Recognition: no theorem link
LLMs Improving LLMs: Agentic Discovery for Test-Time Scaling
Pith reviewed 2026-05-13 07:04 UTC · model grok-4.3
The pith
AutoTTS automatically discovers test-time scaling strategies that improve LLM accuracy-cost tradeoffs over hand-designed baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Test-time scaling is recast as controller synthesis over pre-collected reasoning trajectories and probe signals. The controller, parameterized by beta values, chooses at each step whether to branch, continue, probe, prune, or stop. Cheap offline evaluation of candidate controllers, augmented by fine-grained execution traces, lets an agentic search locate programs whose accuracy-cost curves dominate those of hand-crafted baselines. The discovered controllers generalize to held-out benchmarks and different model scales.
What carries the argument
A beta-parameterized controller that operates over pre-collected reasoning trajectories, using probe signals to decide branching, continuation, probing, pruning, or stopping, and that is scored without live LLM calls.
If this is right
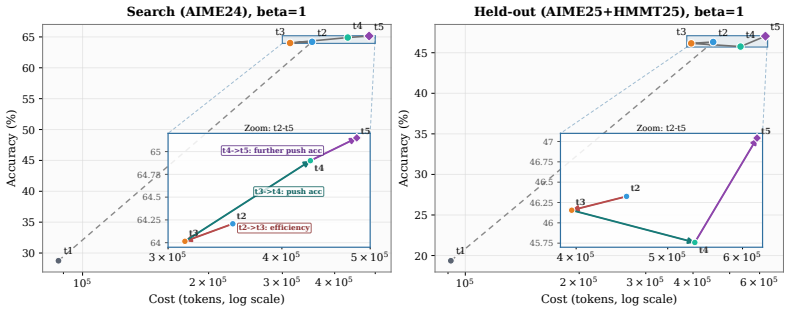
- The discovered strategies achieve better accuracy-cost tradeoffs than strong manually designed baselines on mathematical reasoning benchmarks.
- The strategies generalize to held-out benchmarks and to models of different scales.
- The full discovery process finishes in 160 minutes at a total cost of $39.9.
- The same environment construction makes the search space tractable enough for repeated agentic discovery runs.
Where Pith is reading between the lines
- Treating test-time computation allocation as a discoverable program rather than a fixed heuristic opens a route to systematic exploration of inference-time budgets across many tasks.
- The cheap trajectory-based evaluation loop could be reused to optimize other dynamic inference procedures that currently rely on hand-tuned rules.
- If the set of collected trajectories is broadened, the same search may surface controllers that handle more complex or multi-step reasoning patterns than those tested here.
Load-bearing premise
Evaluations on pre-collected reasoning trajectories and probe signals will accurately predict how the discovered controllers perform when they are later executed with actual live calls to the language model.
What would settle it
Deploy the discovered controllers on live calls to the target LLM, measure the resulting accuracy versus total tokens used, and check whether the Pareto frontier lies above the frontier of the strongest manual baselines on the same mathematical reasoning benchmarks.
Figures



read the original abstract
Test-time scaling (TTS) has become an effective approach for improving large language model performance by allocating additional computation during inference. However, existing TTS strategies are largely hand-crafted: researchers manually design reasoning patterns and tune heuristics by intuition, leaving much of the computation-allocation space unexplored. We propose an environment-driven framework, AutoTTS, that changes what researchers design: from individual TTS heuristics to environments where TTS strategies can be discovered automatically. The key to AutoTTS lies in environment construction: the discovery environment must make the control space tractable and provide cheap, frequent feedback for TTS search. As a concrete instantiation, we formulate width--depth TTS as controller synthesis over pre-collected reasoning trajectories and probe signals, where controllers decide when to branch, continue, probe, prune, or stop and can be evaluated cheaply without repeated LLM calls. We further introduce beta parameterization to make the search tractable and fine-grained execution trace feedback to improve discovery efficiency by helping the agent diagnose why a TTS program fails. Experiments on mathematical reasoning benchmarks show that the discovered strategies improve the overall accuracy--cost tradeoff over strong manually designed baselines. The discovered strategies generalize to held-out benchmarks and model scales, while the entire discovery costs only $39.9 and 160 minutes. Our data, and code will be open-source at https://github.com/zhengkid/AutoTTS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AutoTTS, an environment-driven agentic framework for automatically discovering test-time scaling (TTS) strategies instead of hand-crafting them. It formulates width-depth TTS as controller synthesis over pre-collected reasoning trajectories and probe signals, where controllers select actions (branch/continue/probe/prune/stop) that can be evaluated cheaply without repeated LLM calls. Beta parameterization is introduced to make the search tractable, and fine-grained execution trace feedback aids diagnosis. Experiments on mathematical reasoning benchmarks claim that discovered strategies improve accuracy-cost tradeoffs over strong manual baselines, generalize to held-out benchmarks and model scales, and that the full discovery process costs only $39.9 and 160 minutes.
Significance. If the proxy-based discovery reliably transfers to live LLM execution, the work could shift TTS research from manual heuristic design to automated search over larger strategy spaces, with potential benefits for efficient inference scaling. The low discovery cost, emphasis on generalization across benchmarks and scales, and commitment to open-sourcing code and data are notable strengths that would support reproducibility and follow-on work.
major comments (2)
- [§3 (method) and Experiments] The central empirical claim (improved accuracy-cost tradeoff and generalization) rests on the proxy evaluation of controllers over fixed pre-collected trajectories (abstract and §3 formulation of width-depth TTS). However, no direct ablation or correlation analysis is provided comparing proxy scores against actual live LLM performance when the same discovered controllers are executed with fresh stochastic generations. This leaves open the risk that discovered beta-parameterized policies overfit the proxy distribution and underperform in deployment due to path stochasticity or distribution shift.
- [Experiments] The Experiments section reports benchmark improvements and generalization but provides no details on the number of independent runs, statistical significance tests (e.g., p-values or confidence intervals), variance across seeds, or precise rules for trajectory collection and exclusion. Without these, it is difficult to assess whether the reported gains over manual baselines are robust or could be explained by selection effects in the pre-collected data.
minor comments (2)
- [§3.3] The beta parameterization is described as making search tractable, but the exact functional form, how it constrains the controller space, and any sensitivity analysis to the beta hyperparameter are not clearly illustrated with equations or pseudocode.
- [Figures and Tables] Figure captions and table legends could more explicitly state whether reported costs include only discovery or also include the final live evaluation of discovered strategies.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will incorporate revisions to strengthen the empirical validation and reporting in the manuscript.
read point-by-point responses
-
Referee: [§3 (method) and Experiments] The central empirical claim (improved accuracy-cost tradeoff and generalization) rests on the proxy evaluation of controllers over fixed pre-collected trajectories (abstract and §3 formulation of width-depth TTS). However, no direct ablation or correlation analysis is provided comparing proxy scores against actual live LLM performance when the same discovered controllers are executed with fresh stochastic generations. This leaves open the risk that discovered beta-parameterized policies overfit the proxy distribution and underperform in deployment due to path stochasticity or distribution shift.
Authors: We appreciate the referee's concern about the fidelity of the proxy-based evaluation. The proxy is intentionally designed to enable tractable and low-cost search by reusing pre-collected trajectories and probe signals, avoiding repeated LLM calls during discovery. To directly address the risk of overfitting or distribution shift, we will add a new analysis in the revised Experiments section: we will execute the top discovered controllers in a live setting with fresh stochastic generations on the same benchmarks and report the Pearson correlation (and other metrics) between proxy scores and actual live accuracy-cost tradeoffs. This will quantify any gap and support the claim that the proxy reliably transfers. revision: yes
-
Referee: [Experiments] The Experiments section reports benchmark improvements and generalization but provides no details on the number of independent runs, statistical significance tests (e.g., p-values or confidence intervals), variance across seeds, or precise rules for trajectory collection and exclusion. Without these, it is difficult to assess whether the reported gains over manual baselines are robust or could be explained by selection effects in the pre-collected data.
Authors: We agree that these experimental details are necessary for assessing robustness. In the revised manuscript, we will expand the Experiments section (and add a dedicated subsection on experimental setup) to report: the number of independent runs (conducted with 5 random seeds), statistical significance tests including p-values and 95% confidence intervals for improvements over baselines, observed variance across seeds, and precise trajectory collection rules (sampling strategy from the base model, number of trajectories per problem, length limits, and exclusion criteria for low-quality or duplicate traces). These additions will allow readers to evaluate the reliability of the gains. revision: yes
Circularity Check
No significant circularity; empirical claims rest on independent benchmark validation
full rationale
The paper constructs an environment for controller synthesis over pre-collected trajectories to enable cheap discovery, then reports empirical improvements on held-out mathematical reasoning benchmarks and model scales. No derivation step reduces by construction to its own inputs: the beta-parameterized policies are searched rather than fitted to the target metric, the proxy evaluation is a deliberate efficiency mechanism rather than a self-defining loop, and generalization claims are tested externally. No self-citation load-bearing, uniqueness theorems, or ansatz smuggling appear in the derivation chain. The central result is therefore an empirical finding, not a tautology.
Axiom & Free-Parameter Ledger
free parameters (1)
- beta parameterization
axioms (1)
- domain assumption Pre-collected reasoning trajectories plus probe signals are representative enough to evaluate controllers without live LLM calls
Reference graph
Works this paper leans on
-
[1]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Let’s sample step by step: Adaptive-consistency for efficient reasoning and coding with llms
Pranjal Aggarwal, Aman Madaan, Yiming Yang, et al. Let’s sample step by step: Adaptive-consistency for efficient reasoning and coding with llms. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12375–12396, 2023
work page 2023
-
[3]
Yiwei Li, Peiwen Yuan, Shaoxiong Feng, Boyuan Pan, Xinglin Wang, Bin Sun, Heda Wang, and Kan Li. Escape sky-high cost: Early-stopping self-consistency for multi-step reasoning.arXiv preprint arXiv:2401.10480, 2024
-
[4]
Answer convergence as a signal for early stopping in reasoning
Xin Liu and Lu Wang. Answer convergence as a signal for early stopping in reasoning. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 17907–17918, 2025
work page 2025
-
[5]
Sampling-efficient test-time scaling: Self-estimating the best-of-n sampling in early decoding
Yiming Wang, Pei Zhang, Siyuan Huang, Baosong Yang, Zhuosheng Zhang, Fei Huang, and Rui Wang. Sampling-efficient test-time scaling: Self-estimating the best-of-n sampling in early decoding.arXiv preprint arXiv:2503.01422, 2025
-
[6]
Tong Zheng, Chengsong Huang, Runpeng Dai, Yun He, Rui Liu, Xin Ni, Huiwen Bao, Kaishen Wang, Hongtu Zhu, Jiaxin Huang, et al. Parallel-probe: Towards efficient parallel thinking via 2d probing.arXiv preprint arXiv:2602.03845, 2026
-
[7]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V Le, Christopher Ré, and Azalia Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling.arXiv preprint arXiv:2407.21787, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori B Hashimoto. s1: Simple test-time scaling. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 20286–20332, 2025
work page 2025
-
[10]
Wenting Zhao, Pranjal Aggarwal, Swarnadeep Saha, Asli Celikyilmaz, Jason Weston, and Ilia Kulikov. The majority is not always right: Rl training for solution aggregation.arXiv preprint arXiv:2509.06870, 2025
-
[11]
Hao Wen, Yifan Su, Feifei Zhang, Yunxin Liu, Yunhao Liu, Ya-Qin Zhang, and Yuanchun Li. Parathinker: Native parallel thinking as a new paradigm to scale llm test-time compute.arXiv preprint arXiv:2509.04475, 2025
-
[12]
Do Not Waste Your Rollouts: Recycling Search Experience for Efficient Test-Time Scaling
Xinglin Wang, Jiayi Shi, Shaoxiong Feng, Peiwen Yuan, Yiwei Li, Yueqi Zhang, Chuyi Tan, Ji Zhang, Boyuan Pan, Yao Hu, et al. Do not waste your rollouts: Recycling search experience for efficient test-time scaling.arXiv preprint arXiv:2601.21684, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
DeepPrune: Parallel Scaling without Inter-trace Redundancy
Shangqing Tu, Yaxuan Li, Yushi Bai, Lei Hou, and Juanzi Li. Deepprune: Parallel scaling without inter-trace redundancy.arXiv preprint arXiv:2510.08483, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Alphaone: Reasoning models thinking slow and fast at test time
Junyu Zhang, Runpei Dong, Han Wang, Xuying Ning, Haoran Geng, Peihao Li, Xialin He, Yutong Bai, Jitendra Malik, Saurabh Gupta, et al. Alphaone: Reasoning models thinking slow and fast at test time. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 11340–11365, 2025
work page 2025
-
[16]
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems, 36:11809–11822, 2023
work page 2023
-
[17]
Yuichi Inoue, Kou Misaki, Yuki Imajuku, So Kuroki, Taishi Nakamura, and Takuya Akiba. Wider or deeper? scaling llm inference-time compute with adaptive branching tree search.arXiv preprint arXiv:2503.04412, 2025. 10
-
[18]
Math-shepherd: Verify and reinforce llms step-by-step without human annotations
Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math-shepherd: Verify and reinforce llms step-by-step without human annotations. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9426–9439, 2024
work page 2024
-
[19]
Improve Mathematical Reasoning in Language Models by Automated Process Supervision
Liangchen Luo, Yinxiao Liu, Rosanne Liu, Samrat Phatale, Meiqi Guo, Harsh Lara, Yunxuan Li, Lei Shu, Yun Zhu, Lei Meng, et al. Improve mathematical reasoning in language models by automated process supervision.arXiv preprint arXiv:2406.06592, 2024
work page internal anchor Pith review arXiv 2024
-
[20]
Meta-Harness: End-to-End Optimization of Model Harnesses
Yoonho Lee, Roshen Nair, Qizheng Zhang, Kangwook Lee, Omar Khattab, and Chelsea Finn. Meta-harness: End-to-end optimization of model harnesses.arXiv preprint arXiv:2603.28052, 2026
work page internal anchor Pith review arXiv 2026
-
[21]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark.arXiv preprint arXiv:2311.12022, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Make every penny count: Difficulty-adaptive self-consistency for cost-efficient reasoning
Xinglin Wang, Shaoxiong Feng, Yiwei Li, Peiwen Yuan, Yueqi Zhang, Chuyi Tan, Boyuan Pan, Yao Hu, and Kan Li. Make every penny count: Difficulty-adaptive self-consistency for cost-efficient reasoning. In Findings of the Association for Computational Linguistics: NAACL 2025, pages 6904–6917, 2025
work page 2025
-
[25]
Efficient test-time scaling via self-calibration
Chengsong Huang, Langlin Huang, Jixuan Leng, Jiacheng Liu, and Jiaxin Huang. Efficient test-time scaling via self-calibration.arXiv preprint arXiv:2503.00031, 2025
-
[26]
Amir Taubenfeld, Tom Sheffer, Eran. O. Ofek, Amir Feder, Ariel Goldstein, Zorik Gekhman, and G. Yona. Confidence improves self-consistency in llms. InAnnual Meeting of the Association for Computational Linguistics, 2025
work page 2025
-
[27]
Yichao Fu, Xuewei Wang, Yuandong Tian, and Jiawei Zhao. Deep think with confidence.ArXiv, abs/2508.15260, 2025
-
[28]
Reasoning aware self-consistency: Leveraging reasoning paths for efficient llm sampling
Guangya Wan, Yuqi Wu, Jie Chen, and Sheng Li. Reasoning aware self-consistency: Leveraging reasoning paths for efficient llm sampling. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 3613–3635, 2025
work page 2025
-
[29]
Zhixiang Liang, Beichen Huang, Zheng Wang, and Minjia Zhang. Hidden states as early signals: Step-level trace evaluation and pruning for efficient test-time scaling.arXiv preprint arXiv:2601.09093, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
Slim-sc: Thought pruning for efficient scaling with self-consistency
Colin Hong, Xu Guo, Anand Chaanan Singh, Esha Choukse, and Dmitrii Ustiugov. Slim-sc: Thought pruning for efficient scaling with self-consistency. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 34488–34505, 2025
work page 2025
-
[31]
Entropy After </Think> for reasoning model early exiting
Xi Wang, James McInerney, Lequn Wang, and Nathan Kallus. Entropy after </think> for reasoning model early exiting.arXiv preprint arXiv:2509.26522, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Aman Sharma and Paras Chopra. Think just enough: Sequence-level entropy as a confidence signal for llm reasoning.arXiv preprint arXiv:2510.08146, 2025
-
[33]
Xixian Yong, Xiao Zhou, Yingying Zhang, Jinlin Li, Yefeng Zheng, and Xian Wu. Think or not? exploring thinking efficiency in large reasoning models via an information-theoretic lens.arXiv preprint arXiv:2505.18237, 2025
-
[34]
Early stopping chain-of-thoughts in large language models.ArXiv, abs/2509.14004, 2025
Minjia Mao, Bowen Yin, Yu Zhu, and Xiao Fang. Early stopping chain-of-thoughts in large language models.ArXiv, abs/2509.14004, 2025
-
[35]
Reasoning without self- doubt: More efficient chain-of-thought through certainty probing
Yichao Fu, Junda Chen, Yonghao Zhuang, Zheyu Fu, Ion Stoica, and Hao Zhang. Reasoning without self- doubt: More efficient chain-of-thought through certainty probing. InICLR 2025 Workshop on Foundation Models in the Wild, 2025
work page 2025
-
[36]
Anqi Zhang, Yulin Chen, Jane Pan, Chen Zhao, Aurojit Panda, Jinyang Li, and He He. Reasoning models know when they’re right: Probing hidden states for self-verification.arXiv preprint arXiv:2504.05419, 2025. 11
-
[37]
Dynamic early exit in reasoning models, 2025
Chenxu Yang, Qingyi Si, Yongjie Duan, Zheliang Zhu, Chenyu Zhu, Zheng Lin, Li Cao, and Weiping Wang. Dynamic early exit in reasoning models.ArXiv, abs/2504.15895, 2025
-
[38]
Neural architecture search with reinforcement learning.arXiv preprint arXiv:1611.01578, 2016
Barret Zoph and Quoc V Le. Neural architecture search with reinforcement learning.arXiv preprint arXiv:1611.01578, 2016
-
[39]
Neural architecture search: A survey.Journal of Machine Learning Research, 20(55):1–21, 2019
Thomas Elsken, Jan Hendrik Metzen, and Frank Hutter. Neural architecture search: A survey.Journal of Machine Learning Research, 20(55):1–21, 2019
work page 2019
-
[40]
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M Pawan Kumar, Emilien Dupont, Francisco JR Ruiz, Jordan S Ellenberg, Pengming Wang, Omar Fawzi, et al. Mathematical discoveries from program search with large language models.Nature, 625(7995):468–475, 2024
work page 2024
-
[41]
Evolution of heuristics: Towards efficient automatic algorithm design using large language model,
Fei Liu, Xialiang Tong, Mingxuan Yuan, Xi Lin, Fu Luo, Zhenkun Wang, Zhichao Lu, and Qingfu Zhang. Evolution of heuristics: Towards efficient automatic algorithm design using large language model.arXiv preprint arXiv:2401.02051, 2024
-
[42]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Alexander Novikov, Ngân V˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco JR Ruiz, Abbas Mehrabian, et al. Alphaevolve: A coding agent for scientific and algorithmic discovery.arXiv preprint arXiv:2506.13131, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Automated design of agentic systems.arXiv preprint arXiv:2408.08435, 2024
Shengran Hu, Cong Lu, and Jeff Clune. Automated design of agentic systems.arXiv preprint arXiv:2408.08435, 2024
-
[44]
Learning to discover at test time
Mert Yuksekgonul, Daniel Koceja, Xinhao Li, Federico Bianchi, Jed McCaleb, Xiaolong Wang, Jan Kautz, Yejin Choi, James Zou, Carlos Guestrin, et al. Learning to discover at test time.arXiv preprint arXiv:2601.16175, 2026
-
[45]
Thetaevolve: Test-time learning on open problems.arXiv preprint arXiv:2511.23473, 2025
Yiping Wang, Shao-Rong Su, Zhiyuan Zeng, Eva Xu, Liliang Ren, Xinyu Yang, Zeyi Huang, Xuehai He, Luyao Ma, Baolin Peng, et al. Thetaevolve: Test-time learning on open problems.arXiv preprint arXiv:2511.23473, 2025. 12 A Limitation AutoTTS demonstrates that effective TTS strategies can be automatically discovered through environment-driven search at minima...
-
[46]
maximize answer accuracy
-
[47]
minimize total token cost Accuracy is the primary objective. Among controllers with similar accuracy, prefer lower total cost. The goal is to improve held-out accuracy-efficiency behavior, not merely search-set numbers. The target is a reusable controller algorithm that maps the current 2D probing state to decisions such as:,→ - whether to start a new bra...
-
[48]
Inspect the current codebase and understand the environment abstraction (`code_base/data_loader.py`,`code_base/eval.py`).,→
-
[49]
Inspect`code_base/method.py`(and`code_base/method.template.py`) to read the seed implementations`ASCMethod`,`ESCMethod`,`Parallel_Probe`, the shared helpers, and the `OptimalController`stub you must fill in. ,→ ,→
-
[50]
Inspect`code_base/history/seed_algorithms/matrix_results_<Model>/`for the seed accuracy-cost frontier and per-step traces.,→
-
[51]
Inspect the latest few`code_base/history/rNNNN_<ts>_<uid>/`folders for prior `OptimalController`proposals (`method.py`snapshot) and their`proposal_results/`(CSV + trace JSONL). ,→ ,→
-
[52]
Summarize the core ideas of prior proposals and seed algorithms
-
[53]
Identify what has already been tried, what failed, and what would count as genuinely different. 16
-
[54]
Propose a new controller that is novel, adaptive, and plausibly stronger in held-out accuracy-efficiency behavior.,→
-
[55]
Prefer a coherent budget-controlled controller family, ideally governed by`beta`, over many independent thresholds.,→
-
[56]
Implement the controller by directly editing`OptimalController`in`code_base/method.py`. Wire the`MethodTraceRecorder`/`_trace_step`/`solve_with_trace`surface in the same style as the seeds so traces are emitted into `training_results/matrix_results_<Model>/<dataset>_trace_new_api.jsonl`. ,→ ,→ ,→
-
[57]
Ensure constructor, signature, inheritance/interface behavior, and return behavior remain compatible with`code_base/eval.py`(which currently instantiates `OptimalController(config={{"beta": beta}})`). ,→ ,→
-
[58]
Keep the patch focused and avoid unnecessary changes
-
[59]
Summarize: - the controller idea - whether history was used (which rounds and which seed traces) - what lessons were extracted from prior proposals and seed algorithms - what makes this controller genuinely different from`ASCMethod`,`ESCMethod`, and `Parallel_Probe`,→ - why this controller is adaptive in width-depth budget allocation - how it uses the sha...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.