Recognition: 2 theorem links
· Lean TheoremQuantile Geometry Regularization for Distributional Reinforcement Learning
Pith reviewed 2026-05-12 01:15 UTC · model grok-4.3
The pith
A Wasserstein-based correction to Bellman targets regularizes quantile geometry in distributional reinforcement learning while preserving risk-neutral averages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that reinterpreting the IQN loss snapshot as independent local empirical quantile estimation problems permits a Wasserstein distributionally robust correction applied slot-by-slot, which yields a fraction-dependent adjustment to the Bellman target. The adjustment satisfies median antisymmetry to preserve the risk-neutral quantile average and monotonicity to enlarge inter-quantile gaps, thereby regularizing geometry without altering the underlying value objective or requiring additional sample reconstruction.
What carries the argument
The fraction-dependent closed-form correction to the Bellman target, obtained by solving a Wasserstein distributionally robust quantile estimation problem on each local empirical slot from the reinterpreted IQN loss.
If this is right
- The median antisymmetry property ensures the risk-neutral expected return remains unchanged.
- Monotonicity of the correction enlarges upper-lower quantile gaps and prevents distributional collapse.
- RQIQN integrates as a drop-in enhancement to existing IQN-based algorithms without extra sample reconstruction.
- The same correction mechanism yields measurable gains on risk-sensitive navigation and Atari game benchmarks.
Where Pith is reading between the lines
- The local robustification pattern may extend to other quantile regression settings in supervised or unsupervised learning where distribution collapse appears.
- Preserving spread while keeping the mean fixed could stabilize value estimates in long-horizon tasks where variance underestimation is common.
- Because the correction depends only on the current fraction, it could be combined with other distributional regularizers that act on different parts of the return distribution.
Load-bearing premise
Treating a snapshot of the IQN loss as a collection of independent local empirical quantile estimation problems is accurate enough that robustifying each slot separately produces a valid, non-distorting correction to the overall return distribution.
What would settle it
Train both standard IQN and RQIQN on the same risk-sensitive navigation environment, then measure the inter-quantile range of the learned distributions together with the mean returns; if RQIQN fails to produce a reliably larger range while keeping mean returns comparable, the claimed geometric regularization is not occurring.
Figures



read the original abstract
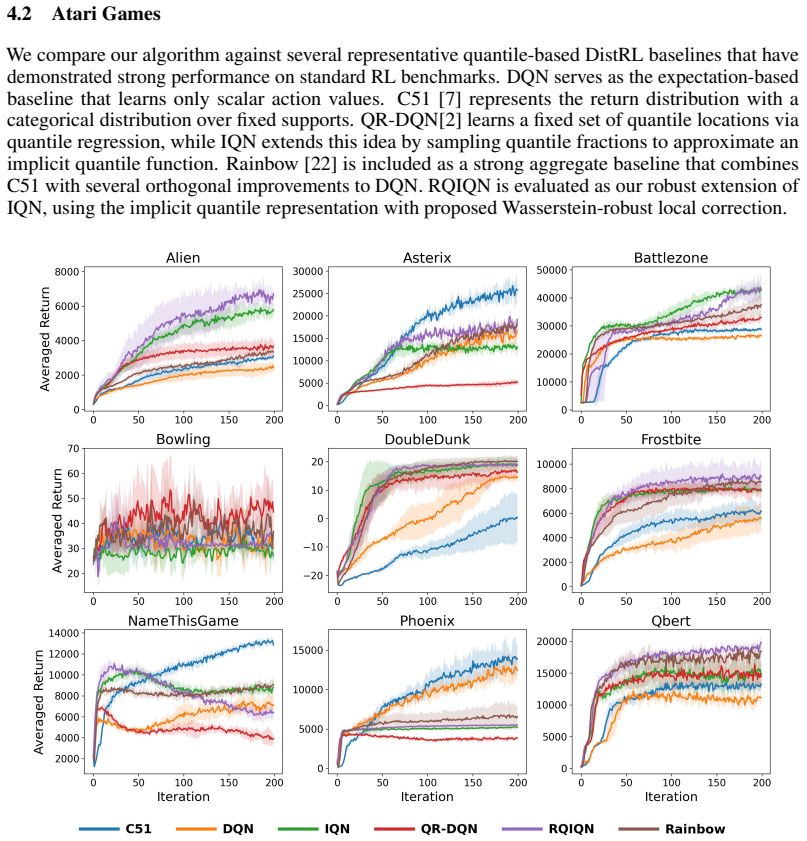
Quantile-based distributional reinforcement learning methods learn return distributions through sampled quantile regression, but their bootstrapped target quantiles may induce distorted or degenerate distribution estimates. We propose Robust Quantile-based Implicit Quantile Networks (RQIQN), a lightweight Wasserstein distributionally robust enhancement boosted from a quantile estimation perspective. We first reinterpret a snapshot of IQN loss as a collection of local empirical quantile estimation problems over sampled current fractions. We then robustify each local slot with a Wasserstein distributionally robust quantile estimation formulation, yielding a closed-form, fraction-dependent correction to the Bellman target. This correction directly addresses distributional degeneration: its median antisymmetry preserves the risk-neutral quantile average, while its monotonicity enlarges upper-lower quantile gaps and counteracts collapsed distributional spread. RQIQN thus regularizes quantile geometry without changing the underlying value objective or requiring additional sample set reconstruction. Finally, we empirically show that the proposed RQIQN outperforms other existing quantile-based distributional reinforcement learning algorithms in risk-sensitive navigation and Atari games.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Robust Quantile-based Implicit Quantile Networks (RQIQN) as a lightweight enhancement to Implicit Quantile Networks (IQN) in distributional reinforcement learning. It reinterprets a snapshot of the IQN loss as a collection of independent local empirical quantile estimation problems over sampled fractions τ, then applies a Wasserstein distributionally robust optimization formulation to each slot. This yields a closed-form, fraction-dependent correction to the Bellman target. The correction is claimed to preserve the risk-neutral mean through median antisymmetry while monotonically enlarging quantile gaps to counteract distributional collapse, all without altering the underlying value objective or requiring extra sample reconstruction. Empirical results are presented showing outperformance over existing quantile-based distributional RL methods on risk-sensitive navigation tasks and Atari games.
Significance. If the decomposition and closed-form correction are rigorously valid, the approach provides a parameter-free geometric regularizer for quantile-based distributional RL that directly targets degeneration while preserving the original objective. This could be useful for risk-sensitive settings where collapsed distributions degrade performance. The empirical gains on navigation and Atari are promising but their significance is limited by the absence of detailed error analysis, ablation on the correction's components, and verification that gains are robust to the coupling issues in the IQN architecture.
major comments (2)
- [Method section (reinterpretation and Wasserstein DRO application)] The reinterpretation of the IQN loss as a sum of independent local quantile regression problems (one per sampled τ) is load-bearing for the entire construction, as it enables independent Wasserstein DRO application per slot to produce the claimed closed-form correction. However, the shared network parameters, joint sampling of multiple τ values, and implicit quantile embedding in the IQN architecture introduce potential coupling between terms. No explicit algebraic verification is provided that the loss factors cleanly or that the resulting per-slot corrections preserve median antisymmetry (hence the risk-neutral mean) and monotonic enlargement of quantile gaps under this coupling. This directly undermines the claims in the abstract regarding 'median antisymmetry' and 'monotonicity' as well as the skeptic's noted concern about exact decomposition.
- [Abstract and §4 (theoretical properties)] The abstract states that the correction 'directly addresses distributional degeneration' with specific geometric properties, yet the provided text contains no derivation details, error bounds, or proof that the Wasserstein DRO formulation on local empirical quantiles yields a non-distorting, fraction-dependent shift that maintains the original Bellman target properties. Without this, it is impossible to confirm whether the empirical gains arise from the intended regularization or from incidental effects.
minor comments (2)
- [Abstract] The abstract is information-dense and combines multiple technical claims (reinterpretation, closed-form correction, geometric properties, empirical results) in a single paragraph; consider separating the method description from the empirical summary for clarity.
- [Experiments] No details are given on the experimental protocol, including how risk-sensitive navigation tasks were defined, the exact baselines compared, or statistical significance of the reported outperformance; this should be expanded in the experiments section to allow reproducibility assessment.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We address each major comment below, acknowledging areas where additional rigor is needed, and commit to revisions that strengthen the theoretical foundations without altering the core claims.
read point-by-point responses
-
Referee: [Method section (reinterpretation and Wasserstein DRO application)] The reinterpretation of the IQN loss as a sum of independent local quantile regression problems (one per sampled τ) is load-bearing for the entire construction, as it enables independent Wasserstein DRO application per slot to produce the claimed closed-form correction. However, the shared network parameters, joint sampling of multiple τ values, and implicit quantile embedding in the IQN architecture introduce potential coupling between terms. No explicit algebraic verification is provided that the loss factors cleanly or that the resulting per-slot corrections preserve median antisymmetry (hence the risk-neutral mean) and monotonic enlargement of quantile gaps under this coupling. This directly undermines the claims in the abstract regarding 'median antisymmetry' and 'monotonicity' as well as the skeptic's noted concern
Authors: We agree that the manuscript would benefit from an explicit algebraic verification of the decomposition and property preservation under the coupled IQN architecture. The per-τ Wasserstein DRO corrections are derived and applied independently to the Bellman targets before being fed into the shared network, which by construction maintains the median antisymmetry (preserving the risk-neutral mean) and monotonic gap enlargement. However, we acknowledge the absence of a formal proof addressing potential coupling effects from joint τ sampling and parameter sharing. In the revised manuscript, we will add a dedicated derivation subsection in the method section proving these properties hold for the corrected targets. revision: yes
-
Referee: [Abstract and §4 (theoretical properties)] The abstract states that the correction 'directly addresses distributional degeneration' with specific geometric properties, yet the provided text contains no derivation details, error bounds, or proof that the Wasserstein DRO formulation on local empirical quantiles yields a non-distorting, fraction-dependent shift that maintains the original Bellman target properties. Without this, it is impossible to confirm whether the empirical gains arise from the intended regularization or from incidental effects.
Authors: We concur that the current version lacks sufficient derivation details to fully substantiate the geometric properties. The Wasserstein DRO applied to each local empirical quantile problem yields a closed-form, τ-dependent correction via the dual of the Wasserstein metric on quantile functions; this shift is non-distorting to the mean by antisymmetry and enlarges gaps monotonically. We will expand the theoretical section (currently §4) with the complete derivation, including step-by-step verification that the correction preserves the original Bellman target properties and risk-neutral objective. While error bounds are not derived in the present work, the revision will clarify the exact mechanism to distinguish the intended regularization from incidental effects. revision: yes
Circularity Check
No circularity: derivation applies standard DRO to reinterpreted local problems without reduction to inputs
full rationale
The paper's chain reinterprets an IQN loss snapshot as independent local empirical quantile problems and applies a standard Wasserstein DRO formulation to derive a closed-form correction. This is a forward mathematical step from existing quantile regression and DRO concepts, with no evidence of self-definition, fitted parameters renamed as predictions, load-bearing self-citations, or ansatz smuggling. The median antisymmetry and monotonicity properties follow directly from the DRO setup rather than being presupposed. The result is self-contained against external benchmarks like standard Wasserstein DRO and does not reduce to its own fitted values or prior author results by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We first reinterpret a snapshot of IQN loss as a collection of local empirical quantile estimation problems over sampled current fractions. We then robustify each local slot with a Wasserstein distributionally robust quantile estimation formulation, yielding a closed-form, fraction-dependent correction to the Bellman target.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
the robust term Δp can be expressed as Δp(τ, ε) = ε (τ^q − (1−τ)^q) / c_{1−q,τ,p} … antisymmetric around the median: Δp(1−τ;ε) = −Δp(τ;ε), Δp(1/2;ε) = 0
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Implicit quantile networks for distributional reinforcement learning
Will Dabney, Georg Ostrovski, David Silver, and Rémi Munos. Implicit quantile networks for distributional reinforcement learning. InInternational conference on machine learning, pages 1096–1105. PMLR, 2018
work page 2018
-
[2]
Distributional reinforce- ment learning with quantile regression
Will Dabney, Mark Rowland, Marc Bellemare, and Rémi Munos. Distributional reinforce- ment learning with quantile regression. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
work page 2018
-
[3]
Statistics and samples in distributional reinforcement learning
Mark Rowland, Robert Dadashi, Saurabh Kumar, Rémi Munos, Marc G Bellemare, and Will Dabney. Statistics and samples in distributional reinforcement learning. InInternational Conference on Machine Learning, pages 5528–5536. PMLR, 2019
work page 2019
-
[4]
Playing Atari with Deep Reinforcement Learning
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. Playing atari with deep reinforcement learning.arXiv preprint arXiv:1312.5602, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[5]
Sami Jullien, Romain Deffayet, Jean-Michel Renders, Paul Groth, and Maarten de Rijke. Distributional reinforcement learning with dual expectile-quantile regression.arXiv preprint arXiv:2305.16877, 2023
-
[6]
Thanh Tang Nguyen, Sunil Gupta, and Svetha Venkatesh. Distributional reinforcement learning with maximum mean discrepancy.Association for the Advancement of Artificial Intelligence (AAAI), 2020
work page 2020
-
[7]
A distributional perspective on rein- forcement learning
Marc G Bellemare, Will Dabney, and Rémi Munos. A distributional perspective on rein- forcement learning. InInternational conference on machine learning, pages 449–458. Pmlr, 2017
work page 2017
-
[8]
Derek Yang, Li Zhao, Zichuan Lin, Tao Qin, Jiang Bian, and Tie-Yan Liu. Fully parameterized quantile function for distributional reinforcement learning.Advances in neural information processing systems, 32, 2019
work page 2019
-
[9]
Robust unmanned surface vehicle navigation with distributional reinforcement learning
Xi Lin, John McConnell, and Brendan Englot. Robust unmanned surface vehicle navigation with distributional reinforcement learning. In2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 6185–6191. IEEE, 2023
work page 2023
-
[10]
Zhaofan Zhang, Minghao Yang, Sihong Xie, and Hui Xiong. Perturbation-mitigated usv navigation with distributionally robust reinforcement learning.arXiv preprint arXiv:2512.00030, 2025
-
[11]
Robust quadrupedal locomotion via risk-averse policy learning
Jiyuan Shi, Chenjia Bai, Haoran He, Lei Han, Dong Wang, Bin Zhao, Mingguo Zhao, Xiu Li, and Xuelong Li. Robust quadrupedal locomotion via risk-averse policy learning. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 11459–11466. IEEE, 2024
work page 2024
-
[12]
Asymmetric least squares estimation and testing
Whitney K Newey and James L Powell. Asymmetric least squares estimation and testing. Econometrica: Journal of the Econometric Society, pages 819–847, 1987
work page 1987
-
[13]
Distributional reinforcement learning with sample- set bellman update
Weijian Zhang, Jianshu Wang, and Yang Yu. Distributional reinforcement learning with sample- set bellman update. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 2852–2858. IEEE, 2024
work page 2024
-
[14]
Arthur P Dempster, Nan M Laird, and Donald B Rubin. Maximum likelihood from incomplete data via the em algorithm.Journal of the royal statistical society: series B (methodological), 39(1):1–22, 1977
work page 1977
-
[15]
Robust estimation of a location parameter
Peter J Huber. Robust estimation of a location parameter. InBreakthroughs in statistics: Methodology and distribution, pages 492–518. Springer, 1992
work page 1992
-
[16]
Nikos Tzavidis, Stefano Marchetti, and Ray Chambers. Robust estimation of small-area means and quantiles.Australian & New Zealand Journal of Statistics, 52(2):167–186, 2010. 10
work page 2010
-
[17]
Onyedikachi O John. Robustness of quantile regression to outliers.American Journal of Applied Mathematics and Statistics, 3(2):86–88, 2015
work page 2015
-
[18]
Christian Galarza Morales, Victor Lachos Davila, Celso Barbosa Cabral, and Luis Castro Cepero. Robust quantile regression using a generalized class of skewed distributions.Stat, 6(1):113–130, 2017
work page 2017
-
[19]
Wasserstein distributionally robust quantile regression.arXiv preprint arXiv:2603.14991, 2026
Chunxu Zhang, Tiantian Mao, and Ruodu Wang. Wasserstein distributionally robust quantile regression.arXiv preprint arXiv:2603.14991, 2026
-
[20]
David J Acheson.Elementary fluid dynamics. Oxford University Press, 1990
work page 1990
-
[21]
Human-level control through deep reinforcement learning.nature, 518(7540):529–533, 2015
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning.nature, 518(7540):529–533, 2015
work page 2015
-
[22]
Rainbow: Combining improve- ments in deep reinforcement learning
Matteo Hessel, Joseph Modayil, Hado Van Hasselt, Tom Schaul, Georg Ostrovski, Will Dabney, Dan Horgan, Bilal Piot, Mohammad Azar, and David Silver. Rainbow: Combining improve- ments in deep reinforcement learning. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
work page 2018
-
[23]
Dopamine: A Research Framework for Deep Reinforcement Learning
Pablo Samuel Castro, Subhodeep Moitra, Carles Gelada, Saurabh Kumar, and Marc G Belle- mare. Dopamine: A research framework for deep reinforcement learning.arXiv preprint arXiv:1812.06110, 2018
work page Pith review arXiv 2018
-
[24]
Atari-5: Distilling the arcade learning environment down to five games
Matthew Aitchison, Penny Sweetser, and Marcus Hutter. Atari-5: Distilling the arcade learning environment down to five games. InInternational Conference on Machine Learning, pages 421–438. PMLR, 2023
work page 2023
-
[25]
Marlos C Machado, Marc G Bellemare, Erik Talvitie, Joel Veness, Matthew Hausknecht, and Michael Bowling. Revisiting the arcade learning environment: Evaluation protocols and open problems for general agents.Journal of Artificial Intelligence Research, 61:523–562, 2018. 11
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.