Recognition: no theorem link
SARA: Semantically Adaptive Relational Alignment for Video Diffusion Models
Pith reviewed 2026-05-11 02:18 UTC · model grok-4.3
The pith
SARA improves text alignment and motion quality in video diffusion models by routing relational supervision to prompt-salient token pairs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
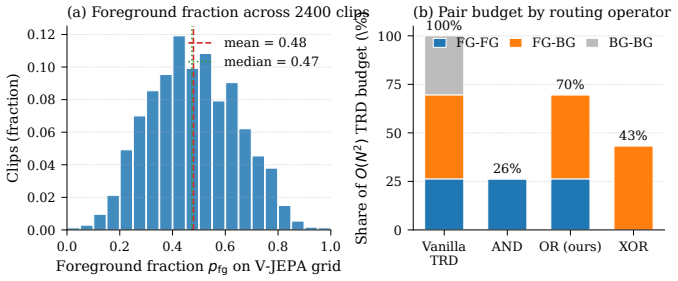
SARA keeps token-relation distillation from a frozen visual foundation model but modulates it with text-conditioned saliency: a Stage-1 aligner trained on SAM 3.1 masks produces continuous saliency scores that are fused into the distillation objective through a pair-routing operator; each token pair receives elevated weight whenever either endpoint is salient, thereby directing supervision toward prompt-relevant relations and away from background-background pairs.
What carries the argument
The pair-routing operator, which fuses continuous saliency scores from a prompt-conditioned Stage-1 aligner into the token-relation distillation loss by elevating the weight of any pair whose endpoints include at least one salient token.
Load-bearing premise
The saliency scores produced by the Stage-1 aligner correctly identify which tokens are relevant to the prompt without introducing systematic bias or noise that misroutes supervision.
What would settle it
Replacing the learned saliency scores with uniform or random weights inside the pair-routing operator and observing that the reported gains on the 13-dimension VLM rubric, VBench scores, and blind user study all disappear would falsify the claim that adaptive routing is responsible for the improvements.
Figures








read the original abstract
Recent video diffusion models (VDMs) synthesize visually convincing clips, yet still drop entities, mis-bind attributes, and weaken the interactions specified in the prompt. Representation-alignment objectives such as VideoREPA and MoAlign improve fine-grained text following by distilling spatio-temporal token relations from a frozen visual foundation model, but their pairwise supervision budget is allocated by visual or motion cues rather than by how relevant each pair is to the prompt. We present SARA, Semantically Adaptive Relational Alignment, which keeps token-relation distillation (TRD) on a frozen VFM target and adds a text-conditioned saliency that decides which token pairs carry supervision. A lightweight Stage 1 aligner is trained with per-entity SAM 3.1 mask supervision and an InfoNCE regulariser, and its continuous saliency is fused into TRD through a pair-routing operator that assigns each token pair a weight whenever either of its two endpoints is salient, thereby routing supervision toward subject-subject and subject-background pairs and away from background-background ones. In the Wan2.2 continual-training setting, SARA improves both text alignment and motion quality over SFT, VideoREPA, and MoAlign on a 13-dimension VLM rubric, on the public VBench benchmarks, and in a blind user study.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SARA for video diffusion models, which augments token-relation distillation (TRD) from a frozen visual foundation model with a text-conditioned saliency mechanism. A lightweight Stage-1 aligner is trained on per-entity SAM 3.1 masks plus InfoNCE to produce continuous saliency scores; these are fused via a pair-routing operator that weights token pairs for TRD supervision whenever either endpoint is salient. This routes supervision toward subject-subject and subject-background pairs. In the Wan2.2 continual-training setting, SARA is reported to improve text alignment and motion quality over SFT, VideoREPA, and MoAlign on a 13-dimension VLM rubric, VBench benchmarks, and a blind user study.
Significance. If the saliency mechanism correctly identifies prompt-relevant pairs, SARA would constitute a targeted advance over prior representation-alignment methods by making pairwise supervision semantically adaptive rather than purely visual or motion-driven. The design reuses frozen VFMs and SAM without introducing new parameters into the diffusion backbone, which is a practical strength. The empirical claims on multiple benchmarks and user studies, if substantiated with ablations, would strengthen the case for semantic routing in VDM alignment.
major comments (2)
- [Abstract / Stage-1 aligner description] Abstract / Stage-1 aligner description: The central claim that SARA improves text alignment and motion quality via semantic adaptation rests on the assumption that saliency scores from the Stage-1 aligner (supervised only by SAM 3.1 masks and InfoNCE) correctly identify prompt-relevant token pairs. No independent validation is reported showing correlation with prompt entity mentions rather than raw visual salience; the pair-routing operator then directly propagates any mismatch into the TRD loss weights.
- [Abstract] Abstract: The reported improvements over VideoREPA and MoAlign are stated without quantitative deltas, ablation tables isolating the pair-routing operator, error bars, or implementation details for the saliency-to-weight mapping. This makes it impossible to assess whether gains exceed what could arise from incidental regularization or extra compute.
minor comments (2)
- The abstract does not specify the exact mathematical form of the pair-routing operator or how continuous saliency is normalized before weighting the TRD loss.
- Clarify whether the 13-dimension VLM rubric is a standard benchmark or custom; if custom, provide its definition and inter-rater reliability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript introducing SARA. The comments help clarify how to better substantiate the semantic adaptation mechanism and improve the presentation of results. We address each major comment below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [Abstract / Stage-1 aligner description] Abstract / Stage-1 aligner description: The central claim that SARA improves text alignment and motion quality via semantic adaptation rests on the assumption that saliency scores from the Stage-1 aligner (supervised only by SAM 3.1 masks and InfoNCE) correctly identify prompt-relevant token pairs. No independent validation is reported showing correlation with prompt entity mentions rather than raw visual salience; the pair-routing operator then directly propagates any mismatch into the TRD loss weights.
Authors: We agree that explicit validation would strengthen the central claim. The Stage-1 aligner uses per-entity SAM 3.1 masks for supervision together with InfoNCE, which is intended to produce text-conditioned saliency focused on prompt entities rather than generic visual salience. However, we did not include a dedicated correlation analysis between the resulting saliency scores and prompt entity mentions. In the revised manuscript we will add a new subsection with quantitative correlation metrics (e.g., overlap between high-saliency tokens and prompt-derived entity locations on a held-out set) and qualitative examples to demonstrate that the routing indeed prioritizes prompt-relevant pairs. revision: yes
-
Referee: [Abstract] Abstract: The reported improvements over VideoREPA and MoAlign are stated without quantitative deltas, ablation tables isolating the pair-routing operator, error bars, or implementation details for the saliency-to-weight mapping. This makes it impossible to assess whether gains exceed what could arise from incidental regularization or extra compute.
Authors: The full paper already contains the requested elements: Table 2 reports numerical deltas on the 13-dimension VLM rubric and VBench; Table 3 isolates the contribution of the pair-routing operator via ablations; error bars are shown from three independent runs; and Section 3.2 details the saliency-to-weight mapping formula. To address the referee’s concern about the abstract, we will revise the abstract to include the key quantitative improvements (e.g., +X% on text alignment) and add explicit pointers to the ablation tables and implementation details. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's core method trains a lightweight Stage-1 aligner on external SAM 3.1 per-entity masks plus InfoNCE regularization, then fuses its continuous saliency scores into token-relation distillation via a pair-routing operator that weights pairs based on endpoint salience. All claimed improvements are measured empirically against external baselines (SFT, VideoREPA, MoAlign) on VBench, a 13-dimension VLM rubric, and blind user studies in the Wan2.2 continual-training setting. No equations, fitted parameters, or predictions reduce to the inputs by construction; the saliency routing is not self-defined or renamed from prior results, and no load-bearing self-citations or uniqueness theorems are invoked. The derivation remains self-contained against external frozen VFMs and SAM without circular reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- saliency-to-weight mapping parameters
axioms (2)
- domain assumption Frozen visual foundation model supplies reliable spatio-temporal token relations for distillation
- domain assumption SAM 3.1 per-entity masks provide accurate entity boundaries for Stage-1 supervision
invented entities (2)
-
pair-routing operator
no independent evidence
-
text-conditioned saliency map
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Seedance 2.0: Advancing Video Generation for World Complexity
Team Seedance, De Chen, Liyang Chen, Xin Chen, Ying Chen, Zhuo Chen, Zhuowei Chen, Feng Cheng, Tianheng Cheng, Yufeng Cheng, et al. Seedance 2.0: Advancing video generation for world complexity.arXiv preprint arXiv:2604.14148, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Google. Veo 3.1 announcement. https://blog.google/innovation-and-ai/ technology/developers-tools/veo-3-1-gemini-api/ , 2026. Accessed: April 29, 2026
work page 2026
-
[3]
wan 2.7.https://wan.video/, 2026
Wan Team. wan 2.7.https://wan.video/, 2026. Accessed: April 29, 2026
work page 2026
-
[4]
LTX-2: Efficient Joint Audio-Visual Foundation Model
Yoav HaCohen, Benny Brazowski, Nisan Chiprut, Yaki Bitterman, Andrew Kvochko, Avishai Berkowitz, Daniel Shalem, Daphna Lifschitz, Dudu Moshe, Eitan Porat, et al. Ltx-2: Efficient joint audio-visual foundation model.arXiv preprint arXiv:2601.03233, 2026
work page Pith review arXiv 2026
-
[5]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Hunyuanvideo 1.5 technical report.arXiv preprint arXiv:2511.18870, 2025a
Bing Wu, Chang Zou, Changlin Li, Duojun Huang, Fang Yang, Hao Tan, Jack Peng, Jianbing Wu, Jiangfeng Xiong, Jie Jiang, et al. Hunyuanvideo 1.5 technical report.arXiv preprint arXiv:2511.18870, 2025
-
[7]
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. Representation alignment for generation: Training diffusion transformers is easier than you think.arXiv preprint arXiv:2410.06940, 2024
work page internal anchor Pith review arXiv 2024
-
[8]
arXiv preprint arXiv:2505.23656 (2025) 2, 4, 6, 7, 8
Xiangdong Zhang, Jiaqi Liao, Shaofeng Zhang, Fanqing Meng, Xiangpeng Wan, Junchi Yan, and Yu Cheng. Videorepa: Learning physics for video generation through relational alignment with foundation models.arXiv preprint arXiv:2505.23656, 2025
-
[9]
Moalign: Motion-centric representation alignment for video diffusion models
Aritra Bhowmik, Denis Korzhenkov, Cees GM Snoek, Amirhossein Habibian, and Mohsen Ghafoorian. Moalign: Motion-centric representation alignment for video diffusion models. arXiv preprint arXiv:2510.19022, 2025
-
[10]
Vision Transformers Need More Than Registers
Cheng Shi, Yizhou Yu, and Sibei Yang. Vision transformers need more than registers.arXiv preprint arXiv:2602.22394, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Do- minik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Video generation models as world simulators
OpenAI. Video generation models as world simulators. https://openai.com/research/ video-generation-models-as-world-simulators, 2024. Accessed: April 29, 2026
work page 2024
-
[14]
kling 3.https://kling.ai/, 2026
Kling Team. kling 3.https://kling.ai/, 2026. Accessed: April 29, 2026
work page 2026
-
[15]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024
work page 2024
-
[17]
Hritik Bansal, Clark Peng, Yonatan Bitton, Roman Goldenberg, Aditya Grover, and Kai-Wei Chang. Videophy-2: A challenging action-centric physical commonsense evaluation in video generation.arXiv preprint arXiv:2503.06800, 2025. 27
-
[18]
Lei Wang, Yuxin Song, Ge Wu, Haocheng Feng, Hang Zhou, Jingdong Wang, Yaxing Wang, and Jian Yang. Refalign: Representation alignment for reference-to-video generation.arXiv preprint arXiv:2603.25743, 2026
-
[19]
Tora: Trajectory-oriented diffusion transformer for video generation
Zhenghao Zhang, Junchao Liao, Menghao Li, Zuozhuo Dai, Bingxue Qiu, Siyu Zhu, Long Qin, and Weizhi Wang. Tora: Trajectory-oriented diffusion transformer for video generation. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 2063–2073, 2025
work page 2063
-
[20]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in Neural Information Processing Systems, 35:27730–27744, 2022
work page 2022
-
[21]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[22]
DanceGRPO: Unleashing GRPO on Visual Generation
Zeyue Xue, Jie Wu, Yu Gao, Fangyuan Kong, Lingting Zhu, Mengzhao Chen, Zhiheng Liu, Wei Liu, Qiushan Guo, Weilin Huang, et al. Dancegrpo: Unleashing grpo on visual generation. arXiv preprint arXiv:2505.07818, 2025
work page internal anchor Pith review arXiv 2025
-
[23]
Diffusion model alignment using direct preference optimization
Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, and Nikhil Naik. Diffusion model alignment using direct preference optimization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8228–8238, 2024
work page 2024
-
[24]
Videodpo: Omni-preference alignment for video diffusion generation
Runtao Liu, Haoyu Wu, Ziqiang Zheng, Chen Wei, Yingqing He, Renjie Pi, and Qifeng Chen. Videodpo: Omni-preference alignment for video diffusion generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 8009–8019, 2025
work page 2025
-
[25]
Imagereward: Learning and evaluating human preferences for text-to-image generation
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagereward: Learning and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems, 36:15903–15935, 2023
work page 2023
-
[26]
Repa-e: Unlocking vae for end-to-end tuning with latent diffusion transformers
Xingjian Leng, Jaskirat Singh, Yunzhong Hou, Zhenchang Xing, Saining Xie, and Liang Zheng. Repa-e: Unlocking vae for end-to-end tuning with latent diffusion transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
work page 2025
-
[27]
Tencent Hunyuan Team. Script-a-video: Deep structured audio-visual captions via factorized streams and relational grounding.arXiv preprint arXiv:2604.11244, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
arXiv preprint arXiv:2512.10942 (2025) 11
Delong Chen, Mustafa Shukor, Theo Moutakanni, Willy Chung, Jade Yu, Tejaswi Kasarla, Yejin Bang, Allen Bolourchi, Yann LeCun, and Pascale Fung. Vl-jepa: Joint embedding predictive architecture for vision-language.arXiv preprint arXiv:2512.10942, 2025
-
[29]
arXiv preprint arXiv:2603.14482 (2026)
Lorenzo Mur-Labadia, Matthew Muckley, Amir Bar, Mido Assran, Koustuv Sinha, Mike Rabbat, Yann LeCun, Nicolas Ballas, and Adrien Bardes. V-jepa 2.1: Unlocking dense features in video self-supervised learning.arXiv preprint arXiv:2603.14482, 2026
-
[30]
Mingxin Li, Yanzhao Zhang, Dingkun Long, Keqin Chen, Sibo Song, Shuai Bai, Zhibo Yang, Pengjun Xie, An Yang, Dayiheng Liu, Jingren Zhou, and Junyang Lin. Qwen3-vl-embedding and qwen3-vl-reranker: A unified framework for state-of-the-art multimodal retrieval and ranking.arXiv, 2026
work page 2026
-
[31]
Qwen Team. Qwen3.5. https://qwen.ai/blog?id=qwen3.5, 2026. Accessed: May 6, 2026
work page 2026
-
[32]
Qwen Team. Qwen3.6. https://qwen.ai/blog?id=qwen3.6, 2026. Accessed: May 6, 2026
work page 2026
-
[33]
Welcome gemma 4: Frontier multimodal intelligence on device.https://huggingface.co/blog/gemma4, 2026
Hugging Face and Google DeepMind. Welcome gemma 4: Frontier multimodal intelligence on device.https://huggingface.co/blog/gemma4, 2026. Accessed: May 6, 2026
work page 2026
-
[34]
VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness
Dian Zheng, Ziqi Huang, Hongbo Liu, Kai Zou, Yinan He, Fan Zhang, Lulu Gu, Yuanhan Zhang, Jingwen He, Wei-Shi Zheng, et al. Vbench-2.0: Advancing video generation benchmark suite for intrinsic faithfulness.arXiv preprint arXiv:2503.21755, 2025. 28
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.