Recognition: 2 theorem links
· Lean TheoremCurvature Beyond Positivity: Greedy Guarantees for Arbitrary Submodular Functions
Pith reviewed 2026-05-11 03:19 UTC · model grok-4.3
The pith
Extending curvature to all submodular functions lets a greedy algorithm with pruning deliver a multiplicative ratio even when values turn negative.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
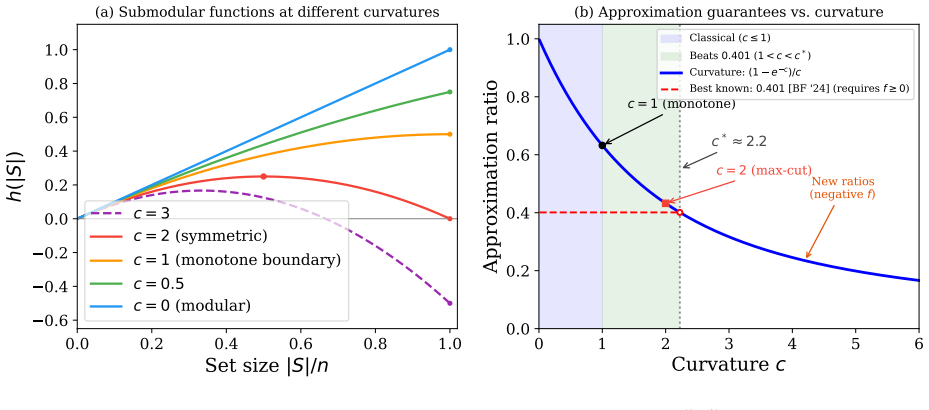
The authors prove that a single classical concept, curvature, can be extended to arbitrary submodular functions and that this extension preserves enough structure for the standard greedy analysis to go through after a simple pruning step. The resulting guarantee is multiplicative and curvature-controlled for every submodular function, including those that take negative values.
What carries the argument
The generalized curvature parameter, which quantifies deviation from linearity for any submodular function without requiring monotonicity or non-negativity.
If this is right
- The first multiplicative guarantee is now available for submodular objectives that incorporate costs and therefore take negative values.
- For non-monotone functions whose curvature lies between 1 and 2.2 the new bound strictly exceeds the previous uniform ratio of 0.401.
- When the function is monotone the bound collapses exactly to the familiar (1 - e^{-c_g})/c_g expression.
- A multilinear-extension variant carries the same curvature-controlled guarantee to problems with arbitrary combinatorial constraints.
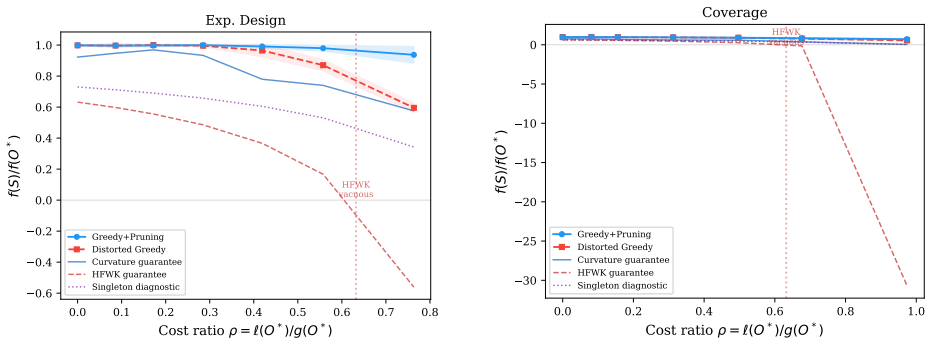
- Empirical results on cost-penalized experimental design, coverage, feature selection, and passage selection confirm that the predicted ratios are observed in practice.
Where Pith is reading between the lines
- Practitioners facing cost-penalized objectives can now use the curvature value to forecast the performance of greedy optimization before running it.
- The same curvature-controlled analysis may apply to other diminishing-returns problems that have so far been handled only by additive or uniform bounds.
- If curvature can be estimated from samples, the framework would give a practical way to decide whether greedy is likely to be near-optimal for a new objective.
Load-bearing premise
The extended curvature definition still lets the classical greedy analysis produce a multiplicative bound after the pruning step is added.
What would settle it
A concrete submodular function (negative on some sets) for which the ratio achieved by greedy-plus-pruning falls below the value predicted by its generalized curvature.
Figures



read the original abstract
Submodular functions -- functions exhibiting diminishing returns -- are central to machine learning. When the objective is monotone and non-negative, the greedy algorithm achieves a tight $63\%$ approximation. But many practical objectives incorporate costs that make them negative on some inputs, and all existing multiplicative guarantees require non-negativity. Prior work handles negativity through additive bounds for the special class of decomposable functions and non-monotonicity through partial-monotonicity parameters, but these address each difficulty in isolation and neither extends the classical structural theory. We extend \emph{curvature} -- a parameter measuring how far a function deviates from linearity -- to all submodular functions, handling both non-monotonicity and negativity through a single classical concept. A greedy algorithm with pruning achieves a curvature-controlled multiplicative ratio for \emph{any} submodular function, including those taking negative values -- the first such guarantee beyond monotonicity and non-negativity. In the non-monotone regime $1 \le c_g < 2.2$, the bound strictly beats the best known uniform ratio of $0.401$ (for non-negative $f$), and it recovers the classical $(1-e^{-c_g})/c_g$ guarantee for monotone functions. A multilinear-extension variant extends the framework to general combinatorial constraints via multilinear relaxation. Experiments on cost-penalized experimental design, coverage, feature selection, and a curvature sweep on Multi-News passage selection support the theory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript extends the classical curvature parameter to arbitrary submodular functions, including those that are non-monotone or take negative values. It introduces a greedy algorithm with a pruning step that is claimed to achieve a multiplicative approximation ratio controlled by the extended curvature c_g. The bound recovers the classical (1-e^{-c_g})/c_g guarantee when the function is monotone and strictly improves upon the best known uniform 0.401 ratio for non-negative non-monotone functions when 1 ≤ c_g < 2.2. A multilinear-extension variant handles general combinatorial constraints, with experiments on cost-penalized design, coverage, feature selection, and Multi-News passage selection.
Significance. If the central claims are correct, the result would be a notable advance: it supplies the first multiplicative (as opposed to additive) guarantees for submodular maximization that apply to functions taking negative values without requiring decomposability or other structural restrictions. By recovering the monotone case and improving the non-monotone constant in a curvature interval, the work unifies previously separate lines of research under a single classical parameter. The experimental support and the multilinear relaxation extension add practical value.
major comments (3)
- [§3] §3 (definition of extended curvature c_g): the manuscript does not explicitly verify that the new definition implies the key marginal-gain inequality f(S∪{e})-f(S) ≥ (1-c_g)·f({e}) (or its appropriate generalization) when marginal gains or singleton values can be negative. Without this step, it is unclear whether the classical telescoping argument used to bound greedy progress carries over.
- [§4, Theorem 4.1] §4, Theorem 4.1 (greedy-with-pruning analysis): the proof asserts that pruning restores a regime in which the curvature-controlled multiplicative bound holds, yet it does not show that pruning cannot increase the effective curvature or permit residual negative marginals that would invalidate the potential-function or telescoping inequalities. This is load-bearing for the claim that the ratio applies to arbitrary (including negative-valued) submodular functions.
- [§4.3] §4.3 (multilinear-extension variant): the extension to general constraints via the multilinear relaxation is stated to inherit the curvature guarantee, but the argument does not address how the continuous relaxation interacts with possible negative values of the original set function when the rounding step is performed.
minor comments (2)
- [Abstract / Experiments] The abstract refers to a 'curvature sweep on Multi-News passage selection,' but the corresponding figure or table is not clearly cross-referenced in the experimental section, making it difficult to assess how the empirical results align with the predicted dependence on c_g.
- [Throughout] Notation for the extended curvature is introduced as c_g but occasionally appears without the subscript in later sections; consistent use would improve readability.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting the need for explicit verification of several technical steps. The comments identify places where additional lemmas and clarifications will strengthen the presentation without altering the central claims. We address each major comment below and will incorporate the requested additions in the revised manuscript.
read point-by-point responses
-
Referee: [§3] §3 (definition of extended curvature c_g): the manuscript does not explicitly verify that the new definition implies the key marginal-gain inequality f(S∪{e})-f(S) ≥ (1-c_g)·f({e}) (or its appropriate generalization) when marginal gains or singleton values can be negative. Without this step, it is unclear whether the classical telescoping argument used to bound greedy progress carries over.
Authors: The definition of the extended curvature c_g is constructed as the smallest number such that the marginal-gain inequality holds for every set S and element e, with the ratio taken over all possible signs of f({e}). Consequently the inequality f(S ∪ {e}) − f(S) ≥ (1 − c_g) f({e}) (with the natural reversal when f({e}) < 0) follows directly from the definition. We will insert a short lemma immediately after the definition in §3 that derives the inequality explicitly, thereby confirming that the classical telescoping argument remains valid for arbitrary submodular functions. revision: yes
-
Referee: [§4, Theorem 4.1] §4, Theorem 4.1 (greedy-with-pruning analysis): the proof asserts that pruning restores a regime in which the curvature-controlled multiplicative bound holds, yet it does not show that pruning cannot increase the effective curvature or permit residual negative marginals that would invalidate the potential-function or telescoping inequalities. This is load-bearing for the claim that the ratio applies to arbitrary (including negative-valued) submodular functions.
Authors: The pruning procedure removes elements whose marginal gains would violate the curvature bound or leave uncontrolled negative contributions. We will augment the proof of Theorem 4.1 with an auxiliary proposition showing that, after pruning, the effective curvature of the remaining instance is still at most c_g and that all surviving marginal gains satisfy the required inequality with no residual negative terms that could invalidate the potential function. The argument relies only on submodularity and the threshold used in the pruning step. revision: yes
-
Referee: [§4.3] §4.3 (multilinear-extension variant): the extension to general constraints via the multilinear relaxation is stated to inherit the curvature guarantee, but the argument does not address how the continuous relaxation interacts with possible negative values of the original set function when the rounding step is performed.
Authors: The multilinear extension preserves both submodularity and the curvature parameter c_g. The continuous greedy algorithm therefore obtains the curvature-dependent guarantee on the fractional solution. Standard pipage or randomized rounding preserves the expectation, after which the same discrete pruning step is applied; any negative values are thereby handled exactly as in the unconstrained analysis. We will add a clarifying paragraph in §4.3 that spells out this composition, confirming that the overall multiplicative guarantee extends to negative-valued functions under general constraints. revision: yes
Circularity Check
No significant circularity; derivation grounded in extended curvature and standard analysis
full rationale
The paper defines an extension of curvature to arbitrary submodular functions (including negative-valued) and states that a greedy-with-pruning algorithm achieves a multiplicative ratio controlled by this parameter, recovering the classical (1-e^{-c})/c bound for the monotone case. The ratio is expressed directly in terms of the intrinsic curvature c_g of the input function rather than being fitted to a target guarantee or reduced by construction to the algorithm's own outputs. No load-bearing self-citations, uniqueness theorems imported from prior author work, or ansatzes smuggled via citation are indicated. The pruning step is presented as part of the algorithmic construction whose performance is then bounded, without evidence that it alters curvature in a way that creates a definitional loop. The central claim therefore remains self-contained against the function properties.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The objective is a submodular set function
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J uniqueness) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We extend curvature... to all submodular functions... A greedy algorithm with pruning achieves a curvature-controlled multiplicative ratio... (1−e^{−¯c_g})/¯c_g
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Pruning loop removes elements with non-positive marginal... every nonempty subset of Ai has positive value, and f is monotone inside the active set
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
An Bian, Kfir Levy, Andreas Krause, and Joachim M Buhmann. Continuous dr-submodular maximiza- tion: Structure and algorithms.Advances in Neural Information Processing Systems, 30, 2017
work page 2017
-
[2]
Kobi Bodek and Moran Feldman. Maximizing sums of non-monotone submodular and linear functions: Understanding the unconstrained case. In30th Annual European Symposium on Algorithms (ESA), pages 23:1–23:17, 2022. doi: 10.4230/LIPIcs.ESA.2022.23
-
[3]
Random (logn)-CNF are hard for cutting planes (again)
Niv Buchbinder and Moran Feldman. Constrained submodular maximization via new bounds for dr-submodular functions. InProceedings of the 56th Annual ACM Symposium on Theory of Computing, pages 1820–1831. ACM, 2024. doi: 10.1145/3618260.3649630
-
[4]
Submodular maximization with car- dinality constraints
Niv Buchbinder, Moran Feldman, Joseph Naor, and Roy Schwartz. Submodular maximization with car- dinality constraints. InProceedings of the 25th Annual ACM-SIAM Symposium on Discrete Algorithms, pages 1433–1452. SIAM, 2014. doi: 10.1137/1.9781611973402.106
-
[5]
Gruia Calinescu, Chandra Chekuri, Martin Pál, and Jan V ondrák. Maximizing a monotone submodular function subject to a matroid constraint.SIAM Journal on Computing, 40(6):1740–1766, 2011. doi: 10.1137/080733991
-
[6]
Lin Chen, Moran Feldman, and Amin Karbasi. Weakly submodular maximization beyond cardinality constraints: Does randomization help greedy? InProceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pages 804–813. PMLR, 2018
work page 2018
-
[7]
Michele Conforti and Gérard Cornuéjols. Submodular set functions, matroids and the greedy algorithm: tight worst-case bounds and some generalizations of the rado-edmonds theorem.Discrete Applied Mathematics, 7(3):251–274, 1984
work page 1984
-
[8]
Multi-news: A large-scale multi-document summarization dataset and abstractive hierarchical model
Alexander R Fabbri, Irene Li, Tianwei She, Suyi Li, and Dragomir R Radev. Multi-news: A large-scale multi-document summarization dataset and abstractive hierarchical model. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 1074–1084. ACL, 2019
work page 2019
-
[9]
Maximizing symmetric submodular functions.ACM Transactions on Algorithms, 13 (3):39:1–39:36, 2017
Moran Feldman. Maximizing symmetric submodular functions.ACM Transactions on Algorithms, 13 (3):39:1–39:36, 2017. doi: 10.1145/3070685
-
[10]
A unified continuous greedy algorithm for submodular maximization
Moran Feldman, Joseph (Seffi) Naor, and Roy Schwartz. A unified continuous greedy algorithm for submodular maximization. InProceedings of the 52nd Annual IEEE Symposium on Foundations of Computer Science (FOCS), pages 570–579, 2011
work page 2011
-
[11]
Submodular maximization beyond non-negativity: Guarantees, fast algorithms, and applications
Chris Harshaw, Moran Feldman, Justin Ward, and Amin Karbasi. Submodular maximization beyond non-negativity: Guarantees, fast algorithms, and applications. InProceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 2634–2643. PMLR, 2019
work page 2019
-
[12]
Regularized submodular maxi- mization at scale
Ehsan Kazemi, Shervin Minaee, Moran Feldman, and Amin Karbasi. Regularized submodular maxi- mization at scale. InProceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pages 5356–5366. PMLR, 2021
work page 2021
-
[13]
Andreas Krause, Ajit Singh, and Carlos Guestrin. Near-optimal sensor placements in Gaussian processes: Theory, efficient algorithms and empirical studies.Journal of Machine Learning Research, 9:235–284, 2008. 11
work page 2008
-
[14]
A class of submodular functions for document summarization
Hui Lin and Jeff Bilmes. A class of submodular functions for document summarization. InProceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, pages 510–520. ACL, 2011
work page 2011
-
[15]
Regularized nonmonotone submodular maximization
Cheng Lu, Wenguo Yang, and Suixiang Gao. Regularized nonmonotone submodular maximization. Optimization, 73(6):1739–1765, 2024. doi: 10.1080/02331934.2023.2173968
-
[16]
Fast constrained submodular maximization: Personalized data summarization
Baharan Mirzasoleiman, Ashwinkumar Badanidiyuru, and Amin Karbasi. Fast constrained submodular maximization: Personalized data summarization. InProceedings of the 33rd International Conference on Machine Learning, volume 48 ofProceedings of Machine Learning Research, pages 1358–1367. PMLR, 2016
work page 2016
-
[17]
Loay Mualem and Moran Feldman. Using partial monotonicity in submodular maximization.Advances in Neural Information Processing Systems, 35:2723–2736, 2022
work page 2022
-
[18]
George L Nemhauser, Laurence A Wolsey, and Marshall L Fisher. An analysis of approximations for maximizing submodular set functions—I.Mathematical Programming, 14(1):265–294, 1978. doi: 10.1007/BF01588971
-
[19]
An efficient framework for balancing submodu- larity and cost
Sofia Maria Nikolakaki, Alina Ene, and Evimaria Terzi. An efficient framework for balancing submodu- larity and cost. InProceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 1256–1266, 2021. doi: 10.1145/3447548.3467367
-
[20]
Submodular maximization by simulated annealing
Shayan Oveis Gharan and Jan V ondrák. Submodular maximization by simulated annealing. In Proceedings of the Twenty-Second Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), pages 1098–1116. SIAM, 2011. doi: 10.1137/1.9781611973082.83
-
[21]
On maximizing sums of non-monotone submodular and linear functions.Algorithmica, 86:1080–1134, 2024
Benjamin Qi. On maximizing sums of non-monotone submodular and linear functions.Algorithmica, 86:1080–1134, 2024. doi: 10.1007/s00453-023-01183-3
-
[22]
Maxim Sviridenko, Jan V ondrák, and Justin Ward. Optimal approximation for submodular and super- modular optimization with bounded curvature.Mathematics of Operations Research, 42(4):1197–1218, 2017
work page 2017
-
[23]
Jan V ondrák. Symmetry and approximability of submodular maximization problems.SIAM Journal on Computing, 42(1):265–304, 2013
work page 2013
-
[24]
Zongqi Wan, Jialin Zhang, Xiaoming Sun, and Zhijie Zhang. Efficient deterministic algorithms for maximizing symmetric submodular functions.Theoretical Computer Science, 1046:115312, 2025. doi: 10.1016/j.tcs.2025.115312. A Additional Related Work Symmetric submodular functions.Feldman [9] proved that a variant of measured continuous greedy achieves (1−e −2...
-
[25]
Summarize the following passages,
Prior: Σprior =I 5; noise variance σ2 = 1. g(S) = tr(Σ prior)−tr(Σ S|) is the variance reduction. Costs: ℓ(e) =c s · ∥xe∥2/∥x∥ where cs is the cost scale and ∥x∥ is the mean row norm.α g = 1−1/κ= 0.667. Cost scales:c s ∈ {0,0.03,0.06,0.10,0.15,0.20,0.28}. Coverage with costs.Random bipartite graph: n= 20 vertices, m= 40 items, each (vertex, item) edge inc...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.