Recognition: no theorem link
EyeCue: Driver Cognitive Distraction Detection via Gaze-Empowered Egocentric Video Understanding
Pith reviewed 2026-05-11 02:24 UTC · model grok-4.3
The pith
EyeCue detects driver cognitive distraction by modeling interactions between eye gaze and visual context in egocentric video.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
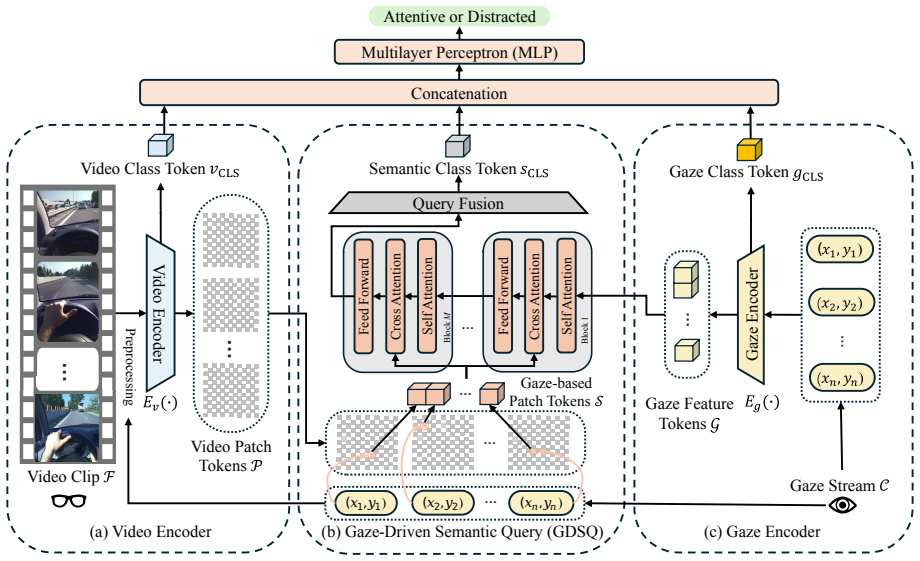
EyeCue is a gaze-empowered egocentric video understanding framework that detects driver cognitive distraction by integrating eye gaze with egocentric video to enable context-aware modeling of the driver's attention over time. On the introduced CogDrive dataset, formed by augmenting four existing driving datasets with cognitive distraction annotations, the framework achieves 74.38 percent accuracy, outperforming 11 baselines from six model families by over 7 percent, and sustains over 70 percent accuracy across diverse scenarios including different road types, times of day, and weather conditions.
What carries the argument
Gaze-context interaction modeling that captures how cognitive distraction appears in the changing relationship between where the driver looks and the surrounding visual scene.
If this is right
- Cognitive distraction detection becomes feasible at scale using only gaze and video without needing explicit physical movement cues.
- The same multimodal interaction approach generalizes to new driving conditions such as night driving or adverse weather.
- Augmenting existing video datasets with targeted annotations overcomes data scarcity for training attention models.
- Cross-modal fusion of gaze and scene context proves more effective than single-modality or non-interactive baselines for this task.
Where Pith is reading between the lines
- Vehicle safety systems could embed similar gaze-video models to issue real-time alerts when cognitive distraction is inferred.
- The interaction-modeling technique may transfer to other attention-critical settings such as pilot monitoring or industrial operators.
- Future validation against physiological sensors could refine or replace purely annotation-based labels for mental-state detection.
- The framework supplies a concrete way to study how visual attention drifts in dynamic real-world environments beyond driving.
Load-bearing premise
The cognitive distraction labels added to existing driving video datasets accurately reflect the driver's true internal mental state.
What would settle it
A controlled study that records simultaneous EEG or other brain-activity measures while drivers perform tasks with known cognitive loads and then checks whether the model's output classifications align with those physiological indicators.
Figures








read the original abstract
Driver cognitive distraction is a major cause of road collisions and remains difficult to detect. Unlike manual or visual distraction, cognitive distraction is diverted by thoughts unrelated to driving, even when the driver appears visually attentive and exhibits no explicit physical movements. In this work, we propose EyeCue, a gaze-empowered egocentric video understanding framework, to detect driver cognitive distraction. A key insight is that cognitive distraction manifests in the interaction between eye gaze and visual context. To capture this interaction, EyeCue integrates eye gaze with egocentric video to enable context-aware modeling of the driver's attention over time. Furthermore, to tackle the limited scale and diversity of existing datasets, we introduce CogDrive, a comprehensive multi-scenario dataset that augments four existing driving datasets with cognitive distraction annotations. Through extensive evaluations on CogDrive, we show that EyeCue achieves the highest accuracy of 74.38%, outperforming 11 baselines from 6 model families by over 7%. Notably, EyeCue can achieve an accuracy of over 70% across various driving scenarios (different road types, times of day, and weather conditions) with strong generalizability. These results highlight the importance of modeling gaze-context interactions and the effectiveness of cross-modal interaction modeling for multimodal cognitive distraction detection. Our codes and CogDrive dataset resources are available at https://github.com/langzhang2000/EyeCue.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes EyeCue, a multimodal framework that integrates eye gaze with egocentric video to model context-aware attention for detecting driver cognitive distraction (internal mental states unrelated to driving). It introduces CogDrive, a dataset created by augmenting four existing driving datasets with cognitive-distraction annotations, and reports that EyeCue achieves 74.38% accuracy on CogDrive while outperforming 11 baselines from 6 model families by more than 7%, with consistent results (>70% accuracy) across road types, times of day, and weather conditions. Code and dataset resources are released.
Significance. If the CogDrive labels validly capture internal cognitive states, the work would be significant for advancing driver monitoring by demonstrating the value of explicit gaze-context interaction modeling and by releasing a new multi-scenario benchmark. The public code and dataset release is a clear strength for reproducibility. However, the significance is limited by the absence of physiological validation for the labels, which directly affects whether the reported gains address the stated task of internal distraction detection.
major comments (2)
- [CogDrive dataset construction] CogDrive dataset construction: the cognitive distraction annotations rely on subjective video review of existing driving footage without reported physiological ground truth (EEG, fNIRS, or validated secondary-task protocols), inter-rater reliability statistics, or cross-validation against brain-activity measures. This is load-bearing for the central claim, because the 74.38% accuracy and >7% gains over baselines (Abstract and experimental section) become difficult to interpret if the labels primarily encode observable gaze or scene patterns rather than verified internal mental states.
- [Experimental evaluation] Experimental evaluation: no details are provided on baseline re-implementations, hyperparameter search, or statistical significance testing (e.g., McNemar or paired t-tests) for the reported performance differences. Without these, it is impossible to determine whether the outperformance is robust or could be explained by implementation variance.
minor comments (2)
- [Abstract] The abstract states 'over 7%' improvement but does not name the strongest baseline or the exact metric value for that baseline, reducing immediate clarity.
- [Method] Notation for the gaze-context fusion module could be clarified with an explicit equation or diagram reference in the method section to aid readers unfamiliar with egocentric video models.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications on our methodology and commitments to revisions where feasible.
read point-by-point responses
-
Referee: [CogDrive dataset construction] CogDrive dataset construction: the cognitive distraction annotations rely on subjective video review of existing driving footage without reported physiological ground truth (EEG, fNIRS, or validated secondary-task protocols), inter-rater reliability statistics, or cross-validation against brain-activity measures. This is load-bearing for the central claim, because the 74.38% accuracy and >7% gains over baselines (Abstract and experimental section) become difficult to interpret if the labels primarily encode observable gaze or scene patterns rather than verified internal mental states.
Authors: We acknowledge the referee's concern regarding label validity. The CogDrive annotations were generated via expert review of egocentric videos, identifying cognitive distraction based on gaze patterns inconsistent with driving demands, scene context, and absence of external distractions. This follows established practices in the field for video-based labeling when source datasets lack physiological signals. We agree that physiological ground truth would strengthen the claims and that its absence is a limitation. In revision, we will expand the dataset section with detailed annotation protocols, annotator information, and any available inter-rater statistics. We will also explicitly discuss this limitation and its implications for interpreting the results. revision: partial
-
Referee: [Experimental evaluation] Experimental evaluation: no details are provided on baseline re-implementations, hyperparameter search, or statistical significance testing (e.g., McNemar or paired t-tests) for the reported performance differences. Without these, it is impossible to determine whether the outperformance is robust or could be explained by implementation variance.
Authors: We appreciate this observation. The revised manuscript will include a new subsection detailing the re-implementation of all 11 baselines, specifying architectures, pre-training, and exact hyperparameter search procedures (ranges and selected values for learning rate, batch size, etc.). We will also add statistical significance testing using McNemar's test for the key performance comparisons to confirm the robustness of the reported gains. revision: yes
- Physiological validation (EEG/fNIRS or equivalent) for CogDrive labels, as no such data exists in the source datasets and cannot be retroactively obtained
Circularity Check
No circularity: empirical evaluation on held-out data with no self-referential derivations
full rationale
The paper introduces the EyeCue framework for gaze-context modeling and the CogDrive dataset with cognitive distraction annotations, then reports standard supervised classification accuracy (74.38%) and comparisons against 11 baselines on held-out splits. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The performance numbers are obtained via conventional train/test evaluation on the augmented dataset rather than any reduction of outputs to inputs by construction. The annotation process for labels is a data-preparation step, not a mathematical loop. This is a self-contained empirical ML contribution whose central claims do not collapse to tautology.
Axiom & Free-Parameter Ledger
free parameters (1)
- model hyperparameters and training thresholds
axioms (1)
- domain assumption Cognitive distraction manifests detectably in the interaction between eye gaze and visual driving context over time
Reference graph
Works this paper leans on
-
[1]
Structure and Interpretation of Computer Programs
Harold Abelson and Gerald Jay Sussman and Julie Sussman. Structure and Interpretation of Computer Programs. 1985
work page 1985
-
[2]
Visual Information Extraction with Lixto
Robert Baumgartner and Georg Gottlob and Sergio Flesca. Visual Information Extraction with Lixto. Proceedings of the 27th International Conference on Very Large Databases. 2001
work page 2001
-
[3]
Ronald J. Brachman and James G. Schmolze. An overview of the KL-ONE knowledge representation system. Cognitive Science. 1985
work page 1985
-
[4]
Complexity results for nonmonotonic logics
Georg Gottlob. Complexity results for nonmonotonic logics. Journal of Logic and Computation. 1992
work page 1992
-
[5]
Hypertree Decompositions and Tractable Queries
Georg Gottlob and Nicola Leone and Francesco Scarcello. Hypertree Decompositions and Tractable Queries. Journal of Computer and System Sciences. 2002
work page 2002
- [6]
- [7]
-
[8]
On the compilability and expressive power of propositional planning formalisms
Bernhard Nebel. On the compilability and expressive power of propositional planning formalisms. Journal of Artificial Intelligence Research. 2000
work page 2000
-
[9]
2023 IEEE Intelligent Vehicles Symposium (IV) , pages=
Driver gaze fixation and pattern analysis in safety critical events , author=. 2023 IEEE Intelligent Vehicles Symposium (IV) , pages=. 2023 , organization=
work page 2023
-
[10]
Human Factors in Transportation , volume=
A comprehensive safety analysis for gaze fixation of drivers to outside scene , author=. Human Factors in Transportation , volume=. 2022 , publisher=
work page 2022
-
[11]
2024 IEEE Intelligent Vehicles Symposium (IV) , pages=
Semantic understanding of traffic scenes with large vision language models , author=. 2024 IEEE Intelligent Vehicles Symposium (IV) , pages=. 2024 , organization=
work page 2024
-
[12]
2023 IEEE Intelligent Vehicles Symposium (IV) , pages=
Explainable driver activity recognition using video transformer in highly automated vehicle , author=. 2023 IEEE Intelligent Vehicles Symposium (IV) , pages=. 2023 , organization=
work page 2023
-
[13]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Egolife: Towards egocentric life assistant , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[14]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
From Gaze to Movement: Predicting Visual Attention for Autonomous Driving Human-Machine Interaction based on Programmatic Imitation Learning , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[15]
Is space-time attention all you need for video understanding? , author=. ICML , volume=
-
[16]
Advances in neural information processing systems , volume=
Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training , author=. Advances in neural information processing systems , volume=
-
[17]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Mv-adapter: Multimodal video transfer learning for video text retrieval , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[18]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
DGL: Dynamic global-local prompt tuning for text-video retrieval , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[19]
European Conference on Computer Vision , pages=
Internvideo2: Scaling foundation models for multimodal video understanding , author=. European Conference on Computer Vision , pages=. 2024 , organization=
work page 2024
-
[20]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding , author=. arXiv preprint arXiv:2501.13106 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Egovlpv2: Egocentric video-language pre-training with fusion in the backbone , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[22]
Egovideo: Exploring egocentric foundation model and downstream adaptation , author=. arXiv preprint arXiv:2406.18070 , year=
-
[23]
arXiv preprint arXiv:2208.04464 , year=
In the eye of transformer: Global-local correlation for egocentric gaze estimation , author=. arXiv preprint arXiv:2208.04464 , year=
-
[24]
IEEE Transactions on Multimedia , volume=
Driver yawning detection based on subtle facial action recognition , author=. IEEE Transactions on Multimedia , volume=. 2020 , publisher=
work page 2020
-
[25]
Measuring driver perception: Combining eye-tracking and automated road scene perception , author=. Human factors , volume=. 2022 , publisher=
work page 2022
-
[26]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Slowfast networks for video recognition , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[27]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
An image is worth 16x16 words: Transformers for image recognition at scale , author=. arXiv preprint arXiv:2010.11929 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[28]
Video-LLaVA: Learning United Visual Representation by Alignment Before Projection
Video-llava: Learning united visual representation by alignment before projection , author=. arXiv preprint arXiv:2311.10122 , year=
work page internal anchor Pith review arXiv
-
[29]
Advances in Neural Information Processing Systems , volume=
Voila-a: Aligning vision-language models with user's gaze attention , author=. Advances in Neural Information Processing Systems , volume=
-
[30]
Novel method for rapid assessment of cognitive impairment using high-performance eye-tracking technology , author=. Scientific reports , volume=. 2019 , publisher=
work page 2019
-
[31]
Proceedings of the Winter Conference on Applications of Computer Vision , pages=
Human Gaze Improves Vision Transformers by Token Masking , author=. Proceedings of the Winter Conference on Applications of Computer Vision , pages=
-
[32]
IEEE transactions on pattern analysis and machine intelligence , volume=
Predicting the Driver's Focus of Attention: the DR (eye) VE Project , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2018 , publisher=
work page 2018
-
[33]
arXiv preprint arXiv:2504.00221 , year=
GazeLLM: Multimodal LLMs incorporating Human Visual Attention , author=. arXiv preprint arXiv:2504.00221 , year=
-
[34]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Videollm-online: Online video large language model for streaming video , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[35]
Advances in neural information processing systems , volume=
Flashattention: Fast and memory-efficient exact attention with io-awareness , author=. Advances in neural information processing systems , volume=
-
[36]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
GazeVQA: A video question answering dataset for multiview eye-gaze task-oriented collaborations , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2023
- [37]
-
[38]
The Kinetics Human Action Video Dataset
The kinetics human action video dataset , author=. arXiv preprint arXiv:1705.06950 , year=
work page internal anchor Pith review arXiv
-
[39]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Taco: Benchmarking generalizable bimanual tool-action-object understanding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[40]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Object-aware gaze target detection , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[41]
IEEE Transactions on Automation Science and Engineering , volume=
A temporal--spatial deep learning approach for driver distraction detection based on EEG signals , author=. IEEE Transactions on Automation Science and Engineering , volume=. 2021 , publisher=
work page 2021
-
[42]
IEEE Sensors Journal , volume=
Smartphone inertial measurement unit data features for analyzing driver driving behavior , author=. IEEE Sensors Journal , volume=. 2023 , publisher=
work page 2023
-
[43]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Aide: A vision-driven multi-view, multi-modal, multi-tasking dataset for assistive driving perception , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[44]
Accident Analysis & Prevention , volume=
Detection of driver manual distraction via image-based hand and ear recognition , author=. Accident Analysis & Prevention , volume=. 2020 , publisher=
work page 2020
-
[45]
Mind-wandering tends to occur under low perceptual demands during driving , author=. Scientific reports , volume=. 2016 , publisher=
work page 2016
-
[46]
2024 IEEE Intelligent Vehicles Symposium (IV) , pages=
ViT-DD: Multi-task vision transformer for semi-supervised driver distraction detection , author=. 2024 IEEE Intelligent Vehicles Symposium (IV) , pages=. 2024 , organization=
work page 2024
-
[47]
Risk assessment of driver performance in the oil and gas transportation industry: Analyzing the relationship between driver vigilance, attention, reaction time, and safe driving practices , author=. Heliyon , volume=. 2024 , publisher=
work page 2024
-
[48]
Open Access Emergency Medicine , pages=
Measuring situation awareness in emergency setting: a systematic review of tools and outcomes , author=. Open Access Emergency Medicine , pages=. 2014 , publisher=
work page 2014
-
[49]
IEEE Sensors Journal , volume=
Driver distraction from the EEG perspective: A review , author=. IEEE Sensors Journal , volume=. 2023 , publisher=
work page 2023
-
[50]
Cognitive load classification of mixed reality human computer interaction tasks based on multimodal sensor signals , author=. Scientific Reports , volume=. 2025 , publisher=
work page 2025
-
[51]
Proceedings of the 2023 CHI conference on human factors in computing systems , pages=
Bubbleu: Exploring augmented reality game design with uncertain ai-based interaction , author=. Proceedings of the 2023 CHI conference on human factors in computing systems , pages=
work page 2023
-
[52]
2022 IEEE International Symposium on Mixed and Augmented Reality Adjunct (ISMAR-Adjunct) , pages=
Industrial augmented reality: lessons learned from a long-term on-site assessment of augmented reality maintenance worker support systems , author=. 2022 IEEE International Symposium on Mixed and Augmented Reality Adjunct (ISMAR-Adjunct) , pages=. 2022 , organization=
work page 2022
-
[53]
International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=
Efficient spatiotemporal learning of microscopic video for augmented reality-guided phacoemulsification cataract surgery , author=. International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=. 2023 , organization=
work page 2023
-
[54]
Project Aria: A New Tool for Egocentric Multi-Modal AI Research
Project aria: A new tool for egocentric multi-modal ai research , author=. arXiv preprint arXiv:2308.13561 , year=
work page internal anchor Pith review arXiv
-
[55]
2020 IEEE Intelligent Vehicles Symposium (IV) , pages=
Toward real-time estimation of driver situation awareness: An eye-tracking approach based on moving objects of interest , author=. 2020 IEEE Intelligent Vehicles Symposium (IV) , pages=. 2020 , organization=
work page 2020
-
[56]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[57]
Driver Distraction Detection Methods: A Literature Review and Framework , year=
Kashevnik, Alexey and Shchedrin, Roman and Kaiser, Christian and Stocker, Alexander , journal=. Driver Distraction Detection Methods: A Literature Review and Framework , year=
-
[58]
Transportation research interdisciplinary perspectives , volume=
Evaluating driver cognitive distraction by eye tracking: From simulator to driving , author=. Transportation research interdisciplinary perspectives , volume=. 2020 , publisher=
work page 2020
-
[59]
ACM Transactions on Applied Perception (TAP) , volume=
Discerning ambient/focal attention with coefficient K , author=. ACM Transactions on Applied Perception (TAP) , volume=. 2016 , publisher=
work page 2016
-
[60]
2020 IEEE International Symposium on Multimedia (ISM) , pages=
Measuring driver situation awareness using region-of-interest prediction and eye tracking , author=. 2020 IEEE International Symposium on Multimedia (ISM) , pages=. 2020 , organization=
work page 2020
-
[61]
Transportation Research Part F: Traffic Psychology and Behaviour , volume=
Visual search while driving: skill and awareness during inspection of the scene , author=. Transportation Research Part F: Traffic Psychology and Behaviour , volume=. 2002 , publisher=
work page 2002
-
[62]
2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC) , pages=
Multi-view region of interest prediction for autonomous driving using semi-supervised labeling , author=. 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC) , pages=. 2020 , organization=
work page 2020
-
[63]
Attention to speed and guide traffic signs with eye movements , author=. Psicothema , volume=
-
[64]
arXiv preprint arXiv:2503.09143 , year=
Exo2ego: Exocentric knowledge guided mllm for egocentric video understanding , author=. arXiv preprint arXiv:2503.09143 , year=
-
[65]
IEEE transactions on intelligent transportation systems , volume=
Real-time detection of driver cognitive distraction using support vector machines , author=. IEEE transactions on intelligent transportation systems , volume=. 2007 , publisher=
work page 2007
-
[66]
Driver's distraction detection based on gaze estimation , author=. 2016 international conference on advances in computing, communications and informatics (icacci) , pages=. 2016 , organization=
work page 2016
-
[67]
The distracted mind on the wheel: Overall propensity to mind wandering is associated with road crash responsibility , author=. PloS one , volume=. 2017 , publisher=
work page 2017
-
[68]
Transportation research record , volume=
Systematic review of research on driver distraction in the context of advanced driver assistance systems , author=. Transportation research record , volume=. 2021 , publisher=
work page 2021
-
[69]
Nature Reviews Neuroscience , volume=
Visual objects in context , author=. Nature Reviews Neuroscience , volume=. 2004 , publisher=
work page 2004
-
[70]
Eye movements and hazard perception in active and passive driving , author=. Visual cognition , volume=. 2015 , publisher=
work page 2015
- [71]
- [72]
-
[73]
Accident Analysis & Prevention , volume=
Investigating the impact of driving automation systems on distracted driving behaviors , author=. Accident Analysis & Prevention , volume=. 2021 , publisher=
work page 2021
-
[74]
Driver distraction: A review of the literature , author=. Distracted driving , volume=
-
[75]
IEEE Transactions on Intelligent Vehicles , year=
Bevgpt: Generative pre-trained foundation model for autonomous driving prediction, decision-making, and planning , author=. IEEE Transactions on Intelligent Vehicles , year=
-
[76]
Proceedings of the 15th biannual conference of the Italian SIGCHI chapter , pages=
VisionARy: exploratory research on contextual language learning using AR glasses with ChatGPT , author=. Proceedings of the 15th biannual conference of the Italian SIGCHI chapter , pages=
- [77]
-
[78]
IEEE Transactions on Reliability , volume=
L-tla: A lightweight driver distraction detection method based on three-level attention mechanisms , author=. IEEE Transactions on Reliability , volume=. 2024 , publisher=
work page 2024
-
[79]
A hybrid deep learning approach for driver distraction detection , author=. 2020 international conference on information and communication technology convergence (ICTC) , pages=. 2020 , organization=
work page 2020
-
[80]
arXiv preprint arXiv:2506.23088 , year=
Where, What, Why: Towards Explainable Driver Attention Prediction , author=. arXiv preprint arXiv:2506.23088 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.