Recognition: 2 theorem links
· Lean TheoremHEART: Hyperspherical Embedding Alignment via Kent-Representation Traversal in Diffusion Models
Pith reviewed 2026-05-11 03:07 UTC · model grok-4.3
The pith
Text encoder representations lie on a hypersphere, where Kent distributions enable precise training-free edits in diffusion models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
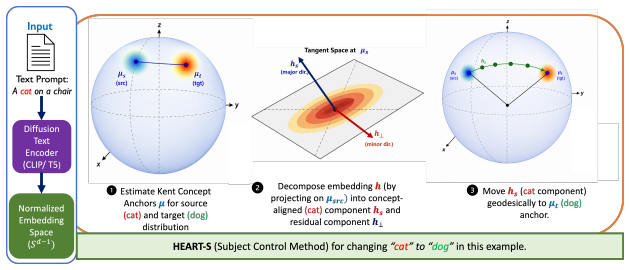
Text encoder representations lie on a hypersphere, where concepts are not linear directions but structured, anisotropic distributions better captured by Kent distributions. HEART performs Kent-aware geodesic transformations on this hyperspherical space to enable intuitive and precise edits, such as consistent subject replacement and fine-grained attribute control, while preserving the original scene, all without finetuning, inversion, or optimization.
What carries the argument
Kent-aware geodesic traversal on hyperspherical embeddings, which respects the spherical geometry and anisotropic structure to perform precise semantic alignments and transformations.
If this is right
- Consistent subject replacement without altering backgrounds or other elements.
- Fine-grained control over specific attributes in generated images.
- Preservation of the original scene composition during edits.
- No requirement for model finetuning, inversion, or per-image optimization.
- Applicability across different diffusion model architectures without modification.
Where Pith is reading between the lines
- The hyperspherical view could account for failures of Euclidean editing techniques in other text-conditioned generation systems.
- Similar Kent-based traversals might extend to controlling embeddings in audio or video diffusion models.
- Empirical tests on whether non-text embeddings in these models also exhibit Kent-like anisotropy would test the generality of the geometric insight.
Load-bearing premise
The assumption that text encoder representations truly lie on a hypersphere with anisotropic structure that is best modeled by Kent distributions, allowing Kent-aware geodesic transformations to produce precise edits without side effects.
What would settle it
Observing that linear transformations achieve equivalent edit precision to HEART on the same prompts, or finding that text embeddings are better fit by isotropic distributions rather than Kent distributions, would falsify the need for the spherical Kent approach.
Figures








read the original abstract
Text-to-image diffusion models can generate visually stunning images, yet, controlling what appears and how it appears, remains surprisingly difficult, especially when operating solely within the constraints of the text-conditioning space. For example, changing a subject or adjusting an attribute often leads to unintended side effects, such as altered backgrounds or distorted details. This is because most existing text-based control methods treat the embedding space as Euclidean and apply simple linear transformations, which do not reflect how semantic concepts are actually organized. In this work, we take a step back and ask: what is the true geometry of these embeddings? We find that text encoder representations lie on a hypersphere, where concepts are not linear directions but structured, anisotropic distributions better captured by Kent distributions. Building on this insight, we propose HEART, a training-free framework that performs Kent-aware geodesic transformations directly on the hypersphere. By respecting the underlying geometry, HEART enables intuitive and precise edits, such as consistent subject replacement and fine-grained attribute control, while preserving the original scene. Importantly, HEART requires no finetuning, inversion, or optimization, and generalizes across diffusion model architectures. Our results show that a simple shift in perspective, from linear to spherical, can unlock fast, and controllable image generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that text encoder representations in text-to-image diffusion models lie on a hypersphere, with semantic concepts forming structured anisotropic distributions best modeled by Kent distributions rather than Euclidean linear directions or simpler spherical models like von Mises-Fisher. It proposes HEART, a training-free framework that performs Kent-aware geodesic transformations directly on this hypersphere to enable precise, intuitive edits (e.g., consistent subject replacement and fine-grained attribute control) while preserving the original scene, generalizing across architectures without finetuning, inversion, or optimization.
Significance. If the geometric characterization of the embedding space is rigorously validated and the editing method is shown to produce side-effect-free results superior to linear baselines, the work could provide a useful shift toward geometry-aware control in diffusion models, potentially improving reliability in text-conditioned generation tasks.
major comments (2)
- [Abstract] Abstract: The central assertion that text encoder representations 'lie on a hypersphere' and form 'structured, anisotropic distributions better captured by Kent distributions' is presented without any reported statistical evidence, such as fitted concentration parameters, likelihood ratio tests against von Mises-Fisher distributions, or ablation studies on anisotropy. This is load-bearing because the motivation and correctness of the subsequent HEART geodesic traversals depend entirely on this unverified structure.
- [Method] Method section (HEART framework): No explicit equations, parameter estimation procedure, or algorithmic description is given for computing the Kent-aware geodesic transformations or ensuring they avoid side effects on background and details. Without these, the claim of 'precise edits without side effects' and generalization across models cannot be assessed or reproduced.
minor comments (2)
- [Abstract] Abstract: The phrase 'our results show' is used but no quantitative metrics, baselines, or specific evaluation protocols are mentioned to support the effectiveness claims.
- [Introduction] Introduction: References to prior work on spherical embeddings or Kent distributions in other domains are absent, which would help contextualize the novelty of applying this to text encoders.
Simulated Author's Rebuttal
Thank you for the referee's constructive feedback. We address the major comments point by point below and commit to revisions that will strengthen the statistical grounding and methodological clarity of the work.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central assertion that text encoder representations 'lie on a hypersphere' and form 'structured, anisotropic distributions better captured by Kent distributions' is presented without any reported statistical evidence, such as fitted concentration parameters, likelihood ratio tests against von Mises-Fisher distributions, or ablation studies on anisotropy. This is load-bearing because the motivation and correctness of the subsequent HEART geodesic traversals depend entirely on this unverified structure.
Authors: We acknowledge that the abstract states the geometric characterization without accompanying statistical tests. The manuscript does include embedding visualizations and editing results that empirically support the hyperspherical and anisotropic structure. To address the concern directly, we will add a new subsection in the revised version containing quantitative validation: fitted Kent concentration parameters, likelihood-ratio tests against von Mises-Fisher, and targeted ablations on anisotropy. These additions will make the motivation for Kent-aware geodesics explicit and reproducible. revision: yes
-
Referee: [Method] Method section (HEART framework): No explicit equations, parameter estimation procedure, or algorithmic description is given for computing the Kent-aware geodesic transformations or ensuring they avoid side effects on background and details. Without these, the claim of 'precise edits without side effects' and generalization across models cannot be assessed or reproduced.
Authors: We agree that the current method description is insufficient for assessment and reproduction. In the revised manuscript we will expand the HEART framework section with: (i) the full Kent distribution equations and parameterization, (ii) the maximum-likelihood or moment-based estimation procedure for the Kent parameters, (iii) the precise algorithmic steps for the geodesic traversal on the hypersphere, and (iv) the explicit mechanism used to restrict transformations to the target semantic region while leaving background and unrelated details unchanged. These additions will enable readers to verify the side-effect-free property and cross-architecture generalization. revision: yes
Circularity Check
No circularity: empirical geometry claim and training-free method are independent of fitted inputs or self-referential definitions.
full rationale
The paper asserts an empirical finding that text-encoder embeddings lie on a hypersphere and are better modeled by anisotropic Kent distributions than simpler alternatives, then constructs a training-free geodesic traversal method (HEART) that operates directly on that geometry. No equations, fitting procedures, or self-citations are shown that would make any claimed prediction or edit capability equivalent to the input observations by construction. The derivation chain therefore remains self-contained: the geometric premise is presented as an independent observation, and the editing framework is derived from it without reducing to a renamed fit or load-bearing self-reference.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Text encoder representations lie on a hypersphere with structured anisotropic distributions best captured by Kent distributions.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
text encoder representations lie on a hypersphere, where concepts are not linear directions but structured, anisotropic distributions better captured by Kent distributions... Kent-aware geodesic transformations directly on the hypersphere
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Cure: Concept unlearning via orthogonal represen- tation editing in diffusion models
Shristi Das Biswas, Arani Roy, and Kaushik Roy. Cure: Concept unlearning via orthogonal represen- tation editing in diffusion models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025a. Shristi Das Biswas, Arani Roy, and Kaushik Roy. Now you see it, now you don’t-instant concept erasure for safe text-to-image and video ge...
-
[2]
When Does Embedding Magnitude Matter? A Cross-Task Functional-Symmetry Framework
Xincan Feng and Taro Watanabe. Beyond the unit hypersphere: Embedding magnitude in contrastive learning.arXiv preprint arXiv:2602.09229,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Prompt-to-Prompt Image Editing with Cross Attention Control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt- to-prompt image editing with cross attention control.arXiv preprint arXiv:2208.01626,
work page internal anchor Pith review arXiv
-
[4]
Modelling of directional data using kent distributions.arXiv preprint arXiv:1506.08105,
Parthan Kasarapu. Modelling of directional data using kent distributions.arXiv preprint arXiv:1506.08105,
-
[5]
The double-ellipsoid geometry of clip.arXiv preprint arXiv:2411.14517,
Meir Yossef Levi and Guy Gilboa. The double-ellipsoid geometry of clip.arXiv preprint arXiv:2411.14517,
-
[6]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Accessed: 2026-05-03. Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952,
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
ξ ∥ξ∥2 . A geodesic step along tangent directiondwith strengthλis thusExp u(λd) = cos(λ)u+ sin(λ)d. HEART-S uses the geodesic operator to rotate a concept-aligned component from source anchorµs toward target anchor µt: µs→t = Geo(µs, µt;λ). HEART-A instead computes an attribute direction in the tangent space and applies an exponential-map update from the ...
work page 2018
-
[8]
A young person, photorealistic
499 . We evaluate four attributes:age,smile,curly hair, andchubby. Attribute strength is measured using ∆CLIP, computed between edited images and attribute-specific text prompts, while structural preservation is measured using LPIPS between original and edited images. BaselinesFor subject replacement, we compare against: SEGA Brack et al. [2023], LEDITS++...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.