Recognition: 2 theorem links
· Lean TheoremNSPOD: Accelerating Krylov solvers via DeepONet-learned POD subspaces
Pith reviewed 2026-05-12 03:54 UTC · model grok-4.3
The pith
DeepONet-learned POD subspaces form a multigrid-like preconditioner that cuts Krylov solver iterations for parametric solid mechanics PDEs on complex domains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
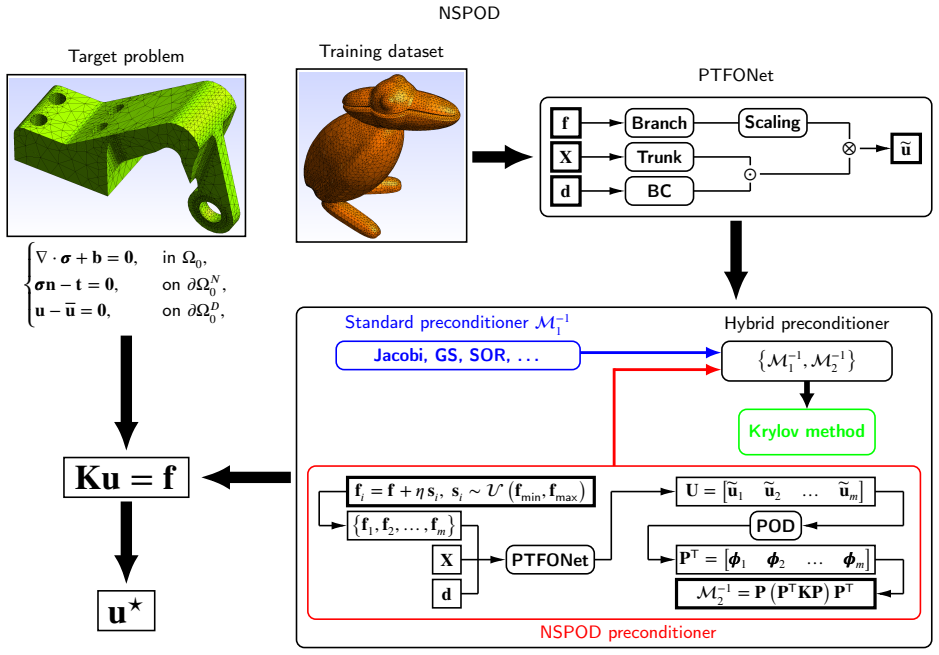
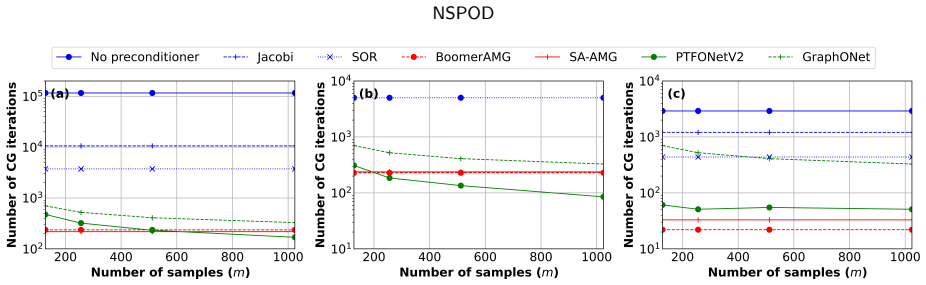
NSPOD is a multigrid-like deep operator network-based preconditioner in which DeepONet learns POD subspaces from parametric data; when these subspaces are used to precondition Krylov solvers for linearized solid mechanics PDEs on unstructured domains from complex CAD geometries, the number of iterations required for convergence drops dramatically, even compared with algebraic multigrid preconditioners, while maintaining performance on geometries and discretizations not seen during training.
What carries the argument
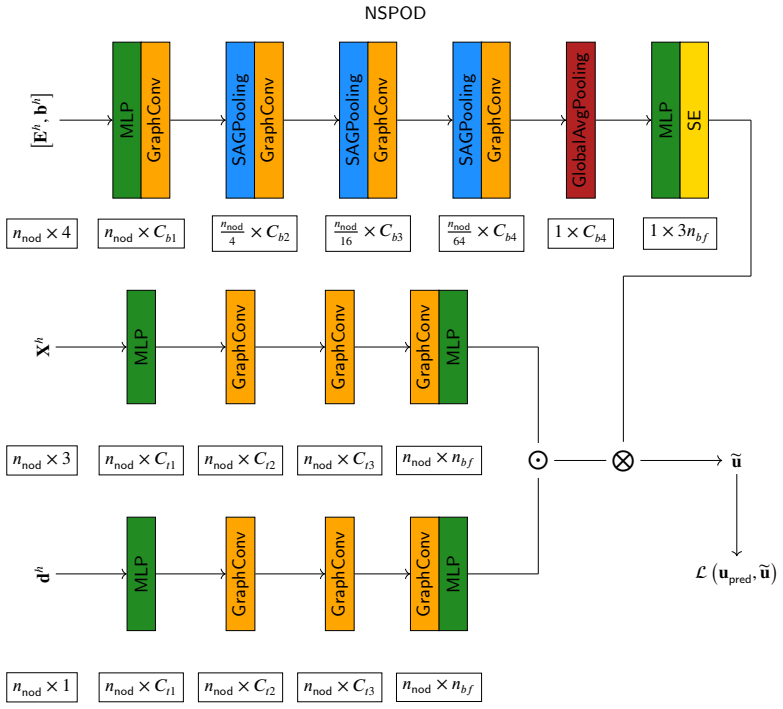
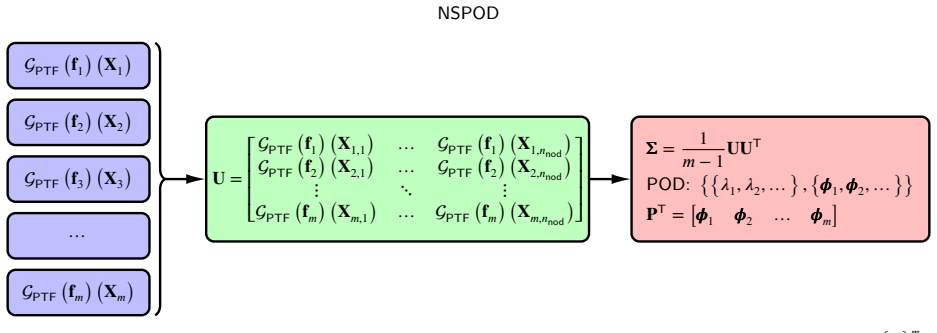
NSPOD, the DeepONet-learned POD subspaces that serve as the multigrid-like preconditioner inside the hybridized Krylov solver.
If this is right
- Krylov solvers preconditioned with NSPOD converge in substantially fewer iterations than those preconditioned with algebraic multigrid on the tested parametric solid mechanics problems.
- The preconditioner maintains its iteration-reduction benefit across arbitrary unstructured meshes without any retraining.
- Hybrid neural-classical solvers of this form can reach or exceed the convergence speed of current gold-standard preconditioners for solid mechanics PDEs.
- The method applies directly to parametric problems whose domains come from complex CAD models.
Where Pith is reading between the lines
- If the learned subspaces remain effective under mesh refinement, NSPOD could be inserted into adaptive or h-refinement loops without extra training cost.
- The same subspace-learning idea might transfer to other linear systems whose solution manifolds admit low-rank POD representations, such as certain fluid or thermal problems.
- Combining NSPOD with existing algebraic multigrid hierarchies could produce a two-level preconditioner whose coarse correction is neural rather than algebraic.
Load-bearing premise
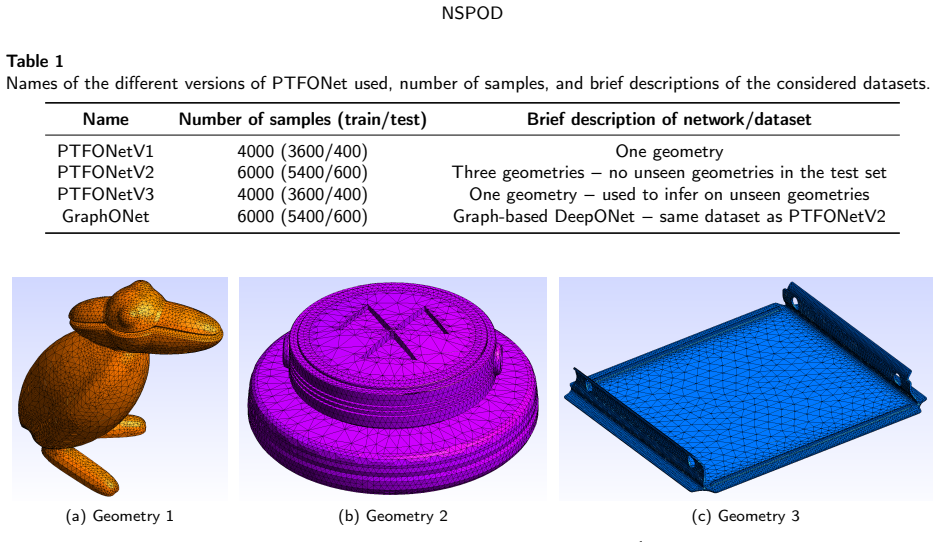
The POD subspaces learned by DeepONet from the training set continue to supply effective preconditioning information for previously unseen geometries, meshes, boundary conditions, and material parameters.
What would settle it
A single new CAD geometry or parameter combination on which the NSPOD-hybridized solver requires at least as many iterations as algebraic multigrid would falsify the claim of consistent dramatic reduction.
Figures




read the original abstract
The convergence of Krylov-based linear iterative solvers applied to parametric partial differential equations (PDEs) is often highly sensitive to the domain, its discretization, the location/values of the applied Dirichlet/Neumann boundary conditions, body forces and material properties, among others. We have previously introduced hybridization of classical linear iterative solvers with neural operators for specific geometries, but they tend to not perform well on geometries not previously seen during training. We partially addressed this challenge by introducing the deep operator network Geo-DeepONet and hybridizing it with Krylov-based iterative linear solvers, which, despite learning effectively across arbitrary unstructured meshes without requiring retraining, led to only modest reductions in iterations compared to state-of-the-art preconditioners. In this study we introduce Neural Subspace Proper Orthogonal Decomposition (NSPOD), a multigrid-like deep operator network-based preconditioner which can dramatically reduce the number of iterations needed for convergence in Krylov-based linear iterative solvers, even when compared to state-of-the-art methods such as algebraic multigrid preconditioners. We demonstrate its efficiency via numerical experiments on a linearized version of solid mechanics PDEs applied to unstructured domains obtained from complex CAD geometries. We expect that the findings in this study lead to more efficient hybrid preconditioners that can match, or possibly even surpass, the convergence properties of the current gold standard preconditioning methods for solid mechanics PDEs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Neural Subspace Proper Orthogonal Decomposition (NSPOD), a hybrid preconditioner that employs a DeepONet to predict POD subspaces for use in Krylov solvers applied to parametric linearized elasticity problems on unstructured CAD meshes. Building on prior Geo-DeepONet work, it claims that the learned subspaces enable dramatic reductions in iteration counts relative to algebraic multigrid (AMG) preconditioners, even for geometries not seen during training and without retraining.
Significance. If the generalization and performance claims hold, NSPOD would constitute a notable advance in learned multigrid-like preconditioners for parametric PDEs in solid mechanics, potentially offering iteration reductions that match or exceed AMG while retaining some geometry-agnostic properties. The integration of operator networks with POD for low-rank corrections is a constructive idea that could influence hybrid solver design, though the absence of quantitative benchmarks in the abstract prevents immediate evaluation of its impact.
major comments (2)
- [Abstract] Abstract: The assertion that NSPOD 'can dramatically reduce the number of iterations needed for convergence... even when compared to state-of-the-art methods such as algebraic multigrid preconditioners' is presented without any supporting numerical data, iteration counts, convergence histories, error bars, or table/figure references, making the central performance claim impossible to assess from the given text.
- [Abstract] The generalization assumption (that DeepONet-learned POD subspaces remain effective for out-of-distribution geometries, discretizations, and material parameters without retraining) is load-bearing for the AMG comparison, yet the abstract and implied experiments provide no description of the training distribution's coverage of topological variations, aspect ratios, or contrasts that would distinguish interpolation from robust extrapolation.
minor comments (1)
- [Abstract] The abstract references prior hybridization work but does not include citations; adding explicit references to the Geo-DeepONet and related papers would improve traceability.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive suggestions. The comments highlight opportunities to strengthen the abstract, and we have revised it accordingly to include quantitative support and clarification on generalization. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that NSPOD 'can dramatically reduce the number of iterations needed for convergence... even when compared to state-of-the-art methods such as algebraic multigrid preconditioners' is presented without any supporting numerical data, iteration counts, convergence histories, error bars, or table/figure references, making the central performance claim impossible to assess from the given text.
Authors: We agree that the abstract should provide quantitative context for the performance claims. In the revised manuscript we have updated the abstract to include specific observed iteration reductions (factors of 4-12x relative to AMG across the reported test cases) together with explicit references to the convergence histories and tables in Sections 4 and 5. This allows readers to evaluate the claims directly while remaining within abstract length limits. revision: yes
-
Referee: [Abstract] The generalization assumption (that DeepONet-learned POD subspaces remain effective for out-of-distribution geometries, discretizations, and material parameters without retraining) is load-bearing for the AMG comparison, yet the abstract and implied experiments provide no description of the training distribution's coverage of topological variations, aspect ratios, or contrasts that would distinguish interpolation from robust extrapolation.
Authors: We acknowledge the need for greater clarity on the training distribution in the abstract. The revised abstract now briefly states that the training set spans multiple families of unstructured CAD geometries with varying topologies, aspect ratios, and material contrasts (Young's modulus ratios up to 10^4), and that all reported AMG comparisons use geometries and discretizations withheld from training. Full details of the training distribution, parameter ranges, and out-of-distribution test cases appear in Sections 3.2 and 4.1. revision: yes
Circularity Check
No significant circularity; NSPOD claims rest on experimental validation of a hybrid DeepONet-POD construction
full rationale
The paper defines NSPOD by combining standard DeepONet operator learning with POD subspace extraction to form a preconditioner for Krylov solvers on parametric elasticity problems. Performance claims (iteration reductions versus AMG) are asserted via numerical experiments on CAD geometries rather than by any algebraic identity that equates the output subspaces or convergence rates to the training data or fitted parameters by construction. Prior self-references to Geo-DeepONet describe an earlier, weaker method and do not supply the load-bearing step for the new dramatic reductions; the derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- DeepONet training hyperparameters and architecture
axioms (2)
- domain assumption DeepONet can learn accurate mappings from PDE parameters and geometries to effective POD subspaces for preconditioning
- domain assumption The learned subspaces yield effective preconditioners that accelerate Krylov convergence across varied domains
invented entities (1)
-
NSPOD preconditioner
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearWe introduce Neural Subspace Proper Orthogonal Decomposition (NSPOD), a multigrid-like deep operator network-based preconditioner which can dramatically reduce the number of iterations needed for convergence in Krylov-based linear iterative solvers
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearPTFONet architecture; ... contraction between branch and trunk networks ... PointTransformer layers
Reference graph
Works this paper leans on
-
[1]
A fully asynchronous multifrontal solver using distributed dynamic scheduling
Amestoy, P.R., Duff, I.S., L’Excellent, J.Y., Koster, J., 2001. A fully asynchronous multifrontal solver using distributed dynamic scheduling. SIAM Journal on Matrix Analysis and Applications 23, 15–41. URL:https://doi.org/10.1137/S0895479899358194, doi:10.1137/ S0895479899358194,arXiv:https://doi.org/10.1137/S089547989935819
-
[2]
DOLFINx: the next generation FEniCS problem solving environment
Baratta, I.A., Dean, J.P., Dokken, J.S., Habera, M., Hale, J.S., Richardson, C.N., Rognes, M.E., Scroggs, M.W., Sime, N., Wells, G.N., 2023. DOLFINx: the next generation FEniCS problem solving environment. preprint. doi:10.5281/zenodo.10447666
-
[3]
Bathe, K., 2006. Finite Element Procedures. Prentice Hall. URL:https://books.google.com/books?id=rWvefGICfO8C
work page 2006
-
[4]
TheMathematicalTheoryofFiniteElementMethods
Brenner,S.,Scott,L.,2013. TheMathematicalTheoryofFiniteElementMethods. TextsinAppliedMathematics,SpringerNewYork. URL: https://books.google.com/books?id=9YPrBwAAQBAJ
work page 2013
-
[5]
A Multigrid Tutorial, Second Edition
Briggs, W.L., Henson, V.E., McCormick, S.F., 2000. A Multigrid Tutorial, Second Edition. Second ed., Society for Industrial and Applied Mathematics. URL:https://epubs.siam.org/doi/abs/10.1137/1.9780898719505, doi:10.1137/1.9780898719505, arXiv:https://epubs.siam.org/doi/pdf/10.1137/1.9780898719505
-
[6]
Physics-informed neural networks (pinns) for fluid mechanics: a review
Cai, S., Mao, Z., Wang, Z., Yin, M., Karniadakis, G.E., 2021a. Physics-informed neural networks (pinns) for fluid mechanics: a review. Acta Mechanica Sinica 37, 1727–1738. URL:https://doi.org/10.1007/s10409-021-01148-1, doi:10.1007/s10409-021-01148-1
-
[7]
Physics -Informed Neural Networks for Heat Transfer Problems,
Cai, S., Wang, Z., Wang, S., Perdikaris, P., Karniadakis, G.E., 2021b. Physics-informed neural networks for heat transfer problems. Journal of Heat Transfer 143, 060801. URL:https://doi.org/10.1115/1.4050542, doi:10.1115/1.4050542
-
[8]
The Finite Element Method for Elliptic Problems
Ciarlet, P.G., 2002. The Finite Element Method for Elliptic Problems. Society for Industrial and Applied Math- ematics. URL:https://epubs.siam.org/doi/abs/10.1137/1.9780898719208, doi:10.1137/1.9780898719208, arXiv:https://epubs.siam.org/doi/pdf/10.1137/1.9780898719208
-
[9]
MAgNET: A graph U-Net architecture for mesh-based simulations
Deshpande, S., Bordas, S.P., Lengiewicz, J., 2024. MAgNET: A graph U-Net architecture for mesh-based simulations. Engineering Applica- tions of Artificial Intelligence 133, 108055. URL:https://www.sciencedirect.com/science/article/pii/S0952197624002136, doi:https://doi.org/10.1016/j.engappai.2024.108055
-
[10]
Falgout, R.D., Yang, U.M., 2002. hypre: A library of high performance preconditioners, in: International Conference on Computational Science, Springer. pp. 632–641
work page 2002
-
[11]
Gmsh: A 3-d finite element mesh generator with built-in pre-and post-processing facilities
Geuzaine, C., Remacle, J.F., 2009. Gmsh: A 3-d finite element mesh generator with built-in pre-and post-processing facilities. International Journal for Numerical Methods in Engineering 79, 1309–1331
work page 2009
-
[12]
Squeeze-and-Excitation Networks
Hu, J., Shen, L., Sun, G., 2018. Squeeze-and-excitation networks, in: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7132–7141. doi:10.1109/CVPR.2018.00745
-
[13]
MIONet: Learning multiple-input operators via tensor product
Jin, P., Meng, S., Lu, L., 2022. MIONet: Learning multiple-input operators via tensor product. SIAM Journal on Scientific Computing 44, A3490–A3514
work page 2022
-
[14]
Billion-scale similarity search with gpus
Johnson, J., Douze, M., Jégou, H., 2019. Billion-scale similarity search with gpus. IEEE Transactions on Big Data 7, 535–547
work page 2019
-
[15]
On the geometry transferability of the hybrid iterative numerical solver for differential equations
Kahana, A., Zhang, E., Goswami, S., Karniadakis, G., Ranade, R., Pathak, J., 2023. On the geometry transferability of the hybrid iterative numerical solver for differential equations. Computational Mechanics 72, 471–484. URL:https://doi.org/10.1007/ s00466-023-02271-5, doi:10.1007/s00466-023-02271-5
-
[16]
Understanding attention and generalization in graph neural networks
Knyazev, B., Taylor, G.W., Amer, M., 2019. Understanding attention and generalization in graph neural networks. Advances in Neural Information Processing Systems 32. URL:https://proceedings.neurips.cc/paper_files/paper/2019/file/ 4c5bcfec8584af0d967f1ab10179ca4b-Paper.pdf
work page 2019
-
[17]
Koch, S., Matveev, A., Jiang, Z., Williams, F., Artemov, A., Burnaev, E., Alexa, M., Zorin, D., Panozzo, D., 2019. Abc: A big cad model dataset for geometric deep learning, in: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 9601–9611. Francesc Levrero-Florencio et al.:Preprint submitted to ElsevierPage 15 of 17 NSPOD
work page 2019
-
[18]
DeepONet based preconditioning strategies for solving parametric linear systems of equations
Kopaničáková, A., Karniadakis, G.E., 2025. DeepONet based preconditioning strategies for solving parametric linear systems of equations. SIAM Journal on Scientific Computing 47, C151–C181. URL:https://doi.org/10.1137/24M162861X, doi:10.1137/24M162861X, arXiv:https://doi.org/10.1137/24M162861X
-
[19]
Lee,J.,Lee,I.,Kang,J.,2019. Self-attentiongraphpooling,in:Chaudhuri,K.,Salakhutdinov,R.(Eds.),Proceedingsofthe36thInternational Conference on Machine Learning, PMLR. pp. 3734–3743. URL:https://proceedings.mlr.press/v97/lee19c.html
work page 2019
-
[20]
Hybrid iterative solvers with geometry-aware neural preconditioners for parametric PDEs
Lee, Y., Florencio, F.L., Pathak, J., Karniadakis, G.E., 2025a. Hybrid iterative solvers with geometry-aware neural preconditioners for parametric PDEs. URL:https://arxiv.org/abs/2512.14596,arXiv:2512.14596
-
[21]
Automaticdiscoveryofoptimalmeta-solversfortime-dependentnonlinearpdes
Lee,Y.,Liu,S.,Darbon,J.,Karniadakis,G.E.,2025b. Automaticdiscoveryofoptimalmeta-solversfortime-dependentnonlinearpdes. URL: https://arxiv.org/abs/2507.00278,arXiv:2507.00278
-
[22]
Lee, Y., Liu, S., Zou, Z., Kahana, A., Turkel, E., Ranade, R., Pathak, J., Karniadakis, G.E., 2025c. Fast meta-solvers for 3d complex-shape scatterersusingneuraloperatorstrainedonanon-scatteringproblem. ComputerMethodsinAppliedMechanicsandEngineering446,118231. URL:https://www.sciencedirect.com/science/article/pii/S0045782525005031, doi:https://doi.org/10...
-
[23]
Fourier neural operator for parametric partial differential equations
Li, Z., Kovachki, N.B., Azizzadenesheli, K., liu, B., Bhattacharya, K., Stuart, A., Anandkumar, A., 2021. Fourier neural operator for parametric partial differential equations. International Conference on Learning Representations URL:https://openreview.net/forum? id=c8P9NQVtmnO
work page 2021
-
[24]
Decoupled weight decay regularization
Loshchilov, I., Hutter, F., 2019. Decoupled weight decay regularization. International Conference on Learning Representations URL: https://openreview.net/forum?id=Bkg6RiCqY7
work page 2019
-
[25]
Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators
Lu,L.,Jin,P.,Pang,G.,Zhang,Z.,Karniadakis,G.E.,2021. Learningnonlinearoperatorsviadeeponetbasedontheuniversalapproximation theoremofoperators. NatureMachineIntelligence3,218–229. URL:https://doi.org/10.1038/s42256-021-00302-5,doi:10.1038/ s42256-021-00302-5
-
[26]
Lu, L., Meng, X., Cai, S., Mao, Z., Goswami, S., Zhang, Z., Karniadakis, G.E., 2022. A comprehensive and fair comparison of two neural operators (with practical extensions) based on fair data. Computer Methods in Applied Mechanics and Engineering 393, 114778. URL: http://dx.doi.org/10.1016/j.cma.2022.114778, doi:10.1016/j.cma.2022.114778
-
[27]
Meijerink, J.A., van der Vorst, H.A., 1977. An iterative solution method for linear systems of which the coefficient matrix is a symmetric 𝑀-matrix. Mathematics of Computation 31, 148–162. URL:http://www.jstor.org/stable/2005786
-
[28]
Weisfeiler and leman go neural: Higher-order graph neural networks
Morris, C., Ritzert, M., Fey, M., Hamilton, W.L., Lenssen, J.E., Rattan, G., Grohe, M., 2021. Weisfeiler and leman go neural: Higher-order graph neural networks. URL:https://arxiv.org/abs/1810.02244,arXiv:1810.02244
-
[29]
PyTorch: An imperative style, high-performance deep learning library
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., Desmaison, A., Kopf, A., Yang, E., DeVito, Z., Raison, M., Tejani, A., Chilamkurthy, S., Steiner, B., Fang, L., Bai, J., Chintala, S., 2019. PyTorch: An imperative style, high-performance deep learning library. Advances in Neural Inform...
work page 2019
-
[30]
Pichi,F.,Moya,B.,Hesthaven,J.S.,2024.Agraphconvolutionalautoencoderapproachtomodelorderreductionforparametrizedpdes.Journal of Computational Physics 501, 112762. URL:https://www.sciencedirect.com/science/article/pii/S0021999124000111, doi:https://doi.org/10.1016/j.jcp.2024.112762
-
[31]
PointNet++: Deep hierarchical feature learning on point sets in a metric space
Qi, C.R., Yi, L., Su, H., Guibas, L.J., 2017. PointNet++: Deep hierarchical feature learning on point sets in a metric space. Advances in Neural Information Processing Systems 30
work page 2017
-
[32]
On the spectral bias of neural networks, in: Chaudhuri, K., Salakhutdinov, R
Rahaman, N., Baratin, A., Arpit, D., Draxler, F., Lin, M., Hamprecht, F., Bengio, Y., Courville, A., 2019. On the spectral bias of neural networks, in: Chaudhuri, K., Salakhutdinov, R. (Eds.), Proceedings of the 36th International Conference on Machine Learning, PMLR. pp. 5301–5310. URL:https://proceedings.mlr.press/v97/rahaman19a.html
work page 2019
-
[33]
Raissi, M., Perdikaris, P., Karniadakis, G., 2019. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. Journal of Computational Physics 378, 686–707. URL:https://www. sciencedirect.com/science/article/pii/S0021999118307125, doi:https://doi.org/10.1016/j.jc...
-
[34]
A sur- vey on oversmoothing in graph neural networks,
Rusch, T.K., Bronstein, M.M., Mishra, S., 2023. A survey on oversmoothing in graph neural networks. URL:https://arxiv.org/abs/ 2303.10993,arXiv:2303.10993
-
[35]
Iterative Methods for Sparse Linear Systems
Saad, Y., 2003. Iterative Methods for Sparse Linear Systems. Second ed., SIAM, Philadelphia. URL:https://epubs.siam.org/doi/abs/10.1137/1.9780898718003, doi:10.1137/1.9780898718003, arXiv:https://epubs.siam.org/doi/pdf/10.1137/1.9780898718003
-
[36]
GMRES: A generalized minimal residual algorithm for solving nonsymmetric linear systems
Saad, Y., Schultz, M.H., 1986. GMRES: A generalized minimal residual algorithm for solving nonsymmetric linear systems. SIAM Journal on Scientific and Statistical Computing 7, 856–869. URL:https://doi.org/10.1137/0907058, doi:10.1137/0907058, arXiv:https://doi.org/10.1137/0907058
-
[37]
Flexible inner-outer Krylov subspace methods
Simoncini, V., Szyld, D.B., 2002. Flexible inner-outer Krylov subspace methods. SIAM Journal on Numerical Analysis 40, 2219–2239. URL:https://doi.org/10.1137/S0036142902401074, doi:10.1137/S0036142902401074, arXiv:https://doi.org/10.1137/S0036142902401074
-
[38]
Domain Decomposition Methods - Algorithms and Theory
Toselli, A., Widlund, O., 2004. Domain Decomposition Methods - Algorithms and Theory. Springer Series in Computational Mathematics, Springer, Berlin Heidelberg. URL:https://books.google.com/books?id=tpSPx68R3KwC
work page 2004
-
[39]
Trefethen,L.N.,Bau,III,D.,1997.NumericalLinearAlgebra.SIAM,Philadelphia.URL:https://epubs.siam.org/doi/abs/10.1137/ 1.9780898719574, doi:10.1137/1.9780898719574,arXiv:https://epubs.siam.org/doi/pdf/10.1137/1.9780898719574
-
[40]
Trottenberg, U., Oosterlee, C., Schuller, A., 2001. Multigrid Methods. Elsevier Science. URL:https://books.google.com/books?id= -og1wD-Nx_wC
work page 2001
-
[41]
Convergence of algebraic multigrid based on smoothed aggregation
Van∖vek, P., Brezina, M., Mandel, J., 2001. Convergence of algebraic multigrid based on smoothed aggregation. Numerische Mathematik 88, 559–579
work page 2001
-
[42]
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I., 2017. Attention is all you need. Advances in Neural Information Processing Systems 30. Francesc Levrero-Florencio et al.:Preprint submitted to ElsevierPage 16 of 17 NSPOD
work page 2017
-
[43]
Iterative methods by space decomposition and subspace correction
Xu, J., 1992. Iterative methods by space decomposition and subspace correction. SIAM Review 34, 581–613. URL:https://doi.org/ 10.1137/1034116, doi:10.1137/1034116,arXiv:https://doi.org/10.1137/1034116
-
[44]
Xu, J., Zikatanov, L., 2017. Algebraic multigrid methods. Acta Numerica 26, 591–721
work page 2017
-
[45]
Revisitingover-smoothingindeepgcns
Yang,C.,Wang,R.,Yao,S.,Liu,S.,Abdelzaher,T.,2020. Revisitingover-smoothingindeepgcns. URL:https://arxiv.org/abs/2003. 13663,arXiv:2003.13663
-
[46]
Iterativemethodsforsolvingpartialdifferenceequationsofelliptictype
Young,D.,1954. Iterativemethodsforsolvingpartialdifferenceequationsofelliptictype. TransactionsoftheAmericanMathematicalSociety 76, 92–111. URL:http://www.jstor.org/stable/1990745
-
[47]
Blendingneuraloperatorsandrelaxation methods in pde numerical solvers
Zhang,E.,Kahana,A.,Kopaničáková,A.,Turkel,E.,Ranade,R.,Pathak,J.,Karniadakis,G.E.,2024. Blendingneuraloperatorsandrelaxation methods in pde numerical solvers. Nature Machine Intelligence 6, 1303–1313
work page 2024
-
[48]
Zhao, H., Jiang, L., Jia, J., Torr, P.H., Koltun, V., 2021. Point Transformer, in: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp. 16259–16268. Francesc Levrero-Florencio et al.:Preprint submitted to ElsevierPage 17 of 17
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.