Recognition: no theorem link
Actor-Critic Algorithm for Dynamic Expectile and CVaR
Pith reviewed 2026-05-11 02:08 UTC · model grok-4.3
The pith
A surrogate policy gradient and elicitability enable model-free actor-critic optimization of dynamic expectile and CVaR.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that a surrogate policy gradient under softmax parameterization, together with elicitability-based model-free value learning, yields a practical off-policy actor-critic algorithm capable of optimizing dynamic expectile and CVaR risk measures; empirical tests in environments where risk-averse behavior can be verified demonstrate that the resulting policies are risk-averse and outperform existing methods.
What carries the argument
Surrogate policy gradient under softmax parameterization combined with elicitability for model-free dynamic value learning.
If this is right
- Risk-averse policies become learnable from samples without constructing or perturbing transition models.
- Value functions for dynamic expectile and CVaR can be estimated reliably in a model-free manner.
- Off-policy updates inspired by Expected SARSA and Expected Policy Gradient become available for risk-sensitive control.
- Consistent outperformance over prior methods is observed in domains that admit verifiable risk-averse behavior.
Where Pith is reading between the lines
- The approach removes a practical barrier to deploying risk-sensitive policies in settings where accurate simulators are unavailable.
- Elicitability may serve as a general route to model-free learning for other dynamic risk measures that admit similar scoring functions.
- The method's sample-based nature could support scaling to larger state spaces when paired with function approximation.
Load-bearing premise
The surrogate policy gradient under softmax parameterization works effectively without transition perturbation, and elicitability enables reliable model-free value learning for dynamic expectile and CVaR.
What would settle it
In a simple MDP with a known risk-averse optimal policy, the algorithm fails to converge to that policy or produces policies whose realized risk is no lower than risk-neutral baselines.
Figures




read the original abstract
Optimizing dynamic risk with stochastic policies is challenging in both policy updates and value learning. The former typically requires transition perturbation, while the latter may rely on model-based approaches. To address these challenges, we propose a surrogate policy gradient without transition perturbation under softmax policy parameterization. We further develop model-free value learning methods for dynamic expectile and conditional value-at-risk by leveraging elicitability. Finally, inspired by Expected SARSA and Expected Policy Gradient, a model-free off-policy actor-critic algorithm is constructed. Empirical results in domains with verifiable risk-averse behavior show that our algorithm can learn risk-averse policy and consistently outperforms other existing methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a surrogate policy gradient for dynamic risk optimization under softmax policies that avoids transition perturbation, develops model-free value learning for dynamic expectile and CVaR via elicitability, and constructs an off-policy actor-critic algorithm inspired by Expected SARSA and Expected Policy Gradient. Empirical results in domains with verifiable risk-averse behavior indicate that the algorithm learns risk-averse policies and outperforms existing methods.
Significance. If the derivations and empirical results hold, the work would advance risk-averse RL by enabling fully model-free dynamic risk optimization, addressing challenges in policy updates and value learning. The surrogate gradient and elicitability-based approach could improve scalability in applications like finance and safe control, building productively on established RL techniques.
major comments (2)
- [§4] §4 (surrogate policy gradient derivation): the claim that the surrogate avoids transition perturbation under softmax parameterization is central to the model-free contribution; the manuscript should include an explicit side-by-side comparison with standard policy gradients to confirm the avoidance holds without additional assumptions.
- [§5] §5 (empirical evaluation): the outperformance claim is load-bearing for the paper's practical contribution; the reported results should include statistical significance tests, number of independent runs, and confidence intervals to substantiate consistent superiority over baselines.
minor comments (3)
- The abstract could more precisely state the specific risk measures addressed and the key algorithmic components for clarity.
- [§2] Notation for dynamic risk measures and elicitability should be introduced with a brief reminder of definitions in the main text to aid readers unfamiliar with the concepts.
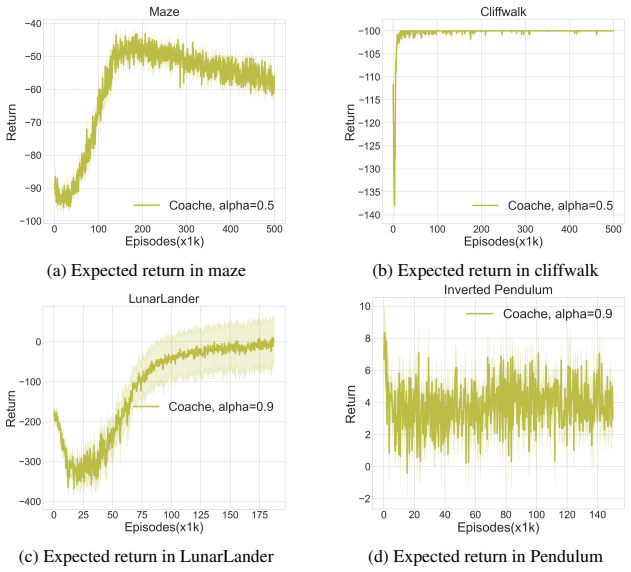
- [§5] Figure captions and axis labels in the experimental section would benefit from explicit mention of the risk parameters used (e.g., expectile level or CVaR alpha).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive recommendation of minor revision. We address each major comment below and will revise the manuscript to incorporate the suggested clarifications and statistical reporting.
read point-by-point responses
-
Referee: [§4] §4 (surrogate policy gradient derivation): the claim that the surrogate avoids transition perturbation under softmax parameterization is central to the model-free contribution; the manuscript should include an explicit side-by-side comparison with standard policy gradients to confirm the avoidance holds without additional assumptions.
Authors: We agree that an explicit side-by-side comparison would strengthen the presentation of the central claim. In the revised manuscript, we will add a new subsection (or table) in §4 that directly contrasts the standard policy gradient expression (which involves explicit perturbation of the transition kernel under the softmax policy) with our surrogate gradient. The comparison will highlight that the surrogate form, derived via the elicitability-based value function and softmax parameterization, eliminates the need for transition perturbation without introducing further assumptions, thereby preserving the model-free property. revision: yes
-
Referee: [§5] §5 (empirical evaluation): the outperformance claim is load-bearing for the paper's practical contribution; the reported results should include statistical significance tests, number of independent runs, and confidence intervals to substantiate consistent superiority over baselines.
Authors: We acknowledge that rigorous statistical support is necessary to substantiate the outperformance claims. In the revised version of §5, we will explicitly state the number of independent runs (with random seeds), report the results of statistical significance tests (e.g., paired t-tests or Wilcoxon signed-rank tests) against each baseline, and include 95% confidence intervals for the key performance metrics across the risk-averse domains. These additions will provide quantitative evidence for consistent superiority. revision: yes
Circularity Check
No significant circularity detected
full rationale
The derivation chain introduces a surrogate policy gradient under softmax parameterization to avoid transition perturbation, leverages elicitability for model-free dynamic risk value learning, and constructs an off-policy actor-critic algorithm inspired by but distinct from Expected SARSA and Expected Policy Gradient. These steps are presented as novel combinations of established concepts rather than reductions to self-definitions, fitted parameters renamed as predictions, or load-bearing self-citations. The empirical claims are framed as validation of the proposed methods in risk-averse domains, with no equations or premises shown to be equivalent to their inputs by construction. The approach remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Q-learning for quantile MDPs: A decomposition, performance, and convergence analysis , author=. Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS) , year=
-
[2]
Mathematical Methods of Operations Research , volume=
Markov decision processes with average-value-at-risk criteria , author=. Mathematical Methods of Operations Research , volume=. 2011 , publisher=
work page 2011
-
[3]
Mathematical programming , volume=
Risk-averse dynamic programming for Markov decision processes , author=. Mathematical programming , volume=. 2010 , publisher=
work page 2010
-
[4]
Proceedings of the AAAI conference on artificial intelligence (AAAI) , volume=
Distributional reinforcement learning with quantile regression , author=. Proceedings of the AAAI conference on artificial intelligence (AAAI) , volume=
-
[5]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Efficient risk-averse reinforcement learning , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[6]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Distributional Reinforcement Learning for Risk-Sensitive Policies , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[7]
Mathematical finance , volume=
Coherent measures of risk , author=. Mathematical finance , volume=. 1999 , publisher=
work page 1999
-
[8]
arXiv preprint arXiv:2602.03381 , year=
Dynamic Programming for Epistemic Uncertainty in Markov Decision Processes , author=. arXiv preprint arXiv:2602.03381 , year=
-
[9]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Policy gradient for coherent risk measures , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
- [10]
-
[11]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
One risk to rule them all: A risk-sensitive perspective on model-based offline reinforcement learning , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[12]
Quantitative finance , volume=
Deep reinforcement learning for option pricing and hedging under dynamic expectile risk measures , author=. Quantitative finance , volume=. 2023 , publisher=
work page 2023
-
[13]
Proceedings of the International Conference on Machine Learning (ICML) , pages=
Deterministic policy gradient algorithms , author=. Proceedings of the International Conference on Machine Learning (ICML) , pages=. 2014 , organization=
work page 2014
-
[14]
Reinforcement learning: An introduction , author=. 1998 , publisher=
work page 1998
-
[15]
Journal of Machine Learning Research , volume=
Expected policy gradients for reinforcement learning , author=. Journal of Machine Learning Research , volume=
-
[16]
SIAM Journal on Financial Mathematics , volume=
Conditionally elicitable dynamic risk measures for deep reinforcement learning , author=. SIAM Journal on Financial Mathematics , volume=. 2023 , publisher=
work page 2023
-
[17]
The European Journal of Finance , volume=
Risk management with expectiles , author=. The European Journal of Finance , volume=. 2017 , publisher=
work page 2017
-
[18]
Optimization of conditional value-at-risk , author=. Journal of risk , volume=. 2000 , publisher=
work page 2000
-
[19]
Entropic risk optimization in discounted MDPs , author=. Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS) , pages=. 2023 , organization=
work page 2023
-
[20]
Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , volume=
Risk-Sensitive Exponential Actor Critic , author=. Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , volume=
-
[21]
arXiv preprint arXiv:2103.02827 , year=
On the convergence and optimality of policy gradient for markov coherent risk , author=. arXiv preprint arXiv:2103.02827 , year=
-
[22]
IEEE transactions on automatic control , volume=
Sequential decision making with coherent risk , author=. IEEE transactions on automatic control , volume=. 2016 , publisher=
work page 2016
-
[23]
Proceedings of the International Conference on Machine Learning (ICML) , pages=
On the global convergence of risk-averse policy gradient methods with expected conditional risk measures , author=. Proceedings of the International Conference on Machine Learning (ICML) , pages=. 2023 , organization=
work page 2023
-
[24]
SIAM Journal on Control and Optimization , volume=
Risk-sensitive Markov control processes , author=. SIAM Journal on Control and Optimization , volume=. 2013 , publisher=
work page 2013
-
[25]
Journal of Machine Learning Research , volume=
On the theory of policy gradient methods: Optimality, approximation, and distribution shift , author=. Journal of Machine Learning Research , volume=
- [26]
-
[27]
The annals of Statistics , pages=
Estimation of the mean of a multivariate normal distribution , author=. The annals of Statistics , pages=. 1981 , publisher=
work page 1981
-
[28]
Quantitative Finance , volume=
On elicitable risk measures , author=. Quantitative Finance , volume=. 2015 , publisher=
work page 2015
-
[29]
Proceedings of the aaai conference on artificial intelligence , volume=
Learning diverse risk preferences in population-based self-play , author=. Proceedings of the aaai conference on artificial intelligence , volume=
-
[30]
The Annals of Statistics , pages=
Higher order elicitability and Osband's principle , author=. The Annals of Statistics , pages=. 2016 , publisher=
work page 2016
-
[31]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Human-level control through deep reinforcement learning , author=. nature , volume=. 2015 , publisher=
work page 2015
- [33]
-
[34]
Risk-sensitive reinforcement learning , author=. Neural computation , volume=. 2014 , publisher=
work page 2014
-
[35]
Stochastic approximation: a dynamical systems viewpoint, Second Edition , author=. 2023 , publisher=
work page 2023
-
[36]
Reinforcement Learning Journal , year=
A simple mixture policy parameterization for improving sample efficiency of cvar optimization , author=. Reinforcement Learning Journal , year=
-
[37]
Proceedings of the International Conference on Machine Learning (ICML) , pages=
Return Capping: Sample-Efficient CVaR Policy Gradient Optimisation , author=. Proceedings of the International Conference on Machine Learning (ICML) , pages=
-
[38]
Openai gym , author=. arXiv preprint arXiv:1606.01540 , year=
work page internal anchor Pith review arXiv
-
[39]
2012 IEEE/RSJ international conference on intelligent robots and systems , pages=
Mujoco: A physics engine for model-based control , author=. 2012 IEEE/RSJ international conference on intelligent robots and systems , pages=. 2012 , organization=
work page 2012
-
[40]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
High-dimensional continuous control using generalized advantage estimation , author=. arXiv preprint arXiv:1506.02438 , year=
work page internal anchor Pith review arXiv
-
[41]
Foundations and trends in Machine Learning , volume=
Convex optimization: Algorithms and complexity , author=. Foundations and trends in Machine Learning , volume=. 2015 , publisher=
work page 2015
-
[42]
SIAM Journal on Control and Optimization , volume=
The ODE method for convergence of stochastic approximation and reinforcement learning , author=. SIAM Journal on Control and Optimization , volume=. 2000 , publisher=
work page 2000
-
[43]
Journal of Financial Econometrics , volume =
Barendse, Sander , title =. Journal of Financial Econometrics , volume =. 2026 , month =
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.