Recognition: no theorem link
Delta-Adapter: Scalable Exemplar-Based Image Editing with Single-Pair Supervision
Pith reviewed 2026-05-11 03:28 UTC · model grok-4.3
The pith
Delta-Adapter learns image edits from single source-target pairs by extracting a semantic delta and injecting it through an adapter.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
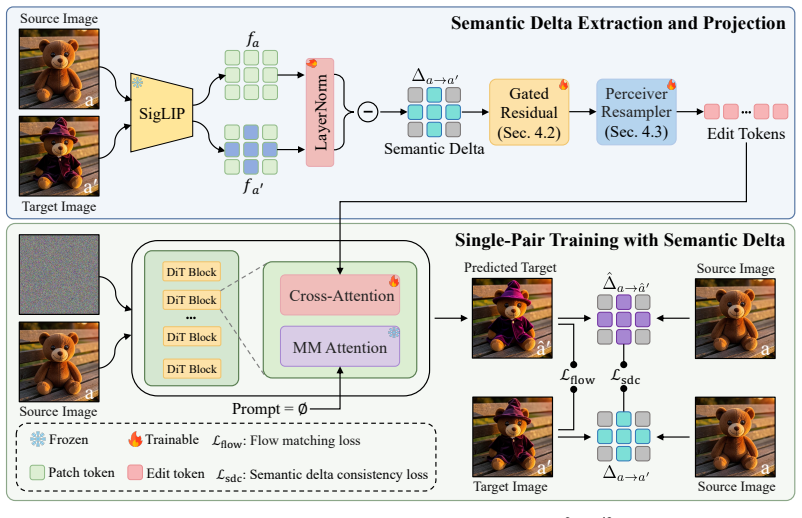
By extracting a semantic delta from an exemplar pair using a pre-trained vision encoder and injecting it into a pre-trained image editing model via a Perceiver adapter, the method achieves faithful transformation transfer under single-pair supervision, with a semantic delta consistency loss ensuring the generated output matches the ground-truth delta, yielding higher editing accuracy and content consistency than pair-of-pairs baselines on both seen and unseen tasks.
What carries the argument
The semantic delta, computed as the feature difference from a pre-trained vision encoder between source and target images in an exemplar pair, which is injected into the editing model via a Perceiver-based adapter to guide the transformation without direct exposure to the target image.
If this is right
- Training can scale to larger datasets because only one pair per edit type is required instead of matched pairs.
- Editing accuracy and content preservation improve compared with methods that demand pair-of-pairs supervision.
- Generalization to previously unseen edit types becomes stronger through the transferable delta representation.
- The process operates without any textual description of the desired change.
Where Pith is reading between the lines
- The same delta extraction could extend to video or 3D editing if comparable feature differences can be computed across frames or models.
- Multiple deltas might be combined to compose complex or sequential edits within one forward pass.
- The approach suggests that pre-trained encoders already contain enough edit semantics to reduce the need for custom paired data in other transformation tasks.
Load-bearing premise
The semantic delta extracted by the vision encoder faithfully encodes the intended visual transformation and remains transferable when injected into the editing model for new images.
What would settle it
Apply the trained adapter with a semantic delta from an exemplar pair to a new query image and check whether the feature difference between the generated output and the query matches the supplied delta; mismatch on held-out pairs would show the transfer has failed.
Figures













read the original abstract
Exemplar-based image editing applies a transformation defined by a source-target image pair to a new query image. Existing methods rely on a pair-of-pairs supervision paradigm, requiring two image pairs sharing the same edit semantics to learn the target transformation. This constraint makes training data difficult to curate at scale and limits generalization across diverse edit types. We propose Delta-Adapter, a method that learns transferable editing semantics under single-pair supervision, requiring no textual guidance. Rather than directly exposing the exemplar pair to the model, we leverage a pre-trained vision encoder to extract a semantic delta that encodes the visual transformation between the two images. This semantic delta is injected into a pre-trained image editing model via a Perceiver-based adapter. Since the target image is never directly visible to the model, it can serve as the prediction target, enabling single-pair supervision without requiring additional exemplar pairs. This formulation allows us to leverage existing large-scale editing datasets for training. To further promote faithful transformation transfer, we introduce a semantic delta consistency loss that aligns the semantic change of the generated output with the ground-truth semantic delta extracted from the exemplar pair. Extensive experiments demonstrate that Delta-Adapter consistently improves both editing accuracy and content consistency over four strong baselines on seen editing tasks, while also generalizing more effectively to unseen editing tasks. Code will be available at https://delta-adapter.github.io.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Delta-Adapter for exemplar-based image editing that operates under single-pair supervision. A pre-trained vision encoder extracts a semantic delta (feature difference) between a source-target exemplar pair; this delta is injected into a frozen pre-trained editing backbone via a Perceiver-based adapter. Because the target image is never shown to the model during inference, it can be used directly as supervision. A semantic delta consistency loss is added to encourage the output to preserve the same transformation. The central claim is that this yields higher editing accuracy and content consistency than four baselines on both seen and unseen editing tasks while enabling training on large-scale datasets that lack pair-of-pairs structure.
Significance. If the quantitative claims hold, the work would be significant: it removes the pair-of-pairs data requirement that has limited scaling of exemplar-based editors, demonstrates that a lightweight adapter can transfer semantic deltas across tasks, and reports improved generalization to unseen edits. The approach is parameter-efficient and re-uses existing large editing corpora, which could accelerate progress in controllable image synthesis.
major comments (3)
- [§3.2] §3.2 (semantic delta extraction): The method treats the difference of frozen encoder features as a faithful, transferable encoding of the visual transformation. This assumption is load-bearing for both the single-pair supervision claim and the unseen-task generalization result, yet the manuscript provides no analysis of what information is preserved or lost (e.g., for shape vs. color vs. style edits) and no failure-case study when the encoder representation is known to be entangled.
- [§4] §4 (experiments): The abstract and introduction assert “consistent gains” and “more effective generalization” over four baselines, but the evaluation section lacks reported numerical tables, ablation results for the consistency loss, statistical significance, or error bars. Without these, the magnitude and reliability of the claimed improvements cannot be assessed.
- [§3.3] §3.3 (adapter injection): The Perceiver adapter is presented as the mechanism that enables delta transfer without ever exposing the target image. However, the training objective still relies on the quality of the upstream frozen encoder; no controlled experiment isolates whether performance degrades when the encoder is replaced by a weaker or differently trained feature extractor.
minor comments (2)
- [§3.1] Notation for the semantic delta (Δ) is introduced without an explicit equation; adding a numbered equation would improve clarity.
- [Figure 2] Figure 2 (method overview) would benefit from an explicit arrow or label showing that the target image is used only for the consistency loss and never as model input.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential impact of our work on scalable exemplar-based editing. We address each major comment below, providing clarifications and committing to revisions where appropriate to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (semantic delta extraction): The method treats the difference of frozen encoder features as a faithful, transferable encoding of the visual transformation. This assumption is load-bearing for both the single-pair supervision claim and the unseen-task generalization result, yet the manuscript provides no analysis of what information is preserved or lost (e.g., for shape vs. color vs. style edits) and no failure-case study when the encoder representation is known to be entangled.
Authors: We agree that additional analysis would enhance the paper's rigor. In the revised manuscript, we will add a dedicated subsection analyzing the semantic delta's preservation of information across edit categories (shape, color, style) through feature visualizations, similarity metrics, and qualitative examples. We will also include a failure-case study section discussing limitations when the encoder features are entangled, such as in intricate style or geometric transformations, and how the consistency loss mitigates some issues. This will better support the claims of transferability. revision: yes
-
Referee: [§4] §4 (experiments): The abstract and introduction assert “consistent gains” and “more effective generalization” over four baselines, but the evaluation section lacks reported numerical tables, ablation results for the consistency loss, statistical significance, or error bars. Without these, the magnitude and reliability of the claimed improvements cannot be assessed.
Authors: We acknowledge the need for more comprehensive quantitative evaluation. The revised version will include detailed numerical tables presenting all metrics for the four baselines on both seen and unseen tasks. We will add ablation studies specifically for the semantic delta consistency loss, showing its impact on performance. Additionally, we will report statistical significance (e.g., p-values from t-tests) and error bars computed over multiple random seeds to demonstrate the reliability of the improvements. revision: yes
-
Referee: [§3.3] §3.3 (adapter injection): The Perceiver adapter is presented as the mechanism that enables delta transfer without ever exposing the target image. However, the training objective still relies on the quality of the upstream frozen encoder; no controlled experiment isolates whether performance degrades when the encoder is replaced by a weaker or differently trained feature extractor.
Authors: We appreciate this point on isolating the encoder's role. In the updated manuscript, we will incorporate a controlled experiment ablating the encoder by substituting it with weaker alternatives, such as a shallower network or one trained on different data. This will quantify performance degradation and highlight the adapter's ability to leverage high-quality deltas while showing the method's sensitivity to encoder quality. revision: yes
Circularity Check
No significant circularity; method is architecturally independent of its empirical claims
full rationale
The paper proposes Delta-Adapter as a new architecture: semantic delta extracted once from a frozen pre-trained vision encoder, injected via a Perceiver adapter into a frozen editing backbone, trained with image-level supervision on the held-out target plus an auxiliary consistency loss on deltas. None of these components is defined in terms of the final performance metric or the generalization result. The single-pair supervision follows directly from withholding the target image from the forward pass (a standard design choice), and the consistency loss is an explicit regularizer rather than a tautology that forces the output by construction. No self-citation chain, uniqueness theorem, or fitted parameter renamed as prediction appears in the derivation. The reported gains on seen and unseen tasks remain empirical claims that can be falsified by new experiments.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A pre-trained vision encoder can extract a semantic delta that encodes the visual transformation between source and target images.
- domain assumption Injecting the semantic delta via a Perceiver-based adapter into a pre-trained editing model enables faithful transfer without exposing the target image.
invented entities (1)
-
semantic delta
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Flamingo: a visual language model for few-shot learning
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. InNeurIPS, 2022
work page 2022
-
[2]
Blended diffusion for text-driven editing of natural images
Omri Avrahami, Dani Lischinski, and Ohad Fried. Blended diffusion for text-driven editing of natural images. InCVPR, 2022
work page 2022
-
[3]
Omri Avrahami, Ohad Fried, and Dani Lischinski. Blended latent diffusion. InSIGGRAPH, 2023
work page 2023
-
[4]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization.arXiv preprint arXiv:1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[5]
Amir Bar, Yossi Gandelsman, Trevor Darrell, Amir Globerson, and Alexei A. Efros. Visual prompting via image inpainting. InNeurIPS, 2022
work page 2022
-
[6]
Ledits++: Limitless image editing using text-to-image models
Manuel Brack, Felix Friedrich, Katharina Kornmeier, Linoy Tsaban, Patrick Schramowski, Kristian Kersting, and Apolinário Passos. Ledits++: Limitless image editing using text-to-image models. InCVPR, 2024
work page 2024
-
[7]
Tim Brooks, Aleksander Holynski, and Alexei A. Efros. Instructpix2pix: Learning to follow image editing instructions. InCVPR, 2023
work page 2023
-
[8]
Edit transfer: Learning image editing via vision in-context relations,
Lan Chen, Qi Mao, Yuchao Gu, and Mike Zheng Shou. Edit transfer: Learning image editing via vision in-context relations.arXiv preprint arXiv:2503.13327, 2025
-
[9]
Anydoor: Zero-shot object-level image customization
Xi Chen, Lianghua Huang, Yu Liu, Yujun Shen, Deli Zhao, and Hengshuang Zhao. Anydoor: Zero-shot object-level image customization. InCVPR, 2024
work page 2024
-
[10]
On the detection of synthetic images generated by diffusion models
Riccardo Corvi, Davide Cozzolino, Giada Zingarini, Giovanni Poggi, Koki Nagano, and Luisa Verdoliva. On the detection of synthetic images generated by diffusion models. InICASSP, 2023
work page 2023
-
[11]
Diffedit: Diffusion- based semantic image editing with mask guidance
Guillaume Couairon, Jakob Verbeek, Holger Schwenk, and Matthieu Cord. Diffedit: Diffusion- based semantic image editing with mask guidance. InICLR, 2023
work page 2023
- [12]
-
[13]
Guiding instruction-based image editing via multimodal large language models
Tsu-Jui Fu, Wenze Hu, Xianzhi Du, William Yang Wang, Yinfei Yang, and Zhe Gan. Guiding instruction-based image editing via multimodal large language models. InICLR, 2024
work page 2024
-
[14]
Instructdiffusion: A generalist modeling interface for vision tasks
Zigang Geng, Binxin Yang, Tiankai Hang, Chen Li, Shuyang Gu, Ting Zhang, Jianmin Bao, Zheng Zhang, Han Hu, Dong Chen, and Baining Guo. Instructdiffusion: A generalist modeling interface for vision tasks. InCVPR, 2024
work page 2024
-
[15]
Relationadapter: Learning and transferring visual relation with diffusion transformers
Yan Gong, Yiren Song, Yicheng Li, Chenglin Li, and Yin Zhang. Relationadapter: Learning and transferring visual relation with diffusion transformers. InNeurIPS, 2025
work page 2025
-
[16]
Analogist: Out-of-the-box visual in-context learning with image diffusion model
Zheng Gu, Shiyuan Yang, Jing Liao, Jing Huo, and Yang Gao. Analogist: Out-of-the-box visual in-context learning with image diffusion model. InSIGGRAPH, 2024
work page 2024
-
[17]
Prompt-to-Prompt Image Editing with Cross Attention Control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt image editing with cross attention control.arXiv preprint arXiv:2208.01626, 2022
work page internal anchor Pith review arXiv 2022
-
[18]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In NeurIPS, 2020
work page 2020
-
[19]
Smartedit: Exploring complex instruction-based image editing with multimodal large language models
Yuzhou Huang, Liangbin Xie, Xintao Wang, Ziyang Yuan, Xiaodong Cun, Yixiao Ge, Jiantao Zhou, Chao Dong, Rui Huang, Ruimao Zhang, and Ying Shan. Smartedit: Exploring complex instruction-based image editing with multimodal large language models. InCVPR, 2024
work page 2024
-
[20]
Image generation from contextually-contradictory prompts.arXiv preprint arXiv:2506.01929, 2025
Saar Huberman, Or Patashnik, Omer Dahary, Ron Mokady, and Daniel Cohen-Or. Image generation from contextually-contradictory prompts.arXiv preprint arXiv:2506.01929, 2025. 10
-
[21]
Chuck Jacobs, D Salesin, N Oliver, A Hertzmann, and A Curless. Image analogies. In SIGGRAPH, 2001
work page 2001
-
[22]
Customizing text-to-image models with a single image pair
Maxwell Jones, Sheng-Yu Wang, Nupur Kumari, David Bau, and Jun-Yan Zhu. Customizing text-to-image models with a single image pair. InSIGGRAPH Asia, 2024
work page 2024
-
[23]
Imagic: Text-based real image editing with diffusion models
Bahjat Kawar, Shiran Zada, Oran Lang, Omer Tov, Huiwen Chang, Tali Dekel, Inbar Mosseri, and Michal Irani. Imagic: Text-based real image editing with diffusion models. InCVPR, 2023
work page 2023
-
[24]
Diffusionclip: Text-guided diffusion models for robust image manipulation
Gwanghyun Kim, Taesung Kwon, and Jong Chul Ye. Diffusionclip: Text-guided diffusion models for robust image manipulation. InCVPR, 2022
work page 2022
-
[25]
Nohumansrequired: Autonomous high-quality image editing triplet mining
Maksim Kuprashevich, Grigorii Alekseenko, Irina Tolstykh, Georgii Fedorov, Bulat Suleimanov, Vladimir Dokholyan, and Aleksandr Gordeev. Nohumansrequired: Autonomous high-quality image editing triplet mining. InWACV, 2026
work page 2026
- [26]
-
[27]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, Sumith Kulal, Kyle Lacey, Yam Levi, Cheng Li, Dominik Lorenz, Jonas Müller, Dustin Podell, Robin Rombach, Harry Saini, Axel Sauer, and Luke Smith. Flux.1 kontext: Flow matching for in-context image ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [28]
-
[29]
Visualcloze: A universal image generation framework via visual in-context learning
Zhong-Yu Li, Ruoyi Du, Juncheng Yan, Le Zhuo, Zhen Li, Peng Gao, Zhanyu Ma, and Ming- Ming Cheng. Visualcloze: A universal image generation framework via visual in-context learning. InICCV, 2025
work page 2025
-
[30]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. InICLR, 2023
work page 2023
-
[31]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InICLR, 2023
work page 2023
-
[32]
Pairedit: Learning semantic variations for exemplar-based image editing
Haoguang Lu, Jiacheng Chen, Zhenguo Yang, Aurele Tohokantche Gnanha, Fu Lee Wang, Li Qing, and Xudong Mao. Pairedit: Learning semantic variations for exemplar-based image editing. InNeurIPS, 2025
work page 2025
-
[33]
Spanning the visual analogy space with a weight basis of loras.arXiv preprint arXiv:2602.15727, 2026
Hila Manor, Rinon Gal, Haggai Maron, Tomer Michaeli, and Gal Chechik. Spanning the visual analogy space with a weight basis of loras.arXiv preprint arXiv:2602.15727, 2026
-
[34]
Sdedit: Guided image synthesis and editing with stochastic differential equations
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. Sdedit: Guided image synthesis and editing with stochastic differential equations. In ICLR, 2022
work page 2022
-
[35]
Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, Ying Shan, and Xiaohu Qie. T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models.arXiv preprint arXiv:2302.08453, 2023
-
[36]
Visual instruction inversion: Image editing via visual prompting
Thao Nguyen, Yuheng Li, Utkarsh Ojha, and Yong Jae Lee. Visual instruction inversion: Image editing via visual prompting. InNeurIPS, 2023
work page 2023
- [37]
-
[38]
Zero-shot image-to-image translation
Gaurav Parmar, Krishna Kumar Singh, Richard Zhang, Yijun Li, Jingwan Lu, and Jun-Yan Zhu. Zero-shot image-to-image translation. InSIGGRAPH, 2023
work page 2023
-
[39]
Localizing object-level shape variations with text-to-image diffusion models
Or Patashnik, Daniel Garibi, Idan Azuri, Hadar Averbuch-Elor, and Daniel Cohen-Or. Localizing object-level shape variations with text-to-image diffusion models. InICCV, 2023
work page 2023
-
[40]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InICCV, 2023. 11
work page 2023
-
[41]
Yusu Qian, Eli Bocek-Rivele, Liangchen Song, Jialing Tong, Yinfei Yang, Jiasen Lu, Wenze Hu, and Zhe Gan. Pico-banana-400k: A large-scale dataset for text-guided image editing.arXiv preprint arXiv:2510.19808, 2025
-
[42]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InICML, 2021
work page 2021
-
[43]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InCVPR, 2022
work page 2022
-
[44]
Emu edit: Precise image editing via recognition and generation tasks
Shelly Sheynin, Adam Polyak, Uriel Singer, Yuval Kirstain, Amit Zohar, Oron Ashual, Devi Parikh, and Yaniv Taigman. Emu edit: Precise image editing via recognition and generation tasks. InCVPR, 2024
work page 2024
-
[45]
Xue Song, Jiequan Cui, Hanwang Zhang, Jiaxin Shi, Jingjing Chen, Chi Zhang, and Yu-Gang Jiang. Lora of change: Learning to generate lora for the editing instruction from a single before-after image pair.arXiv preprint arXiv:2411.19156, 2024
-
[46]
Reedit: Multimodal exemplar-based image editing
Ashutosh Srivastava, Tarun Ram Menta, Abhinav Java, Avadhoot Gorakh Jadhav, Silky Singh, Surgan Jandial, and Balaji Krishnamurthy. Reedit: Multimodal exemplar-based image editing. InWACV, 2025
work page 2025
-
[47]
Imagebrush: Learning visual in-context instructions for exemplar-based image manipulation
Yasheng Sun, Yifan Yang, Houwen Peng, Yifei Shen, Yuqing Yang, Han Hu, Lili Qiu, and Hideki Koike. Imagebrush: Learning visual in-context instructions for exemplar-based image manipulation. InNeurIPS, 2023
work page 2023
-
[48]
Plug-and-play diffusion features for text-driven image-to-image translation
Narek Tumanyan, Michal Geyer, Shai Bagon, and Tali Dekel. Plug-and-play diffusion features for text-driven image-to-image translation. InCVPR, 2023
work page 2023
-
[49]
Sheng-Yu Wang, Oliver Wang, Richard Zhang, Andrew Owens, and Alexei A. Efros. Cnn- generated images are surprisingly easy to spot... for now. InCVPR, 2020
work page 2020
-
[50]
Fleet, Radu Soricut, Jason Baldridge, Mohammad Norouzi, Peter Anderson, and William Chan
Su Wang, Chitwan Saharia, Ceslee Montgomery, Jordi Pont-Tuset, Shai Noy, Stefano Pellegrini, Yasumasa Onoe, Sarah Laszlo, David J. Fleet, Radu Soricut, Jason Baldridge, Mohammad Norouzi, Peter Anderson, and William Chan. Imagen editor and editbench: Advancing and evaluating text-guided image inpainting. InCVPR, 2023
work page 2023
-
[51]
Images speak in images: A generalist painter for in-context visual learning
Xinlong Wang, Wen Wang, Yue Cao, Chunhua Shen, and Tiejun Huang. Images speak in images: A generalist painter for in-context visual learning. InCVPR, 2023
work page 2023
-
[52]
In-context learning unlocked for diffusion models
Zhendong Wang, Yifan Jiang, Yadong Lu, Yelong Shen, Pengcheng He, Weizhu Chen, Zhangyang Wang, and Mingyuan Zhou. In-context learning unlocked for diffusion models. arXiv preprint arXiv:2305.01115, 2023
-
[53]
Zeren Xiong, Yue Yu, Zedong Zhang, Shuo Chen, Jian Yang, and Jun Li. Vmdiff: Visual mixing diffusion for limitless cross-object synthesis.arXiv preprint arXiv:2509.23605, 2025
-
[54]
Paint by example: Exemplar-based image editing with diffusion models
Binxin Yang, Shuyang Gu, Bo Zhang, Ting Zhang, Xuejin Chen, Xiaoyan Sun, Dong Chen, and Fang Wen. Paint by example: Exemplar-based image editing with diffusion models. In CVPR, 2023
work page 2023
-
[55]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models.arXiv preprint arXiv:2308.06721, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[56]
arXiv preprint arXiv:2304.06790 , year=
Tao Yu, Runseng Feng, Ruoyu Feng, Jinming Liu, Xin Jin, Wenjun Zeng, and Zhibo Chen. Inpaint anything: Segment anything meets image inpainting.arXiv preprint arXiv:2304.06790, 2023
-
[57]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InICCV, 2023
work page 2023
-
[58]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. InICCV, 2023. 12
work page 2023
-
[59]
Efros, Eli Shechtman, and Oliver Wang
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang. The unreason- able effectiveness of deep features as a perceptual metric. InCVPR, 2018
work page 2018
-
[60]
Hive: Harnessing human feedback for instructional visual editing
Shu Zhang, Xinyi Yang, Yihao Feng, Can Qin, Chia-Chih Chen, Ning Yu, Zeyuan Chen, Huan Wang, Silvio Savarese, Stefano Ermon, Caiming Xiong, and Ran Xu. Hive: Harnessing human feedback for instructional visual editing. InCVPR, 2024
work page 2024
-
[61]
What makes good examples for visual in-context learning?arXiv preprint arXiv:2301.13670, 2023
Yuanhan Zhang, Kaiyang Zhou, and Ziwei Liu. What makes good examples for visual in-context learning?arXiv preprint arXiv:2301.13670, 2023
- [62]
-
[63]
A task is worth one word: Learning with task prompts for high-quality versatile image inpainting
Junhao Zhuang, Yanhong Zeng, Wenran Liu, Chun Yuan, and Kai Chen. A task is worth one word: Learning with task prompts for high-quality versatile image inpainting. InECCV, 2024. 13 A Implementation Details Our method.We build Delta-Adapter on top of FLUX.2-klein-4B 2, using SigLIP-2 [ 57] (google/siglip2-base-patch16-224) as the image encoder. The mapping...
work page 2024
-
[64]
Infer the intended edit from the actual visual transformation fromA→B
-
[65]
Judge whether the same edit is correctly transferred fromC→D
-
[66]
ScoreDon two dimensions: GPT-A (Editing Accuracy):Whether the candidate correctly applies the intended edit or transfor- mation shown byA→B. GPT-C (Content Consistency):Whether the candidate preserves the source imageCeverywhere outside the intended edit. Focus on non-target content preservation: identity, structure, geometry, layout, background, pose/cam...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.