this would be a notable advance for scalable federated and distributed learning.
major comments (2)
- [Abstract; Section introducing the structural assumption and Theorems for Inkheart SGD / M4] The central claim that the additional structural assumption 'does not restrict the class of considered problems' is load-bearing for both the new complexities and the assertion that the lower bound is evaded without loss of generality. The manuscript must explicitly state the assumption (presumably in the section introducing Inkheart SGD and M4) and prove that every L-smooth function with unbiased sigma^2-bounded gradients satisfies it; without this, the claimed n-scaling in both the communication and variance terms does not apply to the full class.
- [Lower-bound discussion and main complexity theorems] The lower-bound matching argument and the derivation of the improved complexities must be checked for where the structural assumption is invoked; if it implicitly constrains gradient alignment, heterogeneity, or noise structure beyond the standard assumptions, then the statement that the bound is 'necessary due to the lower bound' while remaining non-restrictive is internally inconsistent.
minor comments (1)
- [Notation and abstract] Clarify the precise definitions of h (computation time) and kappa (communication speed) when they first appear and ensure they are used consistently in all complexity expressions.
Simulated Author's Rebuttal
Thank you for your thorough review and constructive comments on our paper. We are pleased that you recognize the potential significance of our results if the structural assumption holds universally. We will revise the manuscript to address your concerns by explicitly stating the assumption and providing the necessary proof. Below, we respond to each major comment.
read point-by-point responses
-
Referee: The central claim that the additional structural assumption 'does not restrict the class of considered problems' is load-bearing for both the new complexities and the assertion that the lower bound is evaded without loss of generality. The manuscript must explicitly state the assumption (presumably in the section introducing Inkheart SGD and M4) and prove that every L-smooth function with unbiased sigma^2-bounded gradients satisfies it; without this, the claimed n-scaling in both the communication and variance terms does not apply to the full class.
Authors: We agree that the assumption needs to be explicitly stated and that a proof is required. In the revised version, we will explicitly state the structural assumption in the section introducing Inkheart SGD and M4. We will also add a proof showing that every function satisfying the standard L-smoothness, unbiased sigma^2-bounded stochastic gradients, and f >= f* assumptions satisfies this structural assumption. This ensures that the improved complexities with n-scaling apply to the full class of problems. revision: yes
-
Referee: The lower-bound matching argument and the derivation of the improved complexities must be checked for where the structural assumption is invoked; if it implicitly constrains gradient alignment, heterogeneity, or noise structure beyond the standard assumptions, then the statement that the bound is 'necessary due to the lower bound' while remaining non-restrictive is internally inconsistent.
Authors: We have verified the derivations. The structural assumption is invoked in the complexity analysis to achieve the improved rates but does not impose any additional constraints on gradient alignment, heterogeneity, or noise beyond the standard assumptions. The lower bound applies when the assumption is not used, but since it holds for all problems under standard assumptions, there is no inconsistency. We will add clarifications in the relevant sections to show explicitly where the assumption is used. revision: yes
Circularity Check
No significant circularity; derivation relies on independent added assumption
full rationale
The paper's central advance is new time complexities for Inkheart SGD and M4 that scale with n, obtained only after introducing an extra structural assumption. This assumption is explicitly positioned as independent of the target result, required solely to evade the cited lower bound, and asserted not to narrow the standard class of L-smooth, unbiased-gradient problems. No equation in the abstract or described chain redefines the assumption in terms of the claimed complexities, fits parameters to the output, or reduces the new bounds to a self-citation or prior ansatz by the same authors. The derivation therefore remains self-contained once the assumption is granted; any question of whether the assumption truly imposes no restriction is a matter of correctness or completeness, not circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Additional structural assumption necessary due to the lower bound and which does not restrict the class of considered problems
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearAssumption 1.6 (Functional(L_A,L_B)Inequality) ... Proposition 1.7: If Assumption 1.1 holds, then Assumption 1.6 is satisfied with L_A=L and L_B=0. If Assumption 1.6 holds, then f is L-smooth with L=√(L_A²+L_B²).
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclearnew state-of-the-art time complexities ... max(h,τ,κ,dκ√n,...) L_max Δ/ε + dκ L_A Δ/ε
Reference graph
Works this paper leans on
-
[1]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[2]
Decentralized Stochastic Optimization and Gossip Algorithms with Compressed Communication , year =
Anastasia Koloskova and Sebastian U Stich and Martin Jaggi , booktitle =. Decentralized Stochastic Optimization and Gossip Algorithms with Compressed Communication , year =
-
[3]
Language Models are Few-Shot Learners , url =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winte...
-
[4]
Cong Fang and Chris Junchi Li and Zhouchen Lin and Tong Zhang , booktitle =
-
[5]
The 34th International Conference on Machine Learning , year =
Nguyen, Lam and Liu, Jie and Scheinberg, Katya and Tak. The 34th International Conference on Machine Learning , year =
-
[6]
arXiv preprint arXiv:2106.05203 , title =
Peter Richt\'. arXiv preprint arXiv:2106.05203 , title =
-
[8]
International Conference on Machine Learning , title =
Zhize Li and Dmitry Kovalev and Xun Qian and Peter Richt\'. International Conference on Machine Learning , title =
-
[9]
Distributed learning with compressed gradients , year =
Sarit Khirirat and Hamid Reza Feyzmahdavian and Mikael Johansson , journal =. Distributed learning with compressed gradients , year =
-
[10]
The convergence of sparsified gradient methods , booktitle =
Alistarh, Dan and Hoefler, Torsten and Johansson, Mikael and Khirirat, Sarit and Konstantinov, Nikola and Renggli, C\'. The convergence of sparsified gradient methods , booktitle =
-
[11]
Fifteenth Annual Conference of the International Speech Communication Association , year =
Seide, Frank and Fu, Hao and Droppo, Jasha and Li, Gang and Yu, Dong , title =. Fifteenth Annual Conference of the International Speech Communication Association , year =
-
[12]
Thijs Vogels and Sai Praneeth Karimireddy and Martin Jaggi , booktitle =. Power
-
[13]
38th International Conference on Machine Learning , title =
Eduard Gorbunov and Konstantin Burlachenko and Zhize Li and Peter Richt\'. 38th International Conference on Machine Learning , title =
-
[14]
34th Conference on Neural Information Processing Systems (NeurIPS 2020) , title =
Gorbunov, Eduard and Kovalev, Dmitry and Makarenko, Dmitry and Richt\'. 34th Conference on Neural Information Processing Systems (NeurIPS 2020) , title =
work page 2020
-
[15]
OPT2020: 12th Annual Workshop on Optimization for Machine Learning (NeurIPS 2020 Workshop) , title =
Xun Qian and Hanze Dong and Peter Richt\'. OPT2020: 12th Annual Workshop on Optimization for Machine Learning (NeurIPS 2020 Workshop) , title =
work page 2020
-
[16]
Tang, Hanlin and Yu, Chen and Lian, Xiangru and Zhang, Tong and Liu, Ji , booktitle =. DoubleSqueeze: Parallel Stochastic Gradient Descent with Double-pass Error-Compensated Compression , year =
-
[17]
Proceedings of the 35th International Conference on Machine Learning , year =
Wu, Jiaxiang and Huang, Weidong and Huang, Junzhou and Zhang, Tong , title =. Proceedings of the 35th International Conference on Machine Learning , year =
-
[18]
Constantin Philippenko and Aymeric Dieuleveut , journal =. Bidirectional compression in heterogeneous settings for distributed or federated learning with partial participation: tight convergence guarantees , year =
-
[19]
arXiv preprint arXiv:1901.09269 , title =
Mishchenko, Konstantin and Gorbunov, Eduard and Tak. arXiv preprint arXiv:1901.09269 , title =
-
[20]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[21]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
- [22]
-
[23]
Khaled, Ahmed and Richt. Better Theory for. Transactions on Machine Learning Research , year=
- [24]
-
[25]
arXiv preprint arXiv:2002.12410 , year=
On Biased Compression for Distributed Learning , author=. arXiv preprint arXiv:2002.12410 , year=
-
[26]
Information and Inference: A Journal of the IMA , title =
Mher Safaryan and Egor Shulgin and Peter Richt\'. Information and Inference: A Journal of the IMA , title =
-
[27]
International Conference on Machine Learning , pages=
Li, Zhize and Bao, Hongyan and Zhang, Xiangliang and Richt. International Conference on Machine Learning , pages=. 2021 , organization=
work page 2021
-
[28]
The Error-Feedback Framework: Better Rates for
Stich, Sebastian and Sai Praneeth Karimireddy , journal=. The Error-Feedback Framework: Better Rates for
-
[29]
Karimireddy, Sai Praneeth and Rebjock, Quentin and Stich, Sebastian and Jaggi, Martin , booktitle =. Error Feedback Fixes
-
[30]
9th International Conference on Learning Representations (ICLR) , year=
A Better Alternative to Error Feedback for Communication-Efficient Distributed Learning , author=. 9th International Conference on Learning Representations (ICLR) , year=
-
[31]
Hanlin Tang and Xiangru Lian and Chen Yu and Tong Zhang and Ji Liu , booktitle =
-
[32]
Stich, Sebastian U. and Cordonnier, J.-B. and Jaggi, Martin , title =. Advances in Neural Information Processing Systems , year =
-
[33]
Artificial intelligence and statistics , pages=
Communication-efficient learning of deep networks from decentralized data , author=. Artificial intelligence and statistics , pages=. 2017 , organization=
work page 2017
-
[34]
Advances in Neural Information Processing Systems , title =
Gorbunov, Eduard and Kovalev, Dmitry and Makarenko, Dmitry and Richt\'. Advances in Neural Information Processing Systems , title =
-
[35]
International Conference on Learning Representations (ICLR) , year=
Decentralized Deep Learning with Arbitrary Communication Compression , author=. International Conference on Learning Representations (ICLR) , year=
-
[36]
Advances in Neural Information Processing Systems (NIPS) , year =
Alistarh, Dan and Grubic, Demjan and Li, Jerry and Tomioka, Ryota and Vojnovic, Milan , title =. Advances in Neural Information Processing Systems (NIPS) , year =
-
[37]
Debraj Basu and Deepesh Data and Can Karakus and Suhas Diggavi , booktitle=
-
[38]
Cong Xie and Shuai Zheng and Oluwasanmi Koyejo and Indranil Gupta and Mu Li and Haibin Lin , booktitle=
-
[39]
9th International Conference on Learning Representations (ICLR) , title =
Horv\'. 9th International Conference on Learning Representations (ICLR) , title =
- [40]
-
[41]
arXiv preprint arXiv:1905.05920 , year=
Hybrid stochastic gradient descent algorithms for stochastic nonconvex optimization , author=. arXiv preprint arXiv:1905.05920 , year=
- [42]
-
[43]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Deep residual learning for image recognition , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[44]
Learning multiple layers of features from tiny images , author=. 2009 , jnumber =
work page 2009
-
[45]
Advances in Neural Information Processing Systems , year=
Pytorch: An imperative style, high-performance deep learning library , author=. Advances in Neural Information Processing Systems , year=
-
[46]
MNIST handwritten digit database , author=. ATT Labs [Online]. Available: http://yann.lecun.com/exdb/mnist , volume=
- [47]
-
[48]
Statistical tables for biological, agricultural aad medical research , author=. 1938 , publisher=
work page 1938
-
[49]
arXiv preprint arXiv:2005.00224 , year=
Distributed stochastic non-convex optimization: Momentum-based variance reduction , author=. arXiv preprint arXiv:2005.00224 , year=
-
[50]
arXiv preprint arXiv:1912.06036 , year=
Parallel Restarted SPIDER--Communication Efficient Distributed Nonconvex Optimization with Optimal Computation Complexity , author=. arXiv preprint arXiv:1912.06036 , year=
-
[51]
Momentum-based variance reduction in non-convex
Cutkosky, Ashok and Orabona, Francesco , journal=. Momentum-based variance reduction in non-convex
-
[52]
Compressed communication for distributed deep learning: Survey and quantitative evaluation , author=
-
[53]
In Neural Information Processing Systems, 2021
Richt. In Neural Information Processing Systems, 2021. , year=
work page 2021
-
[54]
Optimization Methods and Software , year=
Stochastic distributed learning with gradient quantization and variance reduction , author=. Optimization Methods and Software , year=
-
[55]
International Conference on Artificial Intelligence and Statistics , pages=
Federated learning with compression: Unified analysis and sharp guarantees , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2021 , organization=
work page 2021
-
[56]
Improved convergence rates for non-convex federated learning with compression , author=. arXiv e-prints , pages=
-
[57]
arXiv preprint arXiv:2102.07845 , year=
MARINA: Faster non-convex distributed learning with compression , author=. arXiv preprint arXiv:2102.07845 , year=
-
[58]
Language Models are Few-Shot Learners
Language models are few-shot learners , author=. arXiv preprint arXiv:2005.14165 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[59]
arXiv preprint arXiv:2105.12806 , year=
A Universal Law of Robustness via Isoperimetry , author=. arXiv preprint arXiv:2105.12806 , year=
-
[60]
arXiv preprint arXiv:2012.06188 , year=
Recent theoretical advances in non-convex optimization , author=. arXiv preprint arXiv:2012.06188 , year=
-
[61]
Deep Learning Scaling is Predictable, Empirically
Deep learning scaling is predictable, empirically , author=. arXiv preprint arXiv:1712.00409 , year=
work page internal anchor Pith review arXiv
-
[62]
Federated Learning: Strategies for Improving Communication Efficiency
Federated learning: Strategies for improving communication efficiency , author=. arXiv preprint arXiv:1610.05492 , year=
work page internal anchor Pith review arXiv
-
[63]
A field guide to federated optimization , author=. arXiv preprint arXiv:2107.06917 , year=
-
[64]
arXiv preprint arXiv:1902.01046 , year=
Towards federated learning at scale: System design , author=. arXiv preprint arXiv:1902.01046 , year=
-
[65]
Proceedings of Machine Learning and Systems , volume=
Federated optimization in heterogeneous networks , author=. Proceedings of Machine Learning and Systems , volume=
-
[66]
Vogels, Thijs and He, Lie and Koloskova, Anastasiia and Karimireddy, Sai Praneeth and Lin, Tao and Stich, Sebastian U and Jaggi, Martin , journal=
-
[67]
IEEE Transactions on Automatic Control , volume=
Distributed optimization over time-varying directed graphs , author=. IEEE Transactions on Automatic Control , volume=. 2014 , publisher=
work page 2014
-
[68]
Mathematical Programming , pages=
A hybrid stochastic optimization framework for composite nonconvex optimization , author=. Mathematical Programming , pages=. 2021 , publisher=
work page 2021
-
[69]
arXiv preprint arXiv:2008.09055 , year=
An optimal hybrid variance-reduced algorithm for stochastic composite nonconvex optimization , author=. arXiv preprint arXiv:2008.09055 , year=
-
[70]
Advances and open problems in federated learning , author=. Foundations and Trends. 2021 , publisher=
work page 2021
-
[71]
11th International Conference on Learning Representations (ICLR) , year=
Tyurin, Alexander and Richt. 11th International Conference on Learning Representations (ICLR) , year=
-
[72]
Advances in Neural Information Processing Systems , volume=
Gradient sparsification for communication-efficient distributed optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[73]
Mathematical and Scientific Machine Learning , pages=
Natural compression for distributed deep learning , author=. Mathematical and Scientific Machine Learning , pages=. 2022 , organization=
work page 2022
-
[74]
Natural compression for distributed deep learning , booktitle =
Samuel Horv\'. Natural compression for distributed deep learning , booktitle =. 2022 , note =
work page 2022
-
[75]
Stich, Sebastian U and Cordonnier, Jean-Baptiste and Jaggi, Martin , journal=. Sparsified
-
[76]
arXiv preprint arXiv:2203.04925 , year=
Correlated quantization for distributed mean estimation and optimization , author=. arXiv preprint arXiv:2203.04925 , year=
-
[77]
arXiv preprint arXiv:2110.03294 , year=
Fatkhullin, Ilyas and Sokolov, Igor and Gorbunov, Eduard and Li, Zhize and Richt. arXiv preprint arXiv:2110.03294 , year=
-
[78]
Adaptive federated optimization,
Adaptive federated optimization , author=. arXiv preprint arXiv:2003.00295 , year=
-
[79]
arXiv preprint arXiv:1906.04329 , year=
Federated learning for emoji prediction in a mobile keyboard , author=. arXiv preprint arXiv:1906.04329 , year=
-
[80]
Deep gradient compression: Reducing the communication bandwidth for distributed training,
Deep gradient compression: Reducing the communication bandwidth for distributed training , author=. arXiv preprint arXiv:1712.01887 , year=
-
[81]
Mathematical Programming , volume=
Lower bounds for finding stationary points I , author=. Mathematical Programming , volume=. 2020 , publisher=
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.