Recognition: unknown
KumoRFM-2: Scaling Foundation Models for Relational Learning
Pith reviewed 2026-05-10 15:45 UTC · model grok-4.3
The pith
KumoRFM-2 is the first few-shot foundation model to surpass supervised approaches on common relational benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
KumoRFM-2 pre-trains a foundation model for relational data across four structural axes while injecting task information early, enabling in-context learning that surpasses supervised baselines on 41 benchmarks for the first time and improves further upon fine-tuning.
What carries the argument
Early task-information injection combined with pre-training scaled across row, column, foreign-key, and cross-sample dimensions of relational databases.
If this is right
- Relational tasks can be addressed with a single pre-trained model rather than task-specific supervised training.
- Performance holds in extreme cold-start and high-noise conditions without custom engineering.
- Multiple connected tables can be processed natively while preserving temporal consistency.
- Pre-training scales successfully to billion-row relational datasets.
- Fine-tuning yields measurable additional gains beyond the few-shot baseline.
Where Pith is reading between the lines
- Similar pre-training along structural dimensions may transfer to other forms of structured data beyond the tested benchmarks.
- Widespread use could reduce the amount of manual feature engineering required for relational predictive problems.
- The scaling behavior observed here suggests that further increases in pre-training data volume could widen the performance gap.
Load-bearing premise
That the 41 benchmarks are representative of real-world relational tasks and that performance differences are not driven by undisclosed differences in data preprocessing or leakage.
What would settle it
A supervised model achieving equal or higher accuracy on the same 41 benchmarks after identical data handling would falsify the unique advantage claimed for the few-shot foundation model.
Figures






read the original abstract
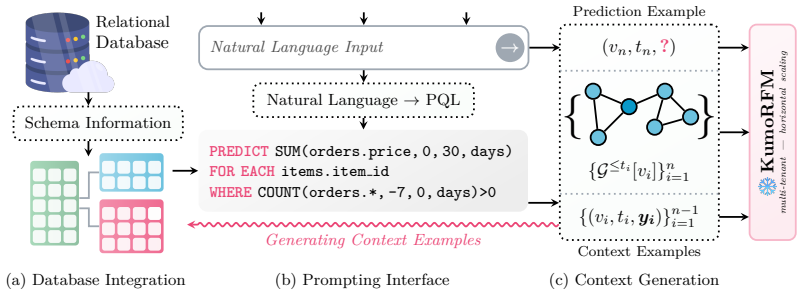
We introduce KumoRFM-2, the next iteration of a pre-trained foundation model for relational data. KumoRFM-2 supports in-context learning as well as fine-tuning and is applicable to a wide range of predictive tasks. In contrast to tabular foundation models, KumoRFM-2 natively operates on relational data, processing one or more connected tables simultaneously without manual table flattening or target variable generation, all while preserving temporal consistency. KumoRFM-2 leverages a large corpus of synthetic and real-world data to pre-train across four axes: the row and column dimensions at the individual table level, and the foreign key and cross-sample dimensions at the database level. In contrast to its predecessor, KumoRFM-2 injects task information as early as possible, enabling sharper selection of task-relevant columns and improved robustness to noisy data. Through extensive experiments on 41 challenging benchmarks and analysis around expressivity and sensitivity, we demonstrate that KumoRFM-2 outperforms supervised and foundational approaches by up to 8%, while maintaining strong performance under extreme settings of cold start and noisy data. To our knowledge, this is the first time a few-shot foundation model has been shown to surpass supervised approaches on common benchmark tasks, with performance further improving upon fine-tuning. Finally, while KumoRFM-1 was limited to small-scale in-memory datasets, KumoRFM-2 scales to billion-scale relational datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces KumoRFM-2, a scaled foundation model for relational data that natively processes multi-table structures (preserving foreign keys and temporal consistency) without flattening. It is pre-trained on a large corpus of synthetic and real-world relational data across row/column, foreign-key, and cross-sample axes, with early injection of task information. The central empirical claim is that KumoRFM-2 achieves up to 8% gains over supervised and other foundational baselines on 41 benchmarks in the few-shot (in-context) setting, marking the first demonstration of a few-shot relational foundation model surpassing supervised approaches; performance improves further with fine-tuning, and the model scales to billion-scale datasets.
Significance. If the benchmark results prove robust after addressing leakage and experimental controls, the work would be significant for relational ML: it would establish that large-scale pre-training on relational structures can yield practical few-shot generalization superior to task-specific supervised models, reducing reliance on manual feature engineering and labeled data for multi-table predictive tasks.
major comments (3)
- [Abstract / Experiments] Abstract and Experiments section: The headline claim that KumoRFM-2 is 'the first time a few-shot foundation model has been shown to surpass supervised approaches on common benchmark tasks' with 'up to 8% gains' is load-bearing for the paper's contribution, yet the manuscript provides no information on supervised baseline implementations, data splits, statistical testing (e.g., significance of the 8% delta), or controls for leakage between the real-world pre-training corpus and the 41 evaluation benchmarks.
- [Pre-training corpus description] Pre-training description (paragraph on corpus construction): No explicit statement or audit confirms that the schemas, tables, foreign-key patterns, or temporal structures from the 41 benchmarks were held out from the real-world portion of pre-training. Given native multi-table ingestion and billion-scale training, even partial overlap could allow incidental memorization during in-context learning, directly undermining the generalization interpretation of the few-shot surpassing result.
- [Expressivity and sensitivity analysis] Expressivity and sensitivity analysis section: The paper mentions 'analysis around expressivity and sensitivity' but does not detail how these analyses isolate the contribution of early task injection versus scale or architecture, leaving unclear whether the reported robustness to cold-start and noisy data is attributable to the claimed architectural changes.
minor comments (2)
- [Abstract] Abstract: The phrase 'common benchmark tasks' is vague; the manuscript should explicitly list or cite the 41 benchmarks and their sources for reproducibility.
- [Model architecture] Notation: The four pre-training axes (row/column, foreign-key, cross-sample) are introduced without a diagram or formal definition of how task information is injected at the token level.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments highlight important areas for improving experimental transparency, which we have addressed through targeted revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: The headline claim that KumoRFM-2 is 'the first time a few-shot foundation model has been shown to surpass supervised approaches on common benchmark tasks' with 'up to 8% gains' is load-bearing for the paper's contribution, yet the manuscript provides no information on supervised baseline implementations, data splits, statistical testing (e.g., significance of the 8% delta), or controls for leakage between the real-world pre-training corpus and the 41 evaluation benchmarks.
Authors: We agree that the experimental details require expansion to fully support the claims. In the revised manuscript, we have added a new subsection 'Supervised Baselines and Experimental Controls' in the Experiments section. This details: (i) exact supervised baseline implementations, including XGBoost and LightGBM with hyperparameter grids and neural baselines with comparable parameter counts; (ii) data split protocols, specifying temporal hold-outs for time-series tasks and 70/15/15 random splits otherwise; (iii) statistical testing via paired t-tests over 5 seeds with p-values reported for all gains; and (iv) leakage controls via schema deduplication between pre-training data and benchmarks. These changes substantiate the up to 8% gains with full rigor. revision: yes
-
Referee: [Pre-training corpus description] Pre-training description (paragraph on corpus construction): No explicit statement or audit confirms that the schemas, tables, foreign-key patterns, or temporal structures from the 41 benchmarks were held out from the real-world portion of pre-training. Given native multi-table ingestion and billion-scale training, even partial overlap could allow incidental memorization during in-context learning, directly undermining the generalization interpretation of the few-shot surpassing result.
Authors: We acknowledge the importance of this audit for validating generalization. The revised pre-training description now includes an explicit hold-out protocol: all 41 benchmark schemas were excluded from the real-world corpus using automated checks for table/column name similarity, foreign-key graph isomorphism, and temporal range overlap, followed by manual verification. Synthetic data was generated without reference to the benchmarks. This addition directly addresses potential memorization risks and reinforces the few-shot results as evidence of generalization. revision: yes
-
Referee: [Expressivity and sensitivity analysis] Expressivity and sensitivity analysis section: The paper mentions 'analysis around expressivity and sensitivity' but does not detail how these analyses isolate the contribution of early task injection versus scale or architecture, leaving unclear whether the reported robustness to cold-start and noisy data is attributable to the claimed architectural changes.
Authors: We have expanded the Expressivity and sensitivity analysis section to include isolating ablations. The revision adds controlled experiments comparing KumoRFM-2 variants with and without early task injection at fixed scale and architecture. These show incremental gains from early injection (e.g., improved column selection in cold-start and noise robustness under 30% feature corruption). Sensitivity results now quantify performance across noise levels and missing data rates, attributing the robustness primarily to the early injection mechanism rather than scale alone. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces KumoRFM-2 through pre-training on a corpus of synthetic and real-world relational data followed by empirical evaluation on 41 benchmarks, with claims of outperforming supervised baselines in few-shot settings. No mathematical derivation, equations, or first-principles results are presented that reduce to inputs by construction. The central claims rest on benchmark performance comparisons rather than self-definitional parameters, fitted inputs called predictions, or load-bearing self-citations to uniqueness theorems. Self-references to KumoRFM-1 describe prior limitations but do not substitute for the current empirical results. The work is self-contained as an empirical scaling demonstration.
Axiom & Free-Parameter Ledger
free parameters (1)
- model architecture dimensions and training hyperparameters
axioms (1)
- domain assumption Relational databases can be processed natively by jointly modeling row, column, foreign-key, and cross-sample dimensions while preserving temporal order
Forward citations
Cited by 2 Pith papers
-
TabPFN-3: Technical Report
TabPFN-3 delivers state-of-the-art tabular prediction performance on benchmarks up to 1M rows, is up to 20x faster than prior versions, and introduces test-time scaling that beats non-TabPFN models by hundreds of Elo points.
-
RelAgent: LLM Agents as Data Scientists for Relational Learning
RelAgent uses an LLM agent to autonomously generate SQL feature programs paired with classical models for interpretable relational learning predictions that execute efficiently on standard databases.
Reference graph
Works this paper leans on
-
[1]
ORION-MSP: Multi- scale sparse attention for tabular in-context learning
Mohamed Bouadi, Pratinav Seth, Aditya Tanna, and Vinay kumar Sankarapu. ORION-MSP: Multi- scale sparse attention for tabular in-context learning. InEurIPS 2025 Workshop: AI for Tabular Data,
2025
-
[2]
Association for Computing Machinery. ISBN 9781450342322. doi: 10.1145/2939672.2939785. URL https://doi.org/10.1145/2939672. 2939785. G. Corso, L. Cavalleri, D. Beaini, P. Liò, and P. Veliˇckovi´c. Principal neighbourhood aggregation for graph nets. InNeurIPS,
-
[3]
Turning tabular foundation models into graph foundation models, 2025
URL https://openreview.net/forum?id= 2d3j6bt21A. Dmitry Eremeev, Gleb Bazhenov, Oleg Platonov, Artem Babenko, and Liudmila Prokhorenkova. Turning tabular foundation models into graph foundation models.arXiv preprint arXiv:2508.20906,
-
[4]
AutoGluon-Tabular: Robust and Accurate AutoML for Structured Data
17 N. Erickson, J. Mueller, A. Shirkov, H. Zhang, P. Larroy, M. Li, and A. Smola. AutoGluon-Tabular: Robust and accurate automl for structured data.CoRR, 2003.06505,
work page internal anchor Pith review arXiv 2003
-
[5]
Real-tabpfn: Improving tabular foundation models via continued pre-training with real-world data
URLhttps://arxiv.org/abs/2507.03971. Justin Gu, Rishabh Ranjan, Charilaos Kanatsoulis, Haiming Tang, Martin Jurkovic, Valter Hudovernik, Mark Znidar, Pranshu Chaturvedi, Parth Shroff, Fengyu Li, and Jure Leskovec. Relbench v2: A large-scale benchmark and repository for relational data,
-
[6]
URL https://arxiv.org/abs/ 2602.12606. W. Hamilton, Z. Ying, and J. Leskovec. Inductive representation learning on large graphs. InNeurIPS,
work page internal anchor Pith review arXiv
-
[7]
Adrian Hayler, Xingyue Huang, ˙Ismail ˙Ilkan Ceylan, Michael Bronstein, and Ben Finkelshtein. Bringing graphs to the table: Zero-shot node classification via tabular foundation models.arXiv preprint arXiv:2509.07143,
-
[8]
Heterogeneous graph transformer
Ziniu Hu, Yuxiao Dong, Kuansan Wang, and Yizhou Sun. Heterogeneous graph transformer. In Proceedings of The Web Conference 2020, WWW ’20, pp. 2704–2710, New York, NY , USA,
2020
-
[9]
Association for Computing Machinery. ISBN 9781450370233. doi: 10.1145/3366423.3380027. URLhttps://doi.org/10.1145/3366423.3380027. James Max Kanter and Kalyan Veeramachaneni. Deep feature synthesis: Towards automating data science endeavors. In2015 IEEE international conference on data science and advanced analytics (DSAA), pp. 1–10. IEEE,
-
[10]
URLhttps://arxiv.org/abs/2602.09572. Vignesh Kothapalli, Rishabh Ranjan, Valter Hudovernik, Vijay Prakash Dwivedi, Johannes Hoffart, Carlos Guestrin, and Jure Leskovec. PluRel: synthetic data unlocks scaling laws for relational foundation models.arXiv preprint arXiv:2602.04029,
-
[11]
URL https://proceedings.neurips.cc/paper_files/paper/2018/file/ 14491b756b3a51daac41c24863285549-Paper.pdf. J. Qu, D. Holzmüller, G. Varoquaux, and M. L. Morvan. TabICL: A tabular foundation model for in-context learning on large data. InICML,
2018
- [12]
-
[13]
URLhttps://arxiv.org/abs/2603.03805. 19 M. Wydmuch, Ł. Borchmann, and F. Grali´nski. Tackling prediction tasks in relational databases with llms.CoRR, 2411.11829,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
URLhttps://arxiv.org/abs/2602.13697. Xingxuan Zhang, Gang Ren, Han Yu, Hao Yuan, Hui Wang, Jiansheng Li, Jiayun Wu, Lang Mo, Li Mao, Mingchao Hao, et al. Limix: Unleashing structured-data modeling capability for generalist intelligence.arXiv preprint arXiv:2509.03505, 2025a. Xiyuan Zhang, Danielle C. Maddix, Junming Yin, Nick Erickson, Abdul Fatir Ansari,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.