Recognition: 2 theorem links
· Lean TheoremSemiparametric Efficient Test for Interpretable Distributional Treatment Effects
Pith reviewed 2026-05-11 02:20 UTC · model grok-4.3
The pith
DR-ME learns finite outcome locations to test for distributional treatment effects with semiparametric efficiency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
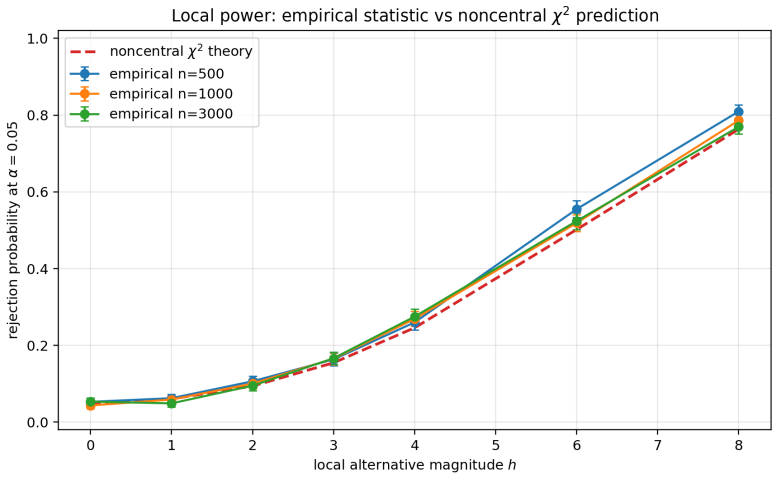
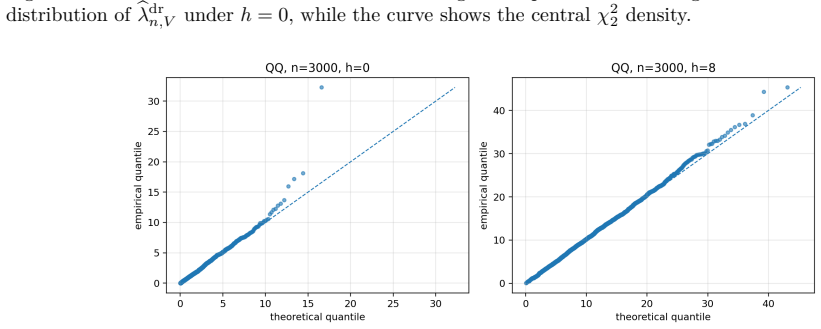
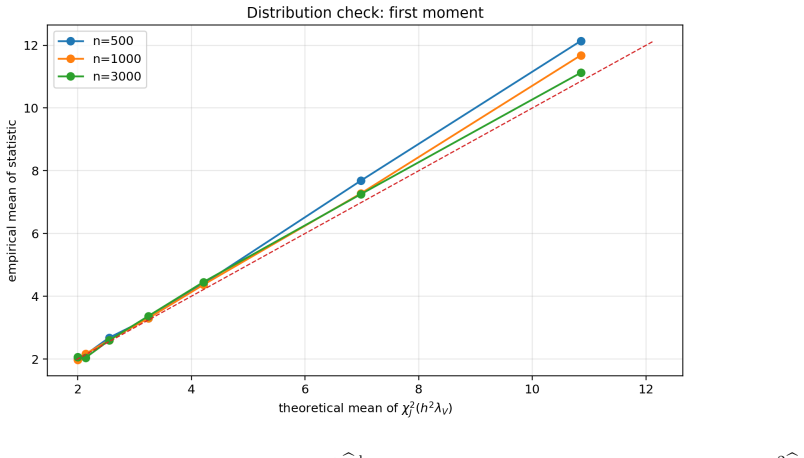
DR-ME is the first semiparametrically efficient finite-location test for interpretable distributional treatment effects. It evaluates an interventional kernel witness at learned outcome locations, using orthogonal doubly robust kernel features whose oracle form supplies the canonical gradient. For fixed locations the procedure is chi-square calibrated under the null, attains noncentral chi-square local power, and employs covariance whitening that maximizes local signal-to-noise; the same geometry supplies a principled location-learning criterion.
What carries the argument
Orthogonal doubly robust kernel features evaluated at learned finite outcome locations, with covariance whitening that optimizes local signal-to-noise.
If this is right
- The test returns explicit coordinates of causal discrepancy rather than a single global p-value.
- Local power is noncentral chi-square when the alternative is visible through the selected coordinates.
- Sample splitting keeps the procedure valid after data-driven location selection.
- The same whitening geometry can be used to compare power across different location choices.
Where Pith is reading between the lines
- The location-learning step could be replaced by a fixed grid in settings where interpretability is less important than exhaustive coverage.
- The doubly robust features might be adapted to continuous treatment or multi-arm designs without changing the efficiency argument.
- The chi-square local-power geometry suggests a natural way to rank candidate location sets before data collection.
Load-bearing premise
The derivation assumes standard causal identification conditions together with correct specification of at least one nuisance model and the validity of sample splitting.
What would settle it
A simulation or real dataset in which the true distributional discrepancy occurs only outside the learned locations yet DR-ME still rejects at the nominal level.
Figures
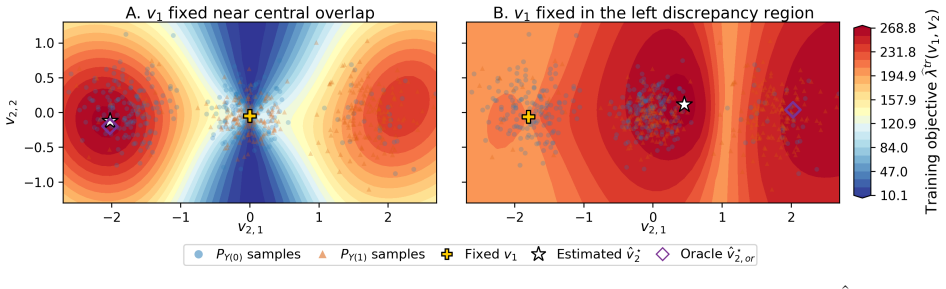
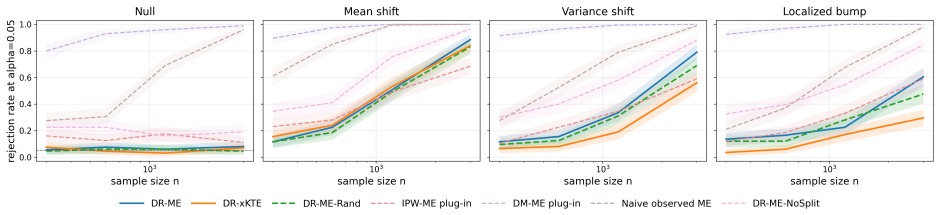

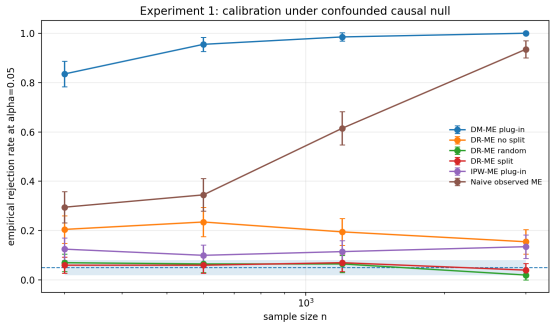
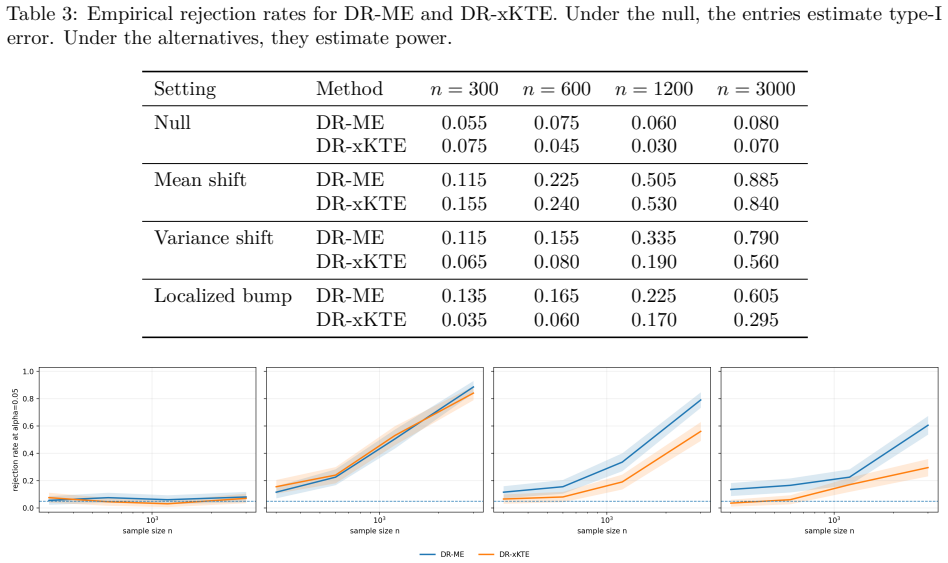

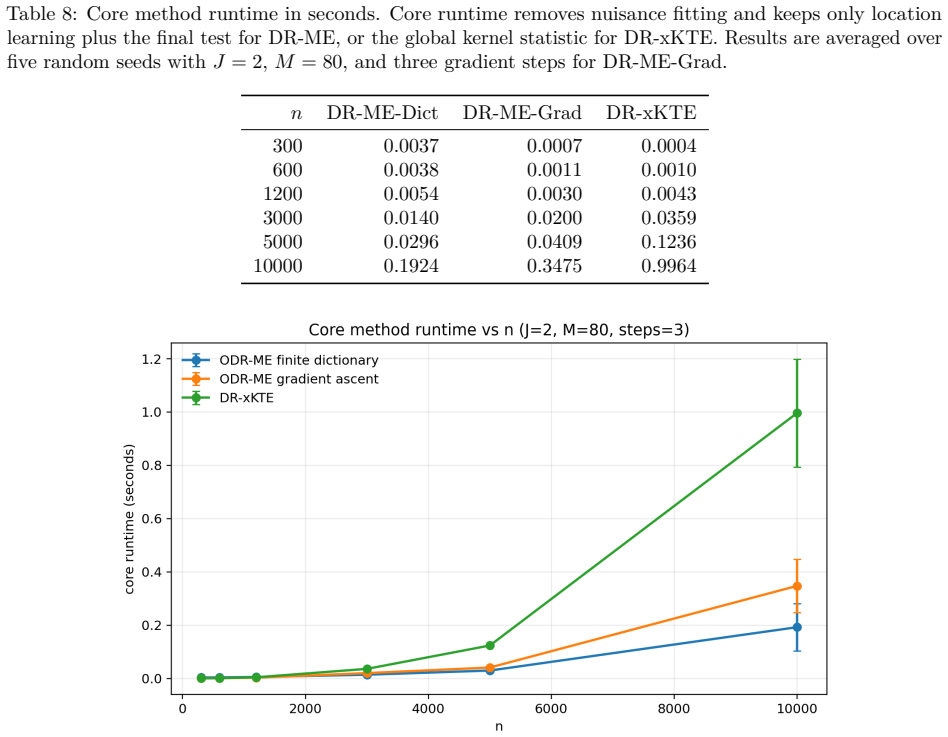

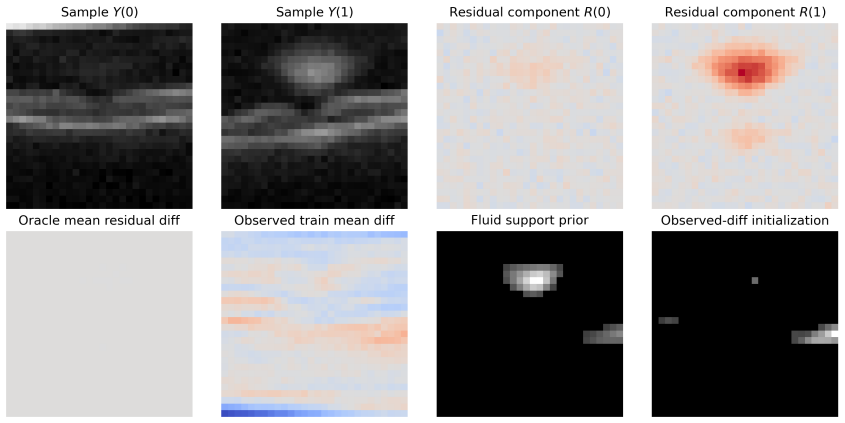
read the original abstract
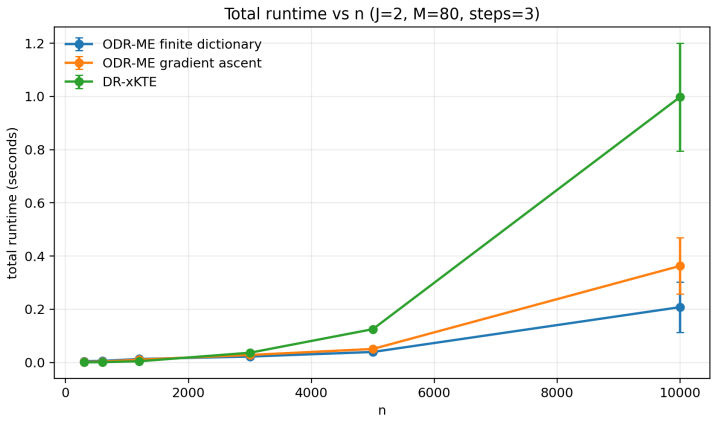
Distributional treatment effects can be invisible to means: a treatment may preserve average outcomes while changing tails, modes, dispersion, or rare-event probabilities. Kernel tests can detect discrepancies between interventional outcome laws, but global tests do not reveal where the laws differ. We propose DR-ME, to our knowledge the first semiparametrically efficient finite-location test for interpretable distributional treatment effects. DR-ME evaluates an interventional kernel witness at learned outcome locations, returning causal-discrepancy coordinates rather than only a global rejection. From observational data, we derive orthogonal doubly robust kernel features whose centered oracle form is the canonical gradient of this finite witness. For fixed locations, we characterize the local testing limit: DR-ME is chi-square calibrated under the null, has noncentral chi-square local power, and uses the covariance whitening that optimizes local signal-to-noise for discrepancies visible through the selected coordinates. This efficient local-power geometry yields a principled location-learning criterion, with sample splitting preserving post-selection validity. Experiments show near-nominal type-I error, competitive power against global doubly robust kernel tests, and interpretable learned locations that localize distributional effects in a semi-synthetic medical-imaging study.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DR-ME as the first semiparametrically efficient finite-location test for interpretable distributional treatment effects. From observational data it derives orthogonal doubly robust kernel features whose oracle form is the canonical gradient of a finite witness function evaluated at learned outcome locations. For fixed locations the method is shown to be chi-square calibrated under the null with noncentral chi-square local power; covariance whitening is used to optimize local signal-to-noise. The efficient local-power geometry induces a location-learning criterion, with sample splitting preserving post-selection validity. Experiments report near-nominal type-I error, competitive power versus global doubly robust kernel tests, and interpretable learned locations in a semi-synthetic medical-imaging study.
Significance. If the central claims hold, the contribution is significant: it supplies the first efficient, interpretable, finite-location procedure for distributional treatment effects that remains valid under standard causal identification and double-robust nuisance estimation. The derivation of the location-learning rule directly from the local-power geometry is a clean application of semiparametric theory and distinguishes the work from purely global kernel tests. The combination of double robustness, chi-square calibration, and post-selection validity via sample splitting is a practical strength for applied causal work.
major comments (2)
- [§3.2] §3.2 (canonical gradient derivation): the claim that the constructed features achieve the semiparametric efficiency bound for the finite witness relies on the features coinciding with the canonical gradient; an explicit verification that the doubly robust estimator is orthogonal to the nuisance tangent space (including the precise form of the influence function) would strengthen the efficiency result.
- [§4.3] §4.3 (local-power geometry and learned locations): the noncentrality parameter and covariance-whitening optimality are derived for fixed locations; the argument that the data-driven location criterion (induced by the same geometry) preserves the chi-square null limit and the local-power optimality after sample splitting needs a precise statement of the asymptotic expansion under the null.
minor comments (3)
- [Abstract] The abstract states 'to our knowledge the first'; a brief sentence contrasting with existing global DR kernel tests and finite-location mean tests would help readers place the novelty.
- [Experiments] In the experimental section, the semi-synthetic medical-imaging setup would benefit from an explicit statement of the nuisance estimators used (e.g., which ML methods for propensity and outcome regression) and the number of sample splits.
- [§2] Notation for the kernel witness and the finite set of locations could be introduced earlier and used consistently to ease reading of the theoretical sections.
Simulated Author's Rebuttal
We thank the referee for the thorough and constructive review. We appreciate the positive assessment of the contribution and the recommendation for minor revision. We address each major comment below.
read point-by-point responses
-
Referee: [§3.2] §3.2 (canonical gradient derivation): the claim that the constructed features achieve the semiparametric efficiency bound for the finite witness relies on the features coinciding with the canonical gradient; an explicit verification that the doubly robust estimator is orthogonal to the nuisance tangent space (including the precise form of the influence function) would strengthen the efficiency result.
Authors: We agree that an explicit verification would strengthen the efficiency result. In the revised manuscript we will add a dedicated appendix deriving the influence function of the doubly robust kernel features and verifying orthogonality to the full nuisance tangent space (including the precise form of the canonical gradient for the finite witness). revision: yes
-
Referee: [§4.3] §4.3 (local-power geometry and learned locations): the noncentrality parameter and covariance-whitening optimality are derived for fixed locations; the argument that the data-driven location criterion (induced by the same geometry) preserves the chi-square null limit and the local-power optimality after sample splitting needs a precise statement of the asymptotic expansion under the null.
Authors: We acknowledge that a precise asymptotic expansion under the null is needed to rigorously justify preservation of the chi-square limit after sample splitting. In the revision we will insert an explicit statement of the asymptotic expansion under the null (including the o_p(1) remainder terms) that confirms the chi-square calibration and the retention of local-power optimality for the data-driven locations. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper derives the orthogonal doubly robust kernel features directly as the canonical gradient of the finite witness and obtains the location-learning criterion from the local-power optimality geometry under the chi-square limit characterization. These steps follow from standard semiparametric efficiency theory and local asymptotic analysis applied to the interventional kernel witness, without reducing to a fitted input renamed as prediction or to any self-citation chain. The abstract and description invoke only external causal identification conditions and sample-splitting validity, with no self-definitional loops, ansatz smuggling, or uniqueness theorems imported from the authors' prior work. The central claim of semiparametric efficiency and interpretable finite-location testing therefore remains independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Standard causal assumptions (consistency, no unmeasured confounding, positivity) allow identification of interventional outcome distributions from observational data
- standard math Kernel mean embeddings and reproducing kernel Hilbert spaces are well-defined for the outcome space
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe derive orthogonal doubly robust kernel features whose centered oracle form is the canonical gradient of this finite witness... DR-ME is chi-square calibrated under the null, has noncentral chi-square local power...
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanabsolute_floor_iff_bare_distinguishability unclearThe efficiency statement in Theorem 3.1 is a local testing statement for the regular finite signal µV... This differs from global MMD-type tests, which target a squared RKHS discrepancy
Reference graph
Works this paper leans on
-
[1]
Heejung Bang and James M. Robins. Doubly robust estimation in missing data and causal inference models.Biometrics, 61(4):962–973, 2005. doi: 10.1111/j.1541-0420.2005.00377.x
-
[2]
Peter J. Bickel, Chris A. J. Klaassen, Ya’acov Ritov, and Jon A. Wellner.Efficient and Adaptive Estimation for Semiparametric Models. Johns Hopkins University Press, 1993
work page 1993
-
[3]
Inference on counterfactual distributions
Victor Chernozhukov, Iván Fernández-Val, and Blaise Melly. Inference on counterfactual distributions. Econometrica, 81(6):2205–2268, 2013
work page 2013
-
[4]
Victor Chernozhukov, Denis Chetverikov, Mert Demirer, Esther Duflo, Christian Hansen, Whitney Newey, and James Robins. Double/debiased machine learning for treatment and structural parameters. The Econometrics Journal, 21(1):C1–C68, 2018. doi: 10.1111/ectj.12097
-
[5]
Fast two-sample testing with analytic representations of probability measures
Kacper P Chwialkowski, Aaditya Ramdas, Dino Sejdinovic, and Arthur Gretton. Fast two-sample testing with analytic representations of probability measures. InAdvances in Neural Information Processing Systems, volume 28, 2015. 10
work page 2015
-
[6]
Jake Fawkes, Robert Hu, Robin J. Evans, and Dino Sejdinovic. Doubly robust kernel statistics for testing distributional treatment effects.Transactions on Machine Learning Research, 2024
work page 2024
-
[7]
Optimal inference after model selection, 2014
William Fithian, Dennis Sun, and Jonathan Taylor. Optimal inference after model selection, 2014
work page 2014
-
[8]
A survey of kernels for structured data.ACM SIGKDD explorations newsletter, 5(1): 49–58, 2003
Thomas Gärtner. A survey of kernels for structured data.ACM SIGKDD explorations newsletter, 5(1): 49–58, 2003
work page 2003
-
[9]
A kernel two-sample test.The Journal of Machine Learning Research, 13(1):723–773, 2012
Arthur Gretton, Karsten M Borgwardt, Malte J Rasch, Bernhard Schölkopf, and Alexander Smola. A kernel two-sample test.The Journal of Machine Learning Research, 13(1):723–773, 2012
work page 2012
-
[10]
Jinyong Hahn. On the role of the propensity score in efficient semiparametric estimation of average treatment effects.Econometrica, 66(2):315–331, 1998. doi: 10.2307/2998560
-
[11]
Miguel A. Hernán and James M. Robins.Causal Inference: What If. Chapman & Hall/CRC, 2020
work page 2020
-
[12]
Springer, Berlin, 3 edition, 1996
Reiner Horst and Hoang Tuy.Global Optimization: Deterministic Approaches. Springer, Berlin, 3 edition, 1996
work page 1996
-
[13]
The Likelihood Test of Independence in Contingency Tables,
Harold Hotelling. The generalization of student’s ratio.The Annals of Mathematical Statistics, 2(3): 360–378, 1931. doi: 10.1214/aoms/1177732979
-
[14]
Inference on function-valued parameters using a restricted score test, 2021
Aaron Hudson, Marco Carone, and Ali Shojaie. Inference on function-valued parameters using a restricted score test, 2021
work page 2021
-
[15]
Guido W. Imbens and Donald B. Rubin.Causal Inference for Statistics, Social, and Biomedical Sciences: An Introduction. Cambridge University Press, 2015. doi: 10.1017/CBO9781139025751
-
[16]
Chwialkowski, and Arthur Gretton
Wittawat Jitkrittum, Zoltán Szabó, Kacper P. Chwialkowski, and Arthur Gretton. Interpretable distribution features with maximum testing power. InAdvances in Neural Information Processing Systems 29, pages 181–189, 2016
work page 2016
-
[17]
Edward H. Kennedy. Semiparametric doubly robust targeted double machine learning: A review, 2022
work page 2022
-
[18]
Kermany, Michael Goldbaum, Wenjia Cai, Carolina C
Daniel S. Kermany, Michael Goldbaum, Wenjia Cai, Carolina C. S. Valentim, Huiying Liang, Sally L. Baxter, Alex McKeown, Ge Yang, Xiaokang Wu, Fangbing Yan, Justin Dong, Made K. Prasadha, Jacqueline Pei, Magdalene Y. L. Ting, Jie Zhu, Christina Li, Sierra Hewett, Jason Dong, Ian Ziyar, Alexander Shi, Runze Zhang, Lianghong Zheng, Rui Hou, William Shi, Xiao...
work page 2018
-
[19]
Arun Kumar Kuchibhotla, John E. Kolassa, and Todd A. Kuffner. Post-selection inference.Annual Review of Statistics and Its Application, 9:505–527, 2022. doi: 10.1146/annurev-statistics-100421-044639
-
[20]
Lucien M. Le Cam and Grace Lo Yang.Asymptotics in Statistics: Some Basic Concepts. Springer Series in Statistics. Springer, 2 edition, 2000. doi: 10.1007/978-1-4612-1166-2
-
[21]
Alex Luedtke and Incheoul Chung. One-step estimation of differentiable hilbert-valued parameters.The Annals of Statistics, 52(4):1534–1563, 2024
work page 2024
-
[22]
Luedtke, Marco Carone, and Mark J
Alexander R. Luedtke, Marco Carone, and Mark J. van der Laan. An omnibus non-parametric test of equality in distribution for unknown functions.Journal of the Royal Statistical Society: Series B, 81(1): 75–99, 2019. 11
work page 2019
-
[23]
An efficient doubly-robust test for the kernel treatment effect
Diego Martinez Taboada, Aaditya Ramdas, and Edward Kennedy. An efficient doubly-robust test for the kernel treatment effect. InAdvances in Neural Information Processing Systems, volume 36, pages 59924–59952, 2023
work page 2023
-
[24]
Counter- factual mean embeddings.Journal of Machine Learning Research, 22(162):1–71, 2021
Krikamol Muandet, Motonobu Kanagawa, Sorawit Saengkyongam, and Sanparith Marukatat. Counter- factual mean embeddings.Journal of Machine Learning Research, 22(162):1–71, 2021
work page 2021
-
[25]
Jerzy Neyman and Egon S. Pearson. On the problem of the most efficient tests of statistical hypotheses. Philosophical Transactions of the Royal Society of London. Series A, Containing Papers of a Mathematical or Physical Character, 231(694–706):289–337, 1933
work page 1933
-
[26]
Jorge Nocedal and Stephen J. Wright.Numerical Optimization. Springer, New York, 2 edition, 2006
work page 2006
-
[27]
S. A. Piyavskii. An algorithm for finding the absolute extremum of a function.USSR Computational Mathematics and Mathematical Physics, 12(4):57–67, 1972
work page 1972
-
[28]
Robins, Andrea Rotnitzky, and Lue Ping Zhao
James M. Robins, Andrea Rotnitzky, and Lue Ping Zhao. Estimation of regression coefficients when some regressors are not always observed.Journal of the American Statistical Association, 89(427):846–866,
-
[29]
doi: 10.1080/01621459.1994.10476818
-
[30]
Paul R. Rosenbaum and Donald B. Rubin. The central role of the propensity score in observational studies for causal effects.Biometrika, 70(1):41–55, 1983. doi: 10.1093/biomet/70.1.41
-
[31]
Christoph Rothe. Nonparametric estimation of distributional policy effects.Journal of Econometrics, 155(1):56–70, 2010
work page 2010
-
[32]
Donald B. Rubin. Estimating causal effects of treatments in randomized and nonrandomized studies. Journal of Educational Psychology, 66(5):688–701, 1974. doi: 10.1037/h0037350
-
[33]
MIT Press, Cambridge, MA, 2004
Bernhard Schölkopf, Koji Tsuda, and Jean-Philippe Vert, editors.Kernel Methods in Computational Biology. MIT Press, Cambridge, MA, 2004. ISBN 9780262195096
work page 2004
-
[34]
Bruno O. Shubert. A sequential method seeking the global maximum of a function.SIAM Journal on Numerical Analysis, 9(3):379–388, 1972
work page 1972
-
[35]
A hilbert space embedding for distributions
Alex Smola, Arthur Gretton, Le Song, and Bernhard Schölkopf. A hilbert space embedding for distributions. InInternational conference on algorithmic learning theory, pages 13–31. Springer, 2007
work page 2007
-
[36]
Bharath K Sriperumbudur, Kenji Fukumizu, and Gert RG Lanckriet. Universality, characteristic kernels and rkhs embedding of measures.Journal of Machine Learning Research, 12(7), 2011
work page 2011
-
[37]
A. W. van der Vaart.Asymptotic Statistics, volume 3 ofCambridge Series in Statistical and Probabilistic Mathematics. Cambridge University Press, 1998. doi: 10.1017/CBO9780511802256
-
[38]
Classification of biological sequences with kernel methods
Jean-Philippe Vert. Classification of biological sequences with kernel methods. In Yasubumi Sakakibara, Satoshi Kobayashi, Kengo Sato, Tetsuro Nishino, and Etsuji Tomita, editors,Grammatical Inference: Algorithms and Applications, volume 4201 ofLecture Notes in Computer Science, pages 7–18, Berlin, Heidelberg, 2006. Springer. doi: 10.1007/11872436_2
-
[39]
Jean-Philippe Vert, Robert Thurman, and William S. Noble. Kernels for gene regulatory regions. In Yair Weiss, Bernhard Schölkopf, and John Platt, editors,Advances in Neural Information Processing Systems 18, pages 1401–1408, Cambridge, MA, 2005. MIT Press
work page 2005
-
[40]
Medmnist v2-a large-scale lightweight benchmark for 2d and 3d biomedical image classification
Jiancheng Yang, Rui Shi, Donglai Wei, Zequan Liu, Lin Zhao, Bilian Ke, Hanspeter Pfister, and Bingbing Ni. Medmnist v2-a large-scale lightweight benchmark for 2d and 3d biomedical image classification. Scientific Data, 10(1):41, 2023. 12
work page 2023
-
[41]
Doubly-robust estimation of counterfactual policy mean embeddings
Houssam Zenati, Bariscan Bozkurt, and Arthur Gretton. Doubly-robust estimation of counterfactual policy mean embeddings. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URLhttps://openreview.net/forum?id=0GDlX9JFf2
work page 2025
-
[42]
Kernel Treatment Effects with Adaptively Collected Data
Houssam Zenati, Bariscan Bozkurt, and Arthur Gretton. Kernel treatment effects with adaptively collected data, 2025. URLhttps://arxiv.org/abs/2510.10245. 13 Appendix Appendix organization.Appendix A collects notation and the full assumptions used in the main text. Appendix B gives a compact review of the local asymptotic tools used for the testing-efficie...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.