Recognition: 2 theorem links
· Lean TheoremSemantic Smoothing for Language Models via Distribution Estimation and Embeddings
Pith reviewed 2026-05-11 02:27 UTC · model grok-4.3
The pith
Context embeddings let language models share next-word statistics across similar contexts, yielding an interpolation estimator with KL risk O(min{Δ, d/n}).
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Semantic smoothing is distribution estimation under KL loss supplied with side-information distributions whose KL distances to the target are known or estimated from context embeddings. The Lipschitz-logit model guarantees that embedding proximity translates into KL proximity of the conditional distributions. The proposed interpolation estimator then achieves worst-case KL risk O(min{Δ, d/n}) for n samples over a d-symbol alphabet when side information lies at KL distance Δ, and the paper proves a matching lower bound when the side information is uniform. The estimator extends directly to multiple synonymous distributions and to empirically estimated ones.
What carries the argument
Interpolation estimator that blends the empirical next-word distribution with KL-proximate side-information distributions obtained from context embeddings.
If this is right
- The same risk bound continues to hold when the side-information distributions are themselves estimated rather than given.
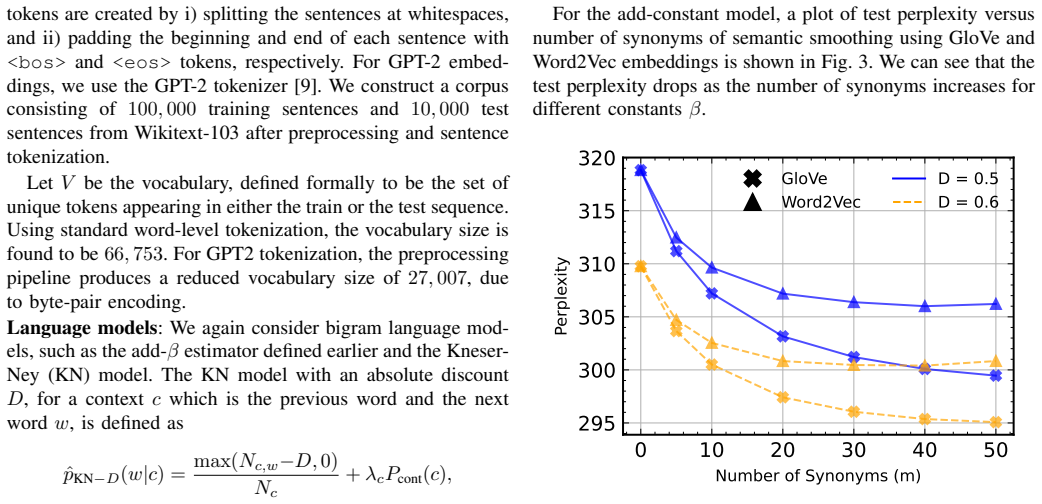
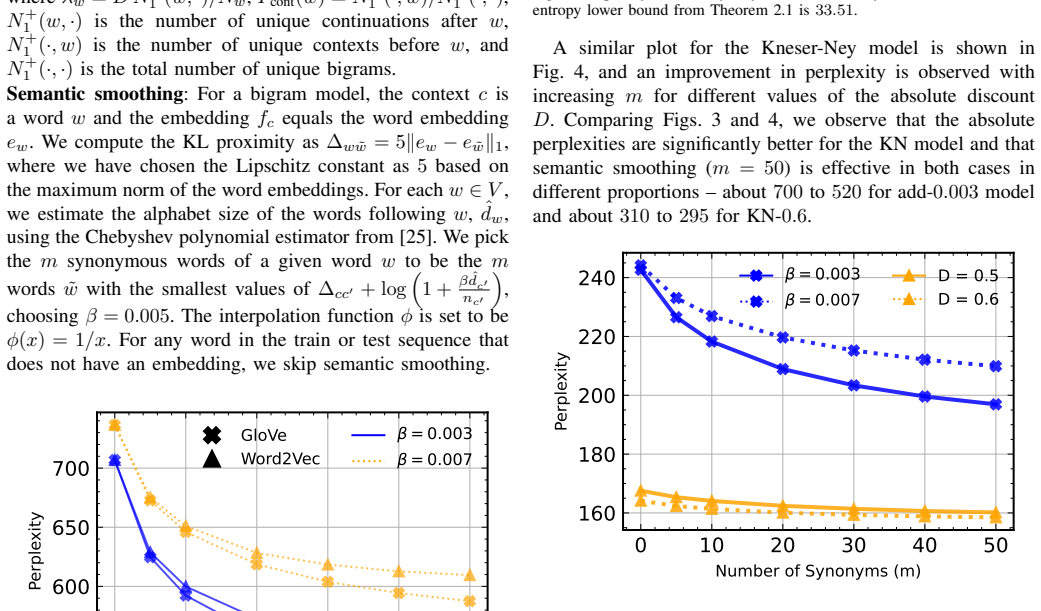
- Adding semantic smoothing to add-constant or Kneser-Ney estimators lowers test perplexity on bigram models of WikiText-103 when Word2Vec, GloVe, or GPT-2 embeddings are used.
- The method applies unchanged to multiple synonymous contexts at different distances.
- On synthetic Markov data the empirical risk tracks the predicted O(min{Δ, d/n}) scaling.
Where Pith is reading between the lines
- If the Lipschitz-logit relation extends to transformer hidden states, the same interpolation could be applied inside large language models without changing their architecture.
- The technique may extend to higher-order n-gram or neural conditional distributions whenever embedding or representation similarity can be quantified.
- One could measure the effective Δ realized by different embedding models and check whether lower Δ reliably produces lower perplexity as the bound predicts.
Load-bearing premise
The next-word log-probabilities vary Lipschitz-continuously with the context embedding vectors.
What would settle it
Fix two contexts whose embeddings differ by a small Euclidean distance yet whose empirical next-word distributions differ by a KL divergence much larger than the Lipschitz constant would allow; if the observed KL risk then exceeds O(min{Δ, d/n}) in controlled synthetic trials with known Δ, the rate claim fails.
Figures


read the original abstract
We propose semantic smoothing, a smoothing method for language models that uses embeddings to share statistical observations across semantically similar contexts. The starting point is a decomposition of log-perplexity that motivates smoothing as a collection of distribution-estimation problems under Kullback-Leibler (KL) loss. We then show that, under a Lipschitz-logit model for embedding-based language generation, proximity of context embeddings implies proximity of the corresponding next-word distributions in KL divergence. Combining these observations, we formulate semantic smoothing as distribution estimation in KL loss with KL-proximity side information. For $n$ samples on a $d$-symbol alphabet with a side-information distribution at KL distance $\Delta$, we give an interpolation estimator with worst-case KL risk $O(\min\{\Delta,d/n\})$, and prove a matching-order lower bound for uniform side information. We extend the estimator to multiple and empirically estimated synonymous distributions. Experiments on synthetic Markov data and WikiText-103 bigram models using Word2Vec, GloVe, and GPT-2 embeddings show that semantic smoothing consistently reduces test perplexity when applied to add-constant and Kneser-Ney estimates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes semantic smoothing for language models, using context embeddings to share statistical strength across semantically similar contexts. It begins with a decomposition of log-perplexity that frames smoothing as a collection of KL-distribution estimation tasks. Under a Lipschitz-logit model, it proves that proximity of context embeddings implies proximity of the corresponding next-word distributions in KL divergence. This yields an interpolation estimator achieving worst-case KL risk O(min{Δ, d/n}) with a matching lower bound under uniform side information; the estimator is extended to multiple and empirically estimated synonymous distributions. Experiments on synthetic Markov chains and WikiText-103 bigram models using Word2Vec, GloVe, and GPT-2 embeddings show consistent perplexity reductions relative to add-constant and Kneser-Ney baselines.
Significance. If the Lipschitz-logit model holds with moderate constants on the embeddings actually used, the work supplies a theoretically grounded smoothing technique whose risk bound is both non-asymptotic and order-optimal. The clean derivation of the interpolation estimator from the side-information model, together with the matching lower bound, constitutes a genuine contribution to distribution estimation under KL loss. The empirical consistency on bigram data is encouraging, though the assumption's realism for modern embeddings remains the key open link.
major comments (2)
- The Lipschitz-logit model (invoked to guarantee that embedding proximity translates into KL-proximity of next-word distributions) is load-bearing for both the O(min{Δ, d/n}) risk bound and the headline claim. The manuscript states the model but supplies neither a derivation of its plausibility nor any diagnostic (e.g., empirical Lipschitz-constant estimates or sensitivity plots) on the Word2Vec, GloVe, or GPT-2 embeddings actually tested. Without such verification the worst-case guarantee risks becoming vacuous in high-dimensional regimes.
- The empirical section restricts evaluation to bigram models on WikiText-103. While the results are consistent with the theory, this choice leaves open whether the interpolation estimator scales to longer contexts and full-scale language models where the embedding-to-distribution map is more complex and the effective alphabet size is larger.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. We address the two major comments point by point below, indicating the revisions we will make.
read point-by-point responses
-
Referee: The Lipschitz-logit model (invoked to guarantee that embedding proximity translates into KL-proximity of next-word distributions) is load-bearing for both the O(min{Δ, d/n}) risk bound and the headline claim. The manuscript states the model but supplies neither a derivation of its plausibility nor any diagnostic (e.g., empirical Lipschitz-constant estimates or sensitivity plots) on the Word2Vec, GloVe, or GPT-2 embeddings actually tested. Without such verification the worst-case guarantee risks becoming vacuous in high-dimensional regimes.
Authors: We agree that the Lipschitz-logit model is central to the theoretical claims and that the original manuscript provides limited justification for it. The model is presented as a modeling assumption that formalizes the intuition that semantically close contexts induce similar next-word distributions, but we did not derive its plausibility from first principles or supply empirical diagnostics on the specific embeddings. In the revised version we will add a dedicated subsection that (i) motivates the assumption via linguistic arguments and existing results on context similarity, and (ii) includes diagnostic plots that estimate effective Lipschitz constants on subsamples of the Word2Vec, GloVe, and GPT-2 embeddings used in the experiments, together with a sensitivity analysis showing how the risk bound behaves under moderate violations of the constant. revision: yes
-
Referee: The empirical section restricts evaluation to bigram models on WikiText-103. While the results are consistent with the theory, this choice leaves open whether the interpolation estimator scales to longer contexts and full-scale language models where the embedding-to-distribution map is more complex and the effective alphabet size is larger.
Authors: The restriction to bigram models was chosen to create a controlled setting in which the theoretical risk bound can be directly compared with empirical perplexity reductions and where the alphabet size remains tractable. The underlying decomposition of log-perplexity and the side-information model are stated for arbitrary contexts, so the theory itself does not depend on context length. Nevertheless, we acknowledge that moving to longer contexts and full-scale models introduces practical difficulties (larger effective alphabets, more complex embedding-to-distribution maps, and increased computational cost). In the revision we will expand the discussion section to explicitly address these scalability issues, outline possible adaptations (e.g., hierarchical or approximate nearest-neighbor search over embeddings), and note the current experiments as a necessary first validation step. We will also add a short paragraph on planned extensions to trigram and longer-context settings. revision: partial
Circularity Check
No circularity: derivation rests on explicit model assumption plus standard KL estimation bounds
full rationale
The paper states the Lipschitz-logit model as an assumption that converts embedding proximity into a KL-proximity side-information parameter Δ. The interpolation estimator and its O(min{Δ, d/n}) worst-case risk bound (plus matching lower bound) are then obtained from classical distribution-estimation arguments under KL loss; neither the estimator nor the bound is obtained by fitting a parameter to the same data later used for evaluation. No self-citations appear in the derivation chain, no quantity is renamed as a prediction after being fitted, and the empirical tests on synthetic Markov chains and WikiText-103 are independent of the theoretical steps. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Lipschitz-logit model: proximity of context embeddings implies proximity of next-word distributions in KL divergence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
under a Lipschitz-logit model ... proximity of context embeddings implies proximity of the corresponding next-word distributions in KL divergence ... interpolation estimator with worst-case KL risk O(min{Δ,d/n})
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
log-perplexity ... decomposes into ... weighted sum of Kullback-Leibler (KL) divergences
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
An empirical study of smoothing techniques for language modeling,
S. F. Chen and J. Goodman, “An empirical study of smoothing techniques for language modeling,” in34th Annual Meeting of the Association for Computational Linguistics. Santa Cruz, California, USA: Association for Computational Linguistics, Jun. 1996, pp. 310–318. [Online]. Available: https://aclanthology.org/P96-1041/
work page 1996
-
[2]
Note on the general case of the Bayes-Laplace formula for inductive or a posteriori probabilities,
G. J. Lidstone, “Note on the general case of the Bayes-Laplace formula for inductive or a posteriori probabilities,”Transactions of the Faculty of Actuaries, vol. 8, pp. 182–192, 1920
work page 1920
-
[3]
S. M. Katz, “Estimation of probabilities from sparse data for the language model component of a speech recognizer,”IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 35, no. 3, pp. 400– 401, March 1987
work page 1987
-
[4]
Interpolated estimation of Markov source parameters from sparse data,
F. Jelinek and R. L. Mercer, “Interpolated estimation of Markov source parameters from sparse data,” inProceedings of the Workshop on Pattern Recognition in Practice. Amsterdam, The Netherlands: North-Holland, May 1980
work page 1980
-
[5]
Improved backing-off for m-gram language modeling,
R. Kneser and H. Ney, “Improved backing-off for m-gram language modeling,” inProceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), vol. 1, 1995, pp. 181–184
work page 1995
-
[6]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. u. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdvances in Neural Information Processing Systems, I. Guyon, U. V . Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, Eds., vol. 30. Curran Associates, Inc., 2017
work page 2017
-
[7]
Efficient Estimation of Word Representations in Vector Space
T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient estimation of word representations in vector space,” 2013. [Online]. Available: https://arxiv.org/abs/1301.3781
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[8]
Distributed representations of words and phrases and their compositionality,
T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, and J. Dean, “Distributed representations of words and phrases and their compositionality,” inAdvances in Neural Information Processing Systems, C. Burges, L. Bottou, M. Welling, Z. Ghahramani, and K. Weinberger, Eds., vol. 26. Curran Associates, Inc.,
-
[9]
[Online]. Available: https://proceedings.neurips.cc/paper files/ paper/2013/file/9aa42b31882ec039965f3c4923ce901b-Paper.pdf
work page 2013
-
[10]
Improving language understanding by generative pre-training,
A. Radford, K. Narasimhan, T. Salimans, and I. Sutskever, “Improving language understanding by generative pre-training,”OpenAI,
-
[11]
[Online]. Available: https://cdn.openai.com/research-covers/ language-unsupervised/language understanding paper.pdf
-
[12]
Towards competitive n-gram smoothing,
M. Falahatgar, M. Ohannessian, A. Orlitsky, and V . Pichapati, “Towards competitive n-gram smoothing,” inInternational Conference on Artifi- cial Intelligence and Statistics. PMLR, 2020, pp. 4206–4215
work page 2020
-
[13]
The role ofn-gram smoothing in the age of neural networks,
L. Malagutti, A. Buinovskij, A. Svete, C. Meister, A. Amini, and R. Cot- terell, “The role ofn-gram smoothing in the age of neural networks,” in Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Mexico City, Mexico: Association for Computational Linguistics, 2024...
work page 2024
-
[14]
Generalization through memorization: Nearest neighbor language mod- els,
U. Khandelwal, O. Levy, D. Jurafsky, L. Zettlemoyer, and M. Lewis, “Generalization through memorization: Nearest neighbor language mod- els,” inInternational Conference on Learning Representations, 2020
work page 2020
-
[15]
Why do nearest neighbor language models work?
F. F. Xu, U. Alon, and G. Neubig, “Why do nearest neighbor language models work?” inProceedings of the 40th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol
- [16]
-
[17]
Distribution estimation with side information,
H. Balasundaram and A. Thangaraj, “Distribution estimation with side information,” 2026. [Online]. Available: https://arxiv.org/abs/2601.08535
-
[18]
Asymptotics of language model alignment,
J. Q. Yang, S. Salamatian, Z. Sun, A. T. Suresh, and A. Beirami, “Asymptotics of language model alignment,” in2024 IEEE International Symposium on Information Theory (ISIT), 2024, pp. 2027–2032
work page 2024
-
[19]
GloVe: Global vectors for word representation,
J. Pennington, R. Socher, and C. Manning, “GloVe: Global vectors for word representation,” inProceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), A. Moschitti, B. Pang, and W. Daelemans, Eds. Doha, Qatar: Association for Computational Linguistics, Oct. 2014, pp. 1532–1543. [Online]. Available: https://aclantholog...
work page 2014
-
[20]
Admissibility properties or Gilbert’s encoding for unknown source probabilities (corresp.),
T. Cover, “Admissibility properties or Gilbert’s encoding for unknown source probabilities (corresp.),”IEEE Transactions on Information The- ory, vol. 18, no. 1, pp. 216–217, 1972
work page 1972
-
[21]
The performance of universal encod- ing,
R. Krichevsky and V . Trofimov, “The performance of universal encod- ing,”IEEE Transactions on Information Theory, vol. 27, no. 2, pp. 199– 207, 1981
work page 1981
-
[22]
The Mixture Approach To Universal Model Selection,
O. Catoni, “The Mixture Approach To Universal Model Selection,” Tech. Rep., 1997. [Online]. Available: https://cds.cern.ch/record/461892
work page 1997
-
[23]
How to achieve minimax expected kullback-leibler distance from an unknown finite dis- tribution,
D. Braess, J. Forster, T. Sauer, and H. U. Simon, “How to achieve minimax expected kullback-leibler distance from an unknown finite dis- tribution,” inAlgorithmic Learning Theory, N. Cesa-Bianchi, M. Numao, and R. Reischuk, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 2002, pp. 380–394
work page 2002
-
[24]
Variational minimax estimation of discrete distributions under kl loss,
L. Paninski, “Variational minimax estimation of discrete distributions under kl loss,” inAdvances in Neural Information Processing Systems, L. Saul, Y . Weiss, and L. Bottou, Eds., vol. 17. MIT Press, 2004
work page 2004
-
[25]
Bernstein polynomials and learning theory,
D. Braess and T. Sauer, “Bernstein polynomials and learning theory,” Journal of Approximation Theory, vol. 128, no. 2, pp. 187–206, 2004. [Online]. Available: https://www.sciencedirect.com/science/article/pii/ S0021904504000723
work page 2004
-
[26]
Pointer Sentinel Mixture Models
S. Merity, C. Xiong, J. Bradbury, and R. Socher, “Pointer sentinel mixture models,”arXiv preprint arXiv:1609.07843, 2016. [Online]. Available: https://arxiv.org/abs/1609.07843
work page internal anchor Pith review arXiv 2016
-
[27]
Datasets: A community library for natural language processing,
Q. Lhoest, A. Villanova del Moral, Y . Jerniteet al., “Datasets: A community library for natural language processing,” inProceedings of EMNLP: System Demonstrations, 2021, pp. 175–184. [Online]. Available: https://aclanthology.org/2021.emnlp-demo.21/
work page 2021
-
[28]
Chebyshev polynomials, moment matching, and optimal estimation of the unseen,
Y . Wu and P. Yang, “Chebyshev polynomials, moment matching, and optimal estimation of the unseen,” 2015
work page 2015
-
[29]
T. M. Cover and J. A. Thomas,Elements of Information Theory 2nd Edition. Wiley-Interscience, 2006
work page 2006
-
[30]
B. Yu,Assouad, Fano, and Le Cam. New York, NY: Springer New York, 1997, pp. 423–435
work page 1997
-
[31]
The Lipschitz constant of self-attention,
H. Kim, G. Papamakarios, and A. Mnih, “The Lipschitz constant of self-attention,” inProceedings of the 38th International Conference on Machine Learning (ICML), ser. Proceedings of Machine Learning Research, vol. 139. PMLR, 2021, pp. 5562–5571. [Online]. Available: https://proceedings.mlr.press/v139/kim21i.html
work page 2021
-
[32]
V . Castin, P. Ablin, and G. Peyr ´e, “How smooth is attention?” inProceedings of the 41st International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol
- [33]
-
[34]
Mitigating transformer overconfidence via Lipschitz regularization,
M. Ye, Y . Liu, Z. Chen, and S. Wang, “Mitigating transformer overconfidence via Lipschitz regularization,” inProceedings of the Thirty-Ninth Conference on Uncertainty in Artificial Intelligence, ser. Proceedings of Machine Learning Research, vol. 216. PMLR, 2023, pp. 2422–2432. [Online]. Available: https://proceedings.mlr.press/v216/ ye23a.html APPENDIXA...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.