Recognition: 2 theorem links
· Lean TheoremZero-Shot Imagined Speech Decoding via Imagined-to-Listened MEG Mapping
Pith reviewed 2026-05-11 01:51 UTC · model grok-4.3
The pith
A mapping learned from paired listened and imagined MEG recordings lets a decoder trained only on listening data identify imagined words above chance on held-out subjects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Paired listened and imagined MEG recordings from trained musicians are used to train mapping models that convert imagined responses into predicted listened responses; a contrastive decoder trained exclusively on listened responses then identifies the imagined words when the mapped signals are supplied, yielding above-chance rank accuracy on held-out subjects.
What carries the argument
The three-stage pipeline of imagined-to-listened mapping models followed by a listened-only contrastive word decoder that operates on the mapped signals.
If this is right
- Imagined speech becomes decodable without collecting large imagined-only datasets for each new user.
- Decoding performance improves as the amount of paired listened-imagined training data grows.
- The approach supports held-out subject evaluation, a necessary condition for practical brain-computer interfaces.
- Stimulus identity is carried through the mapping even when temporal alignment relies on musician participants.
Where Pith is reading between the lines
- If the mapping generalizes beyond musicians, the same pipeline could be applied to non-musician users once alignment techniques improve.
- Real-time BCI deployment would require the mapping and decoder to run with low latency on streaming MEG data.
- Similar imagined-to-listened mappings might be learned for EEG or fMRI if paired recordings can be obtained.
- Extending the contrastive embeddings to sentence-level or continuous speech could broaden the method to more natural imagined language.
Load-bearing premise
The mapping models preserve stimulus-specific information when transferred from training musicians to held-out subjects.
What would settle it
Rank accuracy on imagined-word identification drops to chance level when the same mapping and decoder are tested on a new group of held-out subjects using stimuli not seen during mapping training.
Figures



read the original abstract
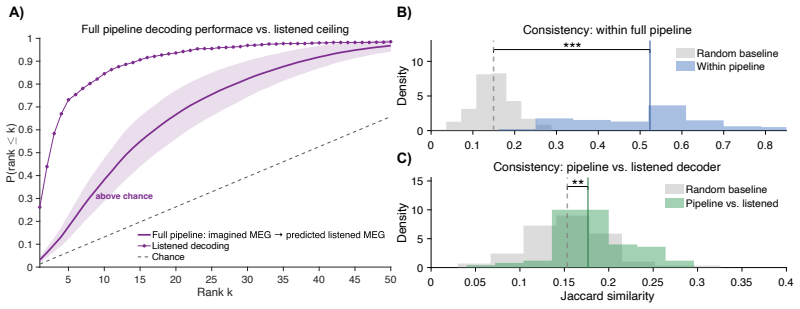
Decoding imagined speech from non-invasive brain recordings is challenging because imagined datasets are scarce and difficult to align temporally across subjects and sessions In this work, we propose a new approach to the decoding of imagined speech that leverages the richer and more reliably labeled recordings during listening to speech. We collected paired listened and imagined MEG recordings to rhythmic melodic and spoken stimuli from trained musicians. Using trained musicians helped improve temporal alignment across conditions. We then developed a three-stage decoding pipeline that revealed consistent and meaningful relationships between neural activity evoked by imagining and listening to the same stimuli. First, we trained six linear and neural models to map imagined MEG responses to listened responses. We evaluated these models against a null baseline from unseen subjects to validate that the predicted-listening responses preserve stimulus-specific information. In the second stage, we trained a contrastive word decoder exclusively on the listened MEG responses, and evaluated it using four embedding strategies including semantic, acoustic, and phonetic representations. In the third stage, we process the imagined MEG responses from held-out subjects through the mapping pipeline to compute the corresponding listening responses that are then decoded by the listened decoder. Using rank-based analysis, we show that the imagined words are decodable significantly above chance. We shall report here the results of a proof-of-concept implementation to decode imagined speech, where all evaluations are performed on held-out subjects. We also demonstrate that performance improves with training data size, suggesting that this approach is scalable and can directly be made applicable to realistic brain-computer interface scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a three-stage pipeline for zero-shot decoding of imagined speech from MEG: (1) train linear and neural models to map imagined MEG responses to listened MEG responses using paired data from trained musicians, (2) train a contrastive word decoder exclusively on listened MEG responses with semantic/acoustic/phonetic embeddings, and (3) apply the mapping to imagined MEG from held-out subjects and decode the resulting listened-like responses. It reports that rank-based analysis shows imagined words are decodable significantly above chance on held-out subjects, with performance improving as training data size increases.
Significance. If the cross-subject mapping successfully preserves stimulus-specific information, the approach could mitigate the scarcity of imagined-speech datasets by leveraging more abundant and reliably labeled listened-speech recordings, offering a scalable route toward practical non-invasive BCIs. The use of musicians to improve temporal alignment and the empirical demonstration of data-size scaling are constructive elements.
major comments (3)
- [Abstract and mapping-evaluation section] The central claim that the imagined-to-listened mapping preserves stimulus-specific information on held-out subjects rests on evaluation against a 'null baseline from unseen subjects' (abstract and mapping-evaluation paragraph). The construction of this baseline is not specified (e.g., stimulus permutation within vs. across subjects, session matching, or whether subject identity is explicitly controlled). Because MEG signals contain strong subject-specific components due to head geometry and neural variability, an inadequately constructed null could allow above-chance rank accuracy to arise from residual subject correlations rather than successful stimulus transfer; this directly undermines the validity of the third-stage held-out evaluation.
- [Abstract and results paragraphs] The abstract asserts that 'imagined words are decodable significantly above chance' via rank-based analysis on held-out subjects and that performance 'improves with training data size,' yet no quantitative values (rank accuracies, number of subjects/stimuli, error bars, or statistical-test details such as p-values or exact permutation procedures) are supplied. These numbers are load-bearing for assessing effect size, reliability, and the scalability claim.
- [Methods and pipeline-description sections] The six mapping models (linear and neural) and the contrastive decoder are described only at a high level; key implementation details—exact architectures, loss functions, training/validation splits, number of paired trials per subject, and how temporal alignment is enforced—are missing. Without these, reproducibility of the reported cross-subject generalization cannot be evaluated.
minor comments (2)
- [Abstract] The phrasing 'We shall report here the results of a proof-of-concept implementation' in the abstract is awkward and should be replaced with a direct statement of the reported findings.
- [Throughout] Ensure all embedding strategies (semantic, acoustic, phonetic) are referenced to standard methods or explicitly defined, and that figure captions for any rank-accuracy plots include exact chance levels and subject counts.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and will revise the manuscript to improve clarity, provide missing details, and strengthen the presentation of results.
read point-by-point responses
-
Referee: [Abstract and mapping-evaluation section] The central claim that the imagined-to-listened mapping preserves stimulus-specific information on held-out subjects rests on evaluation against a 'null baseline from unseen subjects' (abstract and mapping-evaluation paragraph). The construction of this baseline is not specified (e.g., stimulus permutation within vs. across subjects, session matching, or whether subject identity is explicitly controlled). Because MEG signals contain strong subject-specific components due to head geometry and neural variability, an inadequately constructed null could allow above-chance rank accuracy to arise from residual subject correlations rather than successful stimulus transfer; this directly undermines the validity of the third-stage held-out evaluation.
Authors: We agree that the null baseline construction requires explicit description to address potential subject-specific confounds in MEG. In the revised manuscript we will expand the mapping-evaluation section (and update the abstract) to fully specify how the baseline is generated from unseen subjects, including the exact permutation or matching procedure used to isolate stimulus-specific transfer from residual subject correlations. revision: yes
-
Referee: [Abstract and results paragraphs] The abstract asserts that 'imagined words are decodable significantly above chance' via rank-based analysis on held-out subjects and that performance 'improves with training data size,' yet no quantitative values (rank accuracies, number of subjects/stimuli, error bars, or statistical-test details such as p-values or exact permutation procedures) are supplied. These numbers are load-bearing for assessing effect size, reliability, and the scalability claim.
Authors: The referee correctly notes the absence of quantitative metrics. We will revise the abstract and results sections to report the specific rank accuracies (with means, standard deviations, and error bars across subjects), the number of subjects and stimuli, and full statistical details including p-values and the exact permutation test procedure. This will allow proper evaluation of effect sizes and the data-scaling observation. revision: yes
-
Referee: [Methods and pipeline-description sections] The six mapping models (linear and neural) and the contrastive decoder are described only at a high level; key implementation details—exact architectures, loss functions, training/validation splits, number of paired trials per subject, and how temporal alignment is enforced—are missing. Without these, reproducibility of the reported cross-subject generalization cannot be evaluated.
Authors: We acknowledge that the current draft provides only high-level descriptions. In the revised Methods section we will supply all requested implementation details: exact model architectures, loss functions, training/validation split ratios, the number of paired trials per subject, and the precise procedure for temporal alignment (including the role of rhythmic stimuli and musician training). These additions will enable full reproducibility. revision: yes
Circularity Check
No significant circularity in empirical mapping-decoding pipeline
full rationale
The paper describes a purely empirical three-stage ML pipeline: (1) train mapping models on paired listened/imagined MEG from musicians, (2) train contrastive decoder only on listened MEG, (3) apply mapping zero-shot to held-out subjects' imagined MEG and decode. No equations, derivations, or self-referential definitions appear in the text. The central claim (above-chance rank accuracy on held-out subjects) rests on cross-subject generalization and null-baseline comparison rather than any reduction to fitted inputs by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked. This matches the default expectation for data-driven work and the reader's assessment of score 2.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Paired listened and imagined MEG recordings from trained musicians can be temporally aligned effectively to train mapping models.
- domain assumption Linear and neural models can learn a mapping from imagined to listened MEG responses that preserves stimulus-specific information.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
three-stage decoding pipeline... trained six linear and neural models to map imagined MEG responses to listened responses... contrastive word decoder exclusively on the listened MEG responses... process the imagined MEG responses from held-out subjects through the mapping pipeline
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Using rank-based analysis, we show that the imagined words are decodable significantly above chance
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Guilhem Marion, Giovanni M. Di Liberto, Shihab A. Shamma, et al. The music of silence: Part i: Responses to musical imagery encode melodic expectations.Journal of Neuroscience, 41(35):7435–7448, 2021
work page 2021
-
[2]
Kosslyn, Giorgio Ganis, and William L
Stephen M. Kosslyn, Giorgio Ganis, and William L. Thompson. Neural foundations of imagery.Nature Reviews Neuroscience, 2(9):635–642, 2001
work page 2001
-
[3]
Anumanchipalli, Josh Chartier, and Edward F
Gopala K. Anumanchipalli, Josh Chartier, and Edward F. Chang. Speech synthesis from neural decoding of spoken sentences.Nature, 568(7753):493–498, 2019
work page 2019
-
[4]
Meg sensor selection for neural speech decoding.Journal of Neural Engineering, 17(6):066031, 2020
Debanjan Dash, Paolo Ferrari, Wei Wang, et al. Meg sensor selection for neural speech decoding.Journal of Neural Engineering, 17(6):066031, 2020
work page 2020
-
[5]
David A. Moses, Sean L. Metzger, Jessie R. Liu, Gopala K. Anumanchipalli, Joseph G. Makin, Pengfei F. Sun, Josh Chartier, Meaghan E. Dougherty, Patrick M. Liu, Grant M. Abrams, Alicia Tu-Chan, Karunesh Ganguly, and Edward F. Chang. Neuroprosthesis for decoding speech in a paralyzed person with anarthria. New England Journal of Medicine, 385(3):217–227, 2021
work page 2021
-
[6]
Francis R. Willett, Erin M. Kunz, Chaofei Fan, Donald T. Avansino, Guy H. Wilson, Eun Young Choi, Foram Kamdar, Matthew F. Glasser, Leigh R. Hochberg, Shaul Druckmann, Krishna V . Shenoy, and Jaimie M. Henderson. A high-performance speech neuroprosthesis.Nature, 620(7976):1031–1036, 2023
work page 2023
-
[7]
Iterative alignment discovery using dynamic time warping for neural signal analysis
Wei Wang et al. Iterative alignment discovery using dynamic time warping for neural signal analysis. Frontiers in Neuroscience, 18:1–15, 2024
work page 2024
-
[8]
Millán, Gerwin Schalk, Robert T
Stephanie Martin, Peter Brunner, Iñigo Iturrate, José del R. Millán, Gerwin Schalk, Robert T. Knight, and Brian N. Pasley. Word pair classification during imagined speech using direct brain recordings.Scientific Reports, 6:25803, 2016
work page 2016
- [9]
-
[10]
Daniel Lopez-Bernal, Daniel Balderas, Pedro Ponce, and Arturo Molina. A state-of-the-art review of eeg-based imagined speech decoding.Frontiers in Human Neuroscience, 16:867281, 2022
work page 2022
-
[11]
Ahmad H. Milyani and Eyad Talal Attar. Deep learning for inner speech recognition: a pilot comparative study of eegnet and a spectro-temporal transformer on bimodal eeg-fmri data.Frontiers in Human Neuroscience, 19:1668935, 2025
work page 2025
-
[12]
Yasser F. Alharbi et al. Decoding imagined speech from eeg data: A hybrid deep learning approach.Life, 14(11):1501, 2024
work page 2024
-
[13]
Richard Csáky, Mats W. J. van Es, and Mark W. Woolrich. Towards decoding inner speech from eeg and meg.bioRxiv, 2025
work page 2025
-
[14]
Vinicius Rezende Carvalho, Claudia Lainscsek, Terrence J. Sejnowski, et al. Decoding imagined speech with delay differential analysis.Frontiers in Human Neuroscience, 18:1398065, 2024
work page 2024
-
[15]
Brian N. Pasley, Stephen V . David, Nima Mesgarani, Adeen Flinker, Shihab A. Shamma, Nathan E. Crone, Robert T. Knight, and Edward F. Chang. Reconstructing speech from human auditory cortex.PLoS Biology, 10(1):e1001251, 2012
work page 2012
-
[16]
Hassan Akbari, Bahar Khalighinejad, Jose L. Herrero, Ashesh D. Mehta, and Nima Mesgarani. Towards reconstructing intelligible speech from the human auditory cortex.Scientific Reports, 9(1):874, 2019
work page 2019
-
[17]
Tong He et al. V ocalmind: A stereotactic eeg dataset for vocalized, mimed, and imagined speech in a tonal language.Scientific Data, 12:XXX, 2025
work page 2025
-
[18]
Laura Gwilliams, Jean-Rémi King, Alec Marantz, and David Poeppel. Neural dynamics of phoneme sequences reveal position-invariant code for content and order.Nature Communications, 13(1):6606, 2022
work page 2022
-
[19]
Alexandre Défossez, Charlotte Caucheteux, Jérémy Rapin, Ori Kabeli, and Jean-Rémi King. Decoding speech perception from non-invasive brain recordings.Nature Machine Intelligence, 5(10):1097–1107, 2023
work page 2023
-
[20]
Jerry Tang, Alexandre LeBel, Shailee Jain, and Alexander G. Huth. Semantic reconstruction of continuous language from non-invasive brain recordings.Nature Neuroscience, 26:858–866, 2023. 10
work page 2023
-
[21]
Rui Liu, Zhige Chen, Wenlong Pengshu, Wenlong You, Zhi-An Huang, Jibin Wu, and Kay Chen Tan. Mindmix: A multimodal foundation model for auditory perception decoding via deep neural-acoustic alignment. InInternational Conference on Learning Representations (ICLR), 2026. Poster
work page 2026
-
[22]
Miran Özdogan, Gilad Landau, Gereon Elvers, Dulhan Jayalath, Pratik Somaiya, Francesco Mantegna, Mark Woolrich, and Oiwi Parker Jones. Libribrain: Over 50 hours of within-subject meg to improve speech decoding methods at scale.arXiv preprint arXiv:2506.02098, 2025
-
[23]
Daniel Alonso-Vázquez et al. From pronounced to imagined: improving speech decoding with multi- condition eeg data.Frontiers in Neuroscience, 19:1–14, 2025
work page 2025
-
[24]
David J. M. Kraemer, C. Neil Macrae, A. E. Green, and William M. Kelley. Musical imagery: Sound of silence activates auditory cortex.Nature, 434(7030):158, 2005
work page 2005
-
[25]
Robert J. Zatorre and Andrea R. Halpern. Mental concerts: musical imagery and auditory cortex.Neuron, 47(1):9–12, 2005
work page 2005
-
[26]
Sibylle C. Herholz, Andrea R. Halpern, and Robert J. Zatorre. Neuronal correlates of perception, imagery, and memory for familiar tunes.Journal of Cognitive Neuroscience, 24(6):1382–1397, 2012
work page 2012
- [27]
-
[28]
Engemann, Daniel Strohmeier, Christian Brodbeck, Lauri Parkkonen, and Matti S
Alexandre Gramfort, Martin Luessi, Eric Larson, Denis A. Engemann, Daniel Strohmeier, Christian Brodbeck, Lauri Parkkonen, and Matti S. Hämäläinen. Mne software for processing meg and eeg data. NeuroImage, 86:446–460, 2014
work page 2014
-
[29]
Independent component analysis: Algorithms and applications.Neural Networks, 13(4-5):411–430, 2000
Aapo Hyvärinen and Erkki Oja. Independent component analysis: Algorithms and applications.Neural Networks, 13(4-5):411–430, 2000
work page 2000
-
[30]
Whisperx: Time-accurate speech transcrip- tion of long-form audio
Max Bain, Jaesung Huh, Tengda Han, and Andrew Zisserman. Whisperx: Time-accurate speech transcrip- tion of long-form audio. InProceedings of Interspeech 2023, pages 4489–4493, 2023
work page 2023
-
[31]
Robust Speech Recognition via Large-Scale Weak Supervision
Alec Radford et al. Robust speech recognition via large-scale weak supervision.arXiv preprint arXiv:2212.04356, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
wav2vec 2.0: A framework for self-supervised learning of speech representations
Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, and Michael Auli. wav2vec 2.0: A framework for self-supervised learning of speech representations. InNeurIPS, 2020
work page 2020
-
[33]
Bert: Pre-training of deep bidirec- tional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirec- tional transformers for language understanding. InNAACL, 2019
work page 2019
-
[34]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InProceedings of the 37th International Conference on Machine Learning (ICML), volume 119 ofProceedings of Machine Learning Research, pages 1597–1607. PMLR, 2020
work page 2020
-
[35]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InICLR, 2019. 11 A Imagery to listening mapping details A.1 Mapping architecture details We describe the six mapping architectures evaluated in this work. All models take an imagined MEG trial X∈R C×T as input and produce a predicted listened MEG trial ˆY∈R C×T of the same shape. All...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.