Recognition: 2 theorem links
· Lean TheoremOne World, Dual Timeline: Decoupled Spatio-Temporal Gaussian Scene Graph for 4D Cooperative Driving Reconstruction
Pith reviewed 2026-05-12 03:40 UTC · model grok-4.3
The pith
Decoupled pose trajectories per source eliminate quadratic photometric loss and ghosting in 4D cooperative scene reconstruction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
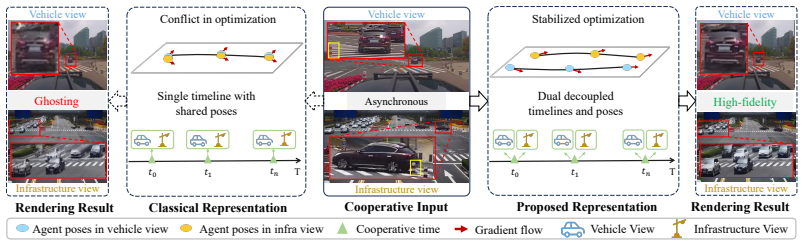
Any single-timeline formulation incurs an irreducible photometric loss scaling quadratically with agent velocity and cross-source time offset. Sharing a canonical Gaussian set per agent for appearance consistency while maintaining decoupled pose trajectories aligned to each source's true capture timestamps enables the pose-gradient kernel to become block-diagonal, eliminating cross-source interference entirely. This is supported by a static anchor-based pose correction pipeline and pose-regularized joint optimization.
What carries the argument
The DUST decoupled spatio-temporal Gaussian scene graph, which shares canonical Gaussians per agent but decouples pose trajectories to source-specific timestamps to block-diagonalize the pose-gradient kernel.
If this is right
- Dynamic-area PSNR increases by 3.2 dB compared to the strongest baseline on V2X-Seq sequences.
- Fréchet Video Distance decreases by 37.7%.
- Robust performance is maintained even with larger temporal asynchrony between vehicle and infrastructure data.
- Cross-source gradient interference is completely removed during optimization of dynamic agents.
Where Pith is reading between the lines
- High-velocity agents would benefit most from this decoupling, suggesting applications in high-speed traffic monitoring.
- Real-world datasets collected without synchronization hardware could now be used directly for high-quality 4D reconstruction.
- The block-diagonal gradient property might extend to other differentiable rendering techniques facing multi-view timing issues.
- Aligning annotations via static anchors could help in broader multi-sensor fusion problems beyond driving.
Load-bearing premise
A shared canonical Gaussian set per agent maintains consistent appearance across temporally offset observations, and the static anchor-based pose correction aligns annotations without new errors affecting dynamic reconstruction.
What would settle it
A direct measurement of photometric loss versus the product of agent velocity and time offset in single-timeline models, or a comparison showing whether ghosting remains after applying the decoupled method to highly asynchronous sequences.
Figures





read the original abstract
Reconstructing dynamic scenes from Vehicle-to-Infrastructure Cooperative Autonomous Driving (VICAD) data is fundamentally complicated by temporal asynchrony: vehicle and infrastructure cameras operate on independent clocks, capturing the same dynamic agent such as cars and pedestrians at different physical times. Existing Gaussian Scene Graph methods implicitly assume synchronized observations and assign a single pose per agent per frame, which is an assumption that breaks in cooperative settings, where the resulting gradient conflicts cause severe ghosting on dynamic agents. We identify this as a representation-level failure, not an optimization artifact: we prove that any single-timeline formulation incurs an irreducible photometric loss scaling quadratically with agent velocity and cross-source time offset. To resolve this, we propose Dust (DecoUpled Spatio-Temporal) Gaussian Scene Graph for 4D Cooperative Driving Reconstruction. DUST Gaussian Scene Graph shares a canonical Gaussian set per agent for appearance consistency, while maintaining decouple pose trajectories aligned to each source's true capture timestamps. We prove that this decoupling enables the pose-gradient kernel block-diagonal, eliminating cross-source interference entirely. To make Dust practical, we further introduce a static anchor-based pose correction pipeline that corrects spatio misalignment between vehicle and infrastructure annotations, and a pose-regularized joint optimization scheme that prevents trajectory jitter and drift during early training. On 26 sequences from V2X-Seq, DUST achieves state-of-the-art performance, improving dynamic-area PSNR by 3.2 dB over the strongest baseline and reducing Fr\'echet Video Distance by 37.7%, with keeping robustness under larger temporal asynchrony.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that single-timeline Gaussian scene graph methods for 4D scene reconstruction suffer from an irreducible quadratic photometric loss due to temporal asynchrony between vehicle and infrastructure sensors in V2X data. It proves that decoupling spatio-temporal pose trajectories per source (while sharing a canonical Gaussian set per agent) produces block-diagonal pose gradients that eliminate cross-source interference. Practical contributions include a static anchor-based pose correction pipeline and pose-regularized joint optimization. On 26 V2X-Seq sequences, DUST reports SOTA results with +3.2 dB dynamic-area PSNR and -37.7% Fréchet Video Distance over baselines, with claimed robustness to larger asynchrony.
Significance. If the proofs hold and the shared canonical Gaussian assumption is valid under real data, this addresses a fundamental representation issue in cooperative driving reconstruction where asynchrony is unavoidable. The block-diagonal gradient property offers a clean structural solution rather than an optimization fix, which could generalize to other multi-source dynamic reconstruction tasks. The empirical gains on a relevant dataset are substantial and suggest practical value for VICAD applications, though significance hinges on verifying the derivations and the absence of confounding errors from pose correction.
major comments (3)
- [Abstract and theoretical analysis] Abstract and theoretical analysis section: The claim that 'any single-timeline formulation incurs an irreducible photometric loss scaling quadratically with agent velocity and cross-source time offset' is load-bearing for the motivation, yet the derivation is presented without explicit steps or assumptions about the rendering model (e.g., how velocity enters the photometric integral); this must be expanded to confirm it is not an artifact of specific Gaussian splatting approximations.
- [Method section on decoupling] Method section on decoupling (§3.1 likely): The decoupling is introduced as producing block-diagonal gradients 'by construction,' but the paper must clarify whether the shared canonical Gaussian parameters (optimized jointly) can still induce effective cross-source coupling through appearance gradients when observations are temporally offset, undermining the 'eliminating cross-source interference entirely' claim.
- [Pose correction pipeline and experiments] Pose correction pipeline and experiments: The static anchor-based correction is asserted to align annotations without new spatial errors, but no quantitative residual error analysis or ablation is provided on how misalignment propagates to dynamic Gaussian optimization; if residuals exceed a threshold, the block-diagonal benefit cannot be isolated from the reported PSNR/FVD gains.
minor comments (3)
- [Abstract] Abstract: 'with keeping robustness' is grammatically unclear and should be rephrased to 'while maintaining robustness'.
- [Abstract] Abstract: Use standard 'Fréchet Video Distance' spelling instead of 'Fr´echet'.
- [Experiments] The paper should include an ablation isolating the contribution of the pose-regularized optimization versus the decoupling itself, as the current results bundle them.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment point by point below, providing clarifications from the manuscript and indicating planned revisions where appropriate to improve clarity and rigor.
read point-by-point responses
-
Referee: Abstract and theoretical analysis: The claim that 'any single-timeline formulation incurs an irreducible photometric loss scaling quadratically with agent velocity and cross-source time offset' is load-bearing for the motivation, yet the derivation is presented without explicit steps or assumptions about the rendering model (e.g., how velocity enters the photometric integral); this must be expanded to confirm it is not an artifact of specific Gaussian splatting approximations.
Authors: We agree that explicit expansion of the derivation is needed for full transparency. Section 3.2 derives the quadratic photometric loss by considering the integral of squared intensity differences between rendered and observed pixels under timestamp misalignment. The velocity term enters through a first-order Taylor expansion of the agent's 3D trajectory between the two sources' capture times, leading to a displacement proportional to velocity times Δt; squaring this displacement in the photometric error yields the quadratic scaling. The derivation assumes a standard differentiable rendering model with Gaussian primitives and linear motion between frames. To address the concern, we will expand the proof with all intermediate mathematical steps, list the rendering assumptions explicitly, and add a remark on its applicability beyond Gaussian splatting specifics. revision: yes
-
Referee: Method section on decoupling: The decoupling is introduced as producing block-diagonal gradients 'by construction,' but the paper must clarify whether the shared canonical Gaussian parameters (optimized jointly) can still induce effective cross-source coupling through appearance gradients when observations are temporally offset, undermining the 'eliminating cross-source interference entirely' claim.
Authors: The canonical Gaussians per agent encode intrinsic, view-independent appearance and are shared to enforce consistency. However, because each source renders using its own decoupled pose trajectory evaluated at its true capture timestamp, the pose gradients remain block-diagonal by construction (as stated in Theorem 1). Appearance gradients are aggregated across sources but flow only to the shared parameters; they do not back-propagate to couple the per-source pose variables. This separation ensures no cross-source pose interference. We will insert a clarifying paragraph in §3.1 that explicitly distinguishes the gradient flows for poses versus appearance parameters. revision: partial
-
Referee: Pose correction pipeline and experiments: The static anchor-based correction is asserted to align annotations without new spatial errors, but no quantitative residual error analysis or ablation is provided on how misalignment propagates to dynamic Gaussian optimization; if residuals exceed a threshold, the block-diagonal benefit cannot be isolated from the reported PSNR/FVD gains.
Authors: We acknowledge the absence of this quantitative analysis in the submitted version. The static anchor pipeline uses fixed scene landmarks to estimate and correct relative pose offsets between sources, but we did not report residual error statistics or controlled ablations. In the revision we will add a new experimental subsection that (i) quantifies post-correction residual pose errors against available ground-truth alignments, (ii) performs an ablation injecting synthetic misalignments of varying magnitude, and (iii) reports the resulting dynamic-area PSNR and FVD to confirm that the reported gains are driven by the decoupling rather than correction effects. revision: yes
Circularity Check
Decoupling produces block-diagonal gradients by construction; quadratic loss presented as general property
specific steps
-
self definitional
[Abstract]
"We prove that this decoupling enables the pose-gradient kernel block-diagonal, eliminating cross-source interference entirely."
DUST is defined to maintain decoupled pose trajectories aligned to each source's true capture timestamps while sharing a canonical Gaussian set. The block-diagonal kernel property is an immediate algebraic consequence of this parameter separation (no cross terms between sources), so the 'proof' reduces to restating the decoupling definition rather than deriving a non-trivial result.
full rationale
The paper introduces decoupled pose trajectories as an independent structural change to the Gaussian Scene Graph. The claimed proof that this enables a block-diagonal pose-gradient kernel follows directly from the separation of pose parameters by source timestamp, rendering the elimination of cross-source interference tautological with the model definition. The quadratic photometric loss scaling for single-timeline formulations is derived as a general consequence of the shared-pose assumption rather than fitted from the paper's data or self-citations. No load-bearing self-citations, ansatzes, or uniqueness theorems are invoked. This is a minor presentational circularity with the central reconstruction claims remaining independently testable on V2X-Seq.
Axiom & Free-Parameter Ledger
free parameters (1)
- pose regularization weight
axioms (2)
- domain assumption Any single-timeline Gaussian scene graph formulation incurs photometric loss that scales quadratically with agent velocity and cross-source time offset
- domain assumption Appearance of each dynamic agent can be captured by a single canonical Gaussian set that remains consistent across temporally offset observations
invented entities (1)
-
Decoupled spatio-temporal pose trajectories
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We prove that any single-timeline formulation incurs an irreducible photometric loss scaling quadratically with agent velocity and cross-source time offset... DUST-GSG shares a canonical Gaussian set per agent... pose-gradient kernel block-diagonal
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
shared canonical Gaussian set per agent for appearance consistency
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Hexplane: A fast representation for dynamic scenes
Ang Cao and Justin Johnson. Hexplane: A fast representation for dynamic scenes. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 130–141, 2023
work page 2023
-
[2]
Yurui Chen, Chun Gu, Junzhe Jiang, Xiatian Zhu, and Li Zhang. Periodic vibration gaussian: Dynamic urban scene reconstruction and real-time rendering.International Journal of Computer Vision, 134(3):83, 2026
work page 2026
-
[3]
Omnire: Omni urban scene reconstruction
Ziyu Chen, Jiawei Yang, Jiahui Huang, Riccardo De Lutio, Janick Martinez Esturo, Boris Ivanovic, Or Litany, Zan Gojcic, Sanja Fidler, Marco Pavone, et al. Omnire: Omni urban scene reconstruction. InInternational Conference on Learning Representations, volume 2025, pages 85508–85527, 2025
work page 2025
-
[4]
K-planes: Explicit radiance fields in space, time, and appearance
Sara Fridovich-Keil, Giacomo Meanti, Frederik Rahbæk Warburg, Benjamin Recht, and Angjoo Kanazawa. K-planes: Explicit radiance fields in space, time, and appearance. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12479–12488, 2023
work page 2023
-
[5]
Dynamic view synthesis from dynamic monocular video
Chen Gao, Ayush Saraf, Johannes Kopf, and Jia-Bin Huang. Dynamic view synthesis from dynamic monocular video. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5712–5721, 2021
work page 2021
-
[6]
Yue Hu, Shaoheng Fang, Zixing Lei, Yiqi Zhong, and Siheng Chen. Where2comm: Communication-efficient collaborative perception via spatial confidence maps.Advances in neural information processing systems, 35:4874–4886, 2022
work page 2022
-
[7]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, George Drettakis, et al. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1, 2023
work page 2023
-
[8]
H. W. Kuhn. The hungarian method for the assignment problem.Naval Research Logistics Quarterly, page 83–97, 1955
work page 1955
-
[9]
Yiming Li, Shunli Ren, Pengxiang Wu, Siheng Chen, Chen Feng, and Wenjun Zhang. Learning distilled collaboration graph for multi-agent perception.Advances in Neural Information Processing Systems, 34:29541–29552, 2021
work page 2021
-
[10]
Neural scene flow fields for space-time view synthesis of dynamic scenes
Zhengqi Li, Simon Niklaus, Noah Snavely, and Oliver Wang. Neural scene flow fields for space-time view synthesis of dynamic scenes. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6498–6508, 2021
work page 2021
-
[11]
Vi-planning: Infrastructure-assisted real-time planning optimization for autonomous driving
Yang Lu, Jie Wang, Xiaoyun Dong, Ziyao Huang, Bingyi Liu, Jen-Ming Wu, and Jianping Wang. Vi-planning: Infrastructure-assisted real-time planning optimization for autonomous driving. InProceedings of the 31st Annual International Conference on Mobile Computing and Networking, pages 923–937, 2025
work page 2025
-
[12]
Yifan Lu, Quanhao Li, Baoan Liu, Mehrdad Dianati, Chen Feng, Siheng Chen, and Yanfeng Wang. Robust collaborative 3d object detection in presence of pose errors.arXiv preprint arXiv:2211.07214, 2022
-
[13]
D-nerf: Neural radiance fields for dynamic scenes
Albert Pumarola, Enric Corona, Gerard Pons-Moll, and Francesc Moreno-Noguer. D-nerf: Neural radiance fields for dynamic scenes. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10318–10327, 2021
work page 2021
-
[14]
Dewi Retno Sari Saputro and Purnami Widyaningsih. Limited memory broyden-fletcher- goldfarb-shanno (l-bfgs) method for the parameter estimation on geographically weighted ordinal logistic regression model (gwolr). InAIP conference proceedings, volume 1868, page 040009. AIP Publishing LLC, 2017
work page 2017
-
[15]
Vips: Real-time perception fusion for infrastructure-assisted autonomous driving
Shuyao Shi, Jiahe Cui, Zhehao Jiang, Zhenyu Yan, Guoliang Xing, Jianwei Niu, and Zhenchao Ouyang. Vips: Real-time perception fusion for infrastructure-assisted autonomous driving. In Proceedings of the 28th annual international conference on mobile computing and networking, pages 133–146, 2022. 10
work page 2022
-
[16]
Animating rotation with quaternion curves
Ken Shoemake. Animating rotation with quaternion curves. InProceedings of the 12th annual conference on Computer graphics and interactive techniques, pages 245–254, 1985
work page 1985
-
[17]
Raft: Recurrent all-pairs field transforms for optical flow
Zachary Teed and Jia Deng. Raft: Recurrent all-pairs field transforms for optical flow. In European conference on computer vision, pages 402–419. Springer, 2020
work page 2020
-
[18]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Thomas Unterthiner, Sjoerd Van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Sylvain Gelly. Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:1812.01717, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[19]
Zhou Wang, A.C. Bovik, H.R. Sheikh, and E.P. Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Processing, 13(4):600–612, 2004
work page 2004
-
[20]
4d gaussian splatting for real-time dynamic scene rendering
Guanjun Wu, Taoran Yi, Jiemin Fang, Lingxi Xie, Xiaopeng Zhang, Wei Wei, Wenyu Liu, Qi Tian, and Xinggang Wang. 4d gaussian splatting for real-time dynamic scene rendering. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20310–20320, 2024
work page 2024
-
[21]
V2x-real: a largs-scale dataset for vehicle-to-everything cooperative perception
Hao Xiang, Zhaoliang Zheng, Xin Xia, Runsheng Xu, Letian Gao, Zewei Zhou, Xu Han, Xinkai Ji, Mingxi Li, Zonglin Meng, et al. V2x-real: a largs-scale dataset for vehicle-to-everything cooperative perception. InEuropean Conference on Computer Vision, pages 455–470. Springer, 2024
work page 2024
-
[22]
Cruise: Cooperative reconstruction and editing in v2x scenarios using gaussian splatting
Haoran Xu, Saining Zhang, Peishuo Li, Baijun Ye, Xiaoxue Chen, Huan-ang Gao, Jv Zheng, Xiaowei Song, Ziqiao Peng, Run Miao, et al. Cruise: Cooperative reconstruction and editing in v2x scenarios using gaussian splatting. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 12518–12525. IEEE, 2025
work page 2025
-
[23]
V2x-vit: Vehicle-to-everything cooperative perception with vision transformer
Runsheng Xu, Hao Xiang, Zhengzhong Tu, Xin Xia, Ming-Hsuan Yang, and Jiaqi Ma. V2x-vit: Vehicle-to-everything cooperative perception with vision transformer. InEuropean conference on computer vision, pages 107–124. Springer, 2022
work page 2022
-
[24]
Runsheng Xu, Hao Xiang, Xin Xia, Xu Han, Jinlong Li, and Jiaqi Ma. Opv2v: An open benchmark dataset and fusion pipeline for perception with vehicle-to-vehicle communication. In2022 International Conference on Robotics and Automation (ICRA), pages 2583–2589, 2022
work page 2022
-
[25]
Instinct: Instance- level interaction architecture for query-based collaborative perception
Yunjiang Xu, Lingzhi Li, Jin Wang, Yupeng Ouyang, and Benyuan Yang. Instinct: Instance- level interaction architecture for query-based collaborative perception. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 25464–25473, 2025
work page 2025
-
[26]
Street gaussians: Modeling dynamic urban scenes with gaussian splatting
Yunzhi Yan, Haotong Lin, Chenxu Zhou, Weijie Wang, Haiyang Sun, Kun Zhan, Xianpeng Lang, Xiaowei Zhou, and Sida Peng. Street gaussians: Modeling dynamic urban scenes with gaussian splatting. InEuropean Conference on Computer Vision, pages 156–173. Springer, 2024
work page 2024
-
[27]
arXiv preprint arXiv:2311.02077 , year=
Jiawei Yang, Boris Ivanovic, Or Litany, Xinshuo Weng, Seung Wook Kim, Boyi Li, Tong Che, Danfei Xu, Sanja Fidler, Marco Pavone, et al. Emernerf: Emergent spatial-temporal scene decomposition via self-supervision.arXiv preprint arXiv:2311.02077, 2023
-
[28]
Bevheight: A robust framework for vision-based roadside 3d object detection
Lei Yang, Kaicheng Yu, Tao Tang, Jun Li, Kun Yuan, Li Wang, Xinyu Zhang, and Peng Chen. Bevheight: A robust framework for vision-based roadside 3d object detection. InIEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), March 2023
work page 2023
-
[29]
Deformable 3d gaussians for high-fidelity monocular dynamic scene reconstruction
Ziyi Yang, Xinyu Gao, Wen Zhou, Shaohui Jiao, Yuqing Zhang, and Xiaogang Jin. Deformable 3d gaussians for high-fidelity monocular dynamic scene reconstruction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20331–20341, 2024
work page 2024
-
[30]
Dair-v2x: A large-scale dataset for vehicle- infrastructure cooperative 3d object detection
Haibao Yu, Yizhen Luo, Mao Shu, Yiyi Huo, Zebang Yang, Yifeng Shi, Zhenglong Guo, Hanyu Li, Xing Hu, Jirui Yuan, and Zaiqing Nie. Dair-v2x: A large-scale dataset for vehicle- infrastructure cooperative 3d object detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21361–21370, 2022. 11
work page 2022
-
[31]
Haibao Yu, Wenxian Yang, Hongzhi Ruan, Zhenwei Yang, Yingjuan Tang, Xu Gao, Xin Hao, Yifeng Shi, Yifeng Pan, Ning Sun, Juan Song, Jirui Yuan, Ping Luo, and Zaiqing Nie. V2x-seq: A large-scale sequential dataset for vehicle-infrastructure cooperative perception and forecasting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni...
work page 2023
-
[32]
End-to-end autonomous driving through v2x cooperation
Haibao Yu, Wenxian Yang, Jiaru Zhong, Zhenwei Yang, Siqi Fan, Ping Luo, and Zaiqing Nie. End-to-end autonomous driving through v2x cooperation. InThe 39th Annual AAAI Conference on Artificial Intelligence, 2025
work page 2025
-
[33]
The unreason- able effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreason- able effectiveness of deep features as a perceptual metric. InCVPR, 2018
work page 2018
-
[34]
Drivinggaussian: Composite gaussian splatting for surrounding dynamic autonomous driving scenes
Xiaoyu Zhou, Zhiwei Lin, Xiaojun Shan, Yongtao Wang, Deqing Sun, and Ming-Hsuan Yang. Drivinggaussian: Composite gaussian splatting for surrounding dynamic autonomous driving scenes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21634–21643, 2024
work page 2024
-
[35]
Yi Zhou, Connelly Barnes, Jingwan Lu, Jimei Yang, and Hao Li. On the continuity of rotation representations in neural networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5745–5753, 2019. 12 Appendices A Notation 13 B Proof 15 B.1 Formal Rendering Model and Assumptions . . . . . . . . . . . . . . . . . . . ....
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.