Recognition: 2 theorem links
· Lean TheoremBlack-box model classification under the discriminative factorization
Pith reviewed 2026-05-11 02:21 UTC · model grok-4.3
The pith
A discriminative factorization of black-box model responses separates effective query sets from ineffective ones, causing the probability of chance-level classification to decay exponentially as the query budget grows.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
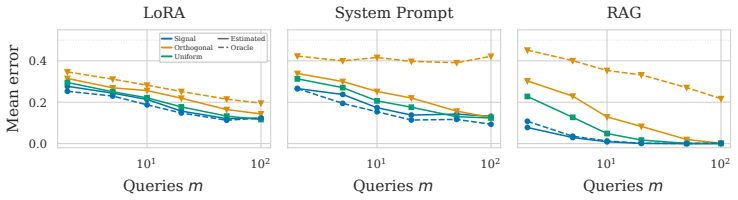
We introduce the discriminative factorization to distinguish between high- and low-quality query sets in the context of black-box model-level classification. Under this framework, the probability of chance-level classification decays exponentially in the query budget. On three auditing tasks, estimated factorization parameters predict the empirical performance decay rate. Query sets selected using the estimated discriminative field reproduce the empirical ordering of oracle query sets.
What carries the argument
The discriminative factorization: a low-dimensional embedding of model responses to a query set whose structure separates high- from low-quality queries and whose parameters control the exponential decay of classification error.
If this is right
- Estimated factorization parameters predict the rate at which classification performance improves with query budget on auditing tasks.
- Query sets chosen using the estimated discriminative field match the empirical ordering of the best possible oracle query sets.
- The exponential decay of chance-level error holds across multiple distinct model auditing scenarios.
Where Pith is reading between the lines
- If the low-dimensional embedding property generalizes, the factorization could guide automated selection of queries for auditing proprietary models with limited budgets.
- The exponential relationship implies that small improvements in query quality produce increasingly large gains in classification reliability as the allowed number of queries grows.
- Similar factorization techniques might extend to other black-box settings where response embeddings are used to infer hidden model properties.
Load-bearing premise
Black-box model responses to query sets admit low-dimensional embeddings whose structure permits a factorization that cleanly separates high- and low-quality query sets, with parameters that can be estimated without circularly fitting to the same classification performance data.
What would settle it
On a new auditing task the estimated factorization parameters fail to predict the observed decay rate of classification accuracy, or query sets selected via the estimated discriminative field do not reproduce the effectiveness ordering of oracle query sets.
Figures


read the original abstract
Access to modern generative systems is often restricted to querying an API (the ``black-box" setting) and many properties of the system are unknown to the user at inference time. While recent work has shown that low-dimensional representations of models based on the relationship between their embedded responses to a set of queries are useful for inferring model-level properties, the quality of these representations is highly sensitive to the query set. We introduce the \emph{discriminative factorization} to distinguish between high- and low-quality query sets in the context of black-box model-level classification. Under this framework, the probability of chance-level classification decays exponentially in the query budget. On three auditing tasks, estimated factorization parameters predict the empirical performance decay rate. We conclude by showing that query sets selected using the estimated discriminative field reproduce the empirical ordering of oracle query sets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the discriminative factorization framework to distinguish high- and low-quality query sets for black-box model-level classification tasks. It claims that the probability of chance-level classification decays exponentially in the query budget. On three auditing tasks, estimated factorization parameters are asserted to predict the empirical performance decay rate, and query sets selected using the estimated discriminative field are shown to reproduce the empirical ordering of oracle query sets.
Significance. If the exponential decay can be derived rigorously from the factorization and the parameter estimation shown to be independent of performance data, the work would offer a useful theoretical and practical advance for query budgeting and selection in API-restricted auditing of generative models. The ability to predict decay rates and approximate oracle orderings without direct performance feedback could reduce the cost of black-box evaluations. However, the absence of derivations, embedding details, and non-circular estimation procedures substantially reduces the assessed significance at present.
major comments (3)
- [Abstract] Abstract: The claim that 'the probability of chance-level classification decays exponentially in the query budget' is load-bearing for the entire framework, yet the manuscript provides no derivation, embedding construction, or statistical model supporting the exponential form.
- [Abstract] Abstract: The statement that 'estimated factorization parameters predict the empirical performance decay rate' on three auditing tasks is central to the contribution, but the abstract supplies no information on whether parameter estimation (via matrix decomposition or optimization over embeddings) uses only query-response structure or also incorporates the classification accuracy/decay statistics from the same tasks; this leaves the prediction claim vulnerable to circularity.
- [Abstract] Abstract: The claim that 'query sets selected using the estimated discriminative field reproduce the empirical ordering of oracle query sets' requires explicit construction of the discriminative field and confirmation that its estimation is unsupervised with respect to oracle performance; without these details the reproduction result cannot be evaluated.
minor comments (2)
- [Abstract] The abstract introduces the terms 'discriminative factorization' and 'discriminative field' without even a one-sentence definition, impairing immediate readability.
- [Abstract] No metrics, error bars, controls, or task descriptions are referenced for the three auditing tasks, which would be needed to assess the strength of the empirical claims.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight areas where the abstract and manuscript can be clarified. We address each major comment below, providing references to the relevant sections and outlining revisions to strengthen the presentation of the discriminative factorization framework.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'the probability of chance-level classification decays exponentially in the query budget' is load-bearing for the entire framework, yet the manuscript provides no derivation, embedding construction, or statistical model supporting the exponential form.
Authors: The exponential decay is derived in Section 3 from the discriminative factorization model. The query-response matrix is decomposed into a low-rank discriminative component and isotropic noise; under the assumption of query independence, the probability of misclassification follows a binomial tail that yields exponential decay in the query budget with rate governed by the discriminative singular value. The embedding construction uses a fixed pre-trained encoder applied to model responses. We will add a concise statement of this derivation and the underlying statistical model to the abstract. revision: yes
-
Referee: [Abstract] Abstract: The statement that 'estimated factorization parameters predict the empirical performance decay rate' on three auditing tasks is central to the contribution, but the abstract supplies no information on whether parameter estimation (via matrix decomposition or optimization over embeddings) uses only query-response structure or also incorporates the classification accuracy/decay statistics from the same tasks; this leaves the prediction claim vulnerable to circularity.
Authors: Parameter estimation is performed exclusively via singular-value decomposition on the matrix of embedded responses to the query set; no classification accuracy or decay-rate statistics enter the decomposition. The subsequent comparison of estimated parameters against empirical decay rates is a separate validation step conducted on held-out performance data. We will revise the abstract to explicitly state that estimation uses only query-response structure and is independent of performance metrics. revision: yes
-
Referee: [Abstract] Abstract: The claim that 'query sets selected using the estimated discriminative field reproduce the empirical ordering of oracle query sets' requires explicit construction of the discriminative field and confirmation that its estimation is unsupervised with respect to oracle performance; without these details the reproduction result cannot be evaluated.
Authors: The discriminative field is constructed as the leading left singular vectors of the factorized query-response matrix (Section 4). Estimation operates solely on the black-box responses and is therefore unsupervised with respect to any oracle performance labels. Query sets are then ranked by the norm of their projections onto this field. We will include a brief description of this construction and its unsupervised character in the revised abstract. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The abstract and described framework present the discriminative factorization as a model for distinguishing query-set quality, with exponential decay as a derived property and parameter estimation performed on response embeddings. The claim that estimated parameters predict empirical decay rates is a validation step comparing independent quantities (embedding-derived parameters vs. observed classification performance), not a reduction of one to the other by construction. No self-definitional equations, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided text. The derivation remains self-contained against external benchmarks of query-set performance.
Axiom & Free-Parameter Ledger
free parameters (1)
- factorization parameters
axioms (1)
- domain assumption Black-box model responses to queries admit low-dimensional embeddings based on their relationships that support a discriminative factorization separating query quality.
invented entities (2)
-
discriminative factorization
no independent evidence
-
discriminative field
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
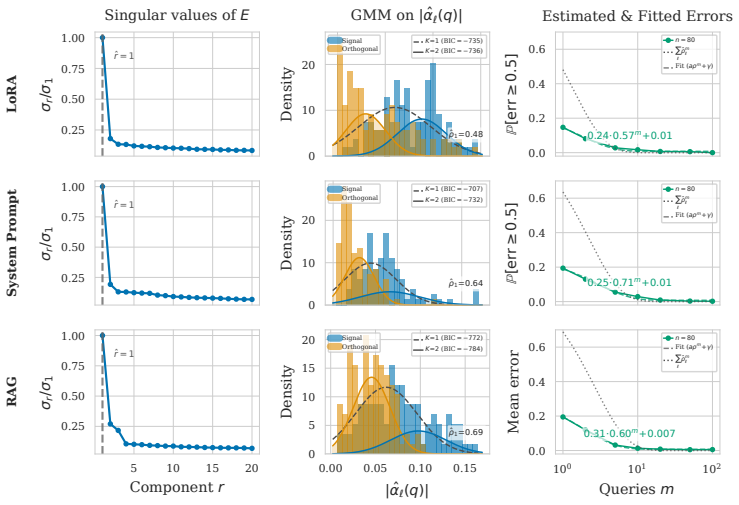
Definition 1. ... d²_P(Pf(q), Pf'(q)) = Σ_ℓ α_ℓ(q) ϕ_ℓ(f,f') ... zero-set probabilities ρ_ℓ = Π_Q(Z_ℓ) ... Theorem 1 ... ≤ Σ ρ_ℓ^m + γ(n)
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Estimation from spectral structure ... SVD of E ... ˆr = argmax σ_s/σ_{s+1} ... GMM on |ˆα_ℓ(qj)|
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Aranyak Acharyya, Michael W. Trosset, Carey E. Priebe, and Hayden S. Helm. Consistent estimation of generative model representations in the data kernel perspective space.arXiv preprint arXiv:2409.17308, 2024
-
[2]
Intrinsic dimensionality explains the effectiveness of language model fine-tuning
Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics, pages 7319–7328, 2021
work page 2021
-
[3]
Query-efficient model evaluation using cached responses
Anonymous. Query-efficient model evaluation using cached responses. InForty-third Inter- national Conference on Machine Learning, 2026. URLhttps://openreview.net/forum? id=LPkaP2roeE
work page 2026
-
[4]
Claude Sonnet 4.5 system card, 2025
Anthropic. Claude Sonnet 4.5 system card, 2025. URL https://assets.anthropic.com/ m/12f214efcc2f457a/original/Claude-Sonnet-4-5-System-Card.pdf
work page 2025
-
[5]
Extracting training data from large language models
Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-V oss, Kather- ine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, Alina Oprea, and Colin Raffel. Extracting training data from large language models. InUSENIX Security Symposium, 2021
work page 2021
-
[6]
Helm, Kate Lytvynets, Weiwei Yang, and Carey E
Guodong Chen, Hayden S. Helm, Kate Lytvynets, Weiwei Yang, and Carey E. Priebe. Mental state classification using multi-graph features.Frontiers in Human Neuro- science, V olume 16 - 2022, 2022. ISSN 1662-5161. doi: 10.3389/fnhum.2022.930291. URLhttps://www.frontiersin.org/journals/human-neuroscience/articles/10. 3389/fnhum.2022.930291
-
[7]
Extracting infor- mation from fine-tuned weights
Nan Chen, Hayden Helm, Youngser Park, Carey Priebe, and Soledad Villar. Extracting infor- mation from fine-tuned weights. InNon-Euclidean Foundation Models: Advancing AI Beyond Euclidean Frameworks, 2025. URLhttps://openreview.net/forum?id=zjwOD3Fwrq
work page 2025
-
[8]
Luc Devroye, László Györfi, and Gábor Lugosi.A Probabilistic Theory of Pattern Recognition. Springer, New York, 1996
work page 1996
-
[9]
Do membership inference attacks work on large language models?arXiv preprint arXiv:2402.07841, 2024
Michael Duan, Anshuman Suri, Niloofar Mireshghallah, Sewon Min, Weijia Shi, Luke Zettle- moyer, Yulia Tsvetkov, Yejin Choi, David Evans, and Hannaneh Hajishirzi. Do membership inference attacks work on large language models?, 2024. URL https://arxiv.org/abs/ 2402.07841
-
[10]
Brandon Duderstadt, Hayden S. Helm, and Carey E. Priebe. Comparing foundation models using data kernels, 2024. URLhttps://arxiv.org/abs/2305.05126
-
[11]
Pál Erd˝os and Alfréd Rényi. On a classical problem of probability theory.A Magyar Tudományos Akadémia Matematikai Kutató Intézetének Közleményei, 6(1-2):215–220, 1961
work page 1961
-
[12]
Retrieval-Augmented Generation for Large Language Models: A Survey
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, and Haofen Wang. Retrieval-augmented generation for large language models: A survey, 2024. URLhttps://arxiv.org/abs/2312.10997
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Google DeepMind. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodal- ity, long context, and next generation agentic capabilities, 2025. URL https://storage. googleapis.com/deepmind-media/gemini/gemini_v2_5_report.pdf
work page 2025
-
[14]
Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey
Zeyu Han, Chao Gao, Jinyang Liu, Jeff Zhang, and Sai Qian Zhang. Parameter-efficient fine- tuning for large models: A comprehensive survey, 2024. URL https://arxiv.org/abs/ 2403.14608. 10
work page internal anchor Pith review arXiv 2024
-
[15]
Tracking the per- spectives of interacting language models
Hayden Helm, Brandon Duderstadt, Youngser Park, and Carey Priebe. Tracking the per- spectives of interacting language models. In Yaser Al-Onaizan, Mohit Bansal, and Yun- Nung Chen, editors,Proceedings of the 2024 Conference on Empirical Methods in Natu- ral Language Processing, pages 1508–1519, Miami, Florida, USA, November 2024. As- sociation for Computa...
-
[16]
Statistical inference on black-box generative models in the data kernel perspective space
Hayden Helm, Aranyak Acharyya, Youngser Park, Brandon Duderstadt, and Carey Priebe. Statistical inference on black-box generative models in the data kernel perspective space. In Findings of the Association for Computational Linguistics: ACL 2025, pages 3955–3970, Vienna, Austria, 2025. Association for Computational Linguistics
work page 2025
-
[17]
The platonic representation hypothesis
Minyoung Huh, Brian Cheung, Tongzhou Wang, and Phillip Isola. The platonic representation hypothesis. InProceedings of the 41st International Conference on Machine Learning. PMLR, 2024
work page 2024
-
[18]
Datamodels: Understanding predictions with data and data with predictions
Andrew Ilyas, Sung Min Park, Logan Engstrom, Guillaume Leclerc, and Aleksander Madry. Datamodels: Understanding predictions with data and data with predictions. InProceedings of the 39th International Conference on Machine Learning, volume 162 ofProceedings of Machine Learning Research, pages 9525–9587. PMLR, 2022
work page 2022
-
[19]
TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension
Mandar Joshi, Eunsol Choi, Daniel S Weld, and Luke Zettlemoyer. TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics, pages 1601–1611, 2017
work page 2017
-
[20]
arXiv preprint arXiv:2512.05117 (2025)
Prakhar Kaushik, Shravan Chaudhari, Ankit Vaidya, Rama Chellappa, and Alan Yuille. The universal weight subspace hypothesis, 2025. URLhttps://arxiv.org/abs/2512.05117
-
[21]
Similarity of neural network representations revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representations revisited. InProceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 3519–3529. PMLR, 2019
work page 2019
-
[22]
Casey Meehan, Florian Bordes, Pascal Vincent, Kamalika Chaudhuri, and Chuan Guo
Pratyush Maini, Hengrui Jia, Nicolas Papernot, and Adam Dziedzic. Llm dataset inference: Did you train on my dataset?, 2024. URLhttps://arxiv.org/abs/2406.06443
-
[23]
Zach Nussbaum, John X Morris, Brandon Duderstadt, and Andriy Mulyar. Nomic embed: Training a reproducible long context text embedder.arXiv preprint arXiv:2402.01613, 2024
-
[24]
OpenAI. GPT-5 system card, 2025. URLhttps://cdn.openai.com/gpt-5-system-card. pdf
work page 2025
-
[25]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick La...
work page 2024
-
[26]
F. Pedregosa, G. Varoquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V . Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay. Scikit-learn: Machine learning in Python.Journal of Machine Learning Research, 12:2825–2830, 2011
work page 2011
-
[27]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceed- ings of the 38th International Conference on Machine Learning, volume 139 ofProceedings...
work page 2021
-
[28]
Adrian E. Raftery. Bayesian model selection in social research.Sociological Methodology, 25: 111–163, 1995. 11
work page 1995
-
[29]
Maithra Raghu, Justin Gilmer, Jason Yosinski, and Jascha Sohl-Dickstein. SVCCA: Singu- lar vector canonical correlation analysis for deep learning dynamics and interpretability. In Advances in Neural Information Processing Systems, volume 30, pages 6076–6085. Curran Associates, Inc., 2017
work page 2017
-
[30]
Sentence-BERT: Sentence embeddings using Siamese BERT-networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence embeddings using Siamese BERT-networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Lan- guage Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3982–3992, Hong Kong, China, 2019. Association for Computational Linguistics
work page 2019
-
[31]
Maria L. Rizzo and Gábor J. Székely. Energy distance.Wiley Interdisciplinary Reviews: Computational Statistics, 8(1):27–38, 2016
work page 2016
-
[32]
A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications
Pranab Sahoo, Ayush Kumar Singh, Sriparna Saha, Vinija Jain, Samrat Mondal, and Aman Chadha. A systematic survey of prompt engineering in large language models: Techniques and applications, 2025. URLhttps://arxiv.org/abs/2402.07927
work page internal anchor Pith review arXiv 2025
-
[33]
I. J. Schoenberg. Metric spaces and positive definite functions.Transactions of the American Mathematical Society, 44(3):522–536, 1938
work page 1938
-
[34]
Detecting pretraining data from large language models
Weijia Shi, Anirudh Ajith, Mengzhou Xia, Yangsibo Huang, Daogao Liu, Terra Blevins, Danqi Chen, and Luke Zettlemoyer. Detecting pretraining data from large language models. InThe Twelfth International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[35]
Membership inference attacks against machine learning models
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. Membership inference attacks against machine learning models. InIEEE Symposium on Security and Privacy, pages 3–18. IEEE, 2017
work page 2017
-
[36]
Gábor J. Székely and Maria L. Rizzo. Testing for equal distributions in high dimension.InterStat, 5(16.10):1249–1272, 2004
work page 2004
-
[37]
Gábor J. Székely and Maria L. Rizzo. Energy statistics: A class of statistics based on distances. Journal of Statistical Planning and Inference, 143(8):1249–1272, 2013
work page 2013
- [38]
-
[39]
Per-Åke Wedin. Perturbation bounds in connection with singular value decomposition.BIT Numerical Mathematics, 12(1):99–111, 1972
work page 1972
-
[40]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11975–11986, 2023
work page 2023
-
[41]
Who’s the President of your country?
Xiang Zhang, Junbo Zhao, and Yann LeCun. Character-level convolutional networks for text classification. InAdvances in Neural Information Processing Systems, volume 28, 2015. A Theoretical Results In order to prove Theorem 1, we first prove Theorem 2. A.1 Bayes-optimal classification (Theorem 2) Proof.We are interested in the risk of a classifierh (n) d t...
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.