Recognition: no theorem link
BRIDGE: Background Routing and Isolated Discrete Gating for Coarse-Mask Local Editing
Pith reviewed 2026-05-12 03:47 UTC · model grok-4.3
The pith
BRIDGE uses background routing and a discrete geometric gate to stop coarse masks from dictating the shape of edited objects in image generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BRIDGE keeps masks outside the DiT backbone for support construction and blending, generates content via BridgePath with a Main Path that preserves background context from independent noise and a Subject Path for editable content, and introduces a learnable Discrete Geometric Gate that performs token-level positional-embedding routing so subject tokens can borrow background-anchored coordinates near fusion regions or keep subject-centric coordinates for geometric freedom.
What carries the argument
The Discrete Geometric Gate, which routes positional embeddings at the token level under the Two-Zone Constraint to control whether subject tokens inherit background coordinates or retain independent ones.
If this is right
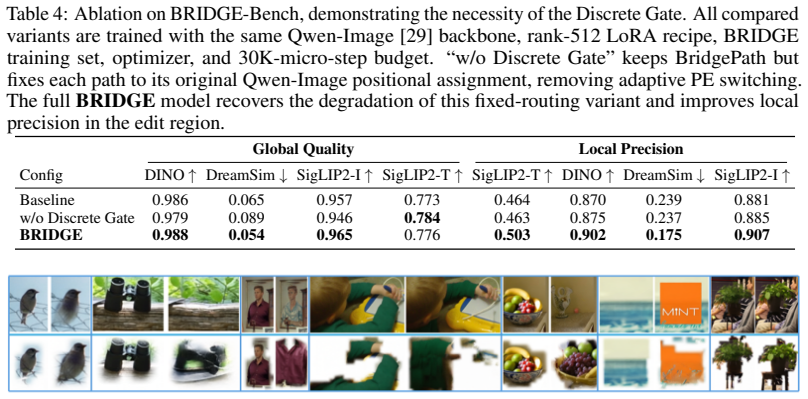
- Local SigLIP2-T rises from 0.262 with FLUX.1-Fill and 0.390 with ACE++ to 0.503 on BRIDGE-Bench, with parallel gains in local DINO and DreamSim.
- Zero-shot transfer yields competitive alignment and source preservation on MagicBrush and ICE-Bench.
- The routing module adds only 13.31M parameters instead of requiring copied ControlNet-style branches.
- Masks remain external to the DiT backbone, avoiding internal mask injection while still supporting blending.
Where Pith is reading between the lines
- The routing idea could extend to video or 3D editing tasks where coarse user annotations similarly risk imposing unwanted geometry.
- If the gate generalizes across backbones, it might reduce reliance on precise mask drawing tools in consumer editing apps.
- The separation of Main and Subject Paths suggests a broader pattern for preserving context in other conditional generation settings.
Load-bearing premise
The assumption that mask-shape bias from positional embeddings and attention connectivity is the dominant failure mode and that the discrete geometric gate will reliably prevent shape inheritance without introducing new artifacts or lowering overall image quality.
What would settle it
An ablation study on BRIDGE-Bench in which removing or disabling the Discrete Geometric Gate causes local SigLIP2-T, DINO, and DreamSim scores to fall back to the levels achieved by FLUX.1-Fill or ACE++ baselines.
Figures














read the original abstract
Coarse-mask local image editing asks a model to modify a user-indicated region while preserving the surrounding scene. In practice, however, rough masks often become unintended shape priors: instead of serving as flexible edit support, the mask can pull the generated object toward its accidental boundary. We study this failure as mask-shape bias and frame the task through a Two-Zone Constraint, where the background should remain stable while the editable region should follow the instruction without being forced to inherit the mask contour. BRIDGE addresses this setting by keeping masks outside the DiT backbone for support construction and blending, avoiding DiT-internal mask injection and copied control branches. It uses BridgePath generation, where a Main Path preserves background context and a Subject Path generates editable content from independent noise. Motivated by a diagnostic Qwen-Image experiment showing that positional embeddings and attention connectivity regulate which image context visual tokens reuse, BRIDGE introduces a learnable Discrete Geometric Gate for token-level positional-embedding routing. This gate lets subject tokens borrow background-anchored coordinates near fusion regions or keep subject-centric coordinates for geometric freedom. We evaluate BRIDGE on BRIDGE-Bench, MagicBrush, and ICE-Bench. On BRIDGE-Bench, BRIDGE improves Local SigLIP2-T from 0.262 with FLUX.1-Fill and 0.390 with ACE++ to 0.503, with parallel gains in local DINO and DreamSim. Zero-shot results on MagicBrush and ICE-Bench further indicate competitive alignment and source preservation beyond the curated benchmark, while the added routing module remains compact at 13.31M parameters compared with ControlNet-style copied branches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes BRIDGE to mitigate mask-shape bias in coarse-mask local image editing with DiT backbones. It frames the problem via a Two-Zone Constraint (stable background, instruction-following edit region free of mask contour inheritance), keeps masks outside the backbone, generates content via dual BridgePath (Main Path preserving background context, Subject Path from independent noise), and introduces a compact learnable Discrete Geometric Gate that routes positional embeddings at token level to control geometric freedom near fusion boundaries. Reported results show gains on BRIDGE-Bench (Local SigLIP2-T from 0.262/0.390 to 0.503 vs. FLUX.1-Fill/ACE++), with competitive zero-shot performance on MagicBrush and ICE-Bench and only 13.31M added parameters.
Significance. If the gains are robust and attributable to the routing mechanism rather than the dual-path construction alone, BRIDGE offers a lightweight alternative to copied ControlNet branches for practical local editing, with potential to reduce unintended shape inheritance while preserving source fidelity.
major comments (2)
- [Motivation and Diagnostic Experiment] Motivation section (diagnostic Qwen-Image experiment): the Discrete Geometric Gate is motivated by positional-embedding and attention-connectivity effects observed in Qwen-Image, yet the target backbone is DiT (e.g., FLUX.1-Fill) with different attention patterns and noise schedules; no ablation or transfer experiment demonstrates that the same mask-shape bias mechanism dominates in the evaluated models or that the gate, rather than BridgePath itself, drives the reported metric lifts.
- [Experiments and Results] Experimental evaluation: the abstract and results report benchmark improvements without detailing controls for the Two-Zone Constraint during training, statistical significance of the gains, or isolation of the gate's contribution via ablations against a BridgePath-only baseline; this leaves open whether the central claim holds or whether gains stem from unablated design choices.
minor comments (1)
- [Abstract] Abstract: the phrase 'parallel gains in local DINO and DreamSim' is stated without the corresponding numerical values or exact baseline comparisons, reducing clarity.
Simulated Author's Rebuttal
We appreciate the referee's detailed feedback on our manuscript. We address the major comments point by point below and outline the revisions we plan to make.
read point-by-point responses
-
Referee: [Motivation and Diagnostic Experiment] Motivation section (diagnostic Qwen-Image experiment): the Discrete Geometric Gate is motivated by positional-embedding and attention-connectivity effects observed in Qwen-Image, yet the target backbone is DiT (e.g., FLUX.1-Fill) with different attention patterns and noise schedules; no ablation or transfer experiment demonstrates that the same mask-shape bias mechanism dominates in the evaluated models or that the gate, rather than BridgePath itself, drives the reported metric lifts.
Authors: We thank the referee for highlighting this important point regarding the transferability of our diagnostic insights. The diagnostic experiment on Qwen-Image was intended to illustrate the general role of positional embeddings in regulating context reuse via attention, which is a fundamental property of transformer-based models including DiTs. While attention patterns and noise schedules differ, the core mechanism of mask-shape bias through positional anchoring is expected to persist. Nevertheless, we agree that a direct diagnostic or ablation on the DiT backbone would provide stronger evidence. In the revised manuscript, we will include a transfer experiment or additional analysis on FLUX.1-Fill to confirm the mechanism and better isolate the gate's contribution from the BridgePath construction. revision: partial
-
Referee: [Experiments and Results] Experimental evaluation: the abstract and results report benchmark improvements without detailing controls for the Two-Zone Constraint during training, statistical significance of the gains, or isolation of the gate's contribution via ablations against a BridgePath-only baseline; this leaves open whether the central claim holds or whether gains stem from unablated design choices.
Authors: We acknowledge the need for greater rigor in our experimental reporting. Regarding controls for the Two-Zone Constraint, we will expand the methods section to detail how the constraint was enforced during training, including any specific loss terms or data sampling strategies. For statistical significance, we will report standard deviations across multiple runs or compute p-values for the observed improvements. Most importantly, to isolate the Discrete Geometric Gate's contribution, we will add an ablation study comparing the full BRIDGE model against a BridgePath-only variant without the gate. These additions will clarify that the reported gains are attributable to the proposed routing mechanism. revision: yes
Circularity Check
No circularity: empirical method with independent benchmark results
full rationale
The paper introduces BRIDGE as a new architecture (BridgePath with Main/Subject paths plus learnable Discrete Geometric Gate) motivated by an internal diagnostic experiment on Qwen-Image. All reported outcomes are direct empirical scores on BRIDGE-Bench (Local SigLIP2-T rising from 0.262/0.390 baselines to 0.503), MagicBrush, and ICE-Bench. No equations, fitted parameters renamed as predictions, or self-citation chains appear that would make any claimed improvement equivalent to the method's own inputs by construction. The Two-Zone Constraint framing and gate design are presented as novel contributions evaluated against external baselines (FLUX.1-Fill, ACE++), keeping the derivation chain self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
O. Avrahami, O. Fried, and D. Lischinski. Blended latent diffusion.ACM Transactions on Graphics (TOG), 42(4):1–11, 2023
work page 2023
-
[2]
S. Bai, Y . Cai, R. Chen, K. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, W. Ge, Z. Guo, J. Huang, F. Huang, B. Hui, S. Jiang, Z. Li, M. Li, M. Li, X. Chen, Q. Huang, K. Li, and Z. Lin. Qwen3-VL technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
S. Batifol, A. Blattmann, F. Boesel, S. Consul, C. Diagne, T. Dockhorn, J. English, Z. English, P. Esser, S. Kulal, K. Lacey, Y . Levi, C. Li, D. Lorenz, J. Müller, D. Podell, R. Rombach, H. Saini, A. Sauer, and L. Smith. FLUX.1 Kontext: Flow Matching for in-context image generation and editing in latent space.arXiv preprint arXiv:2506.15742, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Y . Bengio, N. Léonard, and A. Courville. Estimating or propagating gradients through stochastic neurons for conditional computation.arXiv preprint arXiv:1308.3432, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
- [5]
-
[6]
M. Cao, Y . Wang, N. Sebe, and D. de Geus. MasaCtrl: Tuning-free mutual self-attention control for consistent image synthesis and editing. InICCV, 2023
work page 2023
-
[7]
N. Carion, L. Gustafson, Y .-T. Hu, S. Debnath, R. Hu, D. Suris, C. Ryali, K. V . Alwala, H. Khedr, A. Huang, J. Lei, T. Ma, B. Guo, A. Kalla, M. Marks, J. Greer, M. Wang, P. Sun, R. Rädle, T. Afouras, E. Mavroudi, K. Xu, et al. SAM 3: Segment anything with concepts. InICLR, 2026
work page 2026
-
[8]
G. Couairon, T. Lefort, A. Kadkhodamohammadi, O. Clercq, L. Sigal, and J.-F. Lalonde. DiffEdit: Diffusion-based semantic image editing with mask guidance. InICLR, 2023
work page 2023
-
[9]
A. Defazio, X. A. Yang, H. Mehta, K. Mishchenko, A. Khaled, and A. Cutkosky. The Road Less Scheduled. InNeurIPS, 2024
work page 2024
-
[10]
Diffusion Templates: A Unified Plugin Framework for Controllable Diffusion
Zhongjie Duan, Hong Zhang, and Yingda Chen. Diffusion templates: A unified plugin frame- work for controllable diffusion.arXiv preprint arXiv:2604.24351, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [11]
-
[12]
S. Fu, N. Tamir, S. Sundaram, L. Chai, R. Zhang, T. Dekel, and P. Isola. DreamSim: Learning new dimensions of human visual similarity using synthetic data. InNeurIPS, 2023
work page 2023
-
[13]
A. B. Gokmen, Y . Ekin, B. B. Bilecen, and A. Dundar. RoPECraft: Training-free motion transfer with trajectory-guided RoPE optimization on diffusion transformers. InNeurIPS, 2025
work page 2025
-
[14]
Z. Han, Z. Jiang, Y . Pan, J. Zhang, C. Mao, C. Xie, Y . Liu, and J. Zhou. ACE: All-round creator and editor following instructions via Diffusion Transformer. InICLR, 2025
work page 2025
-
[15]
Z. Han, Z. Jiang, Y . Pan, J. Zhang, C. Mao, C. Xie, Y . Liu, and J. Zhou. ACE++: Instruction- based image creation and editing via Context-Aware Content Filling. InProc. of IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, 2025
work page 2025
-
[16]
K. He, J. Sun, and X. Tang. Guided image filtering.IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(6):1397–1409, 2013
work page 2013
- [17]
- [18]
-
[19]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models. InNeurIPS, 2020
work page 2020
-
[20]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Elazar, and D. Chen. LoRA: Low-Rank Adaptation of large language models. InICLR, 2022. 10
work page 2022
-
[21]
Brushnet: A plug-and-play image inpainting model with decomposed dual-branch diffusion
Xuan Ju, Xian Liu, Xintao Wang, Yuxuan Bian, Ying Shan, and Qiang Xu. Brushnet: A plug-and-play image inpainting model with decomposed dual-branch diffusion. InECCV, pages 150–168. Springer, 2024
work page 2024
-
[22]
J. Ke, Q. Wang, Y . Wang, P. Milanfar, and F. Yang. MUSIQ: Multi-scale image quality transformer. InICCV, pages 5148–5157, 2021
work page 2021
-
[23]
S. Lin, B. Liu, J. Li, and X. Yang. Common diffusion noise schedules and sample steps are flawed. InProc. of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 5404–5413, 2024
work page 2024
-
[24]
K. Mishchenko and A. Defazio. Prodigy: An expeditiously adaptive parameter-free learner. In ICML, 2024
work page 2024
- [25]
-
[26]
Y . Pan, X. He, C. Mao, Z. Han, Z. Jiang, J. Zhang, and Y . Liu. ICE-Bench: A unified and comprehensive benchmark for image creating and editing. InICCV, pages 16586–16596, 2025
work page 2025
-
[27]
W. Peebles and S. Xie. Scalable diffusion models with transformers. InCVPR, 2023
work page 2023
- [28]
-
[29]
Qwen Team. Qwen-Image technical report.arXiv preprint arXiv:2508.02324, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever. Learning transferable visual models from natural language supervision. InICML, pages 8748–8763, 2021
work page 2021
-
[31]
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis with latent diffusion models. InCVPR, 2022
work page 2022
-
[32]
O. Siméoni, H. V . V o, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V . Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoa, X. Chen, L. Huang, Y . Liu, Y . Shen, D. Zhao, and H. Zhao. DINOv3. arXiv preprint arXiv:2508.13032, 2025
-
[33]
Resolution-robust large mask inpainting with fourier convolutions
Roman Suvorov, Elizaveta Logacheva, Anton Mashikhin, Anastasia Remizova, Arsenii Ashukha, Aleksei Silvestrov, Naejin Kong, Harshith Goka, Kiwoong Park, and Victor Lempitsky. Resolution-robust large mask inpainting with fourier convolutions. In2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 3172–3182, 2022
work page 2022
-
[34]
Ominicontrol: Minimal and universal control for diffusion transformer
Zhenxiong Tan, Songhua Liu, Xingyi Yang, Qiaochu Xue, and Xinchao Wang. Ominicontrol: Minimal and universal control for diffusion transformer. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14940–14950, 2025
work page 2025
-
[35]
M. Tschannen, A. Gritsenko, X. Wang, M. F. Naeem, I. Alabdulmohsin, N. Parthasarathy, T. Evans, L. Beyer, Y . Xia, B. Mustafa, O. Hénaff, J. Harmsen, A. Steiner, and X. Zhai. SigLIP 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Plug-and-play diffusion features for text-driven image-to-image translation
Narek Tumanyan, Michal Geyer, Shai Bagon, and Tali Dekel. Plug-and-play diffusion features for text-driven image-to-image translation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1921–1930, 2023
work page 1921
-
[37]
Boxdiff: Text-to-image synthesis with training-free box-constrained diffu- sion
Jinheng Xie, Yuexiang Li, Yawen Huang, Haozhe Liu, Wentian Zhang, Yefeng Zheng, and Mike Zheng Shou. Boxdiff: Text-to-image synthesis with training-free box-constrained diffu- sion. InICCV, pages 7452–7461, 2023
work page 2023
- [38]
- [39]
-
[40]
H. Zhao, X. Ma, L. Chen, S. Si, R. Wu, K. An, P. Yu, M. Zhang, Q. Li, and B. Chang. UltraEdit: Instruction-based fine-grained image editing at scale. InNeurIPS, 2024
work page 2024
-
[41]
Loco: Training-free layout-to-image synthesis with localized constraints
Peiang Zhao, Han Li, Ruiyang Jin, and S Kevin Zhou. Loco: Training-free layout-to-image synthesis with localized constraints. InProceedings of the 33rd ACM International Conference on Multimedia, pages 9481–9490, 2025
work page 2025
-
[42]
Lay- outdiffusion: Controllable diffusion model for layout-to-image generation
Guangcong Zheng, Xianpan Zhou, Xuewei Li, Zhongang Qi, Ying Shan, and Xi Li. Lay- outdiffusion: Controllable diffusion model for layout-to-image generation. InCVPR, pages 22490–22499, 2023
work page 2023
-
[43]
Junhao Zhuang, Yanhong Zeng, Wenran Liu, Chun Yuan, and Kai Chen. A task is worth one word: Learning with task prompts for high-quality versatile image inpainting. InECCV, pages 195–211. Springer, 2024. 12 Table 5: Parameter breakdown of the final BRIDGE fine-tuning checkpoint, reported by checkpoint metadata. Component Parameters LoRA adapters 4,725,211,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.