Recognition: 2 theorem links
· Lean TheoremBaLoRA: Bayesian Low-Rank Adaptation of Large Scale Models
Pith reviewed 2026-05-12 01:39 UTC · model grok-4.3
The pith
BaLoRA equips low-rank adaptation with input-adaptive Bayesian noise that narrows the accuracy gap to full fine-tuning while supplying built-in uncertainty estimates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The input-adaptive Bayesian parameterization of the LoRA matrices delivers well-calibrated uncertainty estimates and, through its adaptive noise injection, also raises prediction accuracy, closing much of the remaining gap to full fine-tuning on language and vision benchmarks.
What carries the argument
Input-adaptive Bayesian parameterization of the LoRA update matrices, realized by treating each matrix entry as drawn from a distribution whose parameters depend on the input.
If this is right
- Accuracy on natural-language reasoning and vision tasks moves closer to full fine-tuning without the full parameter cost.
- Uncertainty estimates become available at test time with no separate training of an ensemble.
- Uncertainty quality on scientific regression tasks improves steadily as more forward passes are budgeted.
- The same low-rank structure can now support reliability-sensitive applications that previously required full Bayesian methods.
Where Pith is reading between the lines
- The same adaptive-noise mechanism could be attached to other low-rank or parameter-efficient adapters beyond LoRA.
- In deployment settings where both accuracy and risk assessment matter, BaLoRA may reduce the need for separate uncertainty heads or post-hoc calibration.
- Because uncertainty improves with extra compute at test time, the method naturally supports variable-budget inference.
Load-bearing premise
The new Bayesian parameterization of the LoRA matrices can be implemented with only tiny extra parameters and compute while still raising accuracy and producing reliable uncertainty.
What would settle it
A controlled comparison on the same tasks in which BaLoRA either fails to improve accuracy over standard LoRA or produces uncertainty estimates whose correlation with error is no better than a simple ensemble.
Figures



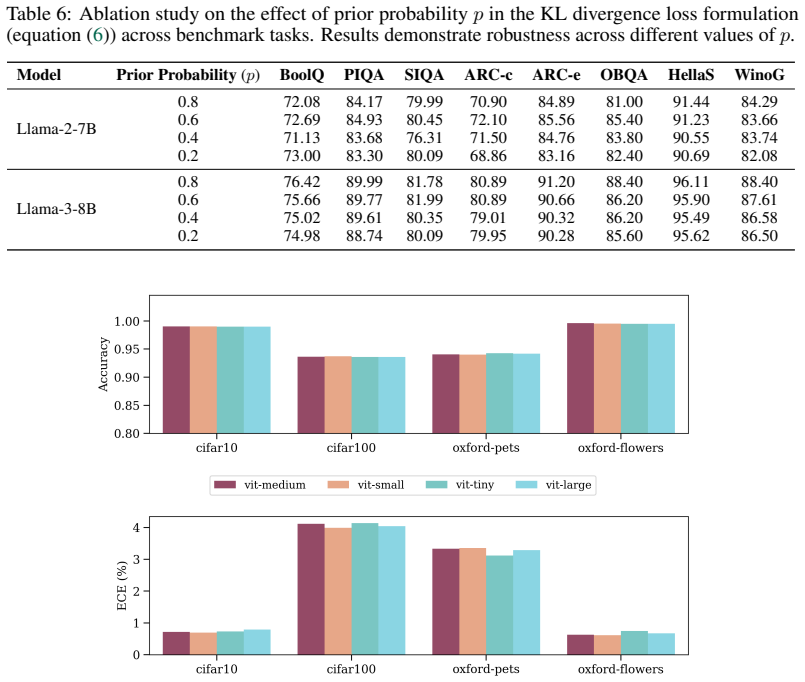

read the original abstract
Low-Rank Adaptation (LoRA) has become the standard for fine-tuning large pre-trained models at reduced computational cost. However, its low-rank point-estimate updates limit expressiveness, leave a persistent gap relative to full fine-tuning accuracy, and provide no built-in uncertainty quantification, limiting its applicability in settings where reliability matters as much as accuracy. We introduce BaLoRA, a Bayesian extension of LoRA with a novel input-adaptive Bayesian parameterization of LoRA matrices that adds minimal parameters and compute. Surprisingly, not only does the Bayesian extension yield well-calibrated uncertainty estimates, but the adaptive noise injection underlying our approach also significantly improves prediction accuracy, narrowing the gap with full fine-tuning across both natural language reasoning and vision tasks. When applied to band gap prediction in metal-organic frameworks, BaLoRA produces zero-shot test-time uncertainty estimates that correlate more strongly with model error than a trained ensemble of LoRA models, and improve monotonically with compute without sacrificing accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BaLoRA, a Bayesian extension of Low-Rank Adaptation (LoRA) that employs a novel input-adaptive Bayesian parameterization of the LoRA matrices. It claims this adds only minimal parameters and compute while yielding well-calibrated uncertainty estimates; the adaptive noise injection is asserted to improve prediction accuracy and narrow the gap to full fine-tuning on natural language reasoning and vision tasks. On band gap prediction for metal-organic frameworks, BaLoRA is claimed to produce zero-shot test-time uncertainty estimates that correlate more strongly with model error than a trained LoRA ensemble and that improve monotonically with compute without sacrificing accuracy.
Significance. If the empirical claims are substantiated, BaLoRA could meaningfully advance parameter-efficient fine-tuning by integrating uncertainty quantification with accuracy gains, reducing reliance on ensembles for reliability. The reported monotonic uncertainty improvement with compute is a potentially valuable property for scientific applications if it holds under controlled ablations.
major comments (2)
- [Abstract] Abstract: The abstract asserts both accuracy gains via adaptive noise injection and superior uncertainty calibration (stronger correlation with model error than ensembles, monotonic improvement with compute) but supplies no quantitative results, ablation studies, or implementation details. This prevents evaluation of the data supporting the central claims.
- [Method] Method description: The input-adaptive Bayesian parameterization of the LoRA matrices is stated to add 'minimal parameters and compute,' yet the manuscript provides no explicit accounting of the additional operations required to realize input dependence (e.g., extra linear layers or hypernetworks for per-sample noise scales or variational parameters). In the regime of long sequences or large batches, this overhead could be non-negligible and could explain part of the accuracy gain through extra capacity rather than the Bayesian mechanism itself.
minor comments (1)
- [Abstract] The abstract would benefit from a brief parenthetical mention of the specific tasks, datasets, and key metrics (e.g., accuracy deltas or correlation values) to allow readers to gauge the magnitude of the reported improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment point by point below, indicating where revisions will be made to strengthen clarity and support for the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts both accuracy gains via adaptive noise injection and superior uncertainty calibration (stronger correlation with model error than ensembles, monotonic improvement with compute) but supplies no quantitative results, ablation studies, or implementation details. This prevents evaluation of the data supporting the central claims.
Authors: We acknowledge that the abstract, as currently written, is high-level and omits specific numerical results to preserve brevity. The full manuscript already contains quantitative results, ablations, and implementation details in the experiments section and appendix. To directly address the concern, we will revise the abstract to include a small number of key quantitative highlights (e.g., accuracy deltas versus standard LoRA and uncertainty-error correlation values) while retaining its concise form. This change will make the central claims easier to evaluate from the abstract alone. revision: yes
-
Referee: [Method] Method description: The input-adaptive Bayesian parameterization of the LoRA matrices is stated to add 'minimal parameters and compute,' yet the manuscript provides no explicit accounting of the additional operations required to realize input dependence (e.g., extra linear layers or hypernetworks for per-sample noise scales or variational parameters). In the regime of long sequences or large batches, this overhead could be non-negligible and could explain part of the accuracy gain through extra capacity rather than the Bayesian mechanism itself.
Authors: This observation is correct and highlights a genuine gap in the current presentation. The manuscript asserts minimal overhead but does not supply an explicit parameter count or FLOP breakdown for the input-adaptive components. In the revised manuscript we will add a dedicated paragraph (and accompanying table) that enumerates the additional linear layers or hypernetwork parameters introduced for per-sample noise scales, together with their contribution to total parameters and inference cost. We will also include a controlled ablation that isolates the effect of this extra capacity from the Bayesian noise mechanism itself. revision: yes
Circularity Check
No circularity: novel parameterization presented without self-referential derivations or fitted predictions
full rationale
The provided abstract and summary contain no equations, derivations, or explicit reduction steps. The central claim introduces a 'novel input-adaptive Bayesian parameterization' as an empirical extension that adds minimal overhead while improving accuracy and uncertainty, but this is not shown to be equivalent to its inputs by construction, nor does it rely on self-citations for uniqueness or load-bearing premises. No fitted parameters are renamed as predictions, and no ansatz is smuggled via prior work. The derivation chain (if present in the full text) is not visible here as reducing to tautology; the paper's contributions rest on reported empirical outcomes rather than algebraic self-definition.
Axiom & Free-Parameter Ledger
invented entities (1)
-
input-adaptive Bayesian parameterization of LoRA matrices
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce BaLoRA, a Bayesian extension of LoRA with a novel input-adaptive Bayesian parameterization of LoRA matrices that adds minimal parameters and compute... ω_A;ij = θ_A;ij + √(α(x) θ_A;ij²) ϵ_ij
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Low-Rank local reparametrization trick... y = θ_0 x + θ_B θ_A x + θ_B (√d(x) ⊙ ϵ_d)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Edward J Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo. 2022 , url=
work page 2022
-
[2]
Blips: Bayesian learned interatomic potentials, 2026
BLIPs: Bayesian Learned Interatomic Potentials , author=. arXiv preprint arXiv:2508.14022 , year=
-
[3]
Physical review letters , volume=
Crystal graph convolutional neural networks for an accurate and interpretable prediction of material properties , author=. Physical review letters , volume=. 2018 , publisher=
work page 2018
-
[4]
International conference on machine learning , pages=
Training data-efficient image transformers & distillation through attention , author=. International conference on machine learning , pages=. 2021 , organization=
work page 2021
-
[5]
Decoupled Weight Decay Regularization
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Kingma, Durk P and Salimans, Tim and Welling, Max , booktitle=
- [7]
-
[8]
Hinton, Geoffrey E and Van Camp, Drew , booktitle=
-
[9]
Graves, Alex , journal=
-
[10]
Gal, Yarin and Ghahramani, Zoubin , booktitle=. 2016 , organization=
work page 2016
-
[11]
LoRA ensembles for large language model fine-tuning.arXiv preprint arXiv:2310.00035,
LoRA ensembles for large language model fine-tuning , author=. arXiv preprint arXiv:2310.00035 , year=
-
[12]
Blundell, Charles and Cornebise, Julien and Kavukcuoglu, Koray and Wierstra, Daan , booktitle=. 2015 , organization=
work page 2015
-
[13]
Welling, Max and Teh, Yee W , booktitle=
-
[14]
Lakshminarayanan, Balaji and Pritzel, Alexander and Blundell, Charles , journal=
-
[15]
International Conference on Neural Information Processing Systems , year=
UMA: A Family of Universal Models for Atoms , author=. International Conference on Neural Information Processing Systems , year=
-
[16]
International Conference on Learning Representations , year=
From Molecules to Materials: Pre-training Large Generalizable Models for Atomic Property Prediction , author=. International Conference on Learning Representations , year=
-
[17]
Nature Machine Intelligence , volume=
A multi-modal pre-training transformer for universal transfer learning in metal--organic frameworks , author=. Nature Machine Intelligence , volume=. 2023 , publisher=
work page 2023
-
[18]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Is ChatGPT a general-purpose natural language processing task solver? , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
work page 2023
-
[19]
International Conference on Neural Information Processing Systems , volume=
Visual instruction tuning , author=. International Conference on Neural Information Processing Systems , volume=
-
[20]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
International conference on machine learning , pages=
Parameter-efficient transfer learning for NLP , author=. International conference on machine learning , pages=. 2019 , organization=
work page 2019
-
[22]
Forty-first International Conference on Machine Learning , year=
Dora: Weight-decomposed low-rank adaptation , author=. Forty-first International Conference on Machine Learning , year=
-
[23]
A foundation model for the Earth system , author=. Nature , volume=. 2025 , publisher=
work page 2025
-
[24]
Forty-second International Conference on Machine Learning , year=
BARNN: A Bayesian Autoregressive and Recurrent Neural Network , author=. Forty-second International Conference on Machine Learning , year=
-
[25]
Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
The power of scale for parameter-efficient prompt tuning , author=. Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
work page 2021
-
[26]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
Residual prompt tuning: Improving prompt tuning with residual reparameterization , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
work page 2023
-
[27]
GPT understands, too , author=. AI open , volume=. 2024 , publisher=
work page 2024
-
[28]
Parameter-efficient multi-task fine-tuning for transformers via shared hypernetworks , author=. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages=
-
[29]
Intrinsic dimensionality explains the effectiveness of language model fine-tuning , author=. Proceedings of the 59th annual meeting of the association for computational linguistics and the 11th international joint conference on natural language processing (volume 1: long papers) , pages=
-
[30]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Llm-adapters: An adapter family for parameter-efficient fine-tuning of large language models , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
work page 2023
-
[32]
P-tuning: Prompt tuning can be comparable to fine-tuning across scales and tasks , author=. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
-
[33]
npj Computational Materials , volume=
High-throughput predictions of metal--organic framework electronic properties: theoretical challenges, graph neural networks, and data exploration , author=. npj Computational Materials , volume=. 2022 , publisher=
work page 2022
-
[34]
Machine learning the quantum-chemical properties of metal--organic frameworks for accelerated materials discovery , author=. Matter , volume=. 2021 , publisher=
work page 2021
-
[35]
Journal of the American Chemical Society , volume=
Moformer: self-supervised transformer model for metal--organic framework property prediction , author=. Journal of the American Chemical Society , volume=. 2023 , publisher=
work page 2023
-
[36]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
An image is worth 16x16 words: Transformers for image recognition at scale , author=. arXiv preprint arXiv:2010.11929 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[37]
Wightman, Ross , doi =
-
[38]
arXiv preprint arXiv:2405.12130 , year=
Mora: High-rank updating for parameter-efficient fine-tuning , author=. arXiv preprint arXiv:2405.12130 , year=
-
[39]
The Thirteenth International Conference on Learning Representations , year=
HiRA: Parameter-efficient hadamard high-rank adaptation for large language models , author=. The Thirteenth International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.