Recognition: 2 theorem links
· Lean TheoremAgentEscapeBench: Evaluating Out-of-Domain Tool-Grounded Reasoning in LLM Agents
Pith reviewed 2026-05-11 03:28 UTC · model grok-4.3
The pith
LLM agents handle short tool sequences but lose substantial accuracy when required to track deep chains of dependencies across novel procedures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AgentEscapeBench shows that current LLM agents can execute local tool calls in familiar patterns yet systematically fail to maintain coherent reasoning across long-range dependencies, with the best model dropping from 90.0 percent to 60.0 percent success as dependency depth rises from 5 to 25 while humans decline only from 98.3 percent to 80.0 percent. Failures concentrate in long-range state tracking, adherence to incrementally revealed clues, and propagation of intermediate results.
What carries the argument
The directed acyclic dependency graph over tools and items, which enforces incremental state revelation and requires agents to discover, execute, and revise novel sequences under explicit long-range constraints.
If this is right
- Agents require new mechanisms for long-range state tracking to succeed on complex tool procedures that exceed training patterns.
- Training should prioritize adaptation to novel workflows instead of short-range, familiar interactions.
- The benchmark supplies an automated testbed that can track whether future agents close the gap between local tool use and sustained multi-step reasoning.
Where Pith is reading between the lines
- If the observed depth-dependent failures generalize, simply scaling model size or context length may not resolve them without explicit architectural support for dependency graphs.
- The same tracking and propagation issues likely appear in other multi-step domains such as software engineering agents or robotic planning, suggesting a shared limitation across tool-using systems.
- One testable extension is to measure whether adding explicit graph-construction or memory-augmentation modules reduces the performance cliff on deeper instances of the benchmark.
Load-bearing premise
Escape-room tasks built on explicit DAG constraints and step-by-step state revelation accurately reflect the real difficulties of out-of-domain tool-grounded reasoning rather than introducing artificial benchmark artifacts.
What would settle it
A controlled follow-up experiment in which models are fine-tuned on families of long-dependency DAG tasks and then retested on AgentEscapeBench; if the steep performance drop with depth disappears, the claim that current architectures cannot sustain deep contextual dependencies would be weakened.
Figures



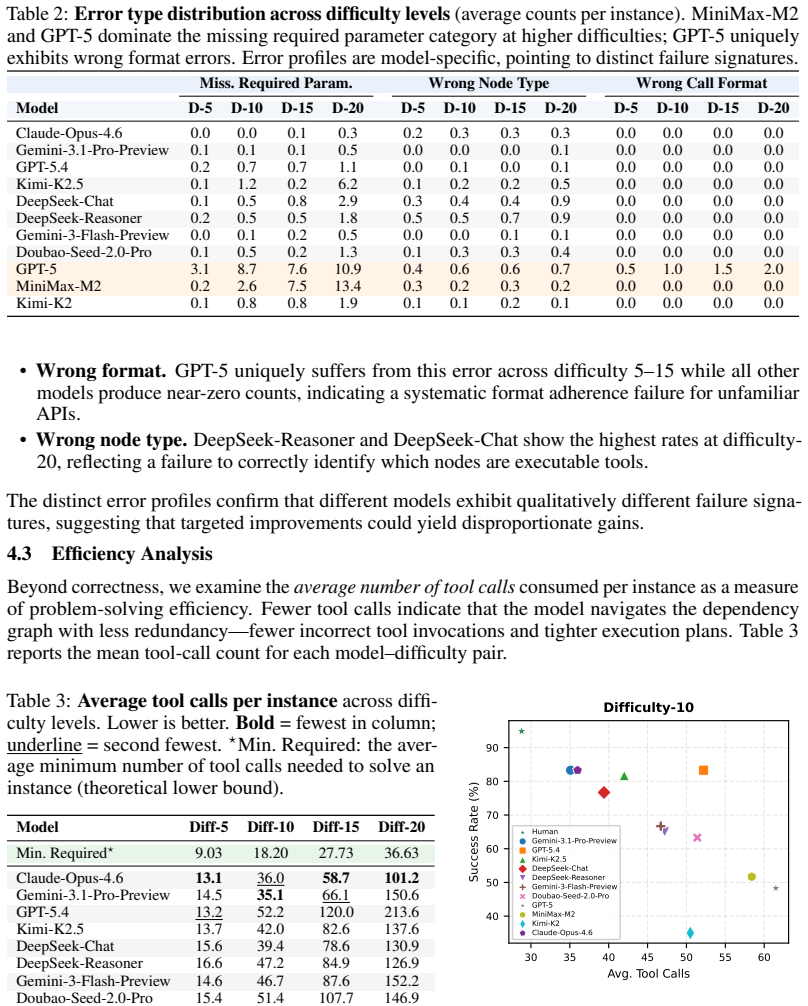



read the original abstract
As LLM-based agents increasingly rely on external tools, it is important to evaluate their ability to sustain tool-grounded reasoning beyond familiar workflows and short-range interactions. We introduce AgentEscapeBench, an escape-room-style benchmark that tests whether agents can infer, execute, and revise novel tool-use procedures under explicit long-range dependency constraints. Each task defines a directed acyclic dependency graph over tools and items, requiring agents to invoke real external functions, track hidden state revealed incrementally, propagate intermediate results, and submit a deterministically verifiable final answer. AgentEscapeBench includes 270 instances across five difficulty tiers and supports fully automated evaluation. Experiments with sixteen LLM agents and human participants show that performance drops sharply as dependency depth increases: humans decline from 98.3% success at difficulty-5 to 80.0% at difficulty-25, while the best model drops from 90.0% to 60.0%. Trajectory analysis attributes model failures mainly to breakdowns in long-range state tracking, clue adherence, and intermediate-result propagation. These findings suggest that current agents can often handle local tool use but still struggle with deep contextual dependencies. We hope AgentEscapeBench can serve as a diagnostic testbed for measuring current agent capabilities and informing future training efforts toward more robust general-purpose reasoning, action, and adaptation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AgentEscapeBench, a benchmark of 270 escape-room tasks defined by explicit DAGs over tools and items. Tasks require agents to invoke external functions, track incrementally revealed hidden state, propagate intermediate results, and produce a verifiable final answer. Experiments with 16 LLM agents and human participants report sharp performance drops as dependency depth increases across five difficulty tiers (humans: 98.3% at tier 5 to 80.0% at tier 25; best model: 90.0% to 60.0%), with trajectory analysis attributing model failures primarily to long-range state tracking, clue adherence, and intermediate-result propagation.
Significance. If the benchmark isolates dependency depth from confounds and the tasks validly capture out-of-domain tool-grounded reasoning, the results would provide a useful diagnostic for current limitations in LLM agents' handling of long-range dependencies. The automated evaluation, human baselines, and failure-mode analysis are positive features that could inform future agent training.
major comments (2)
- [Abstract] Abstract: The central claim attributes the observed performance decline specifically to breakdowns in long-range state tracking and intermediate-result propagation as dependency depth grows. However, the manuscript provides no evidence that difficulty tiers hold constant the number of tools invoked, cumulative context length, or number of intermediate results; without such controls, the drop could instead reflect context-window pressure or compounding local errors.
- [Abstract] Abstract and methods description: No information is given on task validation procedures, inter-annotator agreement for the DAG constructions, or how failure categories were assigned in the trajectory analysis. These details are load-bearing for the claim that the benchmark measures the intended reasoning deficits rather than benchmark-specific artifacts.
minor comments (1)
- [Abstract] The abstract states experiments used sixteen LLM agents but does not name the models or provide implementation details; adding this list would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We address each major point below and will incorporate the requested controls and methodological details into the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim attributes the observed performance decline specifically to breakdowns in long-range state tracking and intermediate-result propagation as dependency depth grows. However, the manuscript provides no evidence that difficulty tiers hold constant the number of tools invoked, cumulative context length, or number of intermediate results; without such controls, the drop could instead reflect context-window pressure or compounding local errors.
Authors: We agree that isolating dependency depth requires explicit controls for these potential confounds. The tiers were constructed by varying maximum DAG path length while reusing similar tool and item templates, but the original manuscript does not report per-tier statistics on tool count, context length, or intermediate-result volume. In the revision we will add a table with these averages across the five tiers and include a matched-subset analysis (selecting tasks with comparable tool counts and context lengths) that still shows a significant performance drop with depth. We will also update the abstract and add a short methods subsection describing the construction process to make the controls transparent. revision: yes
-
Referee: [Abstract] Abstract and methods description: No information is given on task validation procedures, inter-annotator agreement for the DAG constructions, or how failure categories were assigned in the trajectory analysis. These details are load-bearing for the claim that the benchmark measures the intended reasoning deficits rather than benchmark-specific artifacts.
Authors: We acknowledge these details were omitted. In the revised methods we will describe the validation procedure: every one of the 270 tasks was executed with the ground-truth tool sequence to confirm solvability and deterministic verifiability of the final answer. DAG construction was template-driven with author review; we will report that two authors independently checked a random sample of 50 tasks for structural correctness and solvability, obtaining 100% agreement. For the trajectory analysis, failure categories were assigned by three authors who independently labeled 50 randomly sampled failure trajectories (long-range state tracking, clue adherence, intermediate-result propagation, other), yielding Fleiss’ kappa of 0.82; disagreements were resolved by discussion. These additions will be placed in the methods section and referenced from the abstract. revision: yes
Circularity Check
No circularity: empirical benchmark with external human baselines
full rationale
The paper introduces AgentEscapeBench as a new evaluation suite and reports measured success rates on 270 tasks across difficulty tiers for 16 LLM agents plus human participants. Performance drops (e.g., humans 98.3% to 80.0%, best model 90.0% to 60.0%) are direct experimental outcomes against independent human controls, not derived from any fitted parameter, self-referential definition, or prior self-citation chain. No equations, uniqueness theorems, or ansatzes are invoked; trajectory analysis attributes failures to observable behaviors without reducing to the input data by construction. This is a standard empirical benchmark paper whose central claims rest on external measurement rather than internal reduction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclearEach task defines a directed acyclic dependency graph over tools and items... performance drops sharply as dependency depth increases
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearDAG skeleton generation... reverse-generation algorithm
Reference graph
Works this paper leans on
-
[1]
Claude Code: Agentic coding in the real world
Anthropic. Claude Code: Agentic coding in the real world. https://www.anthropic.com/, 2025. Accessed: 2025
work page 2025
-
[2]
$\tau^2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment
Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan. τ 2-bench: Evaluating conversational agents in a dual-control environment.arXiv preprint arXiv:2506.07982, 2025
work page internal anchor Pith review arXiv 2025
-
[3]
Fixme: Find correct gaia-2 agent benchmark paper.FIXME, 2025
FIXME. Fixme: Find correct gaia-2 agent benchmark paper.FIXME, 2025
work page 2025
-
[4]
Wei He, Yueqing Sun, Hongyan Hao, Xueyuan Hao, Zhikang Xia, Qi Gu, Chengcheng Han, Dengchang Zhao, Hui Su, Kefeng Zhang, et al. Vitabench: Benchmarking llm agents with versatile interactive tasks in real-world applications.arXiv preprint arXiv:2509.26490, 2025
-
[5]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
PuzzleWorld: A Benchmark for Multimodal, Open-Ended Reasoning in Puzzlehunts
Hengzhi Li, Brendon Jiang, Alexander Naehu, Regan Song, Justin Zhang, Megan Tjandrasuwita, Chanakya Ekbote, Steven-Shine Chen, Adithya Balachandran, Wei Dai, et al. Puzzleworld: A benchmark for multimodal, open-ended reasoning in puzzlehunts.arXiv preprint arXiv:2506.06211, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Visescape: A benchmark for evaluating exploration-driven decision-making in virtual escape rooms
Seungwon Lim, Sungwoong Kim, Jihwan Yu, Sungjae Lee, Jiwan Chung, and Youngjae Yu. Visescape: A benchmark for evaluating exploration-driven decision-making in virtual escape rooms. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 16031–16058, 2025
work page 2025
-
[9]
AgentBench: Evaluating LLMs as Agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. Agentbench: Evaluating llms as agents.arXiv preprint arXiv:2308.03688, 2023
work page internal anchor Pith review arXiv 2023
-
[10]
Haotian Luo, Huaisong Zhang, Xuelin Zhang, Haoyu Wang, Zeyu Qin, Wenjie Lu, Guozheng Ma, Haiying He, Yingsha Xie, Qiyang Zhou, et al. Ultrahorizon: Benchmarking agent capabilities in ultra long-horizon scenarios.arXiv preprint arXiv:2509.21766, 2025
-
[11]
MAA. Aime 2025, 2025. URL https://artofproblemsolving.com/wiki/index.php/AIME_ Problems_and_Solutions
work page 2025
-
[12]
Shishir G Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E Gonzalez. The berkeley function calling leaderboard (bfcl): From tool use to agentic evaluation of large language models. InForty-second International Conference on Machine Learning, 2025
work page 2025
-
[13]
Escapebench: Pushing language models to think outside the box
Cheng Qian, Peixuan Han, Qinyu Luo, Bingxiang He, Xiusi Chen, Yuji Zhang, Hongyi Du, Jiarui Yao, Xiaocheng Yang, Denghui Zhang, et al. Escapebench: Pushing language models to think outside the box. arXiv e-prints, pages arXiv–2412, 2024
work page 2024
-
[14]
Making language models better tool learners with execution feedback
Shuofei Qiao, Honghao Gui, Chengfei Lv, Qianghuai Jia, Huajun Chen, and Ningyu Zhang. Making language models better tool learners with execution feedback. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 3550–3568, 2024. 10
work page 2024
-
[15]
Yuanzhe Shen, Zisu Huang, Zhengyuan Wang, Muzhao Tian, Zhengkang Guo, Chenyang Zhang, Shuaiyu Zhou, Zengjie Hu, Dailin Li, Jingwen Xu, et al. Trip-bench: A benchmark for long-horizon interactive agents in real-world scenarios.arXiv preprint arXiv:2602.01675, 2026
-
[16]
Zinan Tang and Qiyao Sun. Big escape benchmark: Evaluating human-like reasoning in language models via real-world escape room challenges. InProceedings of the Fourth Workshop on Generation, Evaluation and Metrics (GEM2), pages 488–503, 2025
work page 2025
-
[17]
arXiv:2508.20453 [cs.CL] https://arxiv.org/abs/ 2508.20453
Zhenting Wang, Qi Chang, Hemani Patel, Shashank Biju, Cheng-En Wu, Quan Liu, Aolin Ding, Alireza Rezazadeh, Ankit Shah, Yujia Bao, et al. Mcp-bench: Benchmarking tool-using llm agents with complex real-world tasks via mcp servers.arXiv preprint arXiv:2508.20453, 2025
-
[18]
Beichen Zhang, Kun Zhou, Xilin Wei, Xin Zhao, Jing Sha, Shijin Wang, and Ji-Rong Wen. Evaluating and improving tool-augmented computation-intensive math reasoning.Advances in Neural Information Processing Systems, 36:23570–23589, 2023. A Dataset Construction Details This appendix provides full algorithmic details for the six-stage data construction pipeli...
work page 2023
-
[19]
Sample final-goal node.A template with at least one input port is selected uniformly at random. A node is instantiated from this template and designated as the win node; the puzzle’s success condition is defined as producing the correct output of this node
-
[20]
Initialise pending queue.All input ports of the final-goal node are enqueued as pending requirements, each represented as a tuple (v, p, τ, r): target node v, target port p, required type τ, and retry countr= 0. 11 Algorithm 1DAG Skeleton Generation via Reverse Growth Require:Target node countn, template libraryT Ensure:DAG skeletonG= (V, E) 1:Select a ra...
-
[21]
The output is a structuredsource_initmap attached to the DAG metadata
Drop-node outputs: if a node’s triggering input is of type ITEM/HIDDEN_ITEM (indicating activation by a physical object from a container), its output ports that feed downstream nodes are also flagged, because these values must be materialised before forward execution can propagate through them. The output is a structuredsource_initmap attached to the DAG ...
-
[22]
Missing required parameter— The agent omits one or more mandatory input parameters when invoking a tool or item. Triggered when the server reports missing parameters, an empty parameter set, or a partial parameter submission
-
[23]
Wrong node type— The agent attempts an operation incompatible with the node’s type, such as callinguse_itemwith arguments on a simple Item that should be accessed viainvestigate
-
[24]
Repeated solved node— The agent attempts to unlock an item that has already been successfully solved in a previous step, wasting a turn
-
[25]
Wrong parameter type— The agent provides a parameter value with an incorrect data type (e.g., passing an integer where a hex string is expected)
-
[26]
Node not visible— The agent attempts to invoke a node that does not currently exist in the environment, or mistakenly treats a non-node entity as an invocable node
-
[27]
Node not exist— The agent references a node ID that does not exist in the current scenario, typically due to hallucinating a node name or confusing template names with instance-specific IDs
-
[28]
Wrong format— The agent’s tool-call request is structurally malformed, missing essential fields such asnode_id. 8.Other— Errors that do not match any of the above classification rules. C Example Solving Trajectory We present a complete interaction trace of Claude-Opus-4.6 solving a difficulty-10 instance. The agent successfully solves the puzzle in 12 tur...
-
[29]
**text_bidi_sanitize** password for zip (input: `ComplexPassphrase_123!`)
-
[30]
**zip_unzip_file** file_id for graph
-
[31]
**graph_shortest_path** cost (used in calc_gcd and calc_big [...reasoning...] >> text_bidi_sanitize(text="ComplexPassphrase_123!") >> checksum_crc32(hex="4a2b3c4d5e6f708192a3b4...") >> num_base_convert_83f4(from_base="10", s="9182736450192837465192...", to_base="10") Tool Tool text_bidi_sanitize invoked Output: {"text": "ComplexPassphrase_123!"} All param...
-
[32]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.