Recognition: no theorem link
RelAgent: LLM Agents as Data Scientists for Relational Learning
Pith reviewed 2026-05-11 02:30 UTC · model grok-4.3
The pith
An LLM agent builds SQL feature programs and classical models that perform relational learning without further AI involvement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RelAgent is an LLM-based autonomous data scientist for relational learning that runs in two phases. During search, the agent uses database, validation, and evaluation workspace tools to construct SQL feature programs and choose a predictive model. At inference time the program executes independently of any further LLM calls, so the final system consists only of SQL queries plus a classical model. This yields fast, deterministic predictions whose features are human-readable queries and whose outputs depend solely on the query-defined feature map.
What carries the argument
RelAgent, an LLM agent that uses database, validation, and evaluation workspace tools to construct SQL feature programs and select classical models.
Load-bearing premise
An LLM agent supplied with database access and evaluation tools can reliably produce effective SQL feature programs without human guidance or excessive trial-and-error.
What would settle it
On standard relational benchmarks, the SQL-plus-classical-model predictors generated by RelAgent consistently show lower accuracy than graph neural networks or relational transformers.
Figures




read the original abstract
Relational learning is a challenging problem that has motivated a wide range of approaches, including graph-based models (e.g., graph neural networks, graph transformers), tabular methods (e.g., tabular foundation models), and sequence-based approaches (e.g., large language models), each with its own advantages and limitations. We propose RelAgent, an LLM-based autonomous data scientist for relational learning, which operates in two phases. In the search phase, an LLM agent uses database, validation, and evaluation workspace tools to construct SQL feature programs and select a predictive model. In the inference phase, the resulting program is executed without further LLM calls. The final predictor consists of SQL queries and a classical model, enabling fast, deterministic, and intrinsically interpretable predictions: features are human-readable queries, and predictions depend only on the resulting query-defined feature map, enabling scalable deployment using standard database systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes RelAgent, an LLM-based autonomous agent for relational learning. It operates in two phases: a search phase in which the agent uses database, validation, and evaluation workspace tools to construct SQL feature programs and select a classical predictive model, followed by an inference phase that executes the fixed SQL queries plus model deterministically with no further LLM calls. The central claim is that the resulting predictors are fast, deterministic, and intrinsically interpretable (human-readable SQL features) while matching or exceeding specialized relational models such as graph neural networks, and that they enable scalable deployment on standard database systems.
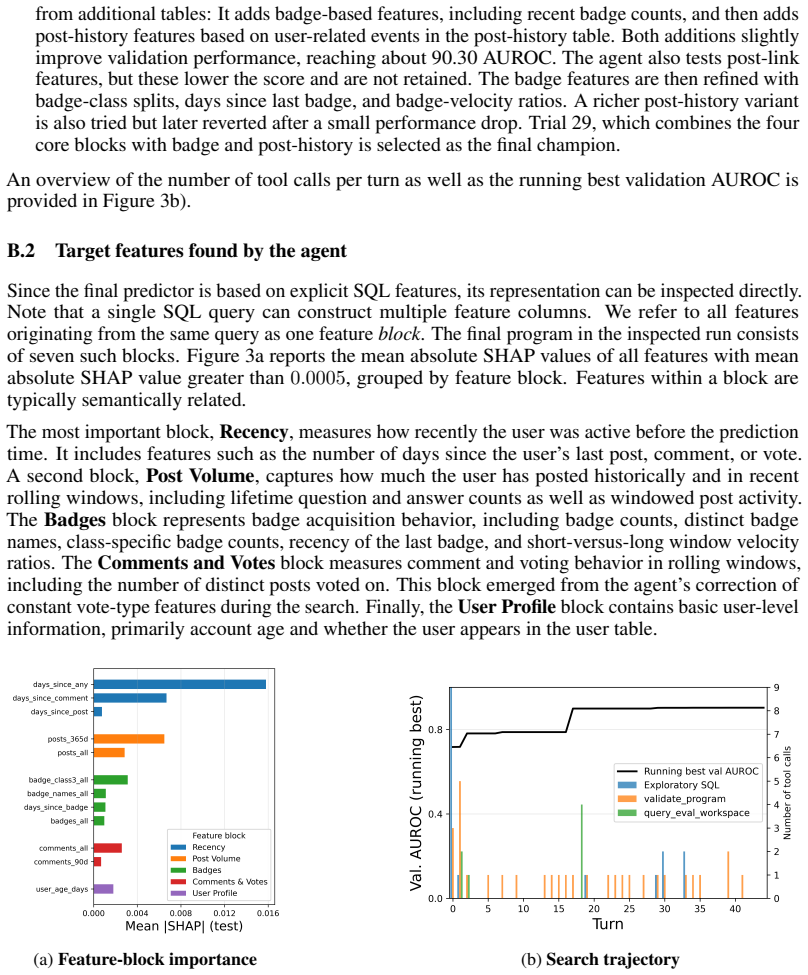
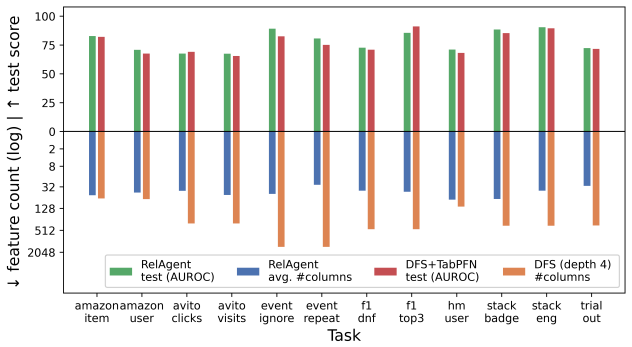
Significance. If the empirical performance claims hold, RelAgent could provide a practical bridge between LLM-driven feature discovery and the efficiency/interpretability of classical SQL-based models, addressing scalability and deployment limitations of graph-based and tabular foundation models. The two-phase design (search then deterministic execution) is a clear strength for production use. However, the significance remains prospective because the manuscript contains no experiments, datasets, baselines, or quantitative results to substantiate that the agent reliably produces competitive SQL features.
major comments (2)
- [Abstract and Section 3 (Architecture)] The core claim that RelAgent yields predictors matching or exceeding specialized relational models (abstract, final paragraph) depends entirely on the LLM agent's ability to discover effective SQL feature programs without human guidance. No experiments, ablation studies, datasets, baselines (e.g., GNNs, relational tabular models), or performance metrics are reported anywhere in the manuscript, leaving the weakest assumption untested and the interpretability/scalability benefits unsupported.
- [Section 3 (Inference Phase)] The inference-phase claim that predictions 'depend only on the resulting query-defined feature map' and are 'intrinsically interpretable' (abstract) is not demonstrated; without any reported feature programs, model choices, or validation results, it is impossible to verify whether the constructed SQL features are human-readable or whether the classical model actually outperforms alternatives.
minor comments (2)
- [Section 3 (Tool Design)] Provide concrete examples of the database, validation, and evaluation workspace tool interfaces, including sample tool calls, expected outputs, and how the agent iterates on failed SQL programs.
- [Section 2] Add a related-work subsection comparing RelAgent to prior LLM agents for automated feature engineering, AutoML systems, and SQL-based relational learning methods.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We agree that the current manuscript is a methodological description of the RelAgent architecture and two-phase design, without empirical results, and that this limits substantiation of the performance and interpretability claims. We will revise the manuscript to address these gaps by adding experiments, examples, and comparisons.
read point-by-point responses
-
Referee: [Abstract and Section 3 (Architecture)] The core claim that RelAgent yields predictors matching or exceeding specialized relational models (abstract, final paragraph) depends entirely on the LLM agent's ability to discover effective SQL feature programs without human guidance. No experiments, ablation studies, datasets, baselines (e.g., GNNs, relational tabular models), or performance metrics are reported anywhere in the manuscript, leaving the weakest assumption untested and the interpretability/scalability benefits unsupported.
Authors: We agree that the manuscript does not contain experiments, datasets, baselines, or quantitative results, and that the performance claims therefore remain untested. The work focuses on the system design, tool interfaces, and the search-then-deterministic-execution structure. In the revision we will add an experimental section reporting results on standard relational benchmarks, direct comparisons to GNNs and relational tabular models, and ablations on the agent's search components to evaluate feature-program quality. revision: yes
-
Referee: [Section 3 (Inference Phase)] The inference-phase claim that predictions 'depend only on the resulting query-defined feature map' and are 'intrinsically interpretable' (abstract) is not demonstrated; without any reported feature programs, model choices, or validation results, it is impossible to verify whether the constructed SQL features are human-readable or whether the classical model actually outperforms alternatives.
Authors: We concur that the interpretability and determinism claims require concrete illustration. The manuscript describes the inference phase at the architectural level but provides no example SQL programs or model selections. In the revision we will augment Section 3 with representative SQL feature programs produced by the agent, the classical models chosen, and qualitative discussion of their readability, together with any supporting validation metrics from our internal development. revision: yes
Circularity Check
No circularity: system proposal without derivations or fitted quantities
full rationale
The manuscript describes a two-phase LLM-agent architecture for generating SQL feature programs and classical models for relational learning. No equations, parameter fits, predictions derived from inputs, or self-citation chains appear in the provided text. The central claims concern the interpretability and scalability of the resulting SQL+model predictor, which are presented as consequences of the design rather than reductions to fitted values or prior self-citations. The validity is explicitly deferred to future empirical validation, consistent with a non-circular system proposal.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM agents can reliably use database and evaluation tools to discover useful SQL feature programs for downstream prediction tasks
invented entities (1)
-
RelAgent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A relational model of data for large shared data banks.Communications of the ACM, 1970
Edgar F Codd. A relational model of data for large shared data banks.Communications of the ACM, 1970
work page 1970
-
[2]
J. Robinson, R. Ranjan, W. Hu, K. Huang, J. Han, A. Dobles, M. Fey, J. E. Lenssen, Y . Yuan, Z. Zhang, X. He, and J. Leskovec. RelBench: A benchmark for deep learning on relational databases. InNeurIPS, 2024
work page 2024
-
[3]
Justin Gu, Rishabh Ranjan, Charilaos Kanatsoulis, Haiming Tang, Martin Jurkovic, Valter Hudovernik, Mark Znidar, Pranshu Chaturvedi, Parth Shroff, Fengyu Li, et al. Relbench v2: A large-scale benchmark and repository for relational data.arXiv preprint arXiv:2602.12606, 2026
work page internal anchor Pith review arXiv 2026
-
[4]
Deep feature synthesis: Towards automating data science endeavors
James Max Kanter and Kalyan Veeramachaneni. Deep feature synthesis: Towards automating data science endeavors. In2015 IEEE international conference on data science and advanced analytics (DSAA). IEEE, 2015
work page 2015
-
[5]
Xgboost: A scalable tree boosting system
Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system. InProceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, 2016
work page 2016
-
[6]
G. Ke, Q. Meng, T. Finley, T. Wang, W. Chen, W. Ma, Q. Ye, and T. Liu. LightGBM: A highly efficient gradient boosting decision tree. InNeurIPS, 2017
work page 2017
-
[7]
N. Erickson, J. Mueller, A. Shirkov, H. Zhang, P. Larroy, M. Li, and A. Smola. AutoGluon- Tabular: Robust and accurate automl for structured data.CoRR, 2020
work page 2020
-
[8]
N. Hollmann, S. Müller, L. Purucker, A. Krishnakumar, M. Körfer, S. B. Hoo, R. T. Schirrmeis- ter, and F. Hutter. Accurate predictions on small data with a tabular foundation model.Nature, 2025
work page 2025
-
[9]
Linjie Xu, Yanlin Zhang, Quan Gan, Minjie Wang, and David Wipf. No need to train your rdb foundation model.arXiv preprint arXiv:2602.13697, 2026
-
[10]
W. Hamilton, Z. Ying, and J. Leskovec. Inductive representation learning on large graphs. In NeurIPS, 2017
work page 2017
-
[11]
P. Veliˇckovi´c, G. Cucurull, A. Casanova, A. Romero, P. Liò, and Y . Bengio. Graph attention networks. InICLR, 2018
work page 2018
-
[12]
Kanatsoulis, Rishi Puri, Matthias Fey, and Jure Leskovec
Vijay Prakash Dwivedi, Sri Jaladi, Yangyi Shen, Federico Lopez, Charilaos I. Kanatsoulis, Rishi Puri, Matthias Fey, and Jure Leskovec. Relational graph transformer. InICLR, 2026
work page 2026
-
[13]
Rishabh Ranjan, Valter Hudovernik, Mark Znidar, Charilaos I. Kanatsoulis, Roshan Reddy Upendra, Mahmoud Mohammadi, Joe Meyer, Tom Palczewski, Carlos Guestrin, and Jure Leskovec. Relational transformer: Toward zero-shot foundation models for relational data. In ICLR, 2026
work page 2026
-
[14]
Griffin: Towards a graph-centric relational database foundation model
Yanbo Wang, Xiyuan Wang, Quan Gan, Minjie Wang, Qibin Yang, David Wipf, and Muhan Zhang. Griffin: Towards a graph-centric relational database foundation model. InICML, 2025
work page 2025
-
[15]
Kumorfm: A foundation model for in-context learning on relational data., 2025
Matthias Fey, Vid Kocijan, Federico Lopez, Jan Eric Lenssen, and Jure Leskovec. Kumorfm: A foundation model for in-context learning on relational data., 2025
work page 2025
-
[16]
KumoRFM-2: Scaling Foundation Models for Relational Learning
Valter Hudovernik, Federico López, Vid Kocijan, Akihiro Nitta, Jan Eric Lenssen, Jure Leskovec, and Matthias Fey. Kumorfm-2: Scaling foundation models for relational learning.arXiv preprint arXiv:2604.12596, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
M. Wydmuch, L. Borchmann, and F. Grali´nski. Tackling prediction tasks in relational databases with llms.CoRR, 2411.11829, 2024
-
[18]
Talk like a graph: Encoding graphs for large language models
Bahare Fatemi, Jonathan Halcrow, and Bryan Perozzi. Talk like a graph: Encoding graphs for large language models. InICLR, 2024. 10
work page 2024
-
[19]
Relgnn: Composite message passing for relational deep learning
Tianlang Chen, Charilaos Kanatsoulis, and Jure Leskovec. Relgnn: Composite message passing for relational deep learning. InICML, 2025
work page 2025
-
[20]
Ramprasath, Karan Paresh, Roshan U
Joe Meyer, Tom Palczewski, Afreen Shaikh, Mahmoud Mohammadi, Dinesh K. Ramprasath, Karan Paresh, Roshan U. Reddy, and Mark Li. Relational in-context learning on structured data via neighborhood aggregation and structural information. InProceedings of the AAAI-26 Summer Symposium Series: AI in Business: Intelligent Transformation and Management, 2026
work page 2026
-
[21]
Large language models are good relational learners
Fang Wu, Vijay Prakash Dwivedi, and Jure Leskovec. Large language models are good relational learners. InACL, 2025
work page 2025
-
[22]
Towards foundation models for knowledge graph reasoning
Mikhail Galkin, Xinyu Yuan, Hesham Mostafa, Jian Tang, and Zhaocheng Zhu. Towards foundation models for knowledge graph reasoning. InICLR, 2024
work page 2024
-
[23]
Bronstein, ˙Ismail ˙Ilkan Ceylan, Mikhail Galkin, Juan L Reutter, and Miguel Romero Orth
Xingyue Huang, Pablo Barceló, Michael M. Bronstein, ˙Ismail ˙Ilkan Ceylan, Mikhail Galkin, Juan L Reutter, and Miguel Romero Orth. How expressive are knowledge graph foundation models? InICML, 2025
work page 2025
-
[24]
Hyper: A foundation model for inductive link prediction with knowledge hypergraphs
Xingyue Huang, Mikhail Galkin, Michael M Bronstein, and Ismail Ilkan Ceylan. Hyper: A foundation model for inductive link prediction with knowledge hypergraphs. InICLR, 2026
work page 2026
-
[25]
TRIX: A more expressive model for zero-shot domain transfer in knowledge graphs
Yucheng Zhang, Beatrice Bevilacqua, Mikhail Galkin, and Bruno Ribeiro. TRIX: A more expressive model for zero-shot domain transfer in knowledge graphs. InLoG, 2024
work page 2024
-
[26]
Flock: A knowledge graph foundation model via learning on random walks
Jinwoo Kim, Xingyue Huang, Krzysztof Olejniczak, Kyungbin Min, Michael Bronstein, Se- unghoon Hong, and ˙Ismail ˙Ilkan Ceylan. Flock: A knowledge graph foundation model via learning on random walks. InICLR, 2026
work page 2026
-
[27]
Tabert: Pretraining for joint understanding of textual and tabular data
Pengcheng Yin, Graham Neubig, Wen-tau Yih, and Sebastian Riedel. Tabert: Pretraining for joint understanding of textual and tabular data. InACL, 2020
work page 2020
-
[28]
Tapex: Table pre-training via learning a neural sql executor
Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, and Jian-Guang Lou. Tapex: Table pre-training via learning a neural sql executor. InICLR, 2022
work page 2022
-
[29]
Tabllm: Few-shot classification of tabular data with large language models
Stefan Hegselmann, Alejandro Buendia, Hunter Lang, Monica Agrawal, Xiaoyi Jiang, and David Sontag. Tabllm: Few-shot classification of tabular data with large language models. In International Conference on Artificial Intelligence and Statistics, 2023
work page 2023
-
[30]
Din-sql: Decomposed in-context learning of text-to-sql with self-correction
Mohammadreza Pourreza and Davood Rafiei. Din-sql: Decomposed in-context learning of text-to-sql with self-correction. InNeurIPS, 2023
work page 2023
-
[31]
Graphgpt: graph instruction tuning for large language models
Jiabin Tang, Yuhao Yang, Wei Wei, Lei Shi, Lixin Su, Suqi Cheng, Dawei Yin, and Chao Huang. Graphgpt: graph instruction tuning for large language models. InSIGIR, 2024
work page 2024
-
[32]
Language is all a graph needs.EACL, 2024
Ruosong Ye, Caiqi Zhang, Runhui Wang, Shuyuan Xu, and Yongfeng Zhang. Language is all a graph needs.EACL, 2024
work page 2024
-
[33]
Graphicl: Unlocking graph learning potential in llms through structured prompt design
Yuanfu Sun, Zhengnan Ma, Yi Fang, Jing Ma, and Qiaoyu Tan. Graphicl: Unlocking graph learning potential in llms through structured prompt design. InFindings of the Association for Computational Linguistics: NAACL 2025, 2025
work page 2025
-
[34]
Let your graph do the talking: Encoding structured data for llms,
Bryan Perozzi, Bahare Fatemi, Dustin Zelle, Anton Tsitsulin, Mehran Kazemi, Rami Al-Rfou, and Jonathan Halcrow. Let your graph do the talking: Encoding structured data for llms.arXiv preprint arXiv:2402.05862, 2024
-
[35]
Llaga: Large language and graph assistant
Runjin Chen, Tong Zhao, Ajay Kumar Jaiswal, Neil Shah, and Zhangyang Wang. Llaga: Large language and graph assistant. InICML, 2024
work page 2024
-
[36]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InNeurIPS 2022 Foundation Models for Decision Making Workshop, 2022
work page 2022
-
[37]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. InNeurIPS, 2023. 11
work page 2023
-
[38]
Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models
Lei Wang, Wanyu Xu, Yihuai Lan, Zhiqiang Hu, Yunshi Lan, Roy Ka-Wei Lee, and Ee-Peng Lim. Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models. InACL, 2023
work page 2023
-
[39]
Reflexion: language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik R Narasimhan, and Shunyu Yao. Reflexion: language agents with verbal reinforcement learning. InNeurIPS, 2023
work page 2023
-
[40]
Rongzheng Wang, Shuang Liang, Qizhi Chen, Jiasheng Zhang, and Ke Qin. Graphtool- instruction: Revolutionizing graph reasoning in llms through decomposed subtask instruction. InKDD, 2025
work page 2025
-
[41]
Actions speak louder than prompts: A large-scale study of llms for graph inference
Ben Finkelshtein, Silviu Cucerzan, Sujay Kumar Jauhar, and Ryen W White. Actions speak louder than prompts: A large-scale study of llms for graph inference. InICLR, 2026
work page 2026
-
[42]
Noah Hollmann, Samuel Müller, and Frank Hutter. Large language models for automated data science: Introducing caafe for context-aware automated feature engineering. InNeurIPS, 2023
work page 2023
-
[43]
Large language models can automatically engineer features for few-shot tabular learning
Sungwon Han, Jinsung Yoon, Sercan O Arik, and Tomas Pfister. Large language models can automatically engineer features for few-shot tabular learning. InICML, 2024
work page 2024
-
[44]
LLM-FE: Automated Feature Engineering for Tabular Data with LLMs as Evolutionary Optimizers
Nikhil Abhyankar, Parshin Shojaee, and Chandan K Reddy. Llm-fe: Automated feature engi- neering for tabular data with llms as evolutionary optimizers.arXiv preprint arXiv:2503.14434, 2025
work page internal anchor Pith review arXiv 2025
-
[45]
Optimized feature generation for tabular data via LLMs with decision tree reasoning
Jaehyun Nam, Kyuyoung Kim, Seunghyuk Oh, Jihoon Tack, Jaehyung Kim, and Jinwoo Shin. Optimized feature generation for tabular data via LLMs with decision tree reasoning. In NeurIPS, 2024
work page 2024
-
[46]
Refuge: Feature generation for prediction tasks on relational databases with llm agents
Kyungho Kim, Geon Lee, Juyeon Kim, Dongwon Choi, Shinhwan Kang, and Kijung Shin. Refuge: Feature generation for prediction tasks on relational databases with llm agents. In Proceedings of the ACM Web Conference, 2026
work page 2026
-
[47]
4dbinfer: A 4d benchmarking toolbox for graph-centric predictive modeling on rdbs
Minjie Wang, Quan Gan, David Wipf, Zhenkun Cai, Ning Li, Jianheng Tang, Yanlin Zhang, Zizhao Zhang, Zunyao Mao, Yakun Song, et al. 4dbinfer: A 4d benchmarking toolbox for graph-centric predictive modeling on rdbs. InNeurIPS, 2024
work page 2024
- [48]
-
[49]
Heterogeneous graph transformer
Ziniu Hu, Yuxiao Dong, Kuansan Wang, and Yizhou Sun. Heterogeneous graph transformer. In Proceedings of The Web Conference 2020, 2020
work page 2020
-
[50]
OpenAI. Introducing gpt-5.2. https://openai.com/index/introducing-gpt-5-2/, 2025. Accessed: 2026-04-22
work page 2025
-
[51]
Camel: Communicative agents for" mind" exploration of large language model society
Guohao Li, Hasan Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. Camel: Communicative agents for" mind" exploration of large language model society. InNeurIPS, 2023
work page 2023
-
[52]
Hannes Mühleisen and Mark Raasveldt.duckdb: DBI Package for the DuckDB Database Management System, 2026
work page 2026
-
[53]
Random forests.Machine learning, 2001
Leo Breiman. Random forests.Machine learning, 2001
work page 2001
-
[54]
Dart: Dropouts meet multiple additive regression trees
R Gilad-Bachrach and K Rashmi. Dart: Dropouts meet multiple additive regression trees. In AIStats, 2015
work page 2015
-
[55]
CatBoost: unbiased boosting with categorical features
Liudmila Prokhorenkova, Gleb Gusev, Aleksandr V orobev, Anna Veronika Dorogush, and Andrey Gulin. Catboost: Unbiased boosting with categorical features.arXiv preprint arXiv:1706.09516, 2017
work page Pith review arXiv 2017
-
[56]
Deepseek-v4: Towards highly efficient million-token context in- telligence
DeepSeek-AI. Deepseek-v4: Towards highly efficient million-token context in- telligence. https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/ DeepSeek_V4.pdf, 2026. Technical report. 12
work page 2026
-
[57]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
DeepSeek. DeepSeek API pricing. https://api-docs.deepseek.com/quick_start/ pricing, 2026
work page 2026
-
[59]
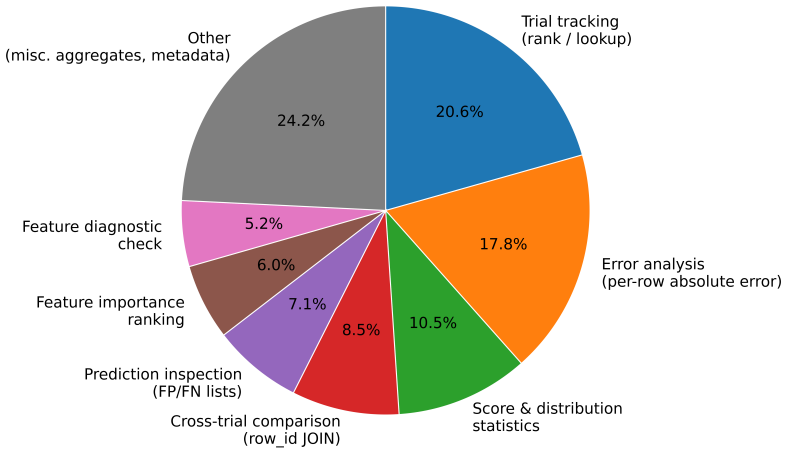
OpenAI. GPT-5.2 API pricing.https://openai.com/api/pricing/, 2026. 13 A Evaluation workspace details Theevaluation workspaceis a persistent DUCKDB database that accumulates trial results across the agent’s search phase. After each call tovalidate_program(), the harness writes the outcome to the workspace; the agent reads it back through query_eval_workspa...
work page 2026
-
[60]
SQL tools (execute_query, get_table_info, etc.) -- explore and query the database
-
[61]
validate_program(feature_queries_json, model_choice, model_config_json) -- train and evaluate your feature pipeline on the validation split 27
-
[62]
get_trial_history() -- see what you’ve already tried and their scores
-
[63]
Do NOT guess table/column names
query_eval_workspace(sql) -- analyze the evaluation workspace (trials, eval_predictions) Rules: - Use SQL tools to explore the database. Do NOT guess table/column names. - Start by running SHOW TABLES and PRAGMA table_info(’table’) to understand the schema. - train_table contains labeled training examples. Use it to learn patterns. - eval_table contains t...
-
[64]
"gbdt" -- Standard Gradient Boosted Trees. Fast, strong default. Config: n_estimators (50-500), learning_rate (0.01-0.3), max_depth (2-10), min_child_samples (1-100), subsample (0.5-1.0), colsample_bytree (0.5-1.0) Regularization: lambda_l1 (0.0-10.0), lambda_l2 (0.0-10.0)
-
[65]
"rf" -- Random Forest (bagging; less sensitive to learning rate). Config: same keys as gbdt
-
[66]
"dart" -- DART Boosting (dropout regularization). Config: same keys as gbdt
-
[67]
"goss" -- GOSS (gradient-based subsampling; fast on large datasets). Config: same keys as gbdt
-
[68]
"xgboost" -- XGBoost (second-order gradients; different regularization). Config: n_estimators (50-500), learning_rate (0.01-0.3), max_depth (2-10), min_child_weight (1-100), subsample (0.5-1.0), colsample_bytree (0.5-1.0) Regularization: reg_alpha (0.0-10.0), reg_lambda (0.0-10.0)
- [69]
-
[70]
"catboost" -- CatBoost (ordered boosting; robust on heterogeneous features). Config: n_estimators (50-500), learning_rate (0.01-0.3), max_depth (2-10), l2_leaf_reg (0.1-10.0) Categorical features (all 7 learners): Add "categorical_features" inside model_config_json as a list of "<query_name>__<col>" names to treat columns natively as categorical. High-car...
-
[71]
"gbdt" -- Standard Gradient Boosted Trees. Fast, strong default. Config: n_estimators (50-500), learning_rate (0.01-0.3), max_depth (2-10), min_child_samples (1-100), subsample (0.5-1.0), colsample_bytree (0.5-1.0) objective: "regression_l1" (MAE), "regression_l2" (MSE), "huber" Default: "regression_l1" -- directly minimises eval metric
-
[72]
Config: same keys as gbdt (including objective)
"rf" -- Random Forest (bagging; less sensitive to learning rate). Config: same keys as gbdt (including objective)
-
[73]
Config: same keys as gbdt (including objective)
"dart" -- DART Boosting (dropout regularization). Config: same keys as gbdt (including objective)
-
[74]
Config: same keys as gbdt (including objective)
"goss" -- GOSS (gradient-based subsampling; fast on large datasets). Config: same keys as gbdt (including objective)
-
[75]
"xgboost" -- XGBoost (second-order gradients). Config: n_estimators (50-500), learning_rate (0.01-0.3), max_depth (2-10), min_child_weight (1-100), subsample (0.5-1.0), colsample_bytree (0.5-1.0) objective: "reg:absoluteerror" (MAE), "reg:squarederror" (MSE), "reg:pseudohubererror" (Huber)
- [76]
-
[77]
"catboost" -- CatBoost (ordered boosting). Config: n_estimators (50-500), learning_rate (0.01-0.3), max_depth (2-10), l2_leaf_reg (0.1-10.0) For skewed targets: add "log_transform_target": true to model_config_json. The harness fits on log1p(y) and reports MAE back in the original scale. Categorical features (all 7 learners): Add "categorical_features" in...
-
[78]
Run SHOW TABLES to see available tables
-
[79]
Run PRAGMA table_info(’train_table’) and inspect other tables
-
[80]
Explore data distributions (SELECT COUNT(*), sample rows, etc.) 30
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.