Recognition: no theorem link
Measuring and Mitigating the Distributional Gap Between Real and Simulated User Behaviors
Pith reviewed 2026-05-11 02:15 UTC · model grok-4.3
The pith
LLM-based user simulators show a large distributional gap from real users that combining complementary simulators can reduce.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
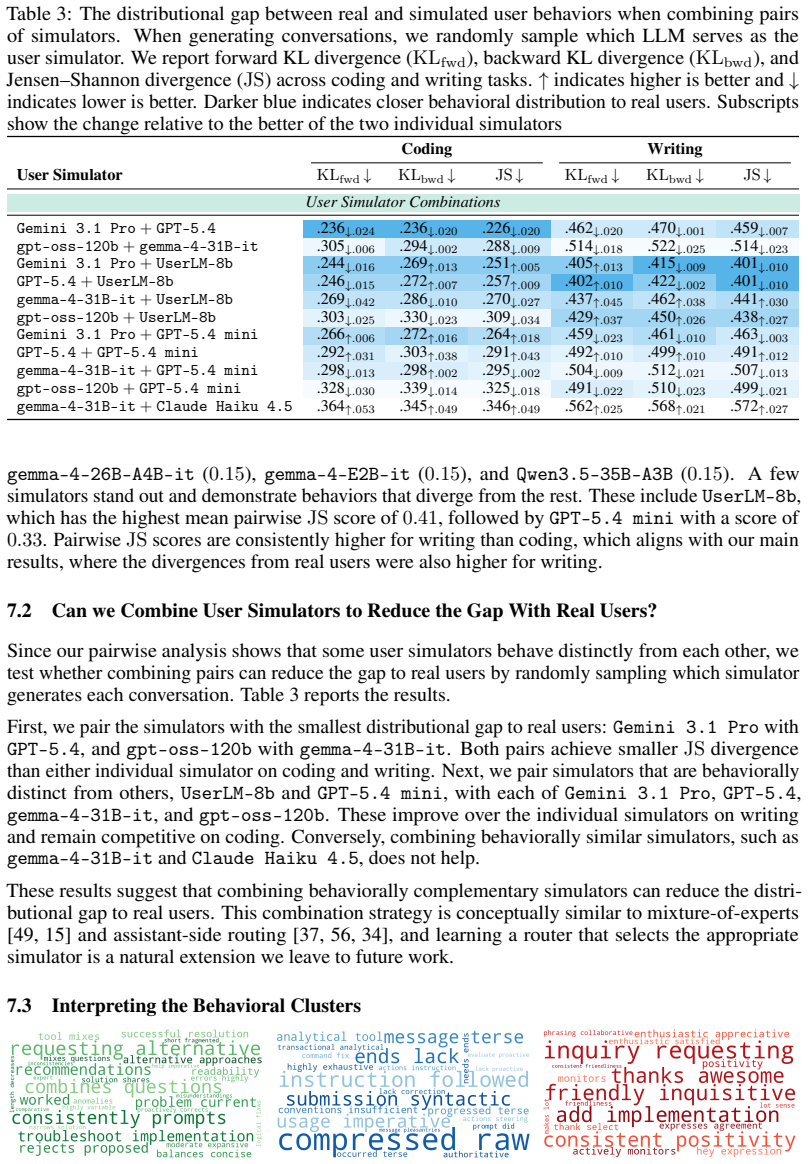
LLM-based user simulators fail to reproduce the broad and heterogeneous distribution of real user behaviors, as quantified by extracting behavior representations from conversations, quantizing them via clustering into discrete distributions, and computing divergence metrics. This gap is large and systematic across 24 simulators on coding and writing tasks, varying by model characteristics, but can be narrowed by combining simulators that cover different behavioral clusters.
What carries the argument
A pipeline that extracts behavior representations from conversations, clusters them to form discrete distributions, and computes divergence between real and simulated distributions.
If this is right
- Most simulators overlap in behavior space, so single-simulator evaluations of AI assistants risk underestimating real-world variability.
- Different model families and scales capture distinct behavioral facets, suggesting targeted selection or mixing based on task needs.
- Ensemble use of complementary simulators provides a direct way to approximate real user distributions more closely.
- TF-IDF inspection of clusters can identify specific missing behaviors to prioritize when improving individual simulators.
Where Pith is reading between the lines
- AI assistant developers could adopt mixed-simulator testing environments as a default practice to better match real user conditions.
- The clustering-based measurement could transfer to simulator evaluation in adjacent domains like education or customer service.
- Persistent gaps may indicate limits in how current LLMs model user variability, motivating new training objectives focused on behavioral diversity.
Load-bearing premise
That the extracted behavior representations, when quantized via clustering, faithfully capture the broad and heterogeneous distribution of real user behaviors.
What would settle it
Applying the full measurement pipeline to a new held-out collection of real user conversations on the same tasks and observing that the computed divergence to the simulators drops near zero would falsify the claim of a large persistent gap.
Figures














read the original abstract
As user simulators are increasingly used for interactive training and evaluation of AI assistants, it is essential that they represent the diverse behaviors of real users. While existing works train user simulators to generate human-like responses, whether they capture the broad and heterogeneous distribution of real user behaviors remains an open question. In this work, we introduce a method to measure the distributional gap between real and simulated user behaviors, validated through a human study and ablations. Given a dataset of real and simulated conversations, our method extracts representations of user behavior from each conversation, quantizes them into discrete distributions via clustering, then computes divergence metrics. We provide the first systematic evaluation of 24 LLM-based user simulators on coding and writing tasks, and reveal a large distributional gap from real users that varies across model families, scales, and behavioral facets. Pairwise comparisons show that most simulators behave similarly, while a few stand apart. Combining behaviorally complementary simulators brings the resulting distribution closer to real users compared to either simulator on its own. Finally, a TF-IDF analysis of the clusters surfaces interpretable patterns of behaviors that simulators capture, miss, and hallucinate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a method to measure the distributional gap between real and simulated user behaviors: extract behavior representations from conversation datasets, quantize them into discrete distributions via clustering, and compute divergence metrics. Validated through a human study and ablations, it systematically evaluates 24 LLM-based user simulators on coding and writing tasks, revealing a large gap from real users that varies across model families, scales, and behavioral facets. Pairwise comparisons indicate most simulators behave similarly while a few stand apart; combining behaviorally complementary simulators yields a distribution closer to real users. TF-IDF analysis of clusters provides interpretable patterns of captured, missed, and hallucinated behaviors.
Significance. If the central measurements are robust, this provides the first large-scale evaluation of LLM user simulators and a practical mitigation strategy via combination of complementary models. This has clear implications for interactive training and evaluation of AI assistants, where simulator fidelity directly affects downstream performance. The use of human validation and ablations is a strength that grounds the approach beyond purely automatic metrics.
major comments (2)
- [Method] Method section: The claim of a 'large distributional gap' and the benefit of combining simulators rests on clustering faithfully preserving the heterogeneous support of real-user behaviors without excessive variance loss or spurious modes. The human study and ablations are cited as validation, but without details on representation extraction, embedding dimensionality, clustering algorithm, and cluster count (including ablations on these choices), it is unclear whether the quantization captures broad facets or only coarse separability, rendering the gap measurements potentially sensitive to post-hoc decisions.
- [Human study and ablations] Human study and ablations: The protocol for the human study (e.g., exact task, participant instructions, and how it tests fine-grained fidelity across behavioral facets rather than just separability) is not specified, which is load-bearing for confirming that the extracted representations and clusters reflect true distributional differences rather than artifacts.
minor comments (2)
- [Abstract] Abstract: The selection criteria for the 24 simulators and the two tasks (coding and writing) could be stated more explicitly to allow readers to assess generalizability.
- [TF-IDF analysis] TF-IDF analysis: Clarify how cluster labels are assigned and whether the surfaced patterns are validated against the original conversation data.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which highlight important aspects of methodological transparency. We address each major comment below and will revise the manuscript to incorporate additional details that strengthen the presentation of our approach.
read point-by-point responses
-
Referee: [Method] Method section: The claim of a 'large distributional gap' and the benefit of combining simulators rests on clustering faithfully preserving the heterogeneous support of real-user behaviors without excessive variance loss or spurious modes. The human study and ablations are cited as validation, but without details on representation extraction, embedding dimensionality, clustering algorithm, and cluster count (including ablations on these choices), it is unclear whether the quantization captures broad facets or only coarse separability, rendering the gap measurements potentially sensitive to post-hoc decisions.
Authors: We agree that explicit details on these choices are necessary to demonstrate robustness. The current manuscript describes the high-level pipeline (behavior representation extraction followed by quantization and divergence computation) but does not enumerate the concrete parameters. In revision we will add a dedicated subsection 'Implementation Details and Sensitivity Analysis' specifying: (i) representation extraction via 768-dimensional sentence embeddings from a fixed pre-trained model, (ii) K-means clustering with k=50 selected via silhouette analysis on the real-user data, and (iii) ablations over k in {20,30,50,75,100} showing that the reported divergence rankings, the large gap relative to real users, and the improvement from combining complementary simulators remain stable. These results indicate that the quantization preserves heterogeneous support without introducing spurious modes that would alter the core conclusions. revision: yes
-
Referee: [Human study and ablations] Human study and ablations: The protocol for the human study (e.g., exact task, participant instructions, and how it tests fine-grained fidelity across behavioral facets rather than just separability) is not specified, which is load-bearing for confirming that the extracted representations and clusters reflect true distributional differences rather than artifacts.
Authors: We acknowledge that the human-study protocol requires fuller exposition. The study was designed to evaluate whether clusters align with human-perceived behavioral distinctions rather than mere separability. In the revised manuscript we will expand the 'Human Validation' section (and add an appendix) with: the exact task (participants rated 100 conversation pairs on a 1-5 behavioral-similarity scale), the participant instructions (explicitly directing attention to facets such as verbosity, topic adherence, clarification-seeking, and error-handling style), and the analysis showing that cluster membership predicts human similarity ratings above chance (Pearson r=0.68). This protocol directly tests fine-grained fidelity across behavioral facets and supports that the distributional gap reflects genuine differences. revision: yes
Circularity Check
No significant circularity; empirical method is self-contained
full rationale
The paper's core contribution is an empirical pipeline that extracts behavior representations from conversation datasets, applies standard clustering to form discrete distributions, and computes divergence metrics to quantify gaps between real and simulated users. This process is applied directly to held-out data without any parameter fitting that is then relabeled as a prediction, without self-definitional loops, and without load-bearing reliance on self-citations or prior author theorems. The human study and ablations serve as external validation of the representation and quantization choices rather than deriving the gap measurements from themselves. All reported findings on simulator similarities, complementary combinations, and TF-IDF patterns follow from applying these standard operations to the collected data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Abdulhai, M., Cheng, R., Clay, D., Althoff, T., Levine, S., and Jaques, N. (2026). Consistently simulating human personas with multi-turn reinforcement learning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
work page 2026
-
[2]
Aher, G. V ., Arriaga, R. I., and Kalai, A. T. (2023). Using large language models to simulate multiple humans and replicate human subject studies. In Krause, A., Brunskill, E., Cho, K., Engel- hardt, B., Sabato, S., and Scarlett, J., editors,Proceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning...
work page 2023
-
[3]
Allen, J. and Core, M. (1997). Draft of damsl: Dialog act markup in several layers
work page 1997
-
[4]
Andukuri, C., Fränken, J.-P., Gerstenberg, T., and Goodman, N. (2024). STar-GATE: Teaching language models to ask clarifying questions. InFirst Conference on Language Modeling
work page 2024
-
[5]
Barres, V ., Dong, H., Ray, S., Si, X., and Narasimhan, K. (2025). τ 2-bench: Evaluating conversational agents in a dual-control environment
work page 2025
-
[6]
Chang, J., Gerrish, S., Wang, C., Boyd-graber, J., and Blei, D. (2009). Reading tea leaves: How humans interpret topic models. In Bengio, Y ., Schuurmans, D., Lafferty, J., Williams, C., and Culotta, A., editors,Advances in Neural Information Processing Systems, volume 22. Curran Associates, Inc
work page 2009
-
[7]
Chen, J., Xu, R., Cao, B., Pan, R., Zhang, Y ., Hu, Y ., Du, Y ., Gao, T., Lu, Y ., Sun, Y ., Han, X., Sun, L., Wu, X., and Lin, H. (2026). Towards real-world human behavior simulation: Benchmarking large language models on long-horizon, cross-scenario, heterogeneous behavior traces
work page 2026
-
[8]
Clark, H. H. and Brennan, S. E. (1991). Grounding in communication
work page 1991
-
[9]
Davidson, S., Romeo, S., Shu, R., Gung, J., Gupta, A., Mansour, S., and Zhang, Y . (2023). User simulation with large language models for evaluating task-oriented dialogue
work page 2023
-
[10]
Ding, N., Chen, Y ., Xu, B., Qin, Y ., Hu, S., Liu, Z., Sun, M., and Zhou, B. (2023). Enhancing chat language models by scaling high-quality instructional conversations. In Bouamor, H., Pino, J., and Bali, K., editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 3029–3051, Singapore. Association for Computa...
work page 2023
-
[11]
Djolonga, J., Lucic, M., Cuturi, M., Bachem, O., Bousquet, O., and Gelly, S. (2020a). Precision- recall curves using information divergence frontiers. InInternational Conference on Artificial Intelligence and Statistics, pages 2550–2559. PMLR
-
[12]
Djolonga, J., Lucic, M., Cuturi, M., Bachem, O., Bousquet, O., and Gelly, S. (2020b). Precision- recall curves using information divergence frontiers. In Chiappa, S. and Calandra, R., editors, Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics, volume 108 ofProceedings of Machine Learning Research, pages 255...
-
[13]
Dou, Y ., Galley, M., Peng, B., Kedzie, C., Cai, W., Ritter, A., Quirk, C., Xu, W., and Gao, J. (2025). SimulatorArena: Are user simulators reliable proxies for multi-turn evaluation of AI assistants? In Christodoulopoulos, C., Chakraborty, T., Rose, C., and Peng, V ., editors, Proceedings of the 2025 Conference on Empirical Methods in Natural Language Pr...
work page 2025
-
[14]
Eckert, W., Levin, E., and Pieraccini, R. (1997). User modeling for spoken dialogue system evaluation. In1997 IEEE Workshop on Automatic Speech Recognition and Understanding Proceedings, pages 80–87. IEEE
work page 1997
-
[15]
Fedus, W., Zoph, B., and Shazeer, N. (2022). Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39
work page 2022
-
[16]
Gandhi, K., Bhatia, A., and Goodman, N. D. (2026). Learning to simulate human dialogue
work page 2026
-
[17]
Ge, T., Chan, X., Wang, X., Yu, D., Mi, H., and Yu, D. (2025). Scaling synthetic data creation with 1,000,000,000 personas. 10
work page 2025
-
[18]
Grosz, B. J. and Sidner, C. L. (1986). Attention, intentions, and the structure of discourse. Computational linguistics, 12(3):175–204
work page 1986
-
[19]
Henderson, M., Thomson, B., and Williams, J. D. (2014). The second dialog state tracking challenge. In Georgila, K., Stone, M., Hastie, H., and Nenkova, A., editors,Proceedings of the 15th Annual Meeting of the Special Interest Group on Discourse and Dialogue (SIGDIAL), pages 263–272, Philadelphia, PA, U.S.A. Association for Computational Linguistics
work page 2014
-
[20]
K., Mehri, S., Hsu, T.-A., Sun, Y .-J., Truong, Q
Hoang, N. K., Mehri, S., Hsu, T.-A., Sun, Y .-J., Truong, Q. X. N., Doan, K. D., and Hakkani-Tür, D. (2026). Psi-bench: Towards clinically grounded and interpretable evaluation of depression patient simulators
work page 2026
-
[21]
Horvitz, E. (1999). Principles of mixed-initiative user interfaces. InProceedings of the SIGCHI conference on Human Factors in Computing Systems, pages 159–166
work page 1999
-
[22]
Ivey, J., Kumar, S., Liu, J., Shen, H., Rakshit, S., Raju, R., Zhang, H., Ananthasubramaniam, A., Kim, J., Yi, B., Wright, D., Israeli, A., Møller, A. G., Zhang, L., and Jurgens, D. (2024). Real or robotic? assessing whether llms accurately simulate qualities of human responses in dialogue
work page 2024
-
[23]
Kynkäänniemi, T., Karras, T., Laine, S., Lehtinen, J., and Aila, T. (2019a). Improved precision and recall metric for assessing generative models. In Wallach, H., Larochelle, H., Beygelzimer, A., d'Alché-Buc, F., Fox, E., and Garnett, R., editors,Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc
-
[24]
Kynkäänniemi, T., Karras, T., Laine, S., Lehtinen, J., and Aila, T. (2019b). Improved precision and recall metric for assessing generative models. In Wallach, H., Larochelle, H., Beygelzimer, A., d'Alché-Buc, F., Fox, E., and Garnett, R., editors,Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc
-
[25]
Laban, P., Hayashi, H., Zhou, Y ., and Neville, J. (2026). LLMs get lost in multi-turn conversation. InThe Fourteenth International Conference on Learning Representations
work page 2026
-
[26]
Levin, E., Pieraccini, R., Eckert, W., et al. (2000). A stochastic model of human-machine interaction for learning dialog strategies.IEEE Transactions on speech and audio processing, 8(1):11–23
work page 2000
-
[27]
Z., Tamkin, A., Goodman, N., and Andreas, J
Li, B. Z., Tamkin, A., Goodman, N., and Andreas, J. (2025). Eliciting human preferences with language models. InThe Thirteenth International Conference on Learning Representations
work page 2025
-
[28]
Liu, Y ., Jiang, X., Yin, Y ., Wang, Y ., Mi, F., Liu, Q., Wan, X., and Wang, B. (2023). One cannot stand for everyone! leveraging multiple user simulators to train task-oriented dialogue systems. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1–21
work page 2023
-
[29]
Luo, X., Tang, Z., Wang, J., and Zhang, X. (2024). DuetSim: Building user simulator with dual large language models for task-oriented dialogues. In Calzolari, N., Kan, M.-Y ., Hoste, V ., Lenci, A., Sakti, S., and Xue, N., editors,Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-C...
work page 2024
-
[30]
McInnes, L., Healy, J., Saul, N., and Großberger, L. (2018). Umap: Uniform manifold approximation and projection.Journal of Open Source Software, 3(29):861
work page 2018
-
[31]
Mehri, S. (2025). Goal alignment in LLM-based user simulators for conversational AI. InFirst Workshop on Multi-Turn Interactions in Large Language Models
work page 2025
-
[32]
Mehri, S., Kargupta, P., August, T., and Hakkani-Tür, D. (2026). Multisessioncollab: Learning user preferences with memory to improve long-term collaboration
work page 2026
-
[33]
Naous, T., Laban, P., Xu, W., and Neville, J. (2026). Flipping the dialogue: Training and evaluating user language models. InThe Fourteenth International Conference on Learning Representations. 11
work page 2026
-
[34]
Ong, I., Almahairi, A., Wu, V ., Chiang, W.-L., Wu, T., Gonzalez, J. E., Kadous, M. W., and Stoica, I. (2025). RouteLLM: Learning to route LLMs from preference data. InThe Thirteenth International Conference on Learning Representations
work page 2025
-
[35]
Park, J. S., O’Brien, J., Cai, C. J., Morris, M. R., Liang, P., and Bernstein, M. S. (2023). Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, UIST ’23, New York, NY , USA. Association for Computing Machinery
work page 2023
-
[36]
LLM Agents Grounded in Self-Reports Enable General-Purpose Simulation of Individuals
Park, J. S., Zou, C. Q., Shaw, A., Hill, B. M., Cai, C., Morris, M. R., Willer, R., Liang, P., and Bernstein, M. S. (2024). Generative agent simulations of 1,000 people.arXiv preprint arXiv:2411.10109, 52
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Peng, B., Li, X., Li, L., Gao, J., Celikyilmaz, A., Lee, S., and Wong, K.-F. (2017). Composite task-completion dialogue policy learning via hierarchical deep reinforcement learning. In Palmer, M., Hwa, R., and Riedel, S., editors,Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 2231–2240, Copenhagen, Denmark. A...
work page 2017
-
[38]
Piantadosi, S. T., Tily, H., and Gibson, E. (2012). The communicative function of ambiguity in language.Cognition, 122(3):280–291
work page 2012
-
[39]
Pietquin, O. and Hastie, H. (2013). A survey on metrics for the evaluation of user simulations. The knowledge engineering review, 28(1):59–73
work page 2013
-
[40]
Pillutla, K., Liu, L., Thickstun, J., Welleck, S., Swayamdipta, S., Zellers, R., Oh, S., Choi, Y ., and Harchaoui, Z. (2023). Mauve scores for generative models: Theory and practice.Journal of Machine Learning Research, 24(356):1–92
work page 2023
-
[41]
Pillutla, K., Swayamdipta, S., Zellers, R., Thickstun, J., Welleck, S., Choi, Y ., and Harchaoui, Z. (2021). Mauve: Measuring the gap between neural text and human text using divergence frontiers. In Ranzato, M., Beygelzimer, A., Dauphin, Y ., Liang, P., and Vaughan, J. W., editors,Advances in Neural Information Processing Systems, volume 34, pages 4816–4...
work page 2021
-
[42]
Pimentel, T., Meister, C. I., and Cotterell, R. (2023). On the usefulness of embeddings, clusters and strings for text generation evaluation. InThe Eleventh International Conference on Learning Representations
work page 2023
-
[43]
M., Wang, S., Liu, Z., Chen, H., Hoang, T
Prabhakar, A., Liu, Z., Zhu, M., Zhang, J., Awalgaonkar, T. M., Wang, S., Liu, Z., Chen, H., Hoang, T. Q., Niebles, J. C., Heinecke, S., Yao, W., Wang, H., Savarese, S., and Xiong, C. (2026). APIGen-MT: Agentic pipeline for multi-turn data generation via simulated agent-human interplay. InThe Thirty-ninth Annual Conference on Neural Information Processing...
work page 2026
-
[44]
Rastogi, A., Zang, X., Sunkara, S., Gupta, R., and Khaitan, P. (2020). Towards scalable multi- domain conversational agents: The schema-guided dialogue dataset. InProceedings of the AAAI conference on artificial intelligence, volume 34, pages 8689–8696
work page 2020
-
[45]
Rieser, V . and Lemon, O. (2006). Cluster-based user simulations for learning dialogue strategies. InNinth International Conference on Spoken Language Processing. ISCA
work page 2006
-
[46]
Sajjadi, M. S. M., Bachem, O., Lucic, M., Bousquet, O., and Gelly, S. (2018a). Assessing generative models via precision and recall. In Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., and Garnett, R., editors,Advances in Neural Information Processing Systems, volume 31. Curran Associates, Inc
-
[47]
Sajjadi, M. S. M., Bachem, O., Lucic, M., Bousquet, O., and Gelly, S. (2018b). Assessing generative models via precision and recall. In Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., and Garnett, R., editors,Advances in Neural Information Processing Systems, volume 31. Curran Associates, Inc
-
[48]
Seshadri, P., Cahyawijaya, S., Odumakinde, A., Singh, S., and Goldfarb-Tarrant, S. (2026). Lost in simulation: Llm-simulated users are unreliable proxies for human users in agentic evaluations. 12
work page 2026
-
[49]
Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q., Hinton, G., and Dean, J. (2017). Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. InInternational Conference on Learning Representations
work page 2017
-
[50]
Shelby, R., Diaz, F., and Prabhakaran, V . (2025). Taxonomy of user needs and actions
work page 2025
-
[51]
K., Xu, X., Song, X., and Neville, J
Shi, T., Wang, Z., Yang, L., Lin, Y .-C., He, Z., Wan, M., Zhou, P., Jauhar, S. K., Xu, X., Song, X., and Neville, J. (2024). Wildfeedback: Aligning LLMs with in-situ user interactions and feedback. InNeurIPS 2024 Workshop on Behavioral Machine Learning
work page 2024
-
[52]
Shi, W., Qian, K., Wang, X., and Yu, Z. (2019). How to build user simulators to train RL-based dialog systems. In Inui, K., Jiang, J., Ng, V ., and Wan, X., editors,Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 1990–2000...
work page 2019
-
[53]
Sun, W., Guo, S., Zhang, S., Ren, P., Chen, Z., de Rijke, M., and Ren, Z. (2023). Metaphorical user simulators for evaluating task-oriented dialogue systems.ACM Trans. Inf. Syst., 42(1)
work page 2023
-
[54]
Taylor, R. S. (1967). Question-negotiation an information-seeking in libraries. Technical report
work page 1967
-
[55]
Team, Q. (2026). Qwen3.5: Accelerating productivity with native multimodal agents
work page 2026
-
[56]
Wang, J., WANG, J., Athiwaratkun, B., Zhang, C., and Zou, J. (2025). Mixture-of-agents enhances large language model capabilities. InThe Thirteenth International Conference on Learning Representations
work page 2025
-
[57]
Wang, L., Yang, N., Huang, X., Jiao, B., Yang, L., Jiang, D., Majumder, R., and Wei, F. (2024). Text embeddings by weakly-supervised contrastive pre-training
work page 2024
-
[58]
C., Wei, W., Yang, D., Leskovec, J., and Zou, J
Wu, S., Choi, E., Khatua, A., Wang, Z., He-Yueya, J., Weerasooriya, T. C., Wei, W., Yang, D., Leskovec, J., and Zou, J. (2026). Humanlm: Simulating users with state alignment beats response imitation
work page 2026
-
[59]
Wu, S., Galley, M., Peng, B., Cheng, H., Li, G., Dou, Y ., Cai, W., Zou, J., Leskovec, J., and Gao, J. (2025). CollabLLM: From passive responders to active collaborators. InForty-second International Conference on Machine Learning
work page 2025
-
[60]
Xiao, S., Liu, Z., Zhang, P., Muennighoff, N., Lian, D., and Nie, J.-Y . (2024). C-pack: Packed resources for general chinese embeddings. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’24, page 641–649, New York, NY , USA. Association for Computing Machinery
work page 2024
-
[61]
Young, S., Gaši´c, M., Keizer, S., Mairesse, F., Schatzmann, J., Thomson, B., and Yu, K. (2010). The hidden information state model: A practical framework for pomdp-based spoken dialogue management.Computer Speech & Language, 24(2):150–174
work page 2010
-
[62]
Y ., Hartmann, B., and Yang, Q
Zamfirescu-Pereira, J., Wong, R. Y ., Hartmann, B., and Yang, Q. (2023). Why johnny can’t prompt: How non-ai experts try (and fail) to design llm prompts. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems, CHI ’23, New York, NY , USA. Association for Computing Machinery
work page 2023
-
[63]
Zhang, F., Li, S., Zhang, C., Ma, Z., Xu, J., Gao, J., Hao, J., He, R., Xu, J., and Liu, H. (2026). Userlm-r1: Modeling human reasoning in user language models with multi-reward reinforcement learning
work page 2026
-
[64]
Zhang, Y ., Li, M., Long, D., Zhang, X., Lin, H., Yang, B., Xie, P., Yang, A., Liu, D., Lin, J., Huang, F., and Zhou, J. (2025). Qwen3 embedding: Advancing text embedding and reranking through foundation models
work page 2025
-
[65]
Zhao, W., Ren, X., Hessel, J., Cardie, C., Choi, Y ., and Deng, Y . (2024). Wildchat: 1m chatGPT interaction logs in the wild. InThe Twelfth International Conference on Learning Representations. 13
work page 2024
-
[66]
Zheng, L., Chiang, W.-L., Sheng, Y ., Li, T., Zhuang, S., Wu, Z., Zhuang, Y ., Li, Z., Lin, Z., Xing, E., Gonzalez, J. E., Stoica, I., and Zhang, H. (2024). LMSYS-chat-1m: A large-scale real-world LLM conversation dataset. InThe Twelfth International Conference on Learning Representations
work page 2024
-
[67]
Zhou, X., Sun, W., Ma, Q., Xie, Y ., Liu, J., Du, W., Welleck, S., Yang, Y ., Neubig, G., Wu, S. T., and Sap, M. (2026). Mind the sim2real gap in user simulation for agentic tasks
work page 2026
-
[68]
Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y ., Fried, D., Neubig, G., and Sap, M. (2024a). SOTOPIA: Interactive evaluation for social intelligence in language agents. InThe Twelfth International Conference on Learning Representations
-
[69]
Zhou, Y ., Zanette, A., Pan, J., Levine, S., and Kumar, A. (2024b). ArCHer: Training language model agents via hierarchical multi-turn RL. InForty-first International Conference on Machine Learning. 14 A Limitations and Future Directions We make an effort to approximate the distribution of real user behaviors by grounding our evaluation in 10,000 real-wor...
-
[70]
S p e c i f i c a t i o n and A r t i c u l a t i o n - How s p e c i f i e d are the r eq ues ts ? Is the first request underspecified , and c l a r i f i e d in s u b s e q u e n t turns ? Or are the r eq ues ts e x h a u s t i v e ? - What type of i n f o r m a t i o n is left u n d e r s p e c i f i e d / s p e c i f i e d ? ( e . g . constraints , ed...
-
[71]
User Goal D e c o m p o s i t i o n - How is the user goal d e c o m p o s e d across u t t e r a n c e s ? - Single - shot : The entire goal is e x p r e s s e d in one u t t e r a n c e with no further d e c o m p o s i t i o n . - Top - down : High - level goal stated upfront , then p r o g r e s s i v e l y refined or e l a b o r a t e d . - Bottom - ...
-
[72]
R e l e v a n c e to Goal - Are the r eq ue st s di re ct ly related to the user goal ? Or does the user i n t r o d u c e s e c o n d a r y / p e r p e n d i c u l a r / em er ge nt needs ? - What f u n c t i o n s do the r eq ues ts serve beyond a c h i e v i n g the user goal ? ( setting context , probing AI capabilities , v e r i f y i n g i n t e r m...
-
[73]
E n g a g e m e n t and E v a l u a t i o n - Does the user engage with the agent responses , or ignore / skip over them ? - How does the user e va lua te the agent ’ s output ? ( e . g . , ex pl ici t validation , im pl ic it a c c e p t a n c e by continuing , partial a c c e p t a n c e with corrections , r e j e c t i o n ) - Does the user provide s p...
-
[74]
R es po ns e C o m p o s i t i o n - What types of actions are present in the user ’ s r e s p o n s e s ? Are they re act iv e ( e . g . , validation , acknowledgment , a n s w e r i n g agent questions , corrections , fe ed ba ck ) , p r o a c t i v e ( e . g . , follow - up requests , new c o n s t r a i n t s / preferences , suggestions , q u e s t i ...
-
[75]
S te er in g M e c h a n i s m - Does the user steer through direct follow - up requests , or through in di re ct means ? ( e . g . , asking q u e s t i o n s that i m p l i c i t l y request action , e x p r e s s i n g d i s s a t i s f a c t i o n without stating what to change , p r o v i d i n g hints or ex amp le s rather than d i r e c t i v e s ) ...
-
[76]
Context Ric hn es s - How much context does the user provide overall ? Do they share b a c k g r o u n d about themselves , their situation , what they ’ ve already tried , what they ’ re s t r u g g l i n g with , or what they ’ re th ink in g ? - Does the user provide all r el ev ant context needed for the agent to help effectively , or is e s s e n t i...
-
[77]
Context Type - What types of context does the user provide ? ( e . g . , p er so nal background , goals / motivations , prior attempts , e xi sti ng solutions , constraints , preferences , domain knowledge , e m o t i o n a l state , thought process )
-
[78]
Context Del iv er y - Does the user front - load all r ele va nt context in their first message , or reveal it i n c r e m e n t a l l y across turns ? What types of context are i n t r o d u c e d later ? ( e . g . , c o n s t r a i n t s they forgot , p r e f e r e n c e s they didn ’ t think to mention , b a c k g r o u n d that becomes r el eva nt as ...
-
[79]
R eg is te r and Tone - What is the user ’ s r eg is te r ? ( e . g . , formal , casual , conversational , terse , p r o f e s s i o n a l ) - What is the user ’ s e m o t i o n a l tone ? ( e . g . , neutral , frustrated , enthusiastic , impatient , apologetic , d e f e r e n t i a l ) - Does the re gi ste r / tone shift across the c o n v e r s a t i o ...
-
[80]
V e r b o s i t y and S t r u c t u r e - How verbose are the user ’ s mes sa ge s ? Are they minimal and compressed , or e x p a n s i v e and e l a b o r a t e d ? - Does the user use f o r m a t t i n g c o n v e n t i o n s ? ( e . g . , bullet points , n um be red lists , code blocks , markdown , all caps , p u n c t u a t i o n p at te rn s ) - How ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.