Recognition: no theorem link
MedVIGIL: Evaluating Trustworthy Medical VLMs Under Broken Visual Evidence
Pith reviewed 2026-05-11 03:40 UTC · model grok-4.3
The pith
Medical vision-language models fail to refuse answers when visual evidence is broken, trailing radiologists by 14 points on a new composite score.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MedVIGIL is a 300-case evaluation suite drawn from public medical VQA sources and fully supervised by board-certified radiologists. It contains 2,556 MCQ probes plus open-ended variants, with clinician-authored false-premise traps, ROI boxes, risk tiers, and refusal options. Audits of 16 vision-capable models using the MCS show a maximum score of 69.2, compared to an independent radiologist baseline of 83.3 at 5.8% silent failures.
What carries the argument
The MedVIGIL Composite Score (MCS), which aggregates seven correctness-conditioned audit metrics to quantify silent failures under four types of broken evidence.
If this is right
- Models can be systematically audited on the released suite to measure progress in evidence verification.
- Clinical deployment should incorporate silent-failure thresholds derived from the MCS to limit unsupported answers.
- The paired open-ended variant allows testing refusal behavior beyond multiple-choice formats.
- Risk-tier annotations enable focused evaluation on high-stakes medical cases.
Where Pith is reading between the lines
- Models passing this benchmark may still require additional testing against naturally occurring image corruptions not captured by the four synthetic perturbations.
- Incorporating MCS-style penalties during training could incentivize VLMs to learn when to withhold answers.
- Extending the suite to non-radiology imaging domains would check whether the observed gap is modality-specific.
Load-bearing premise
The four chosen perturbation types and the 300 clinician-authored cases sufficiently represent the range of broken visual evidence that occurs in real clinical practice.
What would settle it
Releasing a new model that achieves an MCS of 83 or higher on the full MedVIGIL suite with silent-failure rates near 6% would test whether the performance gap can be closed.
Figures






read the original abstract
Medical vision--language models (VLMs) are usually evaluated on intact image--question pairs, but trustworthy clinical use requires a stronger property: a model must recognise when the evidential basis for an answer has failed. We study this through silent failures under perturbed evidence, where a vision-required medical question is paired with a false premise, wording perturbation, knowledge-only rewrite, or ROI-corrupted image, yet the model returns a fluent non-refusal answer. We introduce medvigil, a 300-case evaluation suite drawn from four public medical VQA sources, supervised end to end by four board-certified radiologists: every gold answer, refusal option, candidate-answer set, paraphrase, false-premise trap, ROI box, and clinical risk tier is clinician-authored. Two attending radiologists annotate every case in parallel, a senior radiologist consolidates the released manifest, and a separate fourth radiologist independent of construction answers every probe to provide the human reference baseline. The release contains 2{,}556 MCQ probes, 240 counterfactual triplets, physician-adjudicated risk-tier and answerability flags, ROI boxes, and a paired open-ended variant. We report seven correctness-conditioned audit metrics that summarise into the medvigil Composite Score (MCS), and audit 16 vision-capable models plus two text-only baselines. The independent radiologist scores MCS 83.3 at silent-failure rate 5.8%, leaving a 14.1-point composite headroom above the strongest audited model (Claude Opus 4.7 at 69.2). The benchmark and evaluation harness are publicly released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MedVIGIL, a 300-case evaluation suite for medical VLMs under broken visual evidence, constructed from four public VQA sources and fully supervised by four board-certified radiologists (parallel attending annotations, senior consolidation, independent fourth-radiologist baseline). Cases incorporate four perturbation types (false-premise wording, knowledge-only rewrite, ROI corruption, and related) to induce silent failures where models give fluent non-refusal answers. The suite includes 2,556 MCQ probes, 240 counterfactual triplets, risk tiers, ROI boxes, and an open-ended variant. Seven correctness-conditioned metrics are aggregated into the MedVIGIL Composite Score (MCS); the independent radiologist baseline achieves MCS 83.3 at 5.8% silent-failure rate, 14.1 points above the strongest model (Claude Opus at 69.2). The benchmark and harness are publicly released.
Significance. If the 300 cases and four perturbation classes adequately proxy real clinical visual-evidence failures, the work is significant for exposing a measurable trustworthiness gap in current medical VLMs and supplying a clinician-authored, publicly released resource for auditing and improving model refusal behavior. The multi-radiologist oversight, independent human baseline, and release of probes plus risk tiers strengthen its utility as a standardized testbed.
major comments (2)
- [Abstract] Abstract: The assumption that the four perturbation types (false-premise wording, knowledge-only rewrite, ROI corruption, and the remaining two) plus the 300 clinician-authored cases from four VQA sources sufficiently represent the distribution of broken visual evidence in real radiology workflows is load-bearing for interpreting the 14.1-point MCS headroom and 5.8% human silent-failure rate as clinically actionable. No external validation (e.g., mapping to observed PACS artifacts, modality-specific failure statistics, or inter-institutional audits) is provided to confirm coverage or severity calibration.
- [Abstract] Abstract: The aggregation rule that combines the seven correctness-conditioned audit metrics into the single MedVIGIL Composite Score (MCS) is not specified, preventing assessment of whether the reported 83.3 vs. 69.2 gap is robust to alternative weightings or dominated by particular sub-metrics such as silent-failure rate.
minor comments (1)
- [Abstract] Abstract: The notation '2{,}556' is a typographical artifact and should be rendered as '2,556' for readability.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments on our manuscript. We provide point-by-point responses to the major comments below and have updated the manuscript to address the concerns raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assumption that the four perturbation types (false-premise wording, knowledge-only rewrite, ROI corruption, and the remaining two) plus the 300 clinician-authored cases from four VQA sources sufficiently represent the distribution of broken visual evidence in real radiology workflows is load-bearing for interpreting the 14.1-point MCS headroom and 5.8% human silent-failure rate as clinically actionable. No external validation (e.g., mapping to observed PACS artifacts, modality-specific failure statistics, or inter-institutional audits) is provided to confirm coverage or severity calibration.
Authors: We agree that external validation against real-world clinical data would be valuable for establishing the benchmark's representativeness. Our work focuses on creating a clinician-supervised benchmark using perturbations derived from existing public VQA datasets to systematically evaluate silent failures in medical VLMs. The four perturbation types were selected based on common issues in medical VQA and radiologist input to simulate plausible broken evidence scenarios. We have revised the manuscript by adding a new 'Limitations and Future Work' paragraph in the Discussion section. This paragraph acknowledges that the 300 cases serve as a proxy rather than a comprehensive sample of all possible clinical failures, explains the design choices, and explicitly recommends future studies involving PACS artifact analysis and inter-institutional validation to calibrate severity. revision: yes
-
Referee: [Abstract] Abstract: The aggregation rule that combines the seven correctness-conditioned audit metrics into the single MedVIGIL Composite Score (MCS) is not specified, preventing assessment of whether the reported 83.3 vs. 69.2 gap is robust to alternative weightings or dominated by particular sub-metrics such as silent-failure rate.
Authors: We appreciate this observation. The aggregation rule for the MCS was not sufficiently detailed. We have revised the abstract to state that the MCS is the unweighted average of the seven normalized metrics (each scaled to [0,100]). We have also added the explicit formula in the Methods section along with a sensitivity analysis to alternative weightings, confirming the robustness of the reported gap. revision: yes
Circularity Check
No circularity: new benchmark with independent annotations yields empirical results
full rationale
The paper constructs MedVIGIL as a fresh 300-case suite from public VQA sources, with all gold answers, refusal options, risk tiers, and perturbations clinician-authored under multi-radiologist supervision. MCS aggregates seven audit metrics computed directly on model outputs for the released probes; the human baseline (MCS 83.3) comes from a fourth independent radiologist answering the same probes. No equations, fitted parameters, or self-citations reduce any reported quantity to a prior result by construction. The derivation chain (case construction → model auditing → metric aggregation → headroom calculation) is self-contained and externally falsifiable via the public release.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Board-certified radiologist annotations provide reliable ground truth for answerability and clinical risk in medical VQA cases.
Reference graph
Works this paper leans on
-
[2]
Mirage the illusion of visual understanding.arXiv preprint arXiv:2603.21687, 2026
URLhttps://arxiv.org/abs/2603.21687. Aofei Chang, Le Huang, Parminder Bhatia, Taha Kass-Hout, Fenglong Ma, and Cao Xiao. MedHEval: Benchmarking hallucinations and mitigation strategies in medical large vision-language models. arXiv preprint arXiv:2503.02157,
-
[3]
Detecting and Evaluating Medical Hallucinations in Large Vision Language Models
URLhttps://arxiv.org/abs/2503.02157. Jiawei Chen, Dingkang Yang, Tong Wu, Yue Jiang, Xiaolu Hou, Mingcheng Li, et al. Detect- ing and evaluating medical hallucinations in large vision language models.arXiv preprint arXiv:2406.10185v1, 2024a. doi: 10.48550/arXiv.2406.10185. URL https://arxiv.org/ abs/2406.10185v1. Junying Chen, Chi Gui, Ruyi Ouyang, Anning...
work page internal anchor Pith review doi:10.48550/arxiv.2406.10185 2024
-
[4]
Datasheets for datasets.Communications of the ACM, 64(12):86–92, 2021
doi: 10.1145/3458723. URL https://cacm.acm.org/research/ datasheets-for-datasets/. Yonatan Geifman and Ran El-Yaniv. Selective classification for deep neural networks. InAdvances in Neural Information Processing Systems,
-
[5]
Gemini: A Family of Highly Capable Multimodal Models
URL https://papers.neurips.cc/paper/ 7073-selective-classification-for-deep-neural-networks. Gemini Team Google. Gemini: A family of highly capable multimodal models.arXiv preprint arXiv:2312.11805,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Gemini: A Family of Highly Capable Multimodal Models
doi: 10.48550/arXiv.2312.11805. URL https://arxiv.org/abs/ 2312.11805. Tejas Gokhale, Pratyay Banerjee, Chitta Baral, and Yezhou Yang. VQA-LOL: Visual question answering under the lens of logic. InEuropean Conference on Computer Vision,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.11805
-
[7]
10 Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh
URL https://arxiv.org/abs/2002.08325. 10 Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the V in VQA matter: Elevating the role of image understanding in visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 6904–6913,
-
[8]
In: CVPR (2017),https://doi.org/10.1109/CVPR.2017.670
doi: 10.1109/CVPR.2017.670. URL https://openaccess.thecvf.com/ content_cvpr_2017/html/Goyal_Making_the_v_CVPR_2017_paper.html. Zishan Gu, Changchang Yin, Fenglin Liu, and Ping Zhang. MedVH: Towards systematic evalu- ation of hallucination for large vision language models in the medical context.arXiv preprint arXiv:2407.02730,
-
[9]
URLhttps://arxiv.org/abs/2407.02730. Hao Guan and Mingxia Liu. Domain adaptation for medical image analysis: A survey.IEEE Transactions on Biomedical Engineering, 69(3):1173–1185,
-
[10]
doi: 10.1109/TBME.2021. 3117407. URLhttps://pmc.ncbi.nlm.nih.gov/articles/PMC9011180/. Dan Hendrycks and Thomas Dietterich. Benchmarking neural network robustness to common corruptions and perturbations. InInternational Conference on Learning Representations,
-
[11]
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
doi: 10.48550/arXiv.1903.12261. URLhttps://arxiv.org/abs/1903.12261. Jeremy Irvin, Pranav Rajpurkar, Michael Ko, Yifan Yu, Silviana Ciurea-Ilcus, Chris Chute, Henrik Marklund, Behzad Haghgoo, Robyn Ball, Katie Shpanskaya, et al. CheXpert: A large chest radiograph dataset with uncertainty labels and expert comparison. InAAAI Conference on Artificial Intelligence,
work page internal anchor Pith review doi:10.48550/arxiv.1903.12261 1903
-
[12]
doi: 10.1609/aaai.v33i01.3301590. Alistair E. W. Johnson, Tom J. Pollard, Seth J. Berkowitz, Nathaniel R. Greenbaum, Matthew P. Lungren, Chih-ying Deng, et al. MIMIC-CXR, a de-identified publicly available database of chest radiographs with free-text reports.Scientific Data, 6:317,
-
[13]
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William W Cohen, and Xinghua Lu
doi: 10.1038/s41597-019-0322-0. URLhttps://www.nature.com/articles/s41597-019-0322-0. Polina Kirichenko, Mark Ibrahim, Kamalika Chaudhuri, and Samuel J. Bell. AbstentionBench: Reasoning LLMs fail on unanswerable questions.arXiv preprint arXiv:2506.09038,
- [14]
-
[15]
Lau, Soumya Gayen, Asma Ben Abacha, and Dina Demner-Fushman
doi: 10.1038/sdata.2018.251. URLhttps://www.nature.com/articles/sdata2018251. Kang-il Lee, Minbeom Kim, Seunghyun Yoon, Minsung Kim, Dongryeol Lee, Hyukhun Koh, et al. VLind-Bench: Measuring language priors in large vision-language models. InFindings of the Association for Computational Linguistics: NAACL 2025,
-
[16]
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, et al
URL https://arxiv.org/ abs/2406.08702. Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, et al. LLaV A- Med: Training a large language-and-vision assistant for biomedicine in one day. InAdvances in Neural Information Processing Systems, Datasets and Benchmarks Track, 2023a. URL https: //arxiv.org/abs/2306.00890. Jidong Li, Li...
-
[17]
URL https://arxiv.org/abs/2510.10965. Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. InProceedings of the 2023 Conference on Empir- ical Methods in Natural Language Processing, pages 292–305, 2023b. doi: 10.18653/v1/2023. emnlp-main.20. URLhttps://aclanthology.org/202...
-
[18]
URL https://arxiv.org/abs/2102.09542
doi: 10.1109/ISBI48211.2021.9434010. URL https://arxiv.org/abs/2102.09542. Nishanth Madhusudhan, Vikas Yadav, and Alexandre Lacoste. Knowing when not to answer: Evaluating abstention in multimodal reasoning systems.arXiv preprint arXiv:2604.14799,
-
[19]
Knowing When Not to Answer: Evaluating Abstention in Multimodal Reasoning Systems
URLhttps://arxiv.org/abs/2604.14799. 11 MLCommons. Croissant: A metadata format for ML-ready datasets,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Benchmarking Deflection and Hallucination in Large Vision-Language Models
URLhttps://arxiv.org/abs/2604.12033. Dung Nguyen, Minh Khoi Ho, Huy Ta, Thanh Tam Nguyen, Qi Chen, Kumar Rav, et al. Localizing before answering: A benchmark for grounded medical visual question answering. InProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence (IJCAI),
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
URLhttps://arxiv.org/abs/2505.00744
doi: 10.24963/ijcai.2025/853. URLhttps://arxiv.org/abs/2505.00744. OpenAI. GPT-4o system card,
-
[23]
Mahima Pushkarna, Andrew Zaldivar, and Oddur Kjartansson
doi: 10.1007/978-3-030-01364-6_20. Mahima Pushkarna, Andrew Zaldivar, and Oddur Kjartansson. Data cards: Purposeful and transparent dataset documentation for responsible AI.arXiv preprint arXiv:2204.01075,
-
[24]
URLhttps://arxiv.org/abs/2204.01075
doi: 10.48550/ arXiv.2204.01075. URLhttps://arxiv.org/abs/2204.01075. Jie Ren, Yao Zhao, Tu Vu, Peter J. Liu, and Balaji Lakshminarayanan. Self-evaluation improves selective generation in large language models.arXiv preprint arXiv:2312.09300,
-
[25]
Liu, and Balaji Lakshminarayanan
doi: 10.48550/arXiv.2312.09300. URLhttps://arxiv.org/abs/2312.09300. Anna Rohrbach, Lisa Anne Hendricks, Kaylee Burns, Trevor Darrell, and Kate Saenko. Object hallucination in image captioning. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4035–4045,
-
[26]
Object Hallucination in Image Captioning
doi: 10.18653/v1/D18-1437. URL https://aclanthology.org/D18-1437/. Meet Shah, Xinlei Chen, Marcus Rohrbach, and Devi Parikh. Cycle-consistency for ro- bust visual question answering. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 6649–6658,
-
[28]
Bingbing Wen, Jihan Yao, Shangbin Feng, Chenjun Xu, Yulia Tsvetkov, Bill Howe, et al
URLhttps://arxiv.org/abs/2507.23486. Bingbing Wen, Jihan Yao, Shangbin Feng, Chenjun Xu, Yulia Tsvetkov, Bill Howe, et al. Know your limits: A survey of abstention in large language models.Transactions of the Association for Computational Linguistics, 12:1412–1430,
-
[29]
Chaoyi Wu, Xiaoman Zhang, Ya Zhang, Yanfeng Wang, and Weidi Xie
URL https://arxiv.org/abs/2407.18418. Chaoyi Wu, Xiaoman Zhang, Ya Zhang, Yanfeng Wang, and Weidi Xie. Towards generalist foun- dation model for radiology by leveraging web-scale 2d and 3d medical data.arXiv preprint arXiv:2308.02463,
-
[30]
doi: 10.48550/arXiv.2308.02463. URL https://arxiv.org/abs/ 2308.02463. 12 Xiaoman Zhang, Chaoyi Wu, Ziheng Zhao, Weixiong Lin, Ya Zhang, Yanfeng Wang, et al. PMC-VQA: Visual instruction tuning for medical visual question answering.arXiv preprint arXiv:2305.10415,
-
[31]
arXiv preprint arXiv:2305.10415 (2023)
doi: 10.48550/arXiv.2305.10415. URL https://arxiv.org/abs/ 2305.10415. 13 A Benchmark Positioning Table 2 summarizes how MedVIGIL differs from adjacent benchmark families. The key distinction is not only the medical domain, but the combination of paired evidence perturbations, doctor-adjudicated safe targets, and risk-weighted silent-failure scoring. Tabl...
-
[32]
Therisk layerstores the clinical risk tier (CRT) together with the binary text-only-answerability flag. The CRT is one of L1 (meta or modality questions, no clinical harm if wrong), L2 (anatomical localisation with no management impact), L3 (presence of finding, delayed care if missed), L4 (significant pathology or characterisation, wrong treatment if mis...
work page 2021
-
[33]
Is there evidence of a right apical pneumothorax?
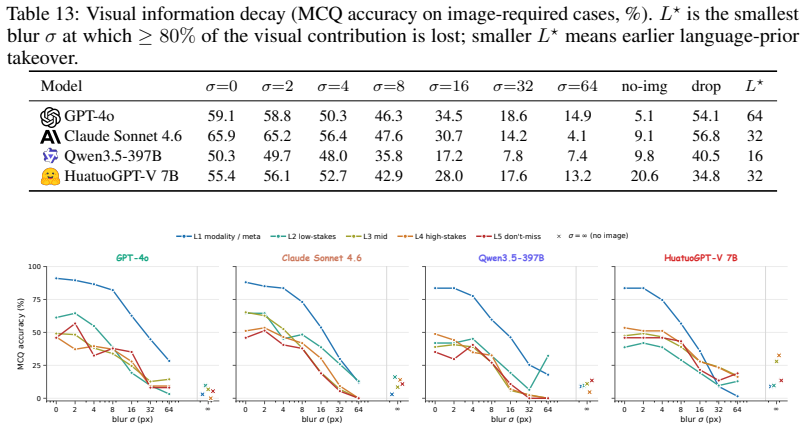
Per-case letter trajectories.To make the aggregate behaviour concrete, Table 14 reports the modal- letter trajectory across the four mask steps for five hand-picked qualitative cases (one per CRT tier, ablation re-queried for each model). Each row is one model on one case; cells colouredgreenare the doctor-finalised refusal option E, cells colouredredare ...
work page 2069
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.