Recognition: 2 theorem links
· Lean TheoremStatistical Inference and Quality Measures of KV Cache Quantisations Inspired by TurboQuant
Pith reviewed 2026-05-12 01:17 UTC · model grok-4.3
The pith
Applying milder quantization to keys than to values reduces KL divergence between reference and quantized attention at the 4-bit budget.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Starting from the Beta distribution on the hypersphere, applying the advanced projection to keys inflates inner-product variance by pi/2, which the softmax amplifies superlinearly via Jensen's inequality under a sufficient condition the paper states. This mechanism produces higher KL divergence for symmetric quantization of both keys and values than for the asymmetric KQV scheme at n=4, where KQV wins on every metric. Empirical results across budgets show the crossover in geometric key error at n in {2,3,5} versus {4,6}, invariant to rank and tail weight, while KL remains lower for KQV at all points.
What carries the argument
The nonlinear amplification of key inner-product variance through the softmax operation when the advanced projection is applied to keys.
If this is right
- KL divergence on attention scores directly connects key direction error to potential routing corruption and output collapse in the model.
- The unconditional K-V asymmetry implies that quantizers should default to milder treatment of keys than values at every budget.
- Geometric reconstruction quality crosses over with budget, so the optimal scheme depends on the target precision rather than being fixed.
- At the practically dominant n=4 setting the Jensen mechanism dominates, explaining why symmetric projection on keys harms performance.
Where Pith is reading between the lines
- Quantizer designs could allocate different transforms to keys and values by default to respect their distinct roles in attention.
- The observed rate-distortion crossover points to an optimization problem of choosing per-vector bit allocation rather than uniform budgets.
- Validating the hyperspherical Beta model against statistics from real model weights would strengthen the statistical predictions for deployment.
Load-bearing premise
The Beta distribution on the hypersphere accurately captures the direction statistics of real key and value vectors from trained transformers.
What would settle it
Compute KL divergence on attention probability distributions from an actual trained transformer at n=4 using the KQV scheme versus the QKQV scheme and check whether the predicted elevation for QKQV appears.
Figures

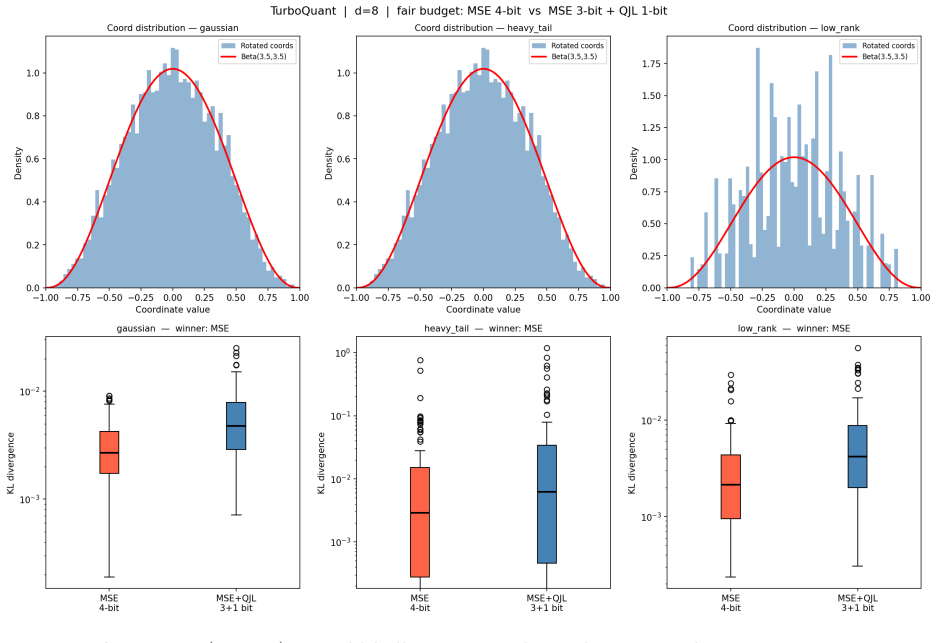
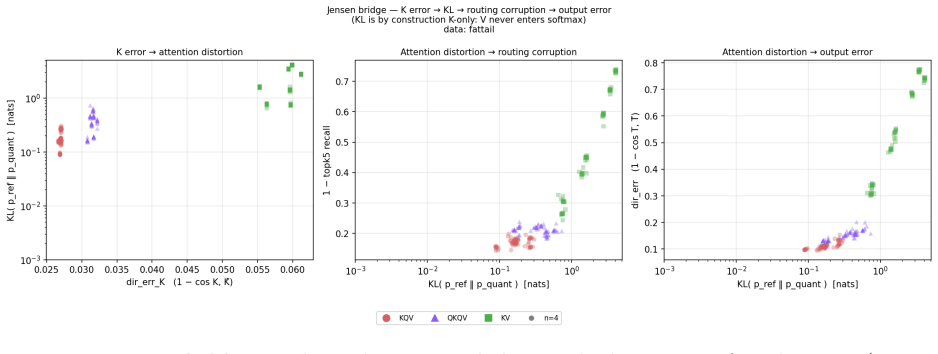



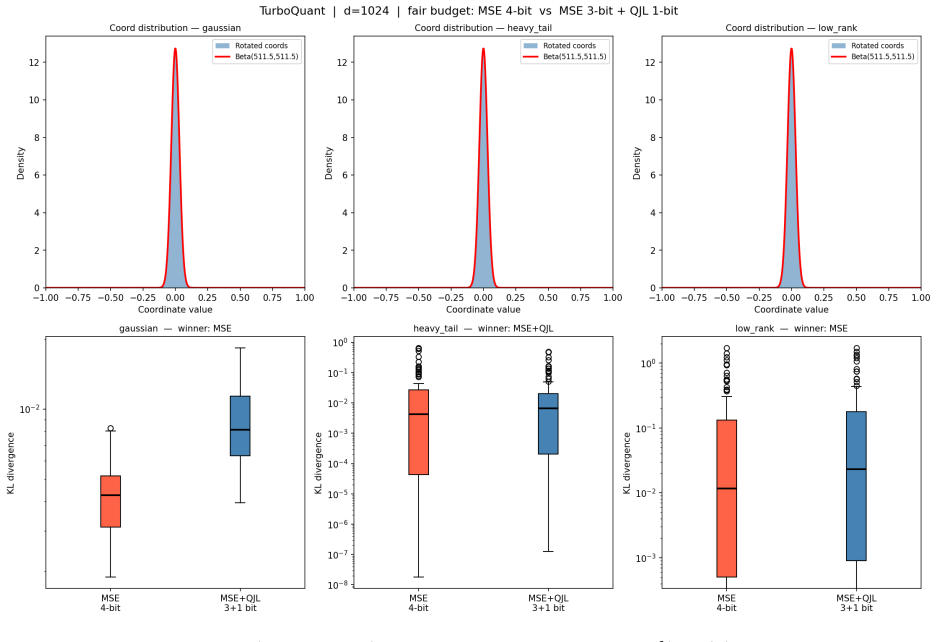
read the original abstract
We analyse three KV cache quantization schemes under a fair bit budget: \textbf{KV} (scalar MSE baseline), \textbf{KQV} (WHT + MSE on $K$; WHT + MSE + QJL on $V$), and \textbf{QKQV} (WHT + MSE + QJL on both). Starting from the Beta distribution on the hypersphere, we trace how QJL on $K$ inflates inner product variance by $\pi/2$, which softmax amplifies nonlinearly via Jensen's inequality, and we present statistical inference and information metrics to highlight practical differences. Three empirical findings emerge. (1)~At $n=4$ (the practically dominant budget), KQV wins on every measure -- KL divergence, geometric $K$ error, and 6D distance -- across all distributions and ranks tested. (2)~The K--V asymmetry is unconditional: QKQV is consistently worse than KQV in KL divergence at every budget and distribution. (3)~A budget-dependent crossover exists: QKQV achieves better geometric $K$ reconstruction at $n \in \{2,3,5\}$, KQV at $n \in \{4,6\}$, invariant to rank and tail weight -- an open rate-distortion problem. $\mathrm{KL}(p_{\mathrm{ref}} \| p_{\mathrm{quant}})$, K-only by construction, bridges K direction error to routing corruption and output collapse. We present a sufficient condition when the Jensen mechanism amplifies superlinearly through the softmax. At $n \in \{2,3,5\}$, QKQV wins geometrically because this assumption does not bind. At $n=4$, elevated K error and KL divergence for QKQV strongly suggest the Jensen mechanism is the operative cause of the crossover, providing a new perspective and explanation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes three KV cache quantization schemes—KV (scalar MSE baseline), KQV (WHT + MSE on K; WHT + MSE + QJL on V), and QKQV (WHT + MSE + QJL on both)—under a fixed bit budget. Using vectors drawn from a Beta distribution on the hypersphere as a model for K and V, the authors derive that applying QJL to K inflates the variance of inner products by a factor of π/2. This inflation is then amplified nonlinearly by the softmax via Jensen's inequality. They provide a sufficient condition for superlinear amplification and report simulation results showing that at n=4 bits, KQV outperforms on KL divergence, geometric K error, and 6D distance across distributions and ranks; QKQV is consistently worse than KQV in KL divergence; and a budget-dependent crossover in geometric K reconstruction occurs, with QKQV better at n=2,3,5 and KQV at n=4,6.
Significance. If the Beta hypersphere model is a faithful representation of real transformer KV cache statistics, the work provides a mechanistic explanation for performance differences between quantization schemes and identifies the Jensen amplification as the cause of the crossover at n=4. It introduces statistical inference and quality measures (KL, geometric error, 6D distance) that link quantization error to potential routing corruption and output collapse. The parameter-free derivation of the π/2 variance factor and the sufficient condition for Jensen amplification are strengths, offering a new perspective on KV quantization design.
major comments (1)
- The central explanatory claim—that the budget-dependent crossover at n=4 is caused by the Jensen mechanism amplifying QJL-induced variance—depends on the Beta distribution on the hypersphere accurately modeling the angular statistics of real K and V vectors from trained transformers (see abstract and the section deriving the variance inflation and sufficient condition). Real KV caches typically exhibit low effective rank, K-V correlations, and non-uniform distributions that could alter inner-product variance or prevent the sufficient condition for superlinear softmax amplification from binding. Without empirical validation against actual model activations or a sensitivity analysis, the practical implications for transformer inference remain uncertain.
minor comments (2)
- The abstract mentions 'across all distributions and ranks tested' but does not specify the exact distributions, rank values, or number of trials; including these details or error bars would improve reproducibility and allow assessment of the consistency of the crossover.
- The term 'n=4' for bit budget is used without initial definition; clarifying that n refers to the number of bits per element in the quantization would aid readers.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for highlighting the importance of model fidelity. We address the major comment below by clarifying the scope of our theoretical analysis and offering a targeted revision.
read point-by-point responses
-
Referee: The central explanatory claim—that the budget-dependent crossover at n=4 is caused by the Jensen mechanism amplifying QJL-induced variance—depends on the Beta distribution on the hypersphere accurately modeling the angular statistics of real K and V vectors from trained transformers (see abstract and the section deriving the variance inflation and sufficient condition). Real KV caches typically exhibit low effective rank, K-V correlations, and non-uniform distributions that could alter inner-product variance or prevent the sufficient condition for superlinear softmax amplification from binding. Without empirical validation against actual model activations or a sensitivity analysis, the practical implications for transformer inference remain uncertain.
Authors: We agree that direct empirical validation on real transformer KV activations would strengthen the practical implications. Our manuscript is explicitly a model-based theoretical study: it begins from the Beta distribution on the hypersphere precisely because this distribution permits an analytic derivation of the π/2 variance inflation factor for inner products under QJL and yields a sufficient condition for superlinear amplification through the softmax via Jensen's inequality. All reported results (KL divergence, geometric K error, 6D distance, and the n=4 crossover) are obtained under controlled simulations within this framework, which isolates the effect of applying QJL to K versus V. The paper does not assert that the Beta hypersphere model replicates every statistic of real KV caches (e.g., low effective rank or K-V correlations); rather, it demonstrates that, whenever the sufficient condition binds, the Jensen mechanism produces the observed performance gap. In revision we will add an explicit Limitations subsection that (i) states the modeling assumptions, (ii) notes that real caches may modulate the variance inflation or prevent the sufficient condition from binding, and (iii) frames the n=4 crossover as a prediction of the model that can be tested on actual activations. This preserves the mechanistic contribution while acknowledging the referee's concern. revision: partial
Circularity Check
No significant circularity; results are simulation outcomes on an explicit synthetic model
full rationale
The paper begins with an explicit Beta distribution on the hypersphere as the generative model for K and V vectors. It derives the inner-product variance inflation of exactly π/2 from the interaction of this distribution with the QJL operator, then applies Jensen's inequality (a standard inequality) to obtain the sufficient condition for superlinear softmax amplification. All three headline empirical findings—KQV dominance at n=4 on KL/geometric/6D metrics, unconditional K-V asymmetry, and the budget-dependent crossover—are direct outputs of Monte-Carlo simulations run under these fixed distributional assumptions. No parameter is fitted to the target performance numbers, no result is renamed as a prediction, and no load-bearing premise rests on a self-citation whose content is itself unverified. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Normalized key and value vectors in attention follow a Beta distribution on the hypersphere.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Starting from the Beta distribution on the hypersphere, we trace how QJL on K inflates inner product variance by π/2, which softmax amplifies nonlinearly via Jensen’s inequality.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
At n=4 ... KQV wins on every measure — KL divergence, geometric K error, and 6D distance
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Turboquant: Online vector quantization with near-optimal distortion rate,
Amir Zandieh, Majid Daliri, Majid Hadian, and Vahab Mirrokni. TurboQuant: Online vector quantization with near-optimal distortion rate. arXiv:2504.19874, 2025
-
[2]
QJL: 1-Bit Quantized JL Transform for KV Cache Quantization with Zero Overhead,
Amir Zandieh, Majid Daliri, and Insu Han. QJL: 1-bit quantized JL transform for KV cache quantization with zero overhead. arXiv:2406.03482, 2024
-
[3]
Quantizing for minimum distortion.IRE Transactions on Information Theory, 6(1):7–12, 1960
Joel Max. Quantizing for minimum distortion.IRE Transactions on Information Theory, 6(1):7–12, 1960
work page 1960
-
[4]
Stuart P. Lloyd. Least squares quantization in PCM.IEEE Transactions on Information Theory, 28(2):129–137, 1982
work page 1982
-
[5]
Johnson and Joram Lindenstrauss
William B. Johnson and Joram Lindenstrauss. Extensions of Lipschitz mappings into a Hilbert space.Contemporary Mathematics, 26:189–206, 1984
work page 1984
-
[6]
Claude E. Shannon. A mathematical theory of communication.Bell System Technical Journal, 27(3):379–423, 1948. 22
work page 1948
-
[7]
G´ abor J. Sz´ ekely and Maria L. Rizzo. Energy statistics: A class of statistics based on distances. Journal of Statistical Planning and Inference, 143(8):1249–1272, 2013
work page 2013
-
[8]
Belinda Phipson and Gordon K. Smyth. Permutationp-values should never be zero: Calculating exactp-values when permutations are randomly drawn.Statistical Applications in Genetics and Molecular Biology, 9(1), 2010
work page 2010
-
[9]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Representations, 2022. A Summary: Best Scheme by Regime and Budget Table 4 collects the best-performing scheme across all tested regimes and budgets, measu...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.